在處理大型資料集或需要快速存取和檢索資料的情境(資料庫查詢最佳化、機器學習和資料採礦、映像和視頻檢索、空間資料查詢等)中,建立向量索引是加速向量檢索的有效方式,可以提高查詢效能、加速資料分析和最佳化搜尋任務,從而提高系統的效率和響應速度。
背景資訊
雲原生資料倉儲AnalyticDB PostgreSQL版向量資料庫中的FastANN向量檢索引擎實現了主流的HNSW(Hierarchical Small World Graph)演算法,它基於PostgreSQL中的段頁式儲存實現,並且在索引中只儲存了指向表中向量列的指標,極大地減少了向量索引的儲存空間。同時FastANN向量檢索引擎也支援PQ(Product Quantization)量化功能,可以對高維向量進行降維。通過在索引中儲存降維後的向量達到減少在向量插入和查詢時的回表操作,從而提升了向量檢索的效能。
文法
CREATE INDEX [INDEX_NAME]
ON [SCHEMA_NAME].[TABLE_NAME]
USING ANN(COLUMN_NAME)
WITH (DIM=<DIMENSION>,
DISTANCEMEASURE=<MEASURE>,
HNSW_M=<M>,
HNSW_EF_CONSTRUCTION=<EF_CONSTURCTION>,
PQ_ENABLE=<PQ_ENABLE>,
PQ_SEGMENTS=<PQ_SEGMENTS>,
PQ_CENTERS=<PQ_CENTERS>,
EXTERNAL_STORAGE=<EXTERNAL_STORAGE>);各欄位說明:
INDEX_NAME:索引名。
SCHEMA_NAME:模式(命名空間)名。
TABLE_NAME:表名。
COLUMN_NAME:向量索引列名。
其他向量索引參數:
向量索引參數
是否必填
說明
預設值
取值範圍
DIM
是
向量維度。該參數主要用於向量插入時的檢查,當維度不匹配的時候,系統將提示相關錯誤資訊。
0
[1, 8192]
DISTANCEMEASURE
否
支援的相似性距離度量演算法:
L2:使用歐氏距離(平方)函數構建索引,通常適用於圖片相似性檢索情境。
計算公式:
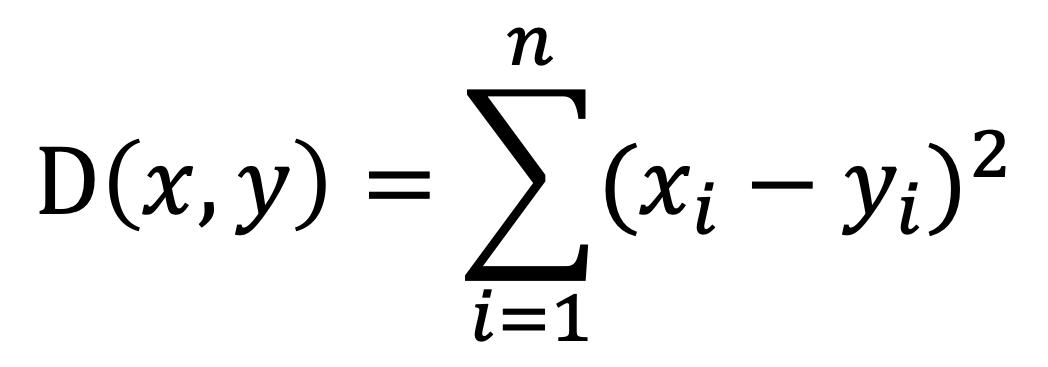
IP:使用反內積距離函數構建索引,通常適用於向量歸一化之後替代餘弦相似性。
計算公式:
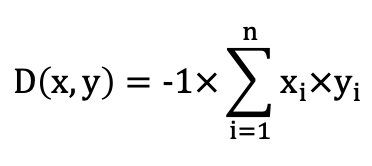
COSINE:使用餘弦距離函數構建索引,通常適用於文本相似性檢索情境。
計算公式:
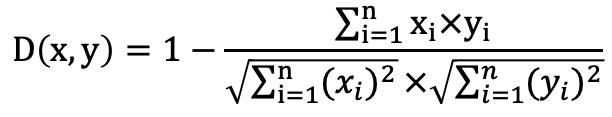
L2
(L2, IP, COSINE)
HNSW_M
否
HNSW演算法中的最大鄰居數。
32
[10, 1000]
HNSW_EF_CONSTRUCTION
否
HNSW演算法構建索引時的候選集大小。
600
[40, 4000]
PQ_ENABLE
否
是否開啟PQ向量降維的功能。PQ向量降維依賴於存量的向量樣本資料進行訓練,如果資料量小於50w時,不建議設定此參數。
0
[0, 1]
PQ_SEGMENTS
否
PQ_ENABLE為1時生效。用於指定PQ向量降維過程中使用的kmeans聚類演算法中的分段數。
如果DIM能被8整除,則不需要填寫,否則需要手動設定。
PQ_SEGMENTS必須大於0,且DIM必須能被PQ_SEGMENTS整除。
0
[1, 256]
PQ_CENTERS
否
PQ_ENABLE為1時生效。用於指定PQ向量降維過程中使用的kmeans聚類演算法中的中心點數。
2048
[256, 8192]
EXTERNAL_STORAGE
否
是否使用mmap構建HNSW索引。
為0時,預設會採用段頁式儲存構建索引,這種模式可以使用PostgreSQL中的shared_buffer做緩衝,支援刪除和更新等操作。
為1時,該索引會採用mmap構建索引,從v6.6.2.3版本開始為索引支援了標記刪除能力,可以支援資料表少量的刪除和更新操作。
重要僅6.0版本支援參數external_storage。7.0版本暫不支援。
0
[0, 1]
樣本
假設有一個文本知識庫,將文章分割成chunk後,轉換為embedding向量,最後存入資料庫中,其中切割產生的chunks表包含以下欄位:
欄位 | 類型 | 說明 |
id | serial | 編號。 |
chunk | varchar(1024) | 文章切塊後的文本chunk。 |
intime | timestamp | 文章的入庫時間。 |
