本文為您介紹如何使用資料轉送同步 OceanBase 資料庫的資料至 Kafka。
背景資訊
Kafka 是目前廣泛應用的高效能分布式Realtime Compute平台,資料轉送支援 OceanBase 資料庫兩種租戶與自建 Kafka 資料來源之間的資料即時同步,擴充訊息處理能力,廣泛應用於即時資料倉庫搭建、資料查詢和報表分流等業務情境。
前提條件
資料轉送已具備雲資源存取權限。詳情請參見 資料轉送遷移角色授權。
已為源端 OceanBase 資料庫建立專用於資料同步任務的資料庫使用者,並為其賦予了相關許可權。詳情請參見 建立資料庫使用者。
使用限制
資料同步的對象僅支援物理表,不支援其他對象。
資料轉送支援的 Kafka 版本為 V0.9、V1.0 和 V2.x。
資料同步過程中,如果您在源端修改了同步範圍內的表名稱,且重新命名後的名稱不在同步對象中,則該部分資料將不被同步至目標 Kafka 執行個體中。
待同步的表名和其中的列名不能包含中文字元。
資料轉送僅支援遷移庫名、表名和列名為 ASCII 碼且不包含特殊字元(包括換行、空格,以及 .|"'`()=;/&\)的對象。
資料轉送不支援 OceanBase 備庫作為源端。
注意事項
在源端為 OceanBase 資料庫並開啟同步 DDL 的資料同步任務中,如果源端庫表發生重新命名(
RENAME)操作,建議您重新啟動任務,避免增量同步處理遺失資料。當 OceanBase 資料庫為 V4.0.0 ~ V4.3.x 之間的版本(V4.2.5 BP1 除外),並且選擇了增量同步處理時,請為產生列配置 STORED 屬性。否則增量日誌中將不儲存產生列的資訊,可能導致增量同步處理資料異常的問題。
當更新的行包括 LOB 列時:
如果 LOB 列為更新列,請勿依賴 LOB 列在
UPDATE或DELETE操作前的值。目前使用 LOB 列進行儲存的資料類型包括 JSON、GIS、XML、UDT(使用者定義型別),以及 LONGTEXT、MEDIUMTEXT 等各類 TEXT。
如果 LOB 列為非更新列,則在
UPDATE或DELETE操作前或操作後,LOB 列的值均為 NULL。
節點之間的時鐘不同步,或者電腦終端和伺服器之間的時鐘不同步,均可能導致增量同步處理的延遲時間不準確。
例如,如果時鐘早於標準時間,可能導致延遲時間為負數。如果時鐘晚於標準時間,可能導致延遲問題。
當任務意外中斷進行斷點續傳時,Kafka 執行個體中可能會存在部分重複資料(最近一分鐘內),因此下遊系統需要具備去重能力。
同步 OceanBase 資料庫的資料至 Kafka 時,源端執行建立唯一索引語句失敗,Kafka 會消費到建立 DDL 語句和刪除 DDL 語句。如果傳到下遊的建立索引 DDL 執行失敗,請忽略該異常。
