本文介紹了如何開發AnalyticDB for MySQL Spark Python作業,提供雲端環境構建方案。
前提條件
叢集的產品系列為企業版、基礎版或湖倉版。
叢集與OSS儲存空間位於相同地區。
已在企業版、基礎版或湖倉版叢集中建立Job型資源群組。
已建立AnalyticDB for MySQL叢集的資料庫帳號。
如果是通過阿里雲帳號訪問,只需建立高許可權帳號。
如果是通過RAM使用者訪問,需要建立高許可權帳號和普通帳號並且將RAM使用者綁定到普通帳號上。
PySpark的基本用法
編寫如下樣本程式,並將樣本程式儲存為
example.py。from pyspark.sql import SparkSession if __name__ == "__main__": spark = SparkSession.builder.getOrCreate() df = spark.sql("SELECT 1+1") df.printSchema() df.show()將
example.py程式上傳到OSS中。具體操作,請參見控制台上傳檔案。進入Spark開發編輯器。
登入雲原生資料倉儲AnalyticDB MySQL控制台,在左上方選擇叢集所在地區。在左側導覽列,單擊集群清單,然後單擊目的地組群ID。
在左側導覽列,單擊 。
在編輯器視窗上方,選擇Job型資源群組和Spark作業類型。本文以Batch類型為例。
在編輯器中執行以下作業內容。
{ "name": "Spark Python Test", "file": "oss://testBucketName/example.py", "conf": { "spark.driver.resourceSpec": "small", "spark.executor.instances": 1, "spark.executor.resourceSpec": "small" } }參數說明請參見參數說明。
使用Python依賴
在運行 Python 作業(PySpark)時,通常需要安裝 Pandas、Numpy 等第三方庫。本文將提供兩種無需本地打包的雲端環境構建方案。
方案類型 | 適用情境 | 方案優缺點 |
即時安裝 |
| 優點:配置簡單,即配即用。 缺點:每次運行都要重新下載安裝依賴。 |
雲端構建 |
| 優點:一次打包,永久複用;運行時啟動快,穩定性高。 缺點:需要額外運行一次打包任務。 |
前提條件
在配置雲端環境之前,請確保滿足以下條件:
叢集狀態:叢集已初始化,且能夠成功運行基礎的 Spark Pi 樣本。
版本要求:
Spark 版本:支援 3.5.1。
Python 版本:支援 3.9 或 3.11。
關鍵約束(Numpy 版本):
Apache Spark 必須運行在 numpy < 2.0.0 的環境下。
系統會強制固定安裝 numpy==1.26.0。
操作注意:請確保您要安裝的其他依賴包(如 Pandas、Scipy 等)能相容 Numpy 1.26.0,否則任務會報錯。
操作樣本
即時安裝
準備業務代碼
編寫 Python 指令碼(例如 job.py),並將其上傳到 OSS 路徑,例如
