AnalyticDB for PostgreSQL通過外部資料封裝器FDW(foreign-data wrapper)協助您輕鬆快速實現對同一帳號中的不同執行個體進行聯集查詢,在保證資料即時性的同時,有效減少資料冗餘。
功能介紹
目前,很多公司或組織同時運行了多個執行個體,分別用於各種業務和應用。在特殊情況下,需要跨這些執行個體進行查詢,例如跨業務部門的聯合分析需求。傳統跨執行個體查詢資料會採用如下方式:
在不同的執行個體中儲存相同的資料副本,但可能會導致業務混亂以及資料冗餘。
將資料放在一份共用儲存中,例如儲存在OSS上,但無法保證資料的即時性。
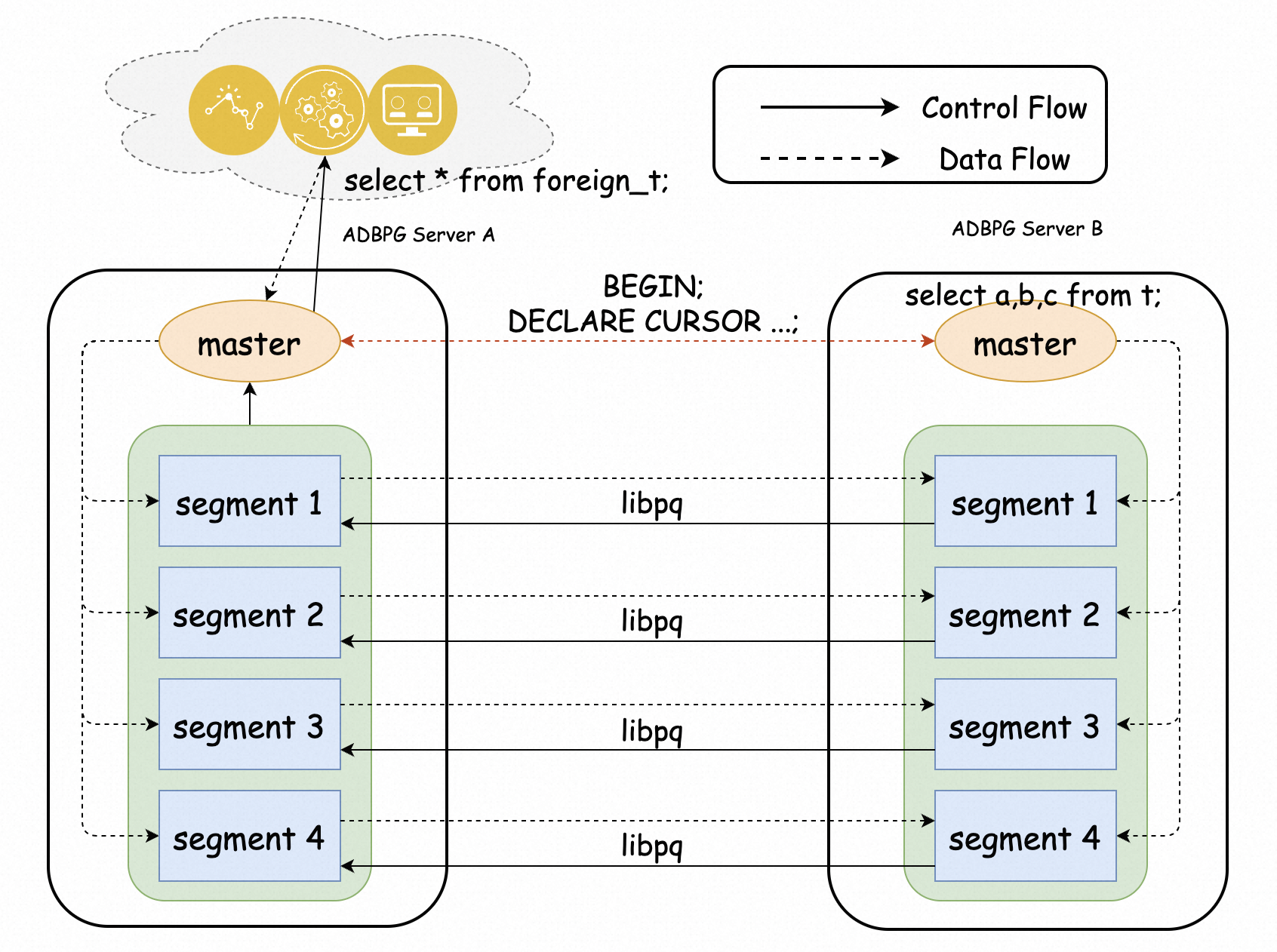
為解決上述問題,阿里雲團隊基於AnalyticDB PostgreSQL版的MPP架構,設計並實現了基於計算節點互聯互連的FDW,充分利用計算節點的效能優勢,實現資料在執行個體之間並行訪問,提高資料訪問效率的效果。效能相較於原生PostgreSQL的postgres_fdw有數倍的提升。
注意事項
源執行個體和目標執行個體需要屬於同一個阿里雲帳號,且位於同一個地區,同一個VPC下。
若訪問的源執行個體為Serverless模式執行個體,當源執行個體處於擴縮容狀態時,擴縮容期間資料不可訪問。
高速跨執行個體查詢僅支援以下資料庫核心版本:
儲存彈性模式7.0版:V7.0.1.x及以上版本。
儲存彈性模式6.0版:V6.3.11.2及以上版本。
Serverless模式:V1.0.6.x以及上版本。
由於AnalyticDB PostgreSQL 7.0版執行個體的密碼驗證方式發生變化,AnalyticDB PostgreSQL 6.0版執行個體和Serverless執行個體訪問AnalyticDB PostgreSQL 7.0版執行個體需要提交工单聯絡技術處理。
FDW外表僅支援SELECT和INSERT操作,不支援UPDATE和DELETE操作。
僅儲存彈性模式7.0版本支援JOIN下推和AGG下推功能。
僅儲存彈性模式7.0版本的ORCA最佳化器支援對FDW外表產生執行計畫,儲存彈性模式6.0版本和Serverless模式的ORCA最佳化器無法處理外表,會使用原生最佳化器產生執行計畫。
操作步驟
以下內容將為同一帳號下的執行個體A和執行個體B(兩個執行個體位於同一地區、同一可用性區域下)開通跨執行個體查詢。開通後,您可以在執行個體A的db01庫訪問執行個體B的db02庫中的表,並利用計算節點之間高速互聯的特性,方便地和本地表進行聯集查詢。
使用psql串連執行個體,操作步驟,請參見用戶端串連。
分別在執行個體A和執行個體B上建立資料庫。