如果在建立資料同步任務時,您僅配置了 增量同步處理,資料轉送要求源端資料庫的本地增量日誌儲存 48 小時以上。
如果在建立資料同步任務時,您配置了 全量同步+增量同步處理,資料轉送要求源端資料庫的本地增量日誌至少保留 7 天以上。否則資料轉送可能因無法擷取增量日誌而導致資料同步任務失敗,甚至導致源端和目標端資料不一致。
支援的源端和目標端執行個體類型
下表中,OceanBase 資料庫 MySQL 租戶簡稱為 OB_MySQL,OceanBase 資料庫 Oracle 租戶簡稱為 OB_Oracle。
源端 | 目標端 |
OB_MySQL(OceanBase 叢集執行個體) | Kafka(阿里雲 Kafka 執行個體) |
OB_MySQL(OceanBase 叢集執行個體) | Kafka(VPC 內自建 Kafka 執行個體) |
OB_MySQL(OceanBase 叢集執行個體) | Kafka(公網 Kafka 執行個體) |
OB_MySQL(Serverless 執行個體) | Kafka(阿里雲 Kafka 執行個體) |
OB_MySQL(Serverless 執行個體) | Kafka(VPC 內自建 Kafka 執行個體) |
OB_MySQL(Serverless 執行個體) | Kafka(公網 Kafka 執行個體) |
OB_Oracle(OceanBase 叢集執行個體) | Kafka(阿里雲 Kafka 執行個體) |
OB_Oracle(OceanBase 叢集執行個體) | Kafka(VPC 內自建 Kafka 執行個體) |
OB_Oracle(OceanBase 叢集執行個體) | Kafka(公網 Kafka 執行個體) |
同步 DDL 支援的範圍
建立表
CREATE TABLE重要建立的表需要在同步物件範圍之內。目前僅支援對已經同步的表進行
DROP TABLE操作後,再執行CREATE TABLE。修改表
ALTER TABLE刪除表
DROP TABLE清空表
TRUNCATE TABLE說明延遲刪除情境下,同一個事務中會有兩條一樣的
TRUNCATE TABLEDDL。此時,下遊消費需要按等冪方式處理。從指定的分區中刪除資料
ALTER TABLE…TRUNCATE PARTITION建立索引
CREATE INDEX刪除索引
DROP INDEX添加表的備忘
COMMENT ON TABLE表重新命名
RENAME TABLE重要重新命名後的表名需要在同步物件範圍之內。
操作步驟
登入 OceanBase 管理主控台,購買資料同步任務。
詳情請參見 購買資料同步任務。
在 資料轉送 > 資料同步 頁面,單擊新購買的資料同步任務後的 配置。

如果您需要引用已有的任務配置資訊,可以單擊 引用配置。詳情請參見 引用和清空資料同步任務配置。
