物化視圖常用來加速複雜查詢或者簡化ETL流程,其本質是將使用者定義的查詢提前計算好,按使用者要求重新整理視圖中的資料。您可以根據基表的寫入模式、物化視圖查詢(query_body)的SQL計算複雜度,以及對物化視圖資料時效性的預期,定義物化視圖的重新整理策略。
如何選擇重新整理策略
物化視圖支援兩種重新整理策略——全量重新整理(COMPLETE)和增量重新整理(FAST)。
全量重新整理,即每次重新整理時運行原始的查詢SQL,掃描基表的全部目標資料分割的資料,用計算好的新資料全量覆蓋舊資料。
增量重新整理,即改寫物化視圖的查詢(query_body),使物化視圖只掃描基表變更的部分資料,加工後寫入物化視圖,從而避免每次都掃描基表的全部資料,降低單次重新整理的計算開銷。
兩種重新整理策略的適用情境、優勢和限制對比如下。
重新整理策略 | 適用情境 | 特點 |
全量重新整理 | 離線情境:
| 優勢:query_body支援任意SQL查詢。 |
限制:只能批次更新全量資料。 | ||
增量重新整理 | 即時情境:
| 優勢:
|
限制:
|
如何選擇重新整理觸發機制
建立物化視圖時,不僅需要定義重新整理策略,還需要定義如何觸發重新整理,即重新整理的觸發機制。物化視圖重新整理觸發機制分為按需重新整理(ON DEMAND)和基表被INSERT OVERWRITE覆寫後自動重新整理(ON OVERWRITE)。其中,按需重新整理又分為定時自動重新整理和手動重新整理。如果未指定重新整理觸發機制,則預設為按需重新整理。
選擇重新整理觸發機制時,需要考慮物化視圖的資料時效性和叢集負載。不同觸發機制的特點和適用情境如下:
手動重新整理:物化視圖不主動重新整理資料。使用者需要執行
REFRESH MATERIALIZED VIEW來手動重新整理資料。適用於對資料一致性要求不高或資料不經常變動的情境。定時自動重新整理:物化視圖將在指定時間自動重新整理資料。如果到達指定的重新整理時間,上次重新整理還未完成,將自動跳過此次重新整理,等到下一個重新整理時間再重新整理。適用於基表資料定期變化的情境,例如每日、每周固定時間段內會產生新的交易記錄。
基表被INSERT OVERWRITE覆寫後自動重新整理:物化視圖將在基表被INSERT OVERWRITE覆蓋寫時自動重新整理。適用於對資料即時性和一致性要求較高的情境。
不同重新整理策略支援不同的重新整理觸發機制,具體如下:
重新整理策略 | 按需重新整理(ON DEMAND) | 基表被覆蓋寫時自動重新整理(ON OVERWRITE) | |
手動重新整理 | 定時自動重新整理(定義NEXT參數值) | ||
全量重新整理 | ✔️ | ✔️ | ✔️ |
增量重新整理 | ❌ | ✔️ | ❌ |
定義物化視圖的重新整理策略和觸發機制
下文以customer表、sales表和product表為例,指導您在建立物化視圖時定義重新整理策略和重新整理觸發機制。
/*+ RC_DDL_ENGINE_REWRITE_XUANWUV2=false */ -- 指定表的引擎為XUANWU引擎。
CREATE TABLE customer (
customer_id INT PRIMARY KEY,
customer_name VARCHAR(255),
is_vip Boolean
);/*+ RC_DDL_ENGINE_REWRITE_XUANWUV2=false */ -- 指定表的引擎為XUANWU引擎。
CREATE TABLE sales (
sale_id INT PRIMARY KEY,
product_id INT,
customer_id INT,
price DECIMAL(10, 2),
quantity INT,
sale_date TIMESTAMP
);/*+ RC_DDL_ENGINE_REWRITE_XUANWUV2=false */ -- 指定表的引擎為XUANWU引擎。
