本文通過實現五個目標任務舉例說明如何在多使用者情境下使用Arena。
前提條件
請確保您已完成以下操作:
建立一個ACK叢集。詳情請參見建立ACK託管叢集。
在ACK叢集同VPC下,建立一個作業系統為Linux的ECS執行個體。具體操作步驟請參見自訂購買執行個體。
本樣本中,ECS執行個體被稱為Client機器。Client機器作為Arena的工作站,提交作業至ACK叢集。
安裝最新版本Arena。具體操作步驟請參見配置Arena用戶端。
背景資訊
當多個開發人員在一個公司或大團體下使用Arena進行工作時,為了有效管理,您可能需要對這些人員進行小組劃分,且每個小組需要彼此隔離。這樣在同一個叢集內,小組就是您分配、隔離資源和許可權的基本單元。
通常您需要將整個叢集的資源(GPU、CPU、MEM)根據具體需求劃分給每個組,並且給組內成員分配不同許可權,以及提供各自獨立的Arena使用環境。其中許可權包括:使用者對於作業的可見、可操作許可權,使用者的作業對特定資料的讀寫權限。
圖 1. 配置多使用者使用Arena的工作環境圖
本文樣本中的ACK叢集和Client機器的節點資訊如下表所示。
主機名稱 | 角色 | IP地址 | GPU卡數 | CPU核心數 | MEM |
client01 | Client | 10.0.0.97(私人)39.98.xxx.xxx(公) | 0 | 2 | 8 GiB |
master01 | Master | 10.0.0.91(私人) | 0 | 4 | 8 GiB |
master02 | Master | 10.0.0.92(私人) | 0 | 4 | 8 GiB |
master03 | Master | 10.0.0.93(私人) | 0 | 4 | 8 GiB |
worker01 | Worker | 10.0.0.94(私人) | 1 | 4 | 30 GiB |
worker02 | Worker | 10.0.0.95(私人) | 1 | 4 | 30 GiB |
worker03 | Worker | 10.0.0.96(私人) | 1 | 4 | 30 GiB |
如無特殊說明,本文操作均為叢集管理員(admin)操作,動作節點為Client機器。
目標任務
本文最佳實務的樣本中將達成以下五個目標任務:
目標一:您需要為當前ACK叢集建立兩個分組dev1和dev2,並且為這兩個分組各添加一個使用者bob和tom。
目標二:每個使用者只能通過自己的帳號和密碼登入到Client機器,使用自己環境下的Arena。
目標三:bob和tom只對自己提交的作業可見,以及進行管理。
目標四:按組劃分Worker節點GPU、CPU、MEM資源(註:僅Worker節點的計算資源才能被Arena作業使用)。
目標五:建立組內共用的資料卷,和組與組之間全域共用的資料卷。
表 1. 資料配置表
組名 | 使用者 | GPU | CPU | MEM | 共用資料卷 |
dev1 | bob | 1 | 不限制 | 不限制 | dev1-public和department1-public-dev1 |
dev2 | tom | 2 | 8 | 60 GiB | dev2-public和department1-public-dev2 |
department1-public-dev1和department1-public-dev2資料卷指向的是同一份資料;組dev1和dev2為所有使用者共用;dev1-public和dev2-public分別對應分組dev1、dev2使用者獨享的資料。
步驟一:建立和管理ACK叢集的使用者和組
為了安全起見,不建議您直接登入ACK叢集的Master節點安裝使用Arena以及對叢集進行操作,因此建議您在與ACK叢集同一個VPC下建立ECS執行個體(Client機器)。通過配置KubeConfig檔案,使用ECS執行個體節點對ACK叢集進行訪問。
建立Client機器上的使用者和組。
通過kubectl串連ACK叢集。
使用kubectl命令串連ACK叢集時,您需要安裝kubectl用戶端工具和配置供叢集管理員admin操作ACK叢集的KubeConfig檔案。有關具體的操作步驟,請參見擷取叢集KubeConfig並通過kubectl工具串連叢集。
說明要求kubectl的版本大於或等於1.10。
執行以下代碼在Client機器上建立對應的Linux UID和GID。
叢集管理員需要為bob、tom以及分組dev1、dev2,在Client機器上建立對應的Linux UID和GID。通過Linux自身的帳號系統機制,實現目標二,即每個使用者只能通過自己的帳號和密碼登入到Client機器,使用自己環境下的Arena。