在 選擇源和目標 頁面,配置各項參數。
參數
描述
同步任務名稱
建議使用中文、數字和字母的組合。名稱中不能包含空格,長度不能超過 64 個字元。
源端
如果您已建立 OceanBase 資料來源,請從下拉式清單中進行選擇。如果未建立,請單擊下拉式清單中的 建立資料來源,在右側對話方塊進行建立。參數詳情請參見 建立 OceanBase 資料來源。
重要源端不支援 OceanBase 資料庫的 執行個體類型 為 OceanBase 租戶執行個體。
目標端
如果您已建立 Kafka 資料來源,請從下拉式清單中進行選擇。如果未建立,請單擊下拉式清單中的 建立資料來源,在右側對話方塊進行建立。參數詳情請參見 建立 Kafka 資料來源。
標籤(可選)
單擊文字框,在下拉式清單中選擇目標標籤。您也可以單擊 管理標籤,進行建立、修改和刪除。詳情請參見 通過標籤管理資料同步任務。
單擊 下一步。在 選擇同步類型 頁面,選擇當前資料同步任務的同步類型。
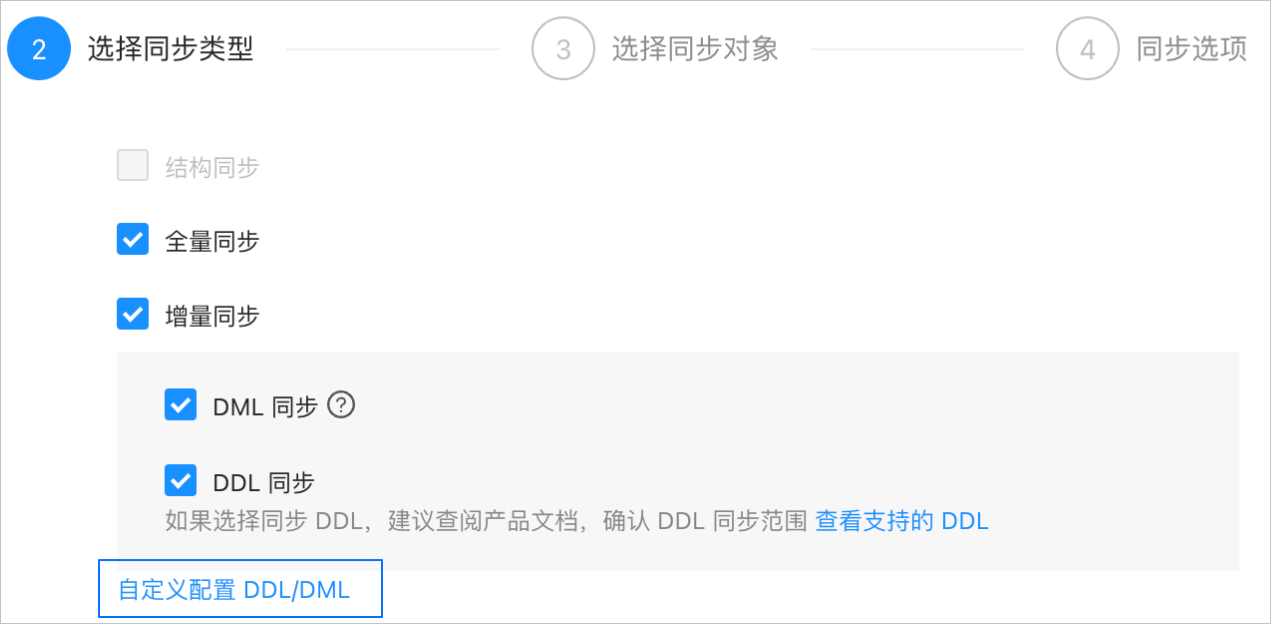
同步類型包括 全量同步 和 增量同步處理。增量同步處理 支援 DML 同步(包括
INSERT、DELETE和UPDATE)和 DDL 同步,您可以根據需求進行自訂配置。詳情請參見 自訂配置 DDL/DML。單擊 下一步。在 選擇同步對象 頁面,選擇當前資料同步任務需要同步的對象。
您可以通過 指定對象 和 匹配規則 兩個入口選擇同步對象。本文為您介紹通過 指定對象 方式選擇同步對象的具體操作,配置匹配規則的詳情請參見 配置和修改匹配規則 中庫到訊息佇列的通配規則說明和配置方式。
說明如果您在 選擇同步類型 步驟已勾選 DDL 同步,建議通過匹配規則方式選擇同步對象,以確保所有符合約步對象規則的新增對象都將被同步。如果您通過指定對象方式選擇同步對象,則新增對象或重新命名後的對象將不會被同步。
同步 OceanBase 資料庫的資料至 Kafka 時,支援多表到多 Topic 的同步。
在 選擇同步對象 地區,選中 指定對象。
在選擇地區左側選中需要同步的對象。
單擊 >。
在 將對象映射至 Topic 對話方塊的 已有 Topic 下拉式清單中,搜尋並選中需要同步的 Topic。
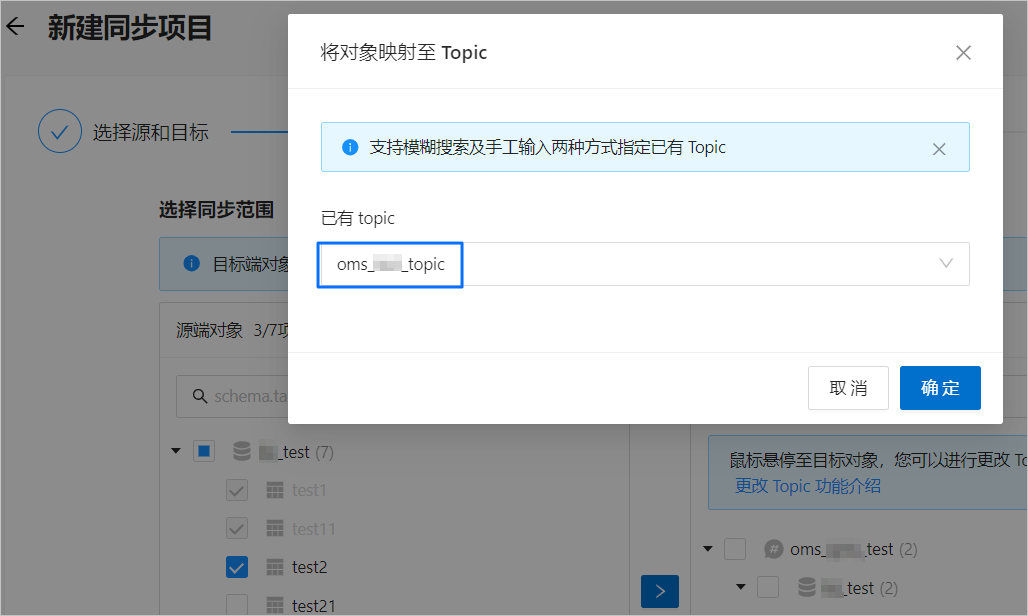
單擊 確定。
資料轉送支援通過文本匯入對象,並支援對目標端對象變更 Topic、設定行過濾、移除單個對象或全部對象等操作。目標端對象的結構為 Topic>Database>Table。
說明通過 匹配規則 方式選擇同步對象時,重新命名能力由匹配規則文法覆蓋,操作處僅支援設定過濾條件,以及選擇分區列和需要同步的列。詳情請參見 配置和修改匹配規則。