oss://your-bucket/scripts/job.py。# 樣本指令碼,會列印出當前python環境中的所有依賴。 # print all modules in python environment import pkgutil if __name__ == "__main__": for module_info in pkgutil.iter_modules(): print(module_info.name)配置作業參數
## 樣本作業 { "file": "oss://your-bucket/scripts/job.py", // 代碼路徑 "name": "Real-time Env Demo", "conf": { "spark.adb.version": "3.5", "spark.driver.resourceSpec": "medium", "spark.executor.instances": 1, "spark.executor.resourceSpec": "medium", // --- 核心配置開始 --- // 1. 設定 Python 版本 "spark.kubernetes.driverEnv.PYTHON_BIN": "python3.11", "spark.executorEnv.PYTHON_BIN": "python3.11", // 2. 設定需要安裝的依賴包 (Driver 和 Executor 都要配) "spark.kubernetes.driverEnv.PYTHON_MODULES": "chinesecalendar>=1.10.0,pandas>=1.5.3,lunar_python", "spark.executorEnv.PYTHON_MODULES": "chinesecalendar>=1.10.0,pandas>=1.5.3,lunar_python" // --- 核心配置結束 --- } }重要Spark 分為 Driver(控制節點)和 Executor(執行節點)。為了保證環境一致,必須同時為這兩者配置相同的環境變數。
參數
參數說明
是否必填
預設值
備忘
spark.kubernetes.driverEnv.PYTHON_MODULES
需要安裝的包名列表。
是
無
多個Python依賴使用逗號隔開。
python依賴的格式需要完全符合
PyPI社區要求的格式。沒有版本約束的Python依賴必須放置在最後。
樣本:
chinesecalendar>=1.10.0,dynaconf>=3.2.10,pandas>=1.5.3,lunar_pythonspark.executorEnv.PYTHON_MODULES
spark.kubernetes.driverEnv.PYTHON_BIN
指定使用的Python版本。
否
python3.11
當前有兩個可選項:
python3.11
python3.9
spark.executorEnv.PYTHON_BIN
spark.kubernetes.driverEnv.INDEX_URL
指定
PyPI倉庫的地址。否