url | varchar(1024) | 文本chunk所屬文章的連結。 |
feature | real[] | 文本chunk embedding向量。 |
建立儲存向量的資料庫表。
CREATE TABLE chunks ( id SERIAL PRIMARY KEY, chunk VARCHAR(1024), intime TIMESTAMP, url VARCHAR(1024), feature REAL[] ) DISTRIBUTED BY (id);將向量列的儲存模式設定為PLAIN,以降低資料行掃描成本,獲得更好的效能。
ALTER TABLE chunks ALTER COLUMN feature SET STORAGE PLAIN;對向量列建立向量索引。
-- 建立歐氏距離度量的向量索引。 CREATE INDEX idx_chunks_feature_l2 ON chunks USING ann(feature) WITH (dim=1536, distancemeasure=l2, hnsw_m=64, pq_enable=1); -- 建立內積距離度量的向量索引。 CREATE INDEX idx_chunks_feature_ip ON chunks USING ann(feature) WITH (dim=1536, distancemeasure=ip, hnsw_m=64, pq_enable=1); -- 建立餘弦相似性度量的向量索引。 CREATE INDEX idx_chunks_feature_cosine ON chunks USING ann(feature) WITH (dim=1536, distancemeasure=cosine, hnsw_m=64, pq_enable=1);說明目前一個向量表可以建立多個向量列,每個向量列又可以建立多個向量索引,具體根據實際需要建立對應的向量索引,避免建立無效的索引。
向量查詢的方式必須與向量索引的距離度量對應。例如,向量查詢中的符號
<->對應歐氏距離度量的向量索引,<#>對應內積距離度量的向量索引,<=>對應餘弦相似性度量的向量索引。如果沒有對應的向量索引,則向量查詢會退化為精確搜尋(即暴力搜尋)。請使用FastANN向量檢索外掛程式提供的
ANN存取方法,當執行個體開啟向量檢索引擎最佳化功能時,會自動在該執行個體中建立FastANN向量檢索外掛程式。若報錯
You must specify an operator class or define a default operator class for the data type,表示該執行個體未開啟向量檢索引擎最佳化功能,請開啟後重試,具體操作請參見開啟或關閉向量檢索引擎最佳化。
為常用的結構化列建立索引,提升融合查詢速度。
CREATE INDEX ON chunks(intime);
向量索引的構建方式
向量索引主要分為兩種構建方式:
流式構建。
即先建立一個空表,並在空表上建立向量索引,那麼在進行向量資料匯入時,就會進行流式即時的索引構建。此方式適用於即時向量檢索情境,但是會導致資料匯入速度過慢。
非同步構建。
即在建立一個空表後,在不建向量索引的情況下,先將資料匯入,然後再對存量的向量資料構建向量索引。此方式適用於大規模向量資料匯入的情境。
雲原生資料倉儲AnalyticDB PostgreSQL版對於非同步向量索引構建模式提供了並發構建能力,可以通過GUC參數fastann.build_parallel_processes來設定並行構建索引的並發度。
例如,在DMS上非同步構建索引可以採用如下方式:
-- 假設在8C32GB的執行個體規格上進行操作。
-- 設定statement_timeout和idle_in_transaction_session_timeout都為0,確保不觸發逾時中斷。
-- 設定fastann.build_parallel_processes為8,確保計算節點的CPU可以用滿,這裡需要根據segment的不同的規格需要設定不同的值,如4C16GB的規格設定為4,8C32GB的規格設定為8,16C64GB規格設定為16。
-- 在DMS上,參數設定必須和索引建立的SQL在同一行,否則不能生效。
SET statement_timeout = 0;SET idle_in_transaction_session_timeout = 0;SET fastann.build_parallel_processes = 8;CREATE INDEX ON chunks USING ann(feature)
