全文檢索索引(Full Text Search)指資料庫將自然語言文本轉換為可被查詢資料的能力。雲原生資料倉儲AnalyticDB PostgreSQL版使用PostgreSQL核心,提供完善的全文檢索索引功能。本文介紹AnalyticDB PostgreSQL版如何?“一站式全文檢索索引”業務。
背景資訊
隨著數字時代的發展,資料的來源和產生方式越來越廣泛,其中也包含大量的文本資料。人們通常選擇資料庫或資料倉儲儲存文本資料,但是將文本資料中有價值的資訊提取出來並進行高效分析,往往需要涉及多個資料處理系統配合來實現,使用者的使用門檻通常較高、維護成本較大。
通常在使用資料倉儲進行文本資料的加工和分析時,離不開資料倉儲的資料即時寫入、全文檢索索引及任務調度等能力。如何使用一套數倉系統完成上述所有功能,往往面臨以下幾個挑戰:
資料倉儲核心的全文檢索索引功能不夠全面。部分資料倉儲在全文檢索索引功能上的的缺失,導致使用者需要對文本資料做大量開發後才能將資料匯入資料倉儲。
任務調度依賴資料倉儲核心的SQL標準支援能力,以及強大的外部工具支援。
全文檢索索引涉及大量的文本資料,而資料倉儲在處理文本資料時效能往往不如數字類型的資料。
不具備靈活的配置變更能力等。
AnalyticDB PostgreSQL版同時具備完善的全文檢索索引和資料加工能力,能夠較好地解決上述問題。
概述
在資料庫儲存的文本中找到特定的查詢詞並將它們按照出現的次數排序,就是一種典型的全文檢索索引應用。
大部分資料庫都提供對文字查詢的準系統。例如,在查詢中使用LIKE等運算式尋找搜尋文本,但這些方法在現代資料庫業務中缺少以下能力:
資料庫常用的運算式查詢方法無法處理派生詞等文法。例如,英文單詞
satisfy和它的第三人稱形式satisfies。如果使用satisfy作為關鍵詞查詢,查詢結果可能遺漏satisfies,這不是全文檢索索引所期望的結果。當然也可以使用運算式OR去同時匹配satisfy和satisfies,但是這樣操作效率非常低且容易出錯(某些單詞存在大量的派生詞)。無法對匹配結果進行有效地排序。當查詢結果較多時,篩選結果將變得非常低效。
查詢效能慢,無法建立有效索引,導致查詢需要遍曆完整的文本資料。
AnalyticDB PostgreSQL版的一站式全文檢索索引業務同時具備上述所有能力。下圖展示了AnalyticDB PostgreSQL版全文檢索索引業務的流程。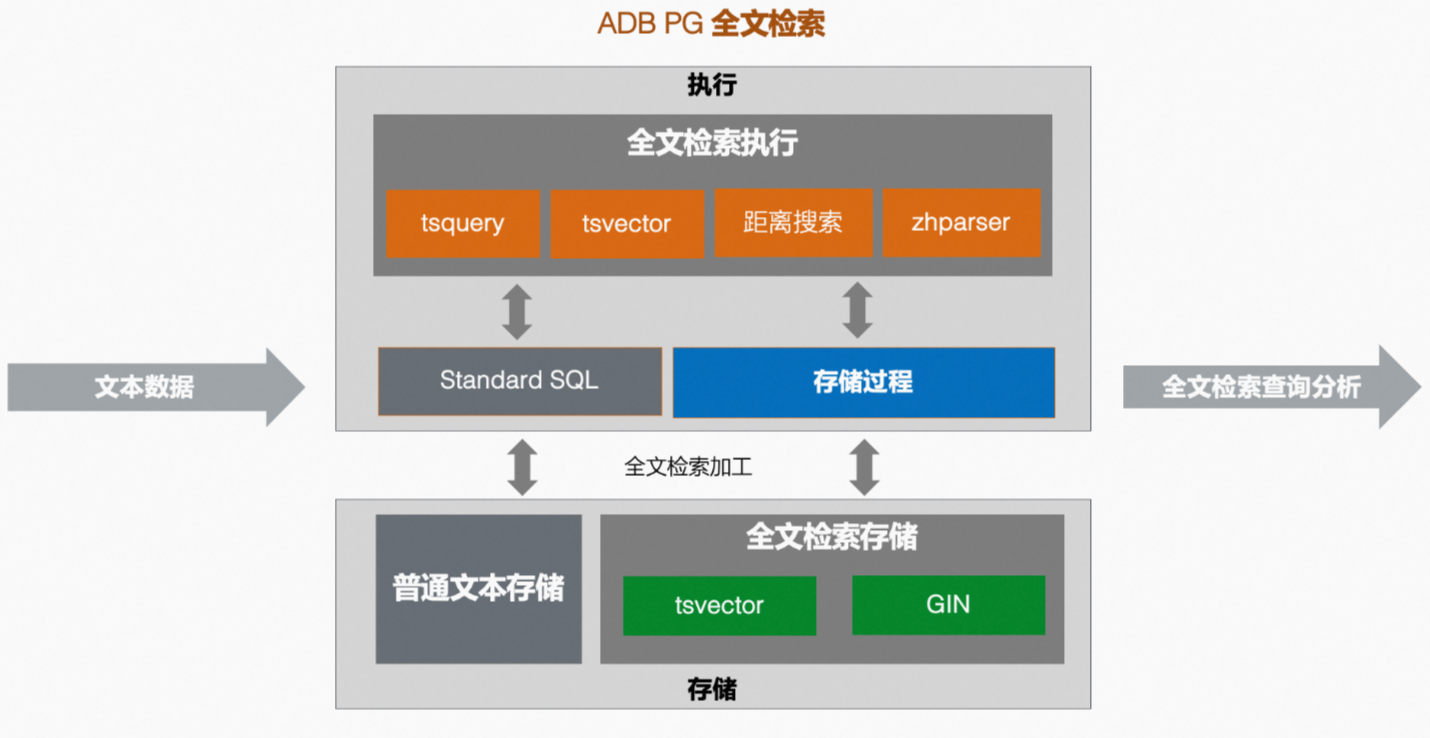
全文檢索索引準系統
AnalyticDB PostgreSQL版的全文檢索索引功能,通過文本的預計算提供快速的查詢效能。其中預計算主要包含以下幾步:
將文本解析為符號。通過符號將文本詞語分類為不同的類型,例如數字、形容詞、副詞等,不同類型的符號可以做不同的操作處理。PostgreSQL核心使用預設的解析器(parser)進行符號解析,並提供自訂解析器能力用於解析不同語言文本。
將符號轉換為詞語。相比較符號,詞語經過了歸一化(normalized)操作,將單詞的不同形式進行合并(如