在執行個體A上建立db01庫,並切換至db01庫。
CREATE DATABASE db01; \c db01在執行個體B上建立db02庫,並切換至db02庫。
CREATE DATABASE db02; \c db02在執行個體A的db01庫和執行個體B的db02庫建立跨庫查詢外掛程式greenplum_fdw和gp_parallel_retrieve_cursor。具體操作,請參見安裝、升級與卸載外掛程式。
擷取執行個體A的內網IP地址,並IP地址添加到執行個體B的白名單中。如何設定白名單,請參見設定白名單。
在執行個體A上執行以下SQL擷取內網IP地址。
SELECT dbid, address FROM gp_segment_configuration;在執行個體B的db02庫準備測試資料。
CREATE SCHEMA s01; CREATE TABLE s01.t1(a int, b int, c text); CREATE TABLE s01.t2(a int, b int, c text); CREATE TABLE s01.t3(a int, b int, c text); INSERT INTO s01.t1 VALUES(generate_series(1,10),generate_series(11,20),'t1'); INSERT INTO s01.t2 VALUES(generate_series(11,20),generate_series(11,20),'t2'); INSERT INTO s01.t3 VALUES(generate_series(21,30),generate_series(11,20),'t3')在執行個體A的db01庫中建立SERVER和USER MAPPING。
建立SERVER。
CREATE SERVER remote_adbpg FOREIGN DATA WRAPPER greenplum_fdw OPTIONS (host 'gp-xxxxxxxx-master.gpdb.zhangbei.rds.aliyuncs.com', port '5432', dbname 'db02');參數說明。
參數
說明
host
執行個體B的內網地址。
您可以登入雲原生資料倉儲AnalyticDB PostgreSQL版控制台,在執行個體B基本資料頁面的資料庫連接資訊地區,擷取內網地址。
port
執行個體B內網地址的連接埠號碼,預設為
5432。dbname
源庫的資料庫名稱,此處樣本為
db02。建立USER MAPPING,更多關於USER MAPPING的介紹,請參見CREATE USER MAPPING。
