cassandra在高可用配置的情況下,無需逾時檢測及log回放,對系統的影響時間為毫秒級,基本無感知。
| QUORUM | HA機制 | Raft | Region | |
| 故障感知 | Coordinator/用戶端重試、無等待逾時時間 + 無log回放 ,無選主時間 | 用戶端重試、逾時檢測、log回放 | 用戶端重試、重新選leader | 用戶端重試、逾時檢測、log回放 |
| 感知時間 | ** 毫秒 ** | 10秒~10分鐘 | 10秒~10分鐘 | 1分鐘~10分鐘 |
| 代表系統 | Cassandra | RDS主備、MongoDB主備、Redis主備 | - | HBase |
配置建議
高可用配置基本要求:
故障類比
3個2cpu4g的節點,在高壓力寫的情況下,直接kill一個節點,用戶端的反饋如下:
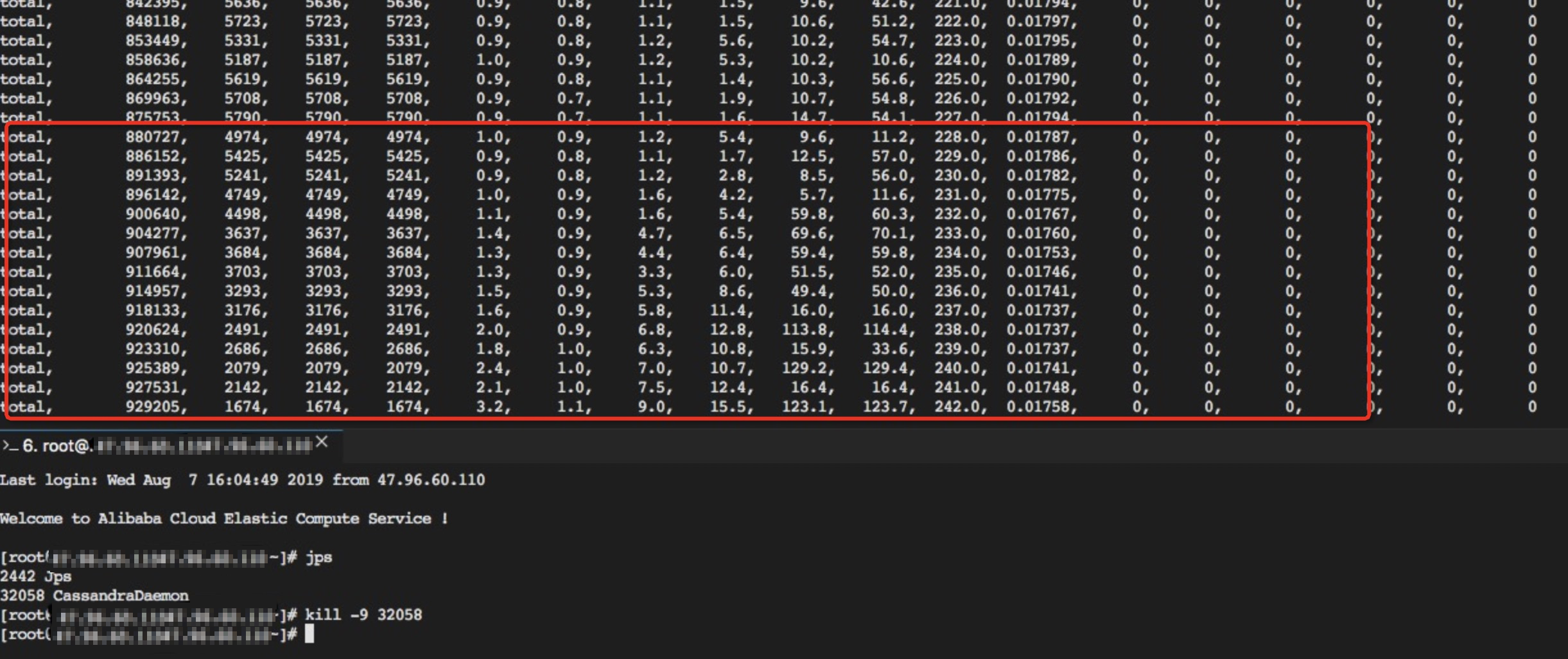
在直接kill Cassandra一個節點的進程情況下,服務沒有任何影響。