# 建立Linux使用者組dev1和dev2 groupadd -g 10001 dev1 groupadd -g 10002 dev2 # 建立Linux使用者bob和tom adduser -u 20001 -s /bin/bash -G dev1 -m bob adduser -u 20002 -s /bin/bash -G dev2 -m tom # 設定使用者bob登入操作AI平台的Linux節點的密碼。 passwd bob # 設定tom登入操作AI平台的Linux節點的密碼。 passwd tom
建立ACK叢集中的使用者(服務帳號)和組(命名空間)。
提交給AI平台的作業都將在ACK叢集中運行。在ACK中,作業的擁有者以服務帳號(ServiceAccount)區分,作業啟動並執行環境以命名空間(Namespace)區分。營運管理員admin將建立ServiceAccount和Namespace,並保證與在Client機器上建立的使用者和組對應。可以將Namespace對應組,ServiceAccount對應使用者。
admin以root身份登入Client機器,並確保擁有操作叢集的許可權(通過kubectl串連ACK叢集步驟中完成)。執行以下操作:
# 建立使用者組dev1對應的命名空間 kubectl create namespace dev1 # 建立使用者組dev2對應的命名空間 kubectl create namespace dev2 # 建立使用者bob對應的服務帳號 kubectl create serviceaccount bob -n dev1 # 建立使用者tom對應的服務帳號 kubectl create serviceaccount tom -n dev2預期輸出:
$ kubectl create namespace dev1 namespace/dev1 created $ kubectl create namespace dev2 namespace/dev2 created $ kubectl create serviceaccount bob -n dev1 serviceaccount/bob created $ kubectl create serviceaccount tom -n dev2 serviceaccount/tom created
步驟二:為使用者配置Arena的使用環境
安裝Arena。
叢集管理員在Client機器上安裝Arena。首先叢集管理員以root身份登入到Client機器,下載社區最新Arena發布的release安裝包,然後解壓並執行安裝包中install.sh指令碼。有關具體的操作步驟,請參見配置Arena用戶端。
說明在同一台Linux作業系統上,您只需安裝一份Arena工具。管理員通過為每位使用者配置各自的設定檔,從而實現隔離,便於使用者以不同的許可權使用Arena工具。
為使用者建立Arena設定檔。
為了使不同使用者以各自的身份和許可權正確操作AI平台叢集(ACK叢集),首先您需要建立不同使用者用於Arena串連ACK叢集的環境設定檔(即建立在各自ServiceAccount下使用的KubeConfig檔案)。
叢集管理員以root身份登入到Client機器上,建立如下指令碼並儲存為generate-kubeconfig.sh:
#!/usr/bin/env bash set -e NAMESPACE= SERVICE_ACCOUNT= DURATION= OUTPUT= help() { echo "Usage: $0 -n <namespace> -s <service-account> -d <duration> -o <output-file>" echo "" echo "Options:" echo "-n, --namespace <namespace> Namespace of the service account." echo "-s, --service-account <name> Name of the service account." echo "-d, --duration <duration> Duration of the token e.g. 30d." echo "-o, --output <file> Output file name. If not set, a temporary file will be created." } parse() { while [ $# -gt 0 ]; do case $1 in -n | --namespace) NAMESPACE="$2" shift 2 ;; -s | --service-account) SERVICE_ACCOUNT="$2" shift 2 ;; -d | --duration) DURATION="$2" shift 