CREATE TABLE product (
product_id INT PRIMARY KEY,
product_name VARCHAR,
category_id INT,
unit_price DECIMAL(10, 2),
stock_quantity INT
);建立全量重新整理的物化視圖
建立物化視圖時,通過關鍵字REFRESH COMPLETE指定物化視圖的重新整理策略為全量重新整理。
全量重新整理的物化視圖支援的重新整理模式包括手動重新整理、定時自動重新整理、基表被INSERT OVERWRITE覆蓋寫時自動重新整理。
建立全量重新整理的物化視圖compl_mv1。該物化視圖未定義重新整理模式和NEXT參數,因此採用預設的重新整理觸發機製為按需重新整理,且為手動重新整理。
CREATE MATERIALIZED VIEW compl_mv1 REFRESH COMPLETE AS SELECT * FROM customer;建立全量重新整理的物化視圖compl_mv2。該物化視圖定義了按需重新整理(ON DEMAND),且定義了首次(START WITH)和下次(NEXT)的重新整理時間。本例每天淩晨2點自動重新整理。
CREATE MATERIALIZED VIEW compl_mv2 REFRESH COMPLETE ON DEMAND START WITH DATE_FORMAT(now() + interval 1 day, '%Y-%m-%d 02:00:00') NEXT DATE_FORMAT(now() + interval 1 day, '%Y-%m-%d 02:00:00') AS SELECT * FROM customer;建立全量重新整理的物化視圖compl_mv3。該物化視圖定義了基表被INSERT OVERWRITE覆寫時自動重新整理(ON OVERWRITE),此重新整理模式無需定義下次重新整理時間(NEXT)。
CREATE MATERIALIZED VIEW compl_mv3 REFRESH COMPLETE ON OVERWRITE AS SELECT * FROM customer;
建立增量重新整理的物化視圖
建立物化視圖時,通過關鍵字REFRESH FAST指定物化視圖的重新整理策略為增量重新整理。增量重新整理的物化視圖僅支援定時自動重新整理。
開啟Binlog特性
在建立增量重新整理的物化視圖前,需先開啟叢集的Binlog特性開關以及基表的Binlog功能。
SET ADB_CONFIG BINLOG_ENABLE=true; --3.2.0.0以下版本叢集需執行該命令手動開啟Binlog特性。3.2.0.0及以上版本預設開啟。
ALTER TABLE customer binlog=true;
ALTER TABLE sales binlog=true;
ALTER TABLE product binlog=true;對於開啟Binlog功能的表,僅3.2.0.0及以上核心版本才支援INSERT OVERWRITE INTO和TRUNCATE操作。
增量重新整理的物化視圖建立完成後,不允許關閉基表的Binlog功能。
刪除增量重新整理的物化視圖後,可以執行
SET ADB_CONFIG BINLOG_ENABLE=false;和ALTER TABLE <table_name> binlog=false;手動關閉Binlog特性和基表的Binlog功能。
單表物化視圖
建立無彙總操作的增量重新整理的單表物化視圖fast_mv1,每10秒鐘重新整理一次,
CREATE MATERIALIZED VIEW fast_mv1 REFRESH FAST NEXT now() + INTERVAL 10 second AS SELECT sale_id, sale_date, price FROM sales WHERE price > 10;建立分組彙總操作的增量重新整理的單表物化視圖fast_mv2,每5秒鐘重新整理一次。