satisfy和satisfies),使得全文檢索索引功能可以根據語義高效檢索。PostgreSQL核心使用詞典(dictionaries)進行符號轉換為詞語的操作,同樣提供了自訂字典功能。最佳化詞語儲存,高效查詢。例如,PostgreSQL核心提供
tsvector(text search vector)資料類型,將文本解析轉換為帶有詞語資訊的有序資料,並通過tsquery(text search query)文法對此類資料進行查詢,實現高效的全文檢索索引。
tsvector
tsvector用於存放一系列去重(distinct)的詞語和詞語順序、位置等資訊,使用PostgreSQL提供的to_tsvector方法可以自動完成文本至tsvector的轉換。以英文語句'a fat cat jumped on a mat and ate two fat rats'為例:
postgres=# SELECT to_tsvector('a fat cat jumped on a mat and ate two fat rats');
to_tsvector
---------------------------------------------------------------
'ate':9 'cat':3 'fat':2,11 'jump':4 'mat':7 'rat':12 'two':10
(1 row)從查詢結果可以看到tsvector的結果包含了一系列的詞語,並按照詞語的順序進行了排序。同時每個詞語後跟隨了其在語句中的位置資訊,如fat':2,11表示fat在語句的第2和第11個位置。此外tsvector結果省略了串連詞(and,on等),並對部分單詞進行了歸一化的處理(jumped過去式歸一化為jump)。
tsvector將文本完成預計算和轉換。
tsquery
tsquery用於存放查詢tsvector的詞語,PostgreSQL同樣提供to_tsquery方法將文本轉換為tsquery,結合tsvector及全文檢索索引操作符,就可以完成全文檢索索引查詢。
tsquery支援@@(包含)操作符和Boolean操作符&( AND)、|(OR) 和!(NOT),可以方便地構建組合條件的檢索查詢。
例如,使用@@尋找tsvector中是否包含tsquery的詞語。
postgres=# SELECT to_tsvector('a fat cat jumped on a mat and ate two fat rats') @@ to_tsquery('cat');
?column?
----------
t
(1 row)
postgres=# SELECT to_tsvector('a fat cat jumped on a mat and ate two fat rats') @@ to_tsquery('cats');
?column?
----------
t
(1 row)
postgres=# SELECT to_tsvector('a fat cat jumped on a mat and ate two fat rats') @@ to_tsquery('cat | dog');
?column?