2 ;; -o | --output) OUTPUT="$2" shift 2 ;; *) help exit 0 ;; esac done if [ -z "${NAMESPACE}" ] || [ -z "${SERVICE_ACCOUNT}" ] || [ -z "${DURATION}" ]; then help exit 0 fi if [ -z "${OUTPUT}" ]; then OUTPUT=$(mktemp -d)/config elif [ -f "${OUTPUT}" ]; then echo "Output file \"${OUTPUT}\" already exists." exit 1 fi } # Generate kubeconfig generate_kubeconfig() { CONTEXT=$(kubectl config current-context) CLUSTER=$(kubectl config view -o jsonpath="{.contexts[?(@.name==\"${CONTEXT}\")].context.cluster}") SERVER=$(kubectl config view -o jsonpath="{.clusters[?(@.name==\"${CLUSTER}\")].cluster.server}") TOKEN=$(kubectl create token "${SERVICE_ACCOUNT}" --namespace "${NAMESPACE}" --duration="${DURATION}") CERT=$(mktemp) mkdir -p "$(dirname "${OUTPUT}")" kubectl config view --raw=true -o jsonpath="{.clusters[?(@.name==\"${CLUSTER}\")].cluster.certificate-authority-data}" | base64 -d >"${CERT}" kubectl config set-cluster "${CLUSTER}" --kubeconfig="${OUTPUT}" --server="${SERVER}" --embed-certs=true --certificate-authority="${CERT}" >/dev/null kubectl config set-credentials "${SERVICE_ACCOUNT}" --kubeconfig="${OUTPUT}" --token="${TOKEN}" >/dev/null kubectl config set-context "${CLUSTER}-${NAMESPACE}-${SERVICE_ACCOUNT}-context" --kubeconfig="${OUTPUT}" --cluster="${CLUSTER}" --user="${SERVICE_ACCOUNT}" --namespace="${NAMESPACE}" >/dev/null kubectl config use-context "${CLUSTER}-${NAMESPACE}-${SERVICE_ACCOUNT}-context" --kubeconfig="${OUTPUT}" >/dev/null rm "${CERT}" echo "Saved kubeconfig to \"${OUTPUT}\"." } main() { parse "$@" generate_kubeconfig } main "$@"執行如下命令,為使用者建立KubeConfig檔案並儲存至各自的家目錄下,您可以自訂到期時間,例如下面樣本將到期時間設定為720小時:
bash generate-kubeconfig.sh -n dev1 -s bob -d 720h -o /home/bob/.kube/config bash generate-kubeconfig.sh -n dev2 -s tom -d 720h -o /home/tom/.kube/config預期輸出如下:
$ bash generate-kubeconfig.sh -n dev1 -s bob -d 720h -o /home/bob/.kube/config Saved kubeconfig to "/home/bob/.kube/config". $ bash generate-kubeconfig.sh -n dev2 -s tom -d 720h -o /home/tom/.kube/config Saved kubeconfig to "/home/tom/.kube/config".
