AnalyticDB for MySQL在前端接入節點接收到查詢請求後,會將查詢切分成多個Stage,在儲存節點(Worker節點)和子任務執行節點(Executor節點)分布式進行資料的讀取和計算。部分Stage可以並存執行,但部分Stage之間存在依賴關係,只能串列執行,導致一些複雜SQL語句的查詢耗時問題難以分析,您可以調用API或通過控制台使用Stage和Task詳情進行慢查詢問題分析。本文主要介紹如何使用Stage和Task詳情分析查詢。
操作步驟
登入雲原生資料倉儲AnalyticDB MySQL控制台,在左上方選擇叢集所在地區。在左側導覽列,單擊集群清單。在集群清單上方,選擇產品系列,然後單擊目的地組群ID。
在左側導覽列,單擊診斷最佳化。
在SQL列表地區,單擊診斷。
單擊Stage&Task詳情,查看目標Stage的詳細資料。Stage的查詢結果說明,請參見Stage查詢結果說明。

如果是慢查詢,單擊目標StageID,查看目標Stage下所有Task的詳細資料。Task的查詢結果說明,請參見Task查詢結果說明。
重要僅耗時超過1秒的查詢支援查看Task詳細資料。
列表欄位說明
Stage列表欄位說明
欄位 | 說明 |
StageID | Stage的唯一標識,和執行計畫樹中的StageID對應。 |
狀態 | Stage的執行狀態。取值:
|
Stage輸入行數 | Stage的輸入資料行數。 |
Stage輸入資料量 | Stage的輸入資料大小。 |
Stage輸出行數 | Stage的輸出資料行數。 |
Stage輸出資料量 | Stage的輸出資料大小。 |
峰值記憶體 | Stage的記憶體最大值。 |
累計耗時 | Stage所有運算元消耗的時間之和。 該欄位可以初步定位耗時較高的Stage,也可以協助定位CPU消耗較高的Stage。累積耗時不能與查詢耗時直接比較,需要結合Stage的並行度判斷查詢耗時和累計耗時是否有關。 |
Task列表欄位說明
欄位 | 說明 |
TaskID | Task的唯一標識。 例如: |
狀態 | Task的執行狀態。取值:
|
Task輸入資料量 | Task的輸入資料量,包括輸入行數和輸入資料大小。 對輸入資料量進行排序,可以查看Stage的輸入資料是否存在資料扭曲。如果存在資料扭曲,說明分組查詢的分組欄位或Join條件欄位存在資料扭曲,需要追溯到當前Task所屬的Stage的上遊Stage進一步定位問題。 說明 資料扭曲即分布欄位設定不合理,導致資料在Worker節點上分布不均衡。 |
Task輸出資料量 | Task的輸出資料量,包括輸出行數和輸出資料大小。 根據當前Stage運算元計劃樹中的彙總節點(Aggregation)或Join節點的屬性,對應到具體的SQL語句,判斷分區欄位或者Join條件欄位中是否存在某些欄位組合。例如: |
峰值記憶體 | Task執行過程中的記憶體最大值。 峰值記憶體和輸入資料大小成正比,峰值記憶體可以判斷某些節點是否存在記憶體使用量極不均衡導致查詢失敗的問題。 |
表資料讀取耗時 | 當某個Stage的運算元樹中有表掃描節點(TableScan)時,表示該Stage的所有表掃描節點在讀取表資料時的耗時累加值。 表資料讀取耗時是一個多機多線程的累加值,不能直接和查詢耗時比較。與累計耗時比較時,可以判斷一個Stage的計算量是否消耗在資料掃描上。 |