CREATE MATERIALIZED VIEW fast_mv2 REFRESH FAST NEXT now() + INTERVAL 5 second AS SELECT customer_id, sale_date, -- 系統會自動輸出GROUP BY列作為物化視圖主鍵。 COUNT(sale_id) AS cnt_sale_id, -- 彙總輸出資料行。 SUM(price * quantity) AS total_revenue, -- 彙總輸出資料行。 customer_id / 100 AS new_customer_id -- 非彙總輸出資料行可以使用任意運算式。 FROM sales WHERE ifnull(price, 1) > 0 -- 條件可以使用任何錶達式。 GROUP BY customer_id, sale_date;建立無分組彙總操作的增量重新整理的單表物化視圖fast_mv3,每分鐘重新整理一次。
CREATE MATERIALIZED VIEW fast_mv3 REFRESH FAST NEXT now() + INTERVAL 1 minute AS SELECT count(*) AS cnt -- 系統會自動產生常量主鍵,確保全域只有一條記錄在物化視圖中。 FROM sales;
多表物化視圖
建立無彙總操作的增量重新整理的多表物化視圖fast_mv4,每5秒鐘重新整理一次,
CREATE MATERIALIZED VIEW fast_mv4 REFRESH FAST NEXT now() + INTERVAL 5 second AS SELECT c.customer_id, c.customer_name, p.product_id, s.sale_id, (s.price * s.quantity) AS revenue FROM sales s JOIN customer c ON s.customer_id = c.customer_id JOIN product p ON s.product_id = p.product_id;建立分組彙總操作的增量重新整理的多表物化視圖fast_mv5,每10秒鐘重新整理一次。
CREATE MATERIALIZED VIEW fast_mv5 REFRESH FAST NEXT now() + INTERVAL 10 second AS SELECT s.sale_id, c.customer_name, p.product_name, COUNT(*) AS cnt, SUM(s.price * s.quantity) AS revenue, SUM(p.unit_price) AS sum_p FROM sales s JOIN (SELECT customer_id, customer_name FROM customer) c ON c.customer_id = s.customer_id JOIN (SELECT * FROM product WHERE stock_quantity > 0) p ON p.product_id = s.product_id GROUP BY s.sale_id, c.customer_name, p.product_name;
使用限制
增量重新整理的物化視圖限制如下:
核心版本為3.2.3.0以下的叢集,不支援分區表作為增量重新整理的物化視圖的基表。
核心版本為3.2.3.1以下的叢集,增量重新整理的物化視圖,基表不支援INSERT OVERWRITE和TRUNCATE,執行會報錯。
增量重新整理只支援定時自動重新整理,不允許手動重新整理。定時自動的增量重新整理,重新整理間隔最短5秒(s),最長5分鐘(min)。
增量重新整理的物化視圖,query_body有以下限制:
由於物化視圖要保證結果和您查詢基表的結果完全一致,且要支援任意DML變更,所以並不是所有query_body都可以增量重新整理。如果建立的物化視圖無法增量重新整理,建立時會報錯。
不允許出現非確定性運算式作為條件,如:
now()、rand()等。僅支援以下彙總函式:COUNT、SUM、MAX、MIN、AVG、APPROX_DISTINCT和COUNT(DISTINCT)。
當query_body中使用MAX、MIN、APPROX_DISTINCT或COUNT(DISTINCT)彙總函式時,增量物化視圖的基表只允許執行INSERT操作,禁止執行DELETE、UPDATE、REPLACE、INSERT ON DUPLICATE KEY UPDATE等會導致資料刪除的操作。
除COUNT(DISTINCT)外,其餘彙總函式均不支援DISTINCT關鍵字。
COUNT(DISTINCT)僅支援INTEGER類型。
AVG不支援DECIMAL類型。
彙總操作不支援HAVING關鍵字。
不支援視窗函數。
不支援排序操作。
不支援UNION、EXCEPT、INTERSECT等集合操作。
增量重新整理的多表物化視圖,還有以下限制:
多表物化視圖目前僅支援使用INNER JOIN。
多表物化視圖中預設最多關聯5張表。
多表物化視圖中的關聯欄位需為表的原始欄位,且關聯欄位的資料類型相同,均有INDEX索引。
手動重新整理物化視圖
如果建立物化視圖時定義的重新整理策略是按需重新整理(ON DEMAND),且未定義下次重新整理時間(NEXT),那麼物化視圖是不會自動重新整理的。您可以手動重新整理物化視圖的資料。
REFRESH MATERIALIZED VIEW <mv_name>;發起重新整理請求後,系統會將重新整理任務放入後台隊列中,您無需等待重新整理完成即可繼續執行其他動作。
返回Query OK或執行成功,說明重新整理完成。
查詢物化視圖的重新整理記錄
查詢自動重新整理記錄
通過下列SQL查詢指定物化視圖的自動重新整理記錄,包括重新整理的開始時間(start_time)、結束時間(end_time)、狀態(state)、查詢ID(process_id)。更多關於返回結果的欄位說明,請參見管理物化視圖。
SELECT * FROM information_schema.mv_auto_refresh_jobs where mv_name = '<mv_name>';查詢手動重新整理記錄
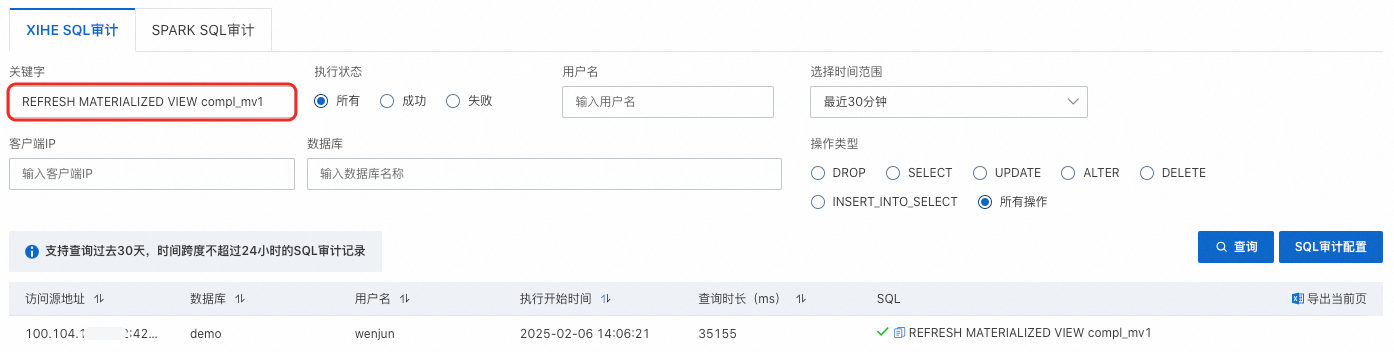
查詢過去30天的物化視圖手動重新整理記錄,可以使用SQL審計功能。查詢時,輸入關鍵字REFRESH MATERIALIZED VIEW mv_name,可查詢手動重新整理的時間、時間長度、IP、使用者名稱等資訊。
SQL審計功能需單獨開通。開通前的SQL操作,不會記錄在審計日誌中。
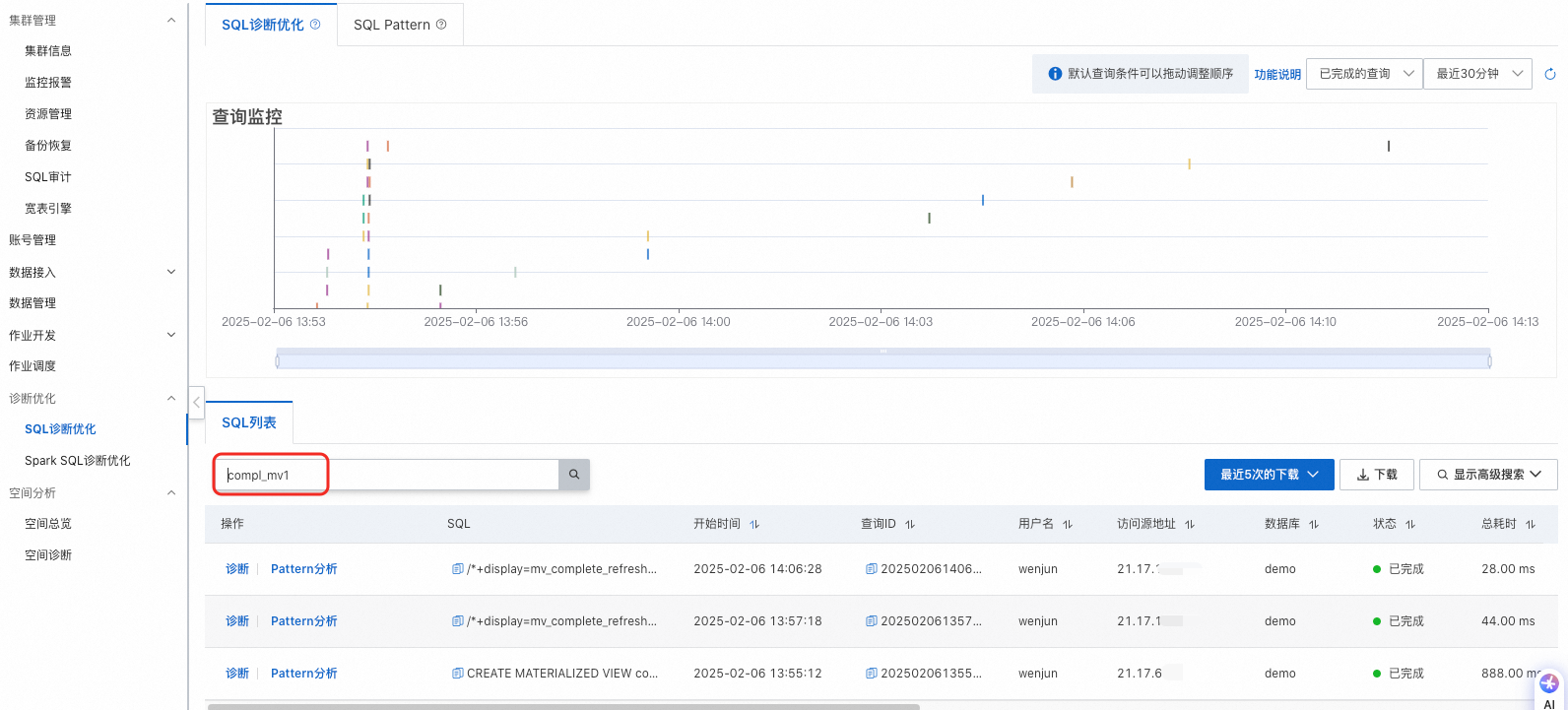
查詢過去14天的物化視圖手動重新整理記錄和自動重新整理記錄,可以使用SQL診斷最佳化功能。查詢時,輸入物化視圖的名稱,例如compl_mv1,可查詢該物化視圖的所有相關SQL查詢(包括建立、手動重新整理、自動重新整理、變更等)的開始時間、使用者名稱、耗時、查詢ID等。
停止進行中的重新整理任務
如果物化視圖重新整理時間過長,您可以聯絡支援人員停止此次重新整理任務。
注意事項
如果您已通過KILL PROCESS <process_id>;嘗試停止本次重新整理任務,需要注意的是,即使停止此次重新整理,之後在到達下次重新整理時間或者基表下次被覆蓋寫時,仍會觸發下次重新整理。
相關文檔
建立物化視圖:瞭解物化視圖的適用情境、重要特性、使用限制等。
CREATE MATERIALIZED VIEW:瞭解物化視圖的文法詳情。
管理物化視圖:如何查詢物化視圖的定義、查詢物化視圖的重新整理紀錄、變更物化視圖、刪除物化視圖等。