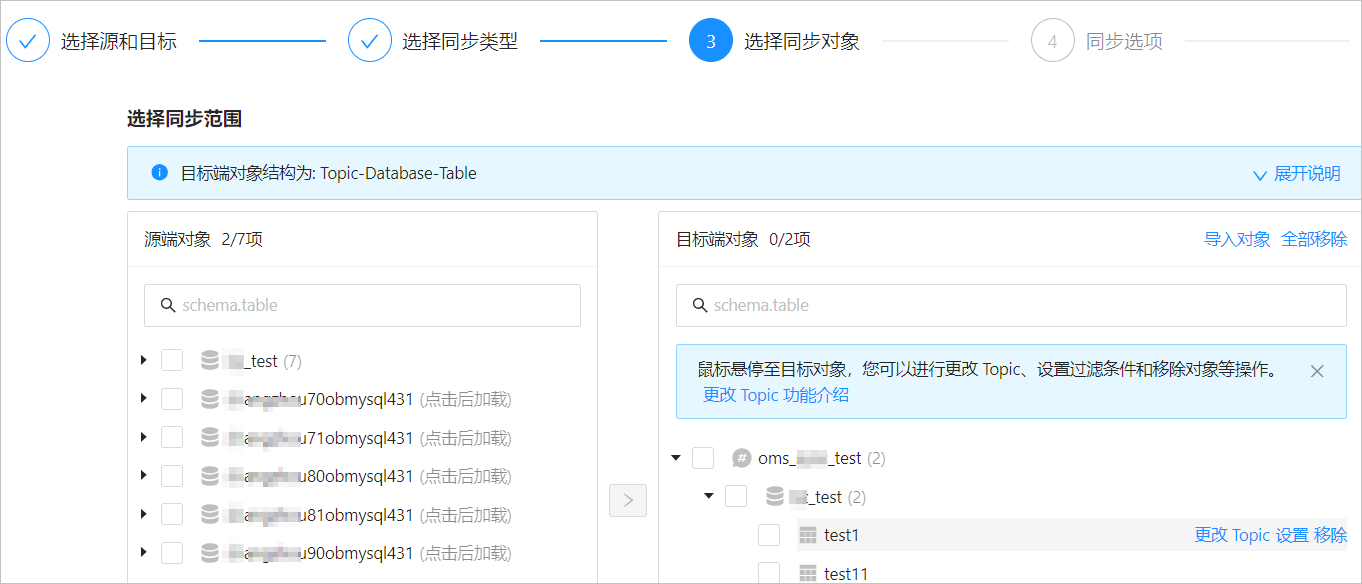
操作
描述
匯入對象
在選擇地區的右側列表中,單擊右上方的 匯入對象。
在對話方塊中,單擊 確定。
重要匯入會覆蓋之前的操作選擇,請謹慎操作。
在 匯入同步對象 對話方塊中,匯入需要同步的對象。 您可以通過匯入 CSV 檔案的方式進行設定行過濾條件、設定過濾列和設定分區列等操作。詳情請參見 下載和匯入同步對象配置。
單擊 檢驗合法性。
通過合法性的檢驗後,單擊 確定。
更改 Topic
資料轉送支援對目標對象變更 Topic 操作。詳情請參見 更改 Topic。
設定
資料轉送支援
WHERE條件實現行過濾,並選擇分區列和需要同步的列。在 設定 對話方塊中,您可以進行以下操作。
在 行過濾條件 地區的文字框中,輸入標準的 SQL 陳述式中的
WHERE子句,來配置行過濾。詳情請參見 SQL 條件過濾資料。在 分區列 下拉式清單中,選擇目標分區列。您可以選擇多個欄位作為分區列,該參數為選擇性參數。
選擇分區列時,如果沒有特殊情況,預設選擇主鍵即可。如果存在主鍵負載不均衡的情況,請選擇唯一性標識且負載相對均衡的欄位作為分區列,避免潛在的效能問題。分區列的主要作用如下:
負載平衡:在目標端可以進行並發寫入的情況下,通過分區列區分發送訊息需要使用的特定線程。
有序性:由於存在並發寫入可能導致的無序問題,資料轉送確保在分區列的值相同的情況下,使用者接收到的訊息是有序的。此處的有序是指變更順序(DML 對於一列的執行順序)。
在 選擇列 地區,選擇需要同步的列。詳情請參見 列過濾。
移除/全部移除
資料轉送支援在資料對應時,對暫時選中到目標端的單個或多個對象進行移除操作。
移除單個同步對象
在選擇地區的右側列表中,滑鼠移至上方至目標對象,單擊顯示的 移除,即可移除該同步對象。
移除全部同步對象
在選擇地區的右側列表中,單擊右上方的 全部移除。在對話方塊中,單擊 確定,即可移除全部同步對象。
單擊 下一步。在 同步選項 頁面,配置各項參數。
全量同步
在 選擇同步類型 頁面,選中 全量同步,才會顯示下述參數。
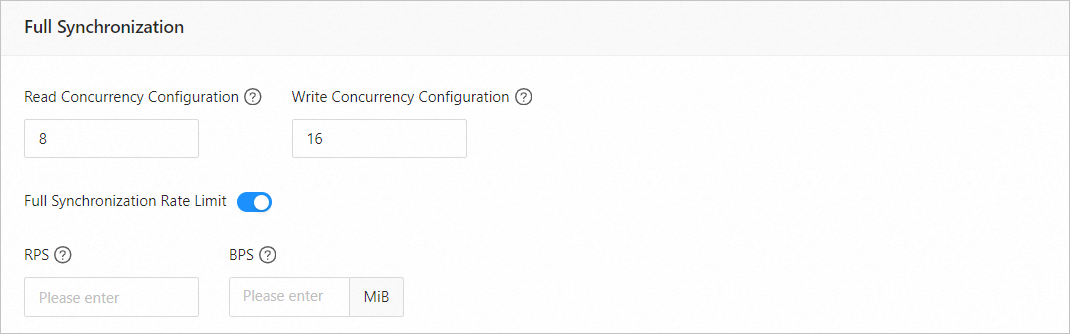
參數
描述
讀取並發配置
該參數用於配置全量同步階段從源端讀取資料的並發數,最大限制為 512.並發數過高可能會造成源端壓力過大,影響業務。
寫入並發配置
該參數用於配置全量同步階段往目標端寫入資料的並發數,最大限制為 512。並發數過高可能會造成目標端壓力過大,影響業務。
全量同步速率限制
您可以根據實際需求決定是否開啟全量同步速率限制。如果開啟,請設定 RPS(全量同步階段每秒最多可以同步至目標端的資料行數的最大值限制)和 BPS(全量同步階段每秒最多可以同步至目標端的資料量的最大值限制)。