表資料讀取量 | 當某個Stage的運算元樹中有表掃描節點(TableScan)時,表示該Stage的所有表掃描節點從源表讀取的資料行數和資料大小。 對該欄位進行排序,可以判斷源表資料是否存在資料扭曲。如果存在資料扭曲,您可以通過控制台進行分布欄位傾斜診斷,具體操作,請參見儲存空間診斷。 |
建立時間 | Task的建立時間。 |
排隊時間 | Task在真正開始執行前的排隊時間。 |
結束時間 | Task執行結束時間。 |
開始結束時間差 | Task結束時間和Task建立時間兩個絕對時間的時間差。例如:Task的建立時間是2022-12-12 12:00:00,結束時間是2022-12-12 12:00:04,則開始結束時間差為4s。 開始結束時間差與查詢耗時比較,可以確定耗時瓶頸發生的位置。例如:查詢耗時是6s,開始結束時間差是4s,則耗時瓶頸發生在當前Stage。詳細的計算方法,請參見Task耗時與並發度計算樣本。 |
累計耗時 | Stage中所有Task任務的所有線程耗時的累加。詳細的計算方法,請參見Task耗時與並發度計算樣本。 |
計算時間佔比 | 實際處理資料的耗時在子任務生命週期中的比例。 計算公式為:計算時間佔比=(累積耗時/子任務並發度)/開始結束時間差。其中,(累積耗時/子任務並發度)表示每個線程實際處理資料平均耗時,開始結束時間差包含實際處理資料的時間、子任務排隊耗時、網路等待延遲等。詳細的計算方法,請參見Task耗時與並發度計算樣本。 說明 開始結束時間差越大,計算時間佔比越小,需要重點定位耗時的運算元;開始結束時間差越小,計算時間佔比越大,需要重點定位資源等待、網路延遲等問題。 |
子任務並發度 | 每個Task在單機內是多線程並發執行的,同時執行計算任務的線程數就是子任務的並發度。詳細的計算方法,請參見Task耗時與並發度計算樣本。 |
執行節點 | Task實際執行的內部節點IP地址。如果多個查詢都在相同的節點出現長尾現象,需要重點定位某個節點問題。 說明 長尾現象即在AnalyticDB for MySQL分布式執行任務時,某些Task任務執行的時間遠大於其他Task任務的執行時間。 |
Task耗時與並發度計算樣本
以Task2.1為例,介紹Task任務開始結束時間差、累加耗時、計算時間佔比和子任務並發度的計算方法。
假設Task2.1所在的Stage[2]包含四個運算元:StageOutput、Join、TableScan、RemoteSource。運算元樹形圖如下所示。
運算元樹形圖在多個節點上按箭頭方向並存執行,其中Task2.1在192.168.12.23上有4個線程並發的執行,分別為線程1、線程2、線程3、線程4,處理資料耗時分別為5s、5s、6s、6s。如下圖所示:
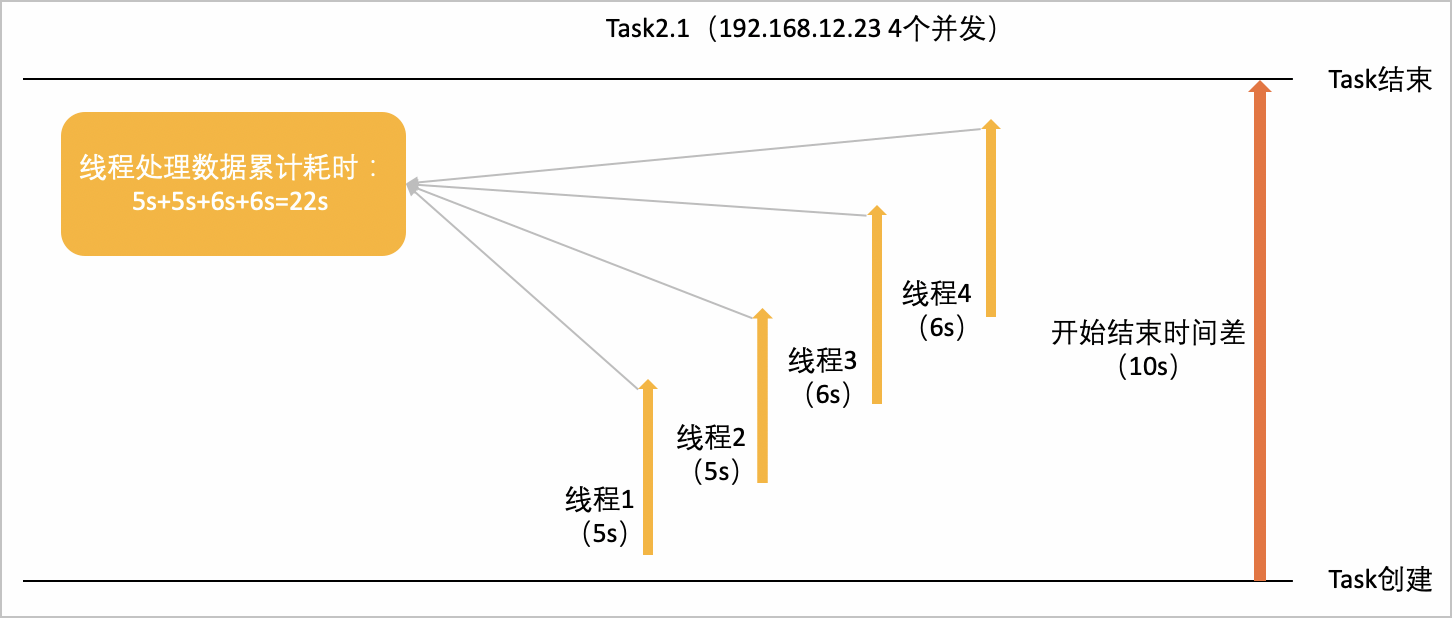
Task的累積耗時:所有線程耗時的累加,即5s+5s+6s+6s=22s。
開始結束時間差:10s。
計算時間佔比:計算時間佔比=(累積耗時/子任務並發度)/開始結束時間差,即(22s/4)/10s=0.55。
相關API
API | 描述 |
擷取SQL執行詳情。 | |
擷取指定查詢ID和Stage ID的分布式子任務執行詳情。 |