Apache Hudi是一個支援插入、更新、刪除的資料湖架構,通常用於基於Object Storage Service構建低成本Lakehouse。同時Apache Hudi還支援多版本的⽂件管理協議,提供⼊湖和分析過程中的增量資料即時寫⼊、ACID事務、小⽂件⾃動合并最佳化、元資訊校正和Schema演化、⾼效的列式分析格式、⾼效的索引最佳化、超⼤分區表格儲存體等能⼒。
AnalyticDB MySQL團隊基於Apache Hudi構建低成本Lakehouse的方案,完全相容開源Hudi生態。開通AnalyticDB MySQL服務後只需簡單配置即可基於OSS儲存和Hudi構建Lakehouse,如通過APS服務將Kafka/SLS日誌型資料准即時入湖,或利用AnalyticDB MySQL Serverless Spark引擎將RDS/Parquet離線資料批量入湖。方案架構圖如下所示: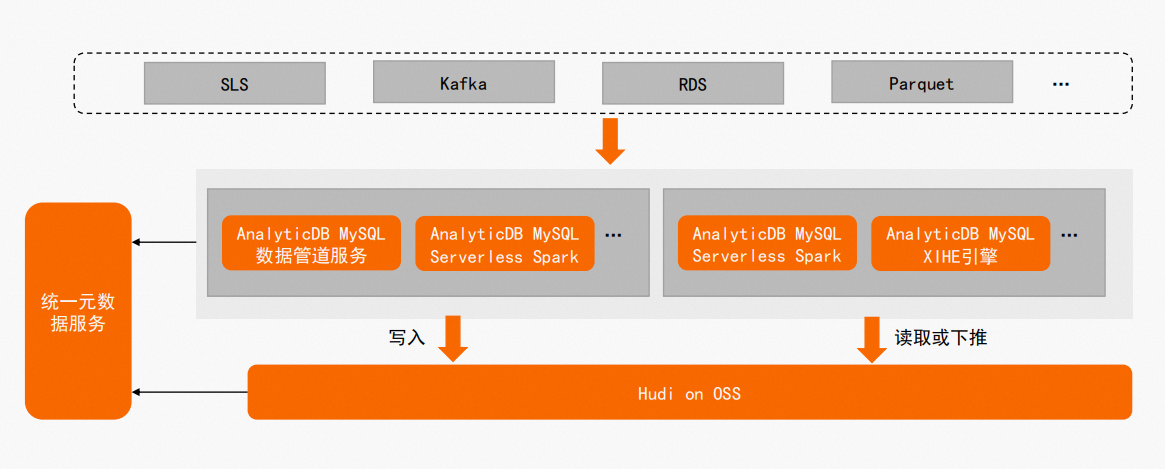
AnalyticDB MySQL與Apache Hudi進行深度整合并對Hudi核心做了深度改造,相對於開源Hudi方案,具有以下優勢:
使用門檻低
- 通過APS白屏化配置即可支援資料快速寫入Hudi,同時AnalyticDB MySQL和Hudi屏蔽了對接Spark的繁瑣配置,開箱即用。
高效能寫入
- 物件導向儲存OSS寫入進行深度最佳化。在典型日誌情境中,相較於開源方案寫OSS效能提升1倍以上;同時支援熱點資料自動打散,解決資料扭曲問題,大幅提升寫入穩定性。
分區級生命週期管理
- 支援設定多種策略,如按分區數、按資料量和按到期時間策略管理分區資料生命週期,同時支援並發設定生命週期管理原則,進一步降低儲存成本。
非同步Table Service
- 支援非同步Table Service服務,與寫入鏈路完全隔離,對寫入鏈路無任何影響,同時通過非同步Table Service如Clustering提升查詢效能,典型情境下查詢效能提升至原來的40%以上。
中繼資料自動同步
- 藉助AnalyticDB MySQL統一中繼資料服務,資料寫入Hudi後可通過AnalyticDB MySQL Serverless Spark和XIHE引擎無縫訪問,無需手動同步表中繼資料,一份入湖資料支援上層多個計算引擎。