說明此處設定的 RPS 和 BPS 僅作為限速限流能力,全量同步實際可以達到的效能受限於源端、目標端、執行個體規格配置等因素的影響。
增量同步處理
在 選擇同步類型 頁面,選中 增量同步處理,才會顯示下述參數。

參數
描述
寫入並發配置
該參數用於配置增量同步處理階段往目標端寫入資料的並發數,最大限制為 512。並發數過高可能會造成目標端壓力過大,影響業務。
增量同步處理速率限制
您可以根據實際需求決定是否開啟增量同步處理速率限制。如果開啟,請設定 RPS(增量同步處理階段每秒最多可以同步至目標端的資料行數的最大值限制)和 BPS(增量同步處理階段每秒最多可以同步至目標端的資料量的最大值限制)。
說明此處設定的 RPS 和 BPS 僅作為限速限流能力,增量同步處理實際可以達到的效能受限於源端、目標端、執行個體規格配置等因素的影響。
增量同步處理起始位點
如果選擇同步類型時已選擇 全量同步,則不支援修改該參數。
如果選擇同步類型時未選擇 全量同步,但選擇了 增量同步處理,請在此處指定同步某個時間節點之後的資料,預設為當前系統時間。詳情請參見 設定增量同步處理位點。
進階選項

參數
描述
序列化方式
控制資料同步至 Kafka 的訊息格式,目前支援 Default、Canal、DataWorks(支援 V2.0)、SharePlex、 DefaultExtendColumnType、Debezium、DebeziumFlatten、DebeziumSmt 和 Avro。詳情請參見 資料格式說明。
重要目前僅 OceanBase 資料庫 MySQL 租戶支援 Debezium、DebeziumFlatten、DebeziumSmt 和 Avro。
當選擇 DataWorks 時,同步 DDL 不支援
COMMENT ON TABLE和ALTER TABLE…TRUNCATE PARTITION。
分區規則
同步 OceanBase 資料庫的資料至 Kafka Topic 的規則,目前支援 Hash、Table 和 One。不同情境下的 DDL 語句投遞和樣本,請參見表格下方的說明。
Hash 表示資料轉送使用一定的 Hash 演算法,根據主索引值或分區列值 Hash 選擇 Kafka Topic 的分區。
Table 表示資料轉送將一張表中的全部資料投遞至同一個分區中,以表名作為 Hash 鍵。
One 表示 JSON 訊息會投遞至 Topic 下的某個分區,目的是為了保持排序。
業務系統標識(可選)
僅選擇 序列化方式 為 DataWorks 時,會顯示該參數,用於標識資料的業務系統來源,以便您後續進行自訂處理。該業務系統標識的長度限制為 1~20 個字元。
下表為不同情境的 DDL 語句投遞說明。
分區規則
DDL 語句涉及多張表
(例如 RENAME TABLE)
DDL 語句無法確認相關表