CREATE USER MAPPING FOR PUBLIC SERVER remote_adbpg OPTIONS (user 'report', password '******');參數說明。
參數
說明
user
執行個體B的資料庫帳號。
該帳號需要擁有db02庫的讀許可權(如需執行INSERT操作,則還需要寫入權限),如何建立帳號,請參見建立資料庫帳號。
password
以上帳號的密碼。
在執行個體A的db01庫實現跨執行個體查詢。
實現跨執行個體查詢有如下兩種方式:
為源表建立外表。
CREATE SCHEMA s01; CREATE FOREIGN TABLE s01.t1(a int, b int) server remote_adbpg options(schema_name 's01', table_name 't1');上述方式的優缺點如下:
優點:可以靈活定製外表的DDL。例如db02庫中t1有三個欄位a,b,c,但目標庫只需要a,b兩個欄位,因此可以在建立外表的時候指定欄位。
缺點:需要知道每一個表的DDL,一次性匯入多個外表較為繁瑣。
匯入源庫下Schema中的所有表。
CREATE SCHEMA s01; IMPORT FOREIGN SCHEMA s01 LIMIT TO (t1, t2, t3) FROM SERVER remote_adbpg INTO s01;上述方式的優缺點如下:
優點:可以快速匯入外表,而且不需要知道每一個表的DDL。
缺點:不夠靈活,每個表的名稱和源庫一致,欄位也一致。
更多介紹,請參見IMPORT FOREIGN SCHEMA。
在執行個體A的db01庫查詢執行個體B的db02資料。
SELECT * FROM s01.t1;返回樣本如下。
a | b | c ----+----+---- 2 | 12 | t1 3 | 13 | t1 4 | 14 | t1 7 | 17 | t1 8 | 18 | t1 1 | 11 | t1 5 | 15 | t1 6 | 16 | t1 9 | 19 | t1 10 | 20 | t1 (10 rows)
效能測試
以下內容為跨執行個體查詢的TPC-H效能測試,測試資料量為1 TB,並分別在資料庫本地和目標端資料庫中執行查詢。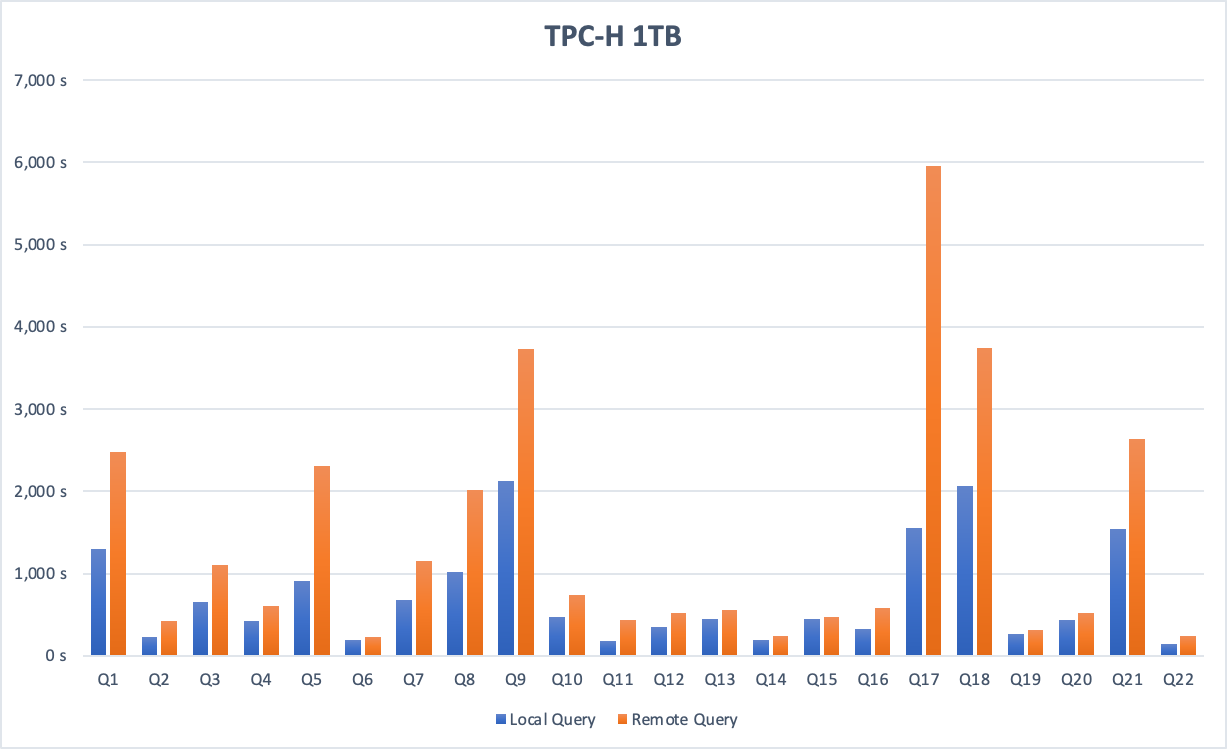
巨量資料情境(例如TPC-H 1 TB資料)下,跨執行個體查詢資料效能約為本地查詢資料效能的50%。
跨執行個體查詢資料需要跨網路傳輸資料,為了減少網路IO,請盡量增加外表的WHERE過濾條件。
相關文檔
AnalyticDB PostgreSQL版也支援跨庫查詢,詳情請參見跨庫查詢。