----------
t
(1 row)
postgres=# SELECT to_tsvector('a fat cat jumped on a mat and ate two fat rats') @@ to_tsquery('cat & dog');
?column?
----------
f
(1 row)從查詢結果可以看到,對詞語cat的查詢結果為t,即true表明查詢匹配。同時,由於cats是cat的複數,語義上也滿足匹配,因此對詞語cats的查詢結果也為t。
距離搜尋
僅AnalyticDB PostgreSQL 7.0版執行個體支援距離搜尋,AnalyticDB PostgreSQL 6.0版執行個體不支援距離搜尋。
全文檢索索引不僅可以尋找文本中是否包含某個詞,還可以在短語、片語的基礎上做進一步分析。PostgreSQL的全文檢索索引tsquery方法,支援短語搜尋符<N>,其中N為整數,表示指定詞語之間的距離。例如,想要尋找文本是否存在cat後跟隨jump的短語,則可以使用<1>操作符尋找。
postgres=# SELECT to_tsvector('a fat cat jumped on a mat and ate two fat rats') @@ to_tsquery('cat<1>jump');
?column?
----------
t
(1 row)尋找特定的詞語組合,也可以用距離搜尋方法實現。
postgres=# SELECT to_tsvector('a fat cat jumped on a mat and ate two fat rats') @@ to_tsquery('cat<2>mat');
?column?
----------
f
(1 row)
postgres=# SELECT to_tsvector('a fat cat jumped on a mat and ate two fat rats') @@ to_tsquery('cat<4>mat');
?column?
----------
t
(1 row)AnalyticDB PostgreSQL版在PostgreSQL全文檢索索引功能基礎上,結合社區能力對全文檢索索引進行了深度開發,進一步支援了全文檢索索引範圍距離搜尋符<N,M>,M和N為整數,即指定詞語之間距離在N至M之間的範圍內。例如尋找文本中是否包含cat和mat間距離小於等於5的短語,則可以使用<1,5>查詢。
postgres=# SELECT to_tsvector('a fat cat jumped on a mat and ate two fat rats') @@ to_tsquery('cat<1,5>mat');
?column?
----------
t
(1 row)中文分詞:Zhparser外掛程式
在部分資料庫業務中,通常會存放大量中文文本資訊,例如使用者的評價表單、地址資訊等。對中文文本的分析同樣需要全文檢索索引功能來實現。但對於中文,詞語是最小語素單位,書寫時並不像英語會在詞之間用空格分開,這就導致如果使用PostgreSQL的預設全文檢索索引引擎,難以得到符合中文語義的分詞結果。例如,使用PostgreSQL tsvector預設方法分詞中文語句,得到的結果明顯無法滿足分詞需求:
postgres=# SELECT to_tsvector('你好,這是一條中文測試文本');
to_tsvector
-----------------------------------
'你好':1 '這是一條中文測試文本':2
(1 row)SCWS(Simple Chinese Word Segmentation,簡易中文分詞系統),是一套基於詞頻詞典的開源中文分詞引擎,它能將一整段的中文文本基本正確地切分成詞。SCWS使用C語言開發,可以直接作為動態連結程式庫接入應用程式,結合PostgreSQL的代碼擴充能力,可以在PostgreSQL資料庫中使用SCWS實現中文分詞功能。
Zhparser外掛程式是一個基於SCWS能力開發的PostgreSQL中文分詞外掛程式,在相容PostgreSQL已有全文檢索索引能力的基礎上,提供豐富的功能配置選項,同時也提供使用者自訂字典功能。
在AnalyticDB PostgreSQL版中,Zhparser外掛程式已完成預設安裝,您可以根據中文分詞需求自訂配置Zhparser。例如,建立一個名為zh_cn的中文分詞解析器並配置分詞策略:
--- 建立分詞解析器。
CREATE TEXT SEARCH CONFIGURATION zh_cn (PARSER = zhparser);
--- 添加名詞(n)、動詞(v)、形容詞(a)、成語(i)、歎詞(e)和慣用語(l)、自訂(x)分詞策略。
ALTER TEXT SEARCH CONFIGURATION zh_cn ADD MAPPING FOR n,v,a,i,e,l,x WITH simple; 完成基本配置後,您可以使用中文分詞能力開發中文檢索業務。樣本如下:
postgres=# SELECT to_tsvector('zh_cn','你好,這是一條中文測試文本');
to_tsvector
----------------------------------------------
'中文':3 '你好':1 '文本':5 '測試':4 '這是':2
(1 row)同樣,您也可以使用tsquery結合Zhparser進行文本搜尋。樣本如下:
postgres=# SELECT to_tsvector('zh_cn','你好,這是一條中文測試文本') @@ to_tsquery('zh_cn','中文<1,3>文本');
?column?