步驟三:為使用者配置Arena的許可權
在ACK叢集中為每個組(Namespace),按需建立組內的角色(Role)。
叢集管理員可以為每個組(Namespace)在ACK叢集的具體操作許可權配置不同的角色(Role)。一個角色(Role)代表組(Namespace)內一系列具體許可權規則的集合。有關ACK叢集中角色(Role)的定義方法,請參見Using RBAC Authorization。
建立許可權定義檔案。
因為需要保證組dev1下使用者bob和組dev2下使用者tom的作業彼此不可見,並且獨立管理各自的作業,所以需要給組dev1和dev2建立最小許可權,並綁定到對應的使用者上(即使用者bob和tom對應的ServiceAccount)。
為使用者組dev1建立如下許可權定義檔案並儲存為dev1_roles.yaml;
kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata: name: arena-topnode rules: - apiGroups: - "" resources: - pods - services - deployments - nodes - nodes/* - services/proxy - persistentvolumes verbs: - get - list --- apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: arena namespace: dev1 rules: - apiGroups: - "" resources: - configmaps verbs: - '*' - apiGroups: - "" resources: - services/proxy - persistentvolumeclaims - events verbs: - get - list - apiGroups: - "" resources: - pods - pods/log - services verbs: - '*' - apiGroups: - "" - apps - extensions resources: - deployments - replicasets verbs: - '*' - apiGroups: - kubeflow.org resources: - '*' verbs: - '*' - apiGroups: - batch resources: - jobs verbs: - '*'為使用者組dev2建立如下許可權定義檔案並儲存為dev2_roles.yaml:
kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata: name: arena-topnode rules: - apiGroups: - "" resources: - pods - services - deployments - nodes - nodes/* - services/proxy - persistentvolumes verbs: - get - list --- apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: arena namespace: dev2 rules: - apiGroups: - "" resources: - configmaps verbs: - '*' - apiGroups: - "" resources: - services/proxy - persistentvolumeclaims - events verbs: - get - list - apiGroups: - "" resources: - pods - pods/log - services verbs: - '*' - apiGroups: - "" - apps - extensions resources: - deployments - replicasets verbs: - '*' - apiGroups: - kubeflow.org resources: - '*' verbs: - '*' - apiGroups: - batch resources: - jobs verbs: - '*'叢集管理員執行以下命令,使之在ACK叢集中生效。
kubectl apply -f dev1_roles.yaml kubectl apply -f dev2_roles.yaml預期輸出如下:
$ kubectl apply -f dev1_roles.yaml clusterrole.rbac.authorization.k8s.io/arena-topnode created role.rbac.authorization.k8s.io/arena created $ kubectl apply -f dev2_roles.yaml clusterrole.rbac.authorization.k8s.io/arena-topnode unchanged role.rbac.authorization.k8s.io/arena created叢集管理員可以通過以下命令查看叢集中不同Namespace下的角色。
kubectl get role -n dev1 kubectl get role -n dev2預期輸出如下:
$ kubectl get role -n dev1 NAME CREATED AT arena 2024-09-14T08:25:34Z $ kubectl get role -n dev2 NAME CREATED AT arena 2024-09-14T08:25:39Z
為使用者配置在叢集內的許可權(賦權)。
組的角色建立完成後,我們需要給使用者綁定這個角色,使之作用在組裡的成員上,即賦權給使用者。叢集管理員通過將組(Namespace)內的某些角色(Role)與使用者(ServiceAccount)進行綁定,來為每位使用者在組內賦權。
通過角色綁定,叢集管理員可以為使用者賦予多個組內的角色許可權。這既包括使用者所屬的使用者組的組內許可權,也包括其他組內的許可權。這樣叢集管理員就可以動態地管理任何使用者在任何組內的許可權,只需要更新使用者與角色的對應關係即可。
ACK中通過定義RoleBinding和ClusterRoleBinding對象來聲明使用者(ServiceAccount)在不同組(Namespaces)或者整個叢集所有組中可以扮演的角色而擷取許可權。ACK中角色綁定(RoleBinding和ClusterRoleBinding)的定義方法可以參見官方的文檔Using RBAC Authorization。
叢集管理員以root身份登入Client機器後,為使用者bob建立如下授權檔案並儲存為bob_rolebindings.yaml:
kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: bob-arena-topnode namespace: dev1 roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: arena-topnode subjects: - kind: ServiceAccount name: bob namespace: dev1 --- kind: RoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: bob-arena namespace: dev1 roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: arena subjects: - kind: ServiceAccount name: bob namespace: dev1為使用者tom建立使用者授權檔案並儲存為tom_rolebindings.yaml:
kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: tom-arena-topnode namespace: dev2 roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: arena-topnode subjects: - kind: ServiceAccount name: tom namespace: dev2 --- kind: RoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: tom-arena namespace: dev2 roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: arena subjects: - kind: ServiceAccount name: tom namespace: dev2執行如下命令完成使用者和角色的綁定,即使用者賦權。
kubectl apply -f bob_rolebindings.yaml kubectl apply -f tom_rolebindings.yaml預期輸出:
$ kubectl apply -f bob_rolebindings.yaml clusterrolebinding.rbac.authorization.k8s.io/bob-arena-topnode created rolebinding.rbac.authorization.k8s.io/bob-arena created $ kubectl apply -f tom_rolebindings.yaml clusterrolebinding.rbac.authorization.k8s.io/tom-arena-topnode created rolebinding.rbac.authorization.k8s.io/tom-arena created叢集管理員通過以下命令查看叢集中不同Namespace下對不同使用者的角色賦權情況。
kubectl get rolebinding -n dev1 kubectl get rolebinding -n dev2預期輸出如下:
$ kubectl get rolebinding -n dev1 NAME ROLE AGE bob-arena Role/arena 34s $ kubectl get rolebinding -n dev2 NAME ROLE AGE tom-arena Role/arena 33s至此,本文樣本已完成了上述的前三個目標任務。
步驟四:配置使用者組資源配額
AI平台通過ACK統一管理所有叢集資源。為了保證不同組和使用者安全、有效地使用叢集資源,需要為小組分配資源配額。AI平台會在使用者提交作業時,自動檢查使用者有許可權運行作業的組配額使用。如果作業需求量超過配額上限,則提交會被拒絕。