(例如 DROP INDEX)
DDL 語句涉及單張表
Hash
DDL 語句投遞至相關表所在 Topic 的所有分區。
例如,DDL 語句涉及 A、B 和 C 三張表,如果 A 在 Topic 1、B 在 Topic 2、C 不在本任務中,則該 DDL 語句投遞至 Topic 1 和 Topic 2 下的所有分區。
DDL 語句投遞至本任務所有 Topic 的所有分區。
例如,DDL 語句無法被資料轉送識別,如果當前任務存在三個 Topic,則該 DDL 語句被投遞至這三個 Topic 的所有分區。
DDL 語句投遞至該表所屬 Topic 下的所有分區。
Table
DDL 語句投遞至相關表所在 Topic 的對應表名 Hash 值所在的分區。
例如,DDL 語句涉及 A、B 和 C 三張表,如果 A 在 Topic 1、B 在 Topic 2、C 不在本任務中,則該 DDL 語句投遞至 Topic 1 和 Topic 2 下相關表 Hash 值所在的分區。
DDL 語句投遞至本任務所有 Topic 的所有分區。
例如,DDL 語句無法被資料轉送識別,如果本任務存在三個 Topic,則該 DDL 語句被投遞至這三個 Topic 的所有分區。
根據 Table Name 進行 Hash,投遞至該表所屬 Topic 內的某個分區。
One
DDL 語句投遞至相關表所在 Topic 的固定分區。
例如,DDL 語句涉及 A、B 和 C 三張表,如果 A 在 Topic 1、B 在 Topic 2、C 不在本任務中,則該 DDL 語句投遞至 Topic 1 和 Topic 2 下的某個固定分區。
DDL 語句投遞至本任務所有 Topic 的某個固定分區。
例如,DDL 語句無法被資料轉送識別,如果本任務存在三個 Topic,則該 DDL 語句被投遞至這三個 Topic 的某個固定分區。
DDL 語句投遞至該表所屬 Topic 下的某個固定分區。
單擊 預檢查。
在 預檢查 環節,資料轉送會檢測源端和目標端的串連情況。如果預檢查報錯:
您可以在排查並處理問題後,重新執行預檢查,直至預檢查成功。
您也可以單擊錯誤預檢查項操作列中的 跳過,會彈出對話方塊提示您跳過本操作的具體影響,確認可以跳過後,請單擊對話方塊中的 確定。
預檢查成功後,單擊 啟動任務。
如果您暫時無需啟動任務,請單擊 儲存。後續您只能在 同步工作清單 頁面手動啟動任務或通過大量操作啟動任務。大量操作的詳情請參見 大量操作資料同步任務。
資料轉送支援在資料同步任務運行過程中修改同步對象,詳情請參見 查看和修改同步對象及其過濾條件。資料同步任務啟動後,會根據選擇的同步類型依次執行,詳情請參見 查看同步詳情。
如果資料同步任務運行報錯(通常由於網路不通或進程啟動過慢導致),您可以在資料同步任務的列表或詳情頁面,單擊 恢複。