玄武分析型儲存引擎為使用者提供高可靠、高可用、高效能、低成本的企業級資料存放區能力,是AnalyticDB for MySQL實現高吞吐即時寫入、高效能即時查詢的基礎支撐。
玄武分析型儲存引擎(XUANWU)
高吞吐即時寫入
AnalyticDB for MySQL通過三層並行架構實現了極強的吞吐能力,從接入層、到儲存節點層再到持久分布式儲存層,都可以並行擴充,再結合行列混合儲存引擎,增量和全量的非同步轉換實現了高吞吐、高並發即時寫入。
在即時可見度方面,AnalyticDB for MySQL通過Raft一致性協議+同步寫入Apply的方式,實現了寫入立即可查,保證寫入一致性。儲存引擎上Mark-for-delete技術實現了高輸送量的即時更新和刪除,同時基於MVCC的技術保證資料原子性和完整性。
行列混合儲存
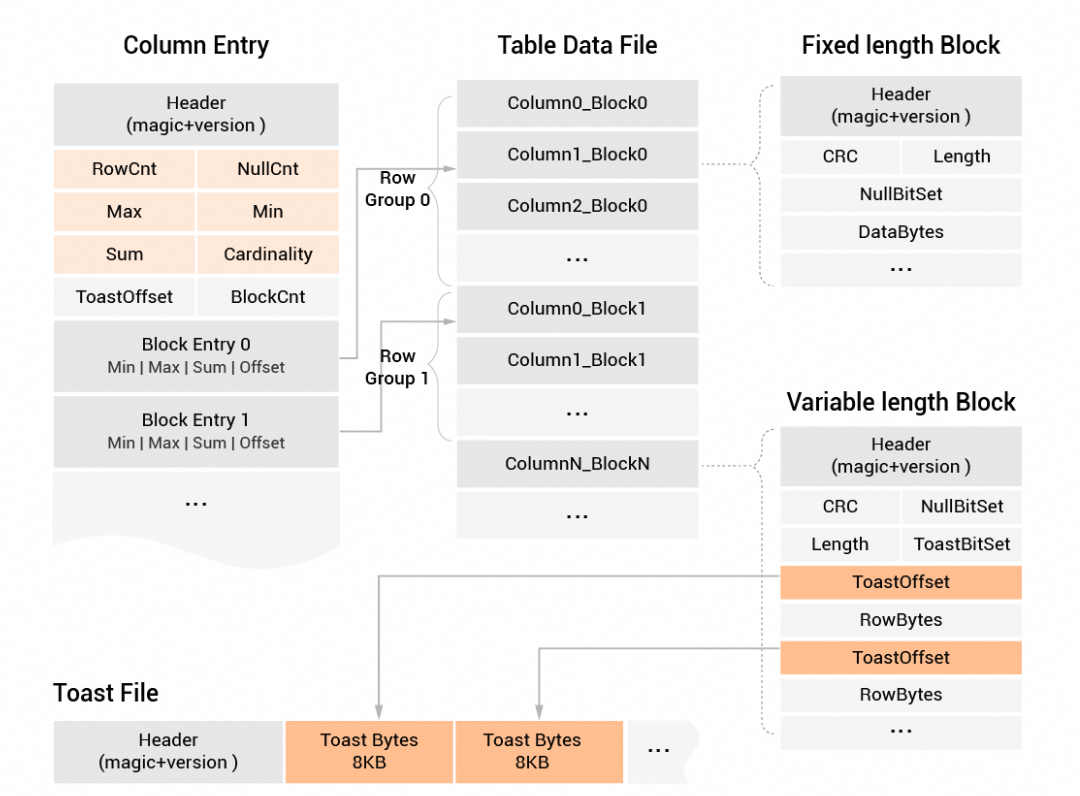
玄武儲存引擎支援行列混存的儲存格式,其中行列混存是一種以列存為基礎兼顧行存的模式,類似於Hadoop中的ORC/Parquet格式。不同的是玄武的行列混存不僅兼顧分析類的列裁剪和大吞吐掃描效能,而且結合其行對齊的能力,可以實現很好的隨機尋找效能,這對於任意多維索引過濾的情境也擁有出色的效能優勢。
行列混存的儲存格式如下:
自適應索引
OLAP情境下需要支援任意維度查詢,傳統的OLTP單列或複合式索引難以滿足該需求。玄武採用了自適應列級自動索引技術,針對字串、數字、文本、JSON、向量等列類型都有自動設定的索引資料結構,並且可以做到列級索引任意維度組合檢索、多路漸進流式歸併,大幅提升了資料過濾效能。
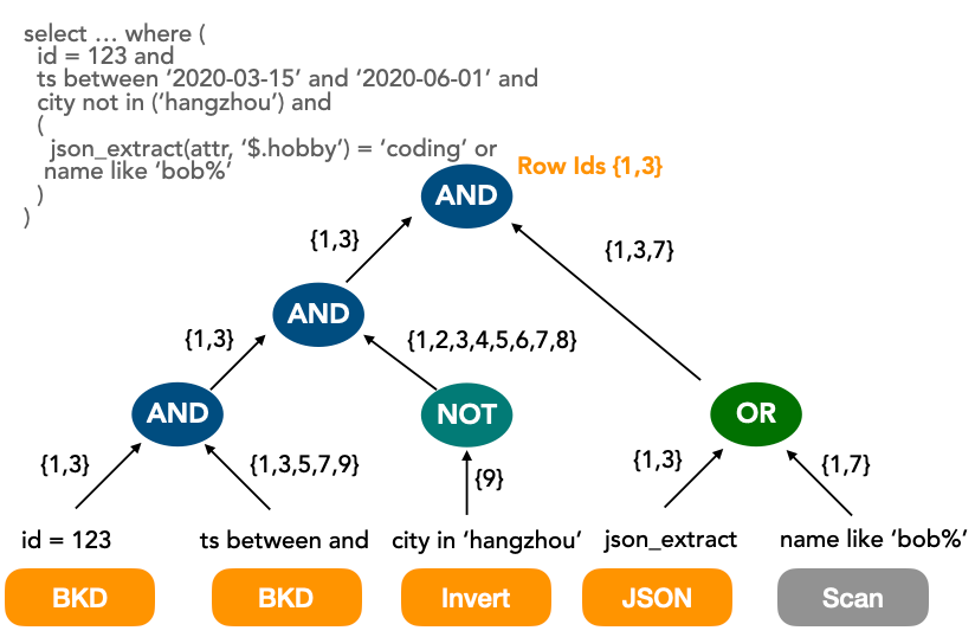
目前索引類型主要有:倒排索引、BKD-Tree索引和Bitmap索引。同時索引的效能主要受資料分布特徵影響,包括:cardinality(散列程度),範圍查詢的記錄數/表記錄數。在某些情況下,例如age > 0 and age <100這種查詢走索引的開銷反而比掃描高。因此玄武基於CBO智能選擇索引或掃描。
多種索引類型多路歸併尋找的過程如下所示:
結構化與非結構化融合
