Argo Workflows是一個強大的工作流程管理工具,廣泛應用於定時任務、機器學習和ETL資料處理等情境,但是使用YAML定義工作流程可能會增加學習難度。Hera Python SDK提供了一種簡潔易用的替代方案,Hera允許使用者以Python代碼構建工作流程,支援複雜任務,易於測試,並與Python生態無縫整合,顯著降低了工作流程設計的門檻。本文將介紹如何使用Python SDK構建大規模Argo Workflows。
背景資訊
Argo Workflows是一個專為Kubernetes環境設計的開源工作流程管理工具,它專註於實現複雜工作流程的自動化編排。允許使用者定義一系列任務,並靈活安排這些任務的執行順序及依賴關係,Argo Workflows助力使用者高效構建和管理高度定製化的自動化工作流程。
Argo Workflows的應用情境非常廣泛,包括定時任務、機器學習、模擬計算、科學計算、ETL資料處理、模型訓練、CI/CD等。Argo Workflows主要依賴YAML來定義工作流程,這種設計目的在於實現配置的清晰與簡潔。然而,對於初次接觸或不熟悉YAML的使用者來說,面對複雜的工作流程設計時,YAML的嚴格縮排要求及層次化的結構可能會增加一定的學習曲線和配置難度。

Hera是一個專為構建和提交Argo工作流程設計的Python SDK架構,其主要目標是簡化工作流程的構建和提交,對於資料科學家而言,通過使用Python能更好地相容平時的使用習慣,克服YAML的阻礙。使用Hera PythonSDK具有以下優勢。
簡潔性:Hera提供了易於理解和編寫的代碼,大幅提升了開發效率。
支援複雜工作流程:在處理複雜工作流程時,使用Hera可以有效避免YAML可能產生的語法錯誤。
Python生態整合:每個Function就是一個Template,與Python生態中的各種架構輕鬆整合。
可測試性:可直接利用Python的測試架構,有助於提高代碼的品質和可維護性。
ACK One Serverless Argo工作流程叢集託管了Argo Workflows,其架構如下所示:

步驟一:建立並擷取叢集Token
開啟Argo Server訪問工作流程叢集,可通過以下兩種方式開啟。
開通Argo Server公網訪問。(專線使用者可選)
執行以下命令,建立並擷取叢集Token。
kubectl create token default -n default
步驟二:開啟Hera PythonSDK之旅
執行以下命令, 安裝Hera。
pip install hera-workflows編寫並提交Workflows。
情境一:Simple DAG Diamond
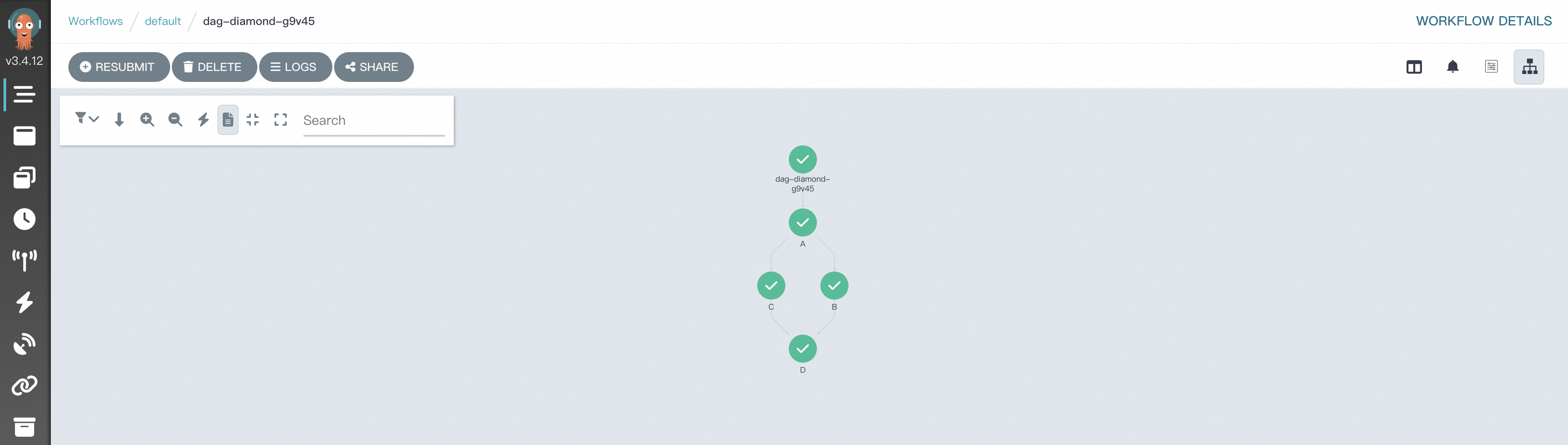
在Argo Workflows中,DAG(有向非循環圖)常用於定義複雜的任務依賴關係,其中Diamond結構是一種常見的工作流程模式,可以實現多個任務並存執行後,將它們的結果匯聚到一個共同的後續任務。這種結構在合并不同資料流或處理結果的情境中非常有效。下面是一個具體樣本,展示如何使用Hera定義一個具有Diamond結構的工作流程,其中兩個任務taskA和taskB並行運行,它們的輸出共同作為輸入傳遞給taskC。
使用以下內容,建立simpleDAG.py。
# 匯入相關包。 from hera.workflows import DAG, Workflow, script from hera.shared import global_config import urllib3 urllib3.disable_warnings() # 配置訪問地址和Token。 global_config.host = "https://argo.{{clusterid}}.{{region-id}}.alicontainer.com:2746" global_config.token = "abcdefgxxxxxx" # 填入之前擷取的Token。 global_config.verify_ssl = "" # 裝飾器函數script是Hera實現近乎原生的Python函數編排的關鍵功能。 # 它允許您在Hera上下文管理器(例如Workflow或Steps上下文)下調用該函數。 # 該函數在任何Hera上下文之外仍將正常運行,這意味著您可以在給定函數上編寫單元測試。 # 該樣本是列印輸入的資訊。 @script() def echo(message: str): print(message) # 構建workflow,Workflow是Argo中的主要資源,也是Hera的關鍵類,負責儲存模板、設定進入點和運行模板。 with Workflow( generate_name="dag-diamond-", entrypoint="diamond", ) as w: with DAG(name="diamond"): A = echo(name="A", arguments={"message": "A"}) # 構建Template。 B = echo(name="B", arguments={"message": "B"}) C = echo(name="C", arguments={"message": "C"}) D = echo(name="D", arguments={"message": "D"}) A >> [B, C] >> D # 構建依賴關係,B、C任務依賴A,D依賴B和C。 # 建立Workflow。 w.create()執行以下命令, 提交工作流程。
python simpleDAG.py工作流程運行後,您可以在工作流程控制台(Argo)查看任務DAG流程與運行結果。
情境二:Map-Reduce
在Argo Workflows中實現MapReduce風格的資料處理的關鍵在於有效利用其DAG(有向非循環圖)模板,以組織和協調多個任務,從而類比Map和Reduce階段。以下是一個更加詳細的樣本,展示了如何使用Hera構建一個簡單的MapReduce工作流程,用於處理文字檔的單詞計數任務。每一步都是一個Python函數,便於和Python生態進行整合。
使用以下內容,建立map-reduce.py。
執行以下命令,提交工作流程。
python map-reduce.py工作流程運行後,您可以在工作流程控制台(Argo)查看任務DAG流程與運行結果。

編輯方式對比
Argo Workflows的編輯方式主要包括YAML和Hera Framework。以下是這兩種方式的對比。
特性 | YAML | Hera Framework |
簡潔性 | 較高 | 高,代碼量少 |
複雜工作流程編寫難易程度 | 難 | 易 |
Python生態整合難易程度 | 難 | 易,豐富的Python Lib |
可測試性 | 難,容易出現語法錯誤 | 易,可使用測試架構 |
Hera Framework以優雅的方式將Python生態體系與Argo Workflows架構結合,使繁瑣的工作流程設計變得直觀簡明。它不僅為大規模任務編排提供了一條免受YAML複雜性困擾的通路,同時也有效串連了資料工程師與他們熟悉的Python語言,使得構建和最佳化機器學習工作流程變得無縫和高效,迅速實現創意到部署的迭代迴圈,從而推動智能應用的快速落地與持續發展。
如果您對於ACK One有任何疑問,歡迎使用DingTalk搜尋DingTalk群號35688562加入DingTalk群。
相關文檔
Hera相關文檔。
如果您需要詳細瞭解Hera相關資訊,請參見Hera概述。
若您想學習如何設定和使用Hera來進行LLM的訓練過程,請參見Train LLM with Hera。
YAML部署樣本。
如果您想瞭解以YAML的方式部署simple-diamond,請參見dag-diamond.yaml。
如果您想瞭解以YAML的方式部署map-reduce,請參見 map-reduce.yaml。