----------
t
(1 row)更多關於Zhparser外掛程式的使用方法,請參見使用Zhparser支援中文分詞。
自訂詞庫
Zhparser提供中文自訂詞庫功能,如果預設的詞庫滿足不了分詞的結果需求,可以更新自訂詞庫並即時最佳化查詢結果。Zhparser的系統資料表zhparser.zhprs_custom_word是一個面向使用者的自訂字典表,您只需要更新該系統資料表即可實現自訂詞庫。zhparser.zhprs_custom_word的表結構如下:
Table "zhparser.zhprs_custom_word"
Column | Type | Collation | Nullable | Default
--------+------------------+-----------+----------+-----------------------
word | text | | not null |
tf | double precision | | | '1'::double precision
idf | double precision | | | '1'::double precision
attr | character(1) | | | '@'::bpchar
Indexes:
"zhprs_custom_word_pkey" PRIMARY KEY, btree (word)
Check constraints:
"zhprs_custom_word_attr_check" CHECK (attr = '@'::bpchar OR attr = '!'::bpchar)其中word列為自訂詞語。tf、idf列用於設定自訂詞語權重,參見TF-IDF(term frequency–inverse document frequency,詞頻-逆文本頻率指數)。attr列為自訂詞語的分詞、停止詞屬性。
在AnalyticDB PostgreSQL版中自訂詞庫是資料庫層級的,存放於每個資料節點對應資料庫的資料目錄下。通過以下樣本為您展示如何AnalyticDB PostgreSQL版中使用自訂詞庫功能。
樣本一:將
你好,這是一條中文測試文本中測試和文本不拆分為兩個詞語,而是以測試文本作為一個單獨的分詞,只需要在zhparser.zhprs_custom_word系統資料表中插入對應分詞,重載後即可生效。postgres=# INSERT INTO zhparser.zhprs_custom_word values('測試文本'); INSERT 0 1 postgres=# SELECT sync_zhprs_custom_word(); --載入自訂分詞。 sync_zhprs_custom_word ------------------------ (1 row) postgres=# \q --重建立立串連。 postgres=# SELECT to_tsvector('zh_cn','你好,這是一條中文測試文本'); to_tsvector ----------------------------------------- '中文':3 '你好':1 '測試文本':4 '這是':2 (1 row)樣本二:自訂詞庫也支援停止詞功能。例如,當不希望將
你好,這是一條中文測試文本中這是單獨作為一個分詞時,同樣可以在自訂詞庫中插入對應的詞語和控制符停止特定分詞。postgres=# INSERT INTO zhparser.zhprs_custom_word(word, attr) values('這是','!'); INSERT 0 1 postgres=# SELECT sync_zhprs_custom_word(); sync_zhprs_custom_word ------------------------ (1 row) postgres=# \q --重建立立串連。 postgres=# SELECT to_tsvector('zh_cn','你好,這是一條中文測試文本'); to_tsvector --------------------------------------- '中文':3 '你好':1 '是':2 '測試文本':4 (1 row)
全文檢索索引索引
全文檢索索引查詢業務可能涉及到大量的文本資料,合理使用索引可以有效提升查詢效能。倒排索引是一種存放了資料和位置關係的資料結構,在資料系統中通常被用於處理大量文本的檢索問題。本文通過以下樣本,展示倒排索引如何提升文本的檢索效能。
現有一張資料表Document,存放了一系列的文本Text,同時每條文本都有一個對應的編號ID,該表的結構如下:
Document | |
ID | Text |
1 | 這是一條中文測試文本 |
2 | 中文分詞外掛程式的使用 |
3 | 資料庫全文檢索索引 |
4 | 基於中文的全文檢索索引 |
當您想尋找出所有包含中文詞語的文本,在這個資料結構下需要逐條檢索Text的全部內容。當資料量大時,查詢代價將很大。而通過建立倒排索引可以解決此問題,其索引結構包含每條文本中的詞語及詞語對應出現的文本位置。一個可能的倒排索引資料結構如下:
Term | ID |
中文 | 1,2,4 |
全文 | 3,4 |
資料庫 | 3 |
文本 | 1 |
... | ... |
通過這個資料結構,在尋找所有包含中文文本時將非常簡單,可根據索引資訊直接定位文本ID,避免了大量的文本資料掃描。
在AnalyticDB PostgreSQL版中,提供GIN(Generalized Inverted Index,通用倒排索引)功能,可以有效提升tsvector類型的查詢效能。
CREATE INDEX text_idx ON document USING GIN (to_tsvector('zh_cn',text));