在ACK中資源配額(ResourceQuota)的範圍是命名空間(Namespace),即對應本文中的使用者組。ResourceQuota支援的資源類型很多,既包括CPU、Memory,也包括Nvidia GPU這類擴充資源。ResourceQuota也能夠限制一個Namespace中容器及其它Kubernetes對象的使用量。有關更詳細的說明,請參見Resource Quotas。
根據目標四中的描述,本文樣本按照組劃分當前叢集的GPU、CPU、MEM等資源。樣本假設劃分的配置如資料配置表所示。本文樣本將分配組dev1一張GPU卡,不劃分CPU和MEM,即可以使用整個叢集的CPU和MEM。分配組dev2兩張GPU卡,八核CPU和60 GiB MEM。具體的操作步驟如下:
叢集管理員登入Client機器後,為使用者組dev1建立如下資源配額檔案並儲存為dev1_quota.yaml
apiVersion: v1 kind: ResourceQuota metadata: name: dev1-compute-resources namespace: dev1 spec: hard: requests.cpu: "10" requests.memory: 10Gi limits.cpu: "15" limits.memory: 20Gi requests.nvidia.com/gpu: 2為使用者組dev2建立如下資源設定檔並儲存為dev2_quota.yaml:
apiVersion: v1 kind: ResourceQuota metadata: name: dev2-compute-resources namespace: dev2 spec: hard: requests.nvidia.com/gpu: 2執行以下命令使之在叢集中生效。
kubectl apply -f dev1_quota.yaml kubectl apply -f dev2_quota.yaml建立後,叢集管理員可以通過以下命令查看ResourceQuota是否生效,並可以看到定義的配額以及組內已經分配掉的資源。
# 查看組dev1下的資源配額。 kubectl get resourcequotas -n dev1 # 查看組dev2下的資源配額。 kubectl get resourcequotas -n dev2 # 查看組dev1資源配額的使用方式。 kubectl describe resourcequotas dev1-compute-resources -n dev1 # 查看組dev2資源配額的使用方式。 kubectl describe resourcequotas dev2-compute-resources -n dev2預期輸出:
$ kubectl get resourcequotas -n dev1 NAME AGE REQUEST LIMIT dev1-compute-resources 9s requests.cpu: 0/10, requests.memory: 0/10Gi, requests.nvidia.com/gpu: 0/2 limits.cpu: 0/15, limits.memory: 0/20Gi $ kubectl get resourcequotas -n dev2 NAME AGE REQUEST LIMIT dev2-compute-resources 10s requests.nvidia.com/gpu: 0/2 $ kubectl describe resourcequotas dev1-compute-resources -n dev1 Name: dev1-compute-resources Namespace: dev1 Resource Used Hard -------- ---- ---- limits.cpu 0 15 limits.memory 0 20Gi requests.cpu 0 10 requests.memory 0 10Gi requests.nvidia.com/gpu 0 2 $ kubectl describe resourcequotas dev2-compute-resources -n dev2 Name: dev2-compute-resources Namespace: dev2 Resource Used Hard -------- ---- ---- requests.nvidia.com/gpu 0 2至此,本文完成了上述的目標四的按照組劃分ACK叢集計算資源。
步驟五:配置多層級共用儲存NAS
根據使用者組織內對資料共用的控制規則,可以為AI平台內的組和使用者分別配置帶有相應許可權控制的資料卷掛載,方便使用者間安全地共用資料。
本文樣本目標五需要建立兩類共用資料卷。一類用於存放全域的共用資料,所有組內成員都可以訪問和使用,另一類僅僅用於各個小組內共用。本文假設共用資料卷的需求如資料配置表所示。四個資料卷dev1-public、dev2-public、department1-public-dev1、department1-public-dev2中的department1-public-dev1和department1-public-dev2指向NAS盤的同一個目錄,組dev1和dev2共用這一份資料。dev1-public、dev2-public分別指向組dev1和組dev2所屬NAS盤的不同目錄,組dev1 、dev2獨享這份資料。具體操作如下:
建立NAS執行個體。
配置ACK叢集的儲存卷(PV)和儲存聲明(PVC)。
建立PV。