玄武儲存層索引管理器實現結構化索引與非結構化索引的統一管理,如數值類的BKD索引、字串類的倒排索引、非結構化的JSON索引及向量索引,還有文本資料的全文索引。對計算層提供統一的運算式,使得計算層的SQL邏輯相容異構資料類型,同時都得到索引加速。因此AnalyticDB for MySQL實現了全文資料與結構化表之間的關聯分析,SQL表達的複雜邏輯都能夠統一支援。如下圖所示:

SQL語義說明:對子查詢裡的全文檢索索引的結果集進行關聯分析,分析後的結果按照打分值降序排列,輸出前10,000行。
玄武分析型儲存引擎V2(XUANWU_V2)
AnalyticDB for MySQL基於原玄武分析型儲存引擎迭代研發出新一代儲存引擎XUANWU_V2。
高效的資料群組織方式
XUANWU_V2最佳化了資料群組織方式。資料以Append方式寫入即時引擎,經過Flush任務,再寫入讀友好的全量引擎中。隨後,通過Compaction任務全量引擎層級內或層級間的合并,確保L0以下層級的分區有序,並按照固定大小進行資料物理組織。
資料群組織方式如下圖所示:
該資料群組織方式可以保證即時引擎能及時的構建為讀友好的全量引擎,提高查詢效能。同時,它顯著改善了Compaction過程的讀放大問題,進一步降低了Compaction過程中的CPU和IO消耗。此外,在這種組織方式下,XUANWU_V2可以自適應地對過大或者過小的分區檔案進行切分與合并,使用者無需再為分區鍵的選擇而困擾。
高效的儲存格式
XUANWU_V2在原有按固定行數組織的列級IO塊基礎上,引入了按固定大小組織IO塊的檔案格式。這種固定大小的IO塊組織方式,不僅最佳化了IO和記憶體管理,解決了因行對齊與IO大小不一致所引發的一系列問題,也提高了記憶體複用效率,降低了記憶體申請與回收的開銷。通過對齊記憶體與IO操作,進一步減少了讀放大的現象,進而降低了IO成本。
更好的水平擴容彈性
XUANWU_V2將所有資料存放區在OSS中,不僅顯著降低了使用者儲存成本,還大幅提升了水平擴縮容和節點遷移的效率。XUANWU_V2採用ESSD雲端硬碟作為查詢快取,支援DDL指定分區預熱和查詢自動緩衝兩種形式,有效提升了查詢效能。