WITH (dim=1536, distancemeasure=cosine, hnsw_m=64, pq_enable=1);使用psql進行非同步構建索引時可以採用如下方式:
-- 假定和上面DMS操作的執行個體一樣,也是8C32GB的執行個體上進行操作。
-- 第一步:將以下內容放到檔案create_index.sql中。
SET statement_timeout = 0;
SET idle_in_transaction_session_timeout = 0;
SET fastann.build_parallel_processes = 8;
CREATE INDEX ON chunks USING ann(feature) WITH (dim=1536, distancemeasure=cosine, hnsw_m=64, pq_enable=1);
-- 第二步:執行如下命令開始並行構建索引。
psql -h gp-xxxx-master.gpdb.rds.aliyuncs.com -p 5432 -d dbname -U username -f create_index.sql如果當前執行個體有業務正在使用,不能將索引構建的並行進程數調到和執行個體規格一致,否則會影響正在啟動並執行業務。
相關參考
函數作用 | 向量函數 | 傳回值類型 | 含義 | 支援資料類型 |
計算 | l2_distance | double precision | 歐氏距離(開方值),用于衡量兩個向量的大小,表示兩個向量的距離。普遍應用於檢索圖片相似性。 重要 l2_distance在V6.3.10.17及以下版本中為歐氏距離(平方值),在V6.3.10.18及以上版本中為歐式距離(開方值)。 | smallint[]、float2[]、float4[]、real[] |
inner_product_distance | double precision | 內積距離,在向量歸一化之後等於餘弦相似性,通常用於在向量歸一化之後替代餘弦相似性。 計算公式: | smallint[]、float2[]、float4[]、real[] | |
cosine_similarity | double precision | 餘弦相似性,取值範圍:[-1, 1],通常用于衡量兩個向量在方向上的相似性,而不關心兩個向量的實際長度。 計算公式: | smallint[]、float2[]、float4[]、real[] | |
dp_distance | double precision | 點積距離,和內積距離完全一致。 計算公式: | smallint[]、float2[]、float4[]、real[] | |
hm_distance | integer | 漢明距離。 計算公式:位元運算 | int[] | |
vector_add | smallint[], float2[] 或 float4[] | 計算兩個向量數組的加法。 | smallint[]、float2[]、float4[]、real[] | |
vector_sub | smallint[], float2[] 或 float4[] | 計算兩個向量數組的減法。 | smallint[]、float2[]、float4[]、real[] | |
vector_mul | smallint[], float2[] 或 float4[] | 計算兩個向量數組的乘法。 | smallint[]、float2[]、float4[]、real[] | |
vector_div | smallint[], float2[] 或 float4[] | 計算兩個向量數組的除法。 | smallint[]、float2[]、float4[]、real[] | |
vector_sum | int 或 double precision | 計算一個向量數組中所有元素的累加值。 | smallint[]、int[]、float2[]、float4[]、real[]、float8[] | |
vector_min | int 或 double precision | 統計一個向量數組中所有元素的最小值。 | smallint[]、int[]、float2[]、float4[]、real[]、float8[] | |
vector_max | int 或 double precision | 統計一個向量數組中所有元素的最大值。 | smallint[]、int[]、float2[]、float4[]、real[]、float8[] | |