http://mirrors.cloud.aliyuncs.com/pypi/simple/
預設值為阿里雲內部託管鏡像的地址,可以使用阿里雲內網訪問。如果配置為公網才能訪問的地址,如清華大學的PyPI鏡像源,需配置公網訪問能力,詳情請參見Spark應用訪問公網配置說明。
spark.executorEnv.INDEX_URL
spark.kubernetes.driverEnv.TRUSTED_HOST
指定
PyPI倉庫的網域名稱為可信任網域名稱。否
mirrors.cloud.aliyuncs.com
當Python從PyPI倉庫安裝依賴包時,會對倉庫的認證進行可信驗證。如果指定的倉庫認證沒有被認證服務託管,可以通過此參數指定此倉庫源是一個可信源。
重要在使用此參數時,請務必確認配置的PyPI源是可信的。PyPI源注入汙染依賴包攻擊是非常常見的攻擊方式。
spark.executorEnv.TRUSTED_HOST
執行樣本作業。可以查看日誌資訊中列印出來Python環境中,包含了聲明的依賴及其級聯依賴。
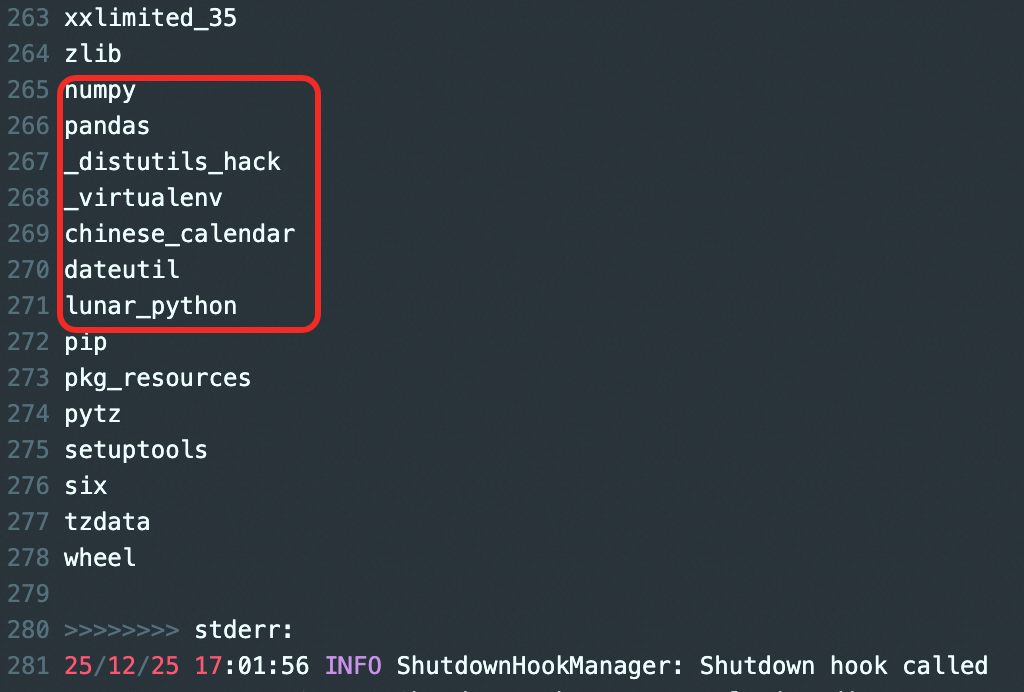
雲端構建
此方案會啟動一個特殊任務:將依賴包打成壓縮檔上傳到 OSS,供後續任務重複使用。
規劃 OSS 路徑
確定一個 OSS 路徑用於存放打好的包,例如:
oss://your-bucket/envs/my_custom_env。提交打包作業
重要請勿修改內建打包指令碼路徑
local:///opt/tools/build_venv.py。args中填入需要安裝的依賴。
## 樣本作業 { // 1. 這裡填寫需要打包的所有依賴 "args": [ "chinesecalendar>=1.10.0", "pandas>=1.5.3", "pyarrow>=19.0.1", "lunar_python" ], // 2. 調用內建打包指令碼 (不要修改) "file": "local:///opt/tools/build_venv.py", "name": "Build VirtualEnv Job", "conf": { "spark.driver.resourceSpec": "medium", "spark.executor.instances": 1, "spark.executor.resourceSpec": "medium", // 3. 指定 Python 版本 "spark.kubernetes.driverEnv.PYTHON_BIN": "python3.11", // 4. 指定打包結果上傳到哪裡(按實際路徑修改) "spark.kubernetes.driverEnv.VENV_OSS_PATH": "oss://your-bucket/envs/my_custom_env", // 5. 指定構建時的臨時目錄 "spark.kubernetes.driverEnv.VENV_DIR": "/tmp/build_test" } }參數
參數說明
是否必填
預設值
備忘
spark.kubernetes.driverEnv.VENV_OSS_PATH