vector_avg | int 或 double precision | 計算一個向量數組中所有元素的平均值。 | smallint[]、int[]、float2[]、float4[]、real[]、float8[] | |
vector_norm | double precision | 計算一個向量數組的模長。 | smallint[]、int[]、float2[]、float4[]、real[]、float8[] | |
vector_angle | double precision | 計算兩個向量數組的夾角。 | smallint[]、float2[]、float4[]、real[] | |
排序 | l2_squared_distance | double precision | 歐氏距離(平方值),由於比歐氏距離(開方值)少了開方的計算,因此主要用於對歐氏距離(開方值)的排序邏輯,以減少計算量。 計算公式: | smallint[]、float2[]、float4[]、real[] |
negative_inner_product_distance | double precision | 反內積距離,為內積距離取反後的結果,主要用於對內積距離的排序邏輯,以保證排序結果按內積距離從大到小排序。 計算公式: | smallint[]、float2[]、float4[]、real[] | |
cosine_distance | double precision | 餘弦距離,取值範圍:[0, 2],主要用於對餘弦相似性的排序邏輯,以保證排序結果按餘弦相似性從大到小排序。 計算公式: | smallint[]、 float2[]、float4[]、real[] |
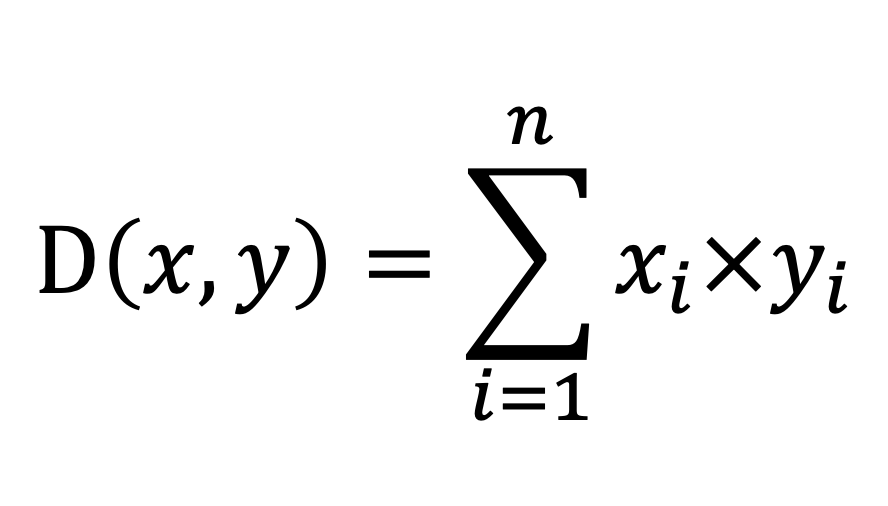

vector_add、vector_sub、vector_mul、vector_div、vector_sum、vector_min、vector_max、vector_avg、vector_norm和vector_angle向量函數僅v6.6.1.0及以上版本支援。如何查看執行個體版本,請參見查看核心小版本。
向量函數的使用樣本:
-- 歐氏距離
SELECT l2_distance(array[1,1,1,1]::real[], array[2,2,2,2]::real[]);
-- 內積距離
SELECT inner_product_distance(array[1,1,1,1]::real[], array[2,2,2,2]::real[]);
-- 餘弦相似性
SELECT cosine_similarity(array[1,1,1,1]::real[], array[2,2,2,2]::real[]);
-- 點積距離
SELECT dp_distance(array[1,1,1,1]::real[], array[2,2,2,2]::real[]);
-- 漢明距離
SELECT hm_distance(array[1,0,1,0]::int[], array[0,1,0,1]::int[]);
-- 向量數組加法
SELECT vector_add(array[1,1,1,1]::real[], array[2,2,2,2]::real[]);
-- 向量數組減法
SELECT vector_sub(array[1,1,1,1]::real[], array[2,2,2,2]::real[]);
-- 向量數組乘法
SELECT vector_mul(array[1,1,1,1]::real[], array[2,2,2,2]::real[]);
-- 向量數組除法
SELECT vector_div(array[1,1,1,1]::real[], array[2,2,2,2]::real[]);
-- 向量數組累加值
SELECT vector_sum(array[1,1,1,1]::real[]);
-- 向量數組最小值
SELECT vector_min(array[1,1,1,1]::real[]);
-- 向量數組最大值
SELECT vector_max(array[1,1,1,1]::real[]);
-- 向量數組平均值
SELECT vector_avg(array[1,1,1,1]::real[]);
-- 向量數組模長
SELECT vector_norm(array[1,1,1,1]::real[]);
-- 兩個向量的夾角
SELECT vector_angle(array[1,1,1,1]::real[], array[2,2,2,2]::real[]);