環境包儲存路徑。
是
無
樣本:
oss://your-bucket/envs/my_custom_env。spark.kubernetes.driverEnv.VENV_DIR
臨時構建目錄。
否
/tmp/venv
若環境包體積較大,建議掛載資料盤並修改此路徑為:
/user_data_dir。spark.kubernetes.driverEnv.PYTHON_BIN
指定使用的Python版本。
否
python3.11
當前有兩個可選項:
python3.11
python3.9
spark.kubernetes.driverEnv.INDEX_URL
指定
PyPI倉庫的地址。否
http://mirrors.cloud.aliyuncs.com/pypi/simple/
預設值為阿里雲內部託管鏡像的地址,可以使用阿里雲內網訪問。如果配置為公網才能訪問的地址,如清華大學的PyPI鏡像源,需配置公網訪問能力,詳情請參見Spark應用訪問公網配置說明。
spark.kubernetes.driverEnv.TRUSTED_HOST
指定
PyPI倉庫的網域名稱為可信任網域名稱。否
mirrors.cloud.aliyuncs.com
當Python從PyPI倉庫安裝依賴包時,會對倉庫的認證進行可信驗證。如果指定的倉庫認證沒有被認證服務託管,可以通過此參數指定此倉庫源是一個可信源。
重要在使用此參數時,請務必確認配置的PyPI源是可信的。PyPI源注入汙染依賴包攻擊是常見的攻擊方式。
執行作業
可以查看日誌資訊中上傳壓縮包的資訊,以及這個virtualenv中所有安裝包的詳細的版本說明。
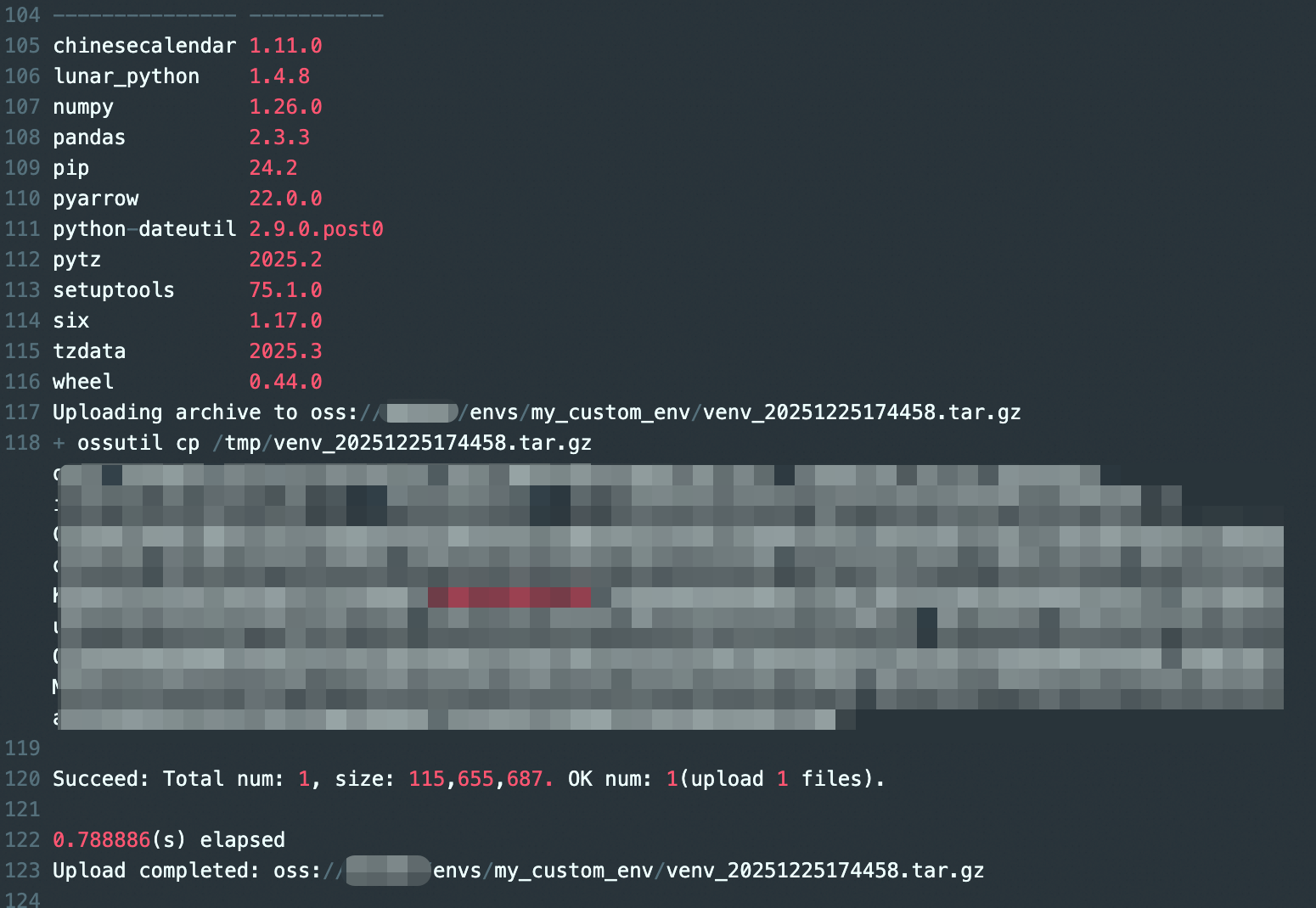
使用環境包
後續您在運行普通 PySpark 任務時,即可引用
oss://your-bucket/envs/my_custom_env中的壓縮包。通過配置
pyFiles參數進行使用。## 使用樣本 { "name": "Spark Python", "file": "oss://testBucketName/example.py", "pyFiles": ["oss://your-bucket/envs/my_custom_env/venv_*****.tar.gz"], "args": [ "oss://testBucketName/staff.csv" ], "conf": { "spark.driver.resourceSpec": "small", "spark.executor.instances": 2, "spark.executor.resourceSpec": "small" } }
常見問題排查
報錯 ModuleNotFoundError:
檢查是否同時配置了
driverEnv和executorEnv。檢查包名拼字是否符合 PyPi 規範。
報錯與 numpy 相關:
檢查您的依賴包版本是否要求 numpy >= 2.0.0。如果是,請降級您的依賴包版本以適配 numpy 1.26.0。
下載逾時:
如果使用預設內網源仍然逾時,請檢查是否配置了公網源但未開通公網存取權限。