分別建立4個PV。有關建立PV的具體操作步驟,請參見建立PV。department1-public-dev1和department1-public-dev2是用於dev1和dev2兩組分別共用部門department1的資料。dev1-public和dev2-public是用於dev1和dev2各自組內共用資料。建立PV的參數配置如下圖所示。
 說明
說明設定掛載點時,選擇上一步驟建立NAS執行個體時建立的掛載點。
建立PVC。
使用上一步建立的PV,分別建立PVC。有關建立PVC的具體操作步驟,請參見建立PVC。
完成建立PVC後,可以看到在命名空間dev1下給dev1組分配部門和小組兩級共用的NAS資料卷:department1-public-dev1和dev1-public。在命名空間dev2下給dev2組分配部門和小組兩級共用的NAS資料卷:department1-public-dev2和dev2-public。
檢查資料卷的配置。
叢集管理員以root身份登入Client機器,執行以下命令查看為不同組分配的NAS資料情況。
# 查看組dev1可以使用的資料卷。 arena data list -n dev1 # 查看組dev2可以使用的資料卷。 arena data list -n dev2預期輸出:

至此,本文已經完成了所有目標。接下來本文將會以bob和tom賬戶進行登入使用Arena。
步驟六:類比多使用者操作
使用者bob
登入Client機器,執行以下命令查看當前可用的共用資料卷。
# 使用bob帳號登入Client機器 ssh bob@39.98.xxx.xx # 通過arena data list查看目前使用者可用共用資料卷。 arena data list預期輸出:

執行以下命令提交一個需要1張GPU卡的訓練作業。
arena submit tf \ --name=tf-git-bob-01 \ --gpus=1 \ --image=tensorflow/tensorflow:1.5.0-devel-gpu \ --sync-mode=git \ --sync-source=https://code.aliyun.com/xiaozhou/tensorflow-sample-code.git \ "python code/tensorflow-sample-code/tfjob/docker/mnist/main.py --max_steps 10000 --data_dir=code/tensorflow-sample-code/data"執行以下命令列出目前使用者提交的作業。
arena list預期輸出:

執行以下命令再提交一個使用一張GPU卡的訓練作業。
arena submit tf \ --name=tf-git-bob-02 \ --gpus=1 \ --image=tensorflow/tensorflow:1.5.0-devel-gpu \ --sync-mode=git \ --sync-source=https://code.aliyun.com/xiaozhou/tensorflow-sample-code.git \ "python code/tensorflow-sample-code/tfjob/docker/mnist/main.py --max_steps 10000 --data_dir=code/tensorflow-sample-code/data"由於本文樣本只給dev1組分配了一張GPU卡,所以預期這個作業不會被調度啟動。
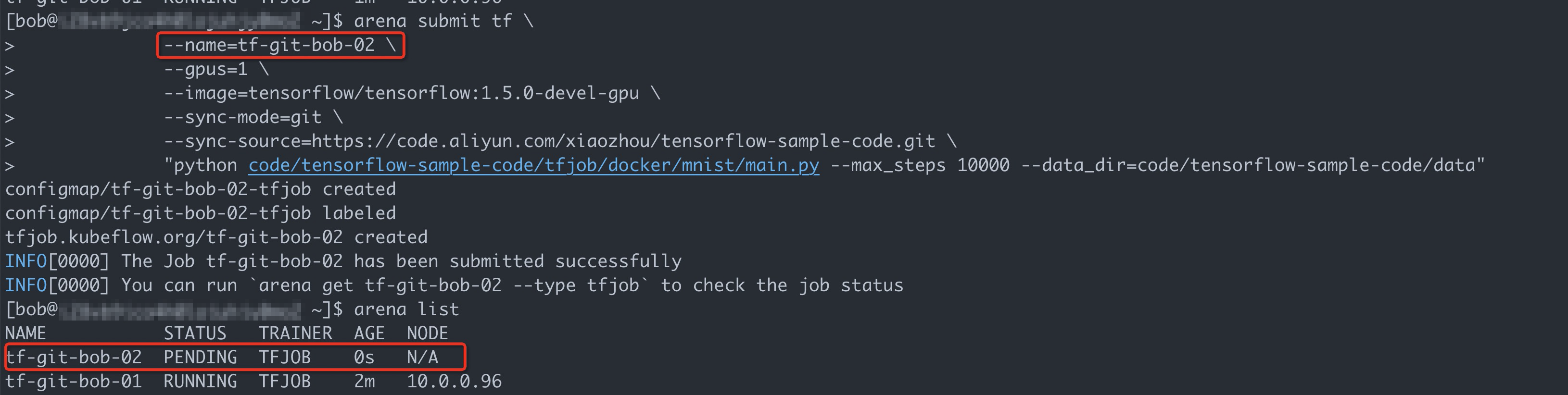

可以看到,雖然整個叢集還有剩餘資源,但是由於bob所在的組只被分配了一張GPU卡資源,並且當前已經有了一個作業佔用了資源,所以bob後續的提交的作業就會被暫停。
使用者tom
執行以下命令登入Client機器,查看當前可用的共用資料卷。
# 使用tom帳號登入Client機器。 ssh tom@39.98.xx.xx # 通過arena data list查看目前使用者可用共用資料卷。 arena data list預期輸出:

執行以下命令列出目前使用者提交的作業。
arena list此時看不到bob提交的作業。

執行以下命令提交一個需要1張GPU卡的訓練作業。
arena submit tf \ --name=tf-git-tom-01 \ --gpus=1 \ --chief-cpu=2 \ --chief-memory=10Gi \ --image=tensorflow/tensorflow:1.5.0-devel-gpu \ --sync-mode=git \ --sync-source=https://code.aliyun.com/xiaozhou/tensorflow-sample-code.git \ "python code/tensorflow-sample-code/tfjob/docker/mnist/main.py --max_steps 10000 --data_dir=code/tensorflow-sample-code/data"說明由於樣本分配了組dev2的GPU、CPU、MEM資源,因此在dev2組裡的使用者提交作業的時候需要明確指定GPU、CPU、MEM的使用資源。
執行以下命令再次提交一個需要1張GPU卡的訓練作業。
arena submit tf \ --name=tf-git-tom-02 \ --gpus=1 \ --chief-cpu=2 \ --chief-memory=10Gi \ --image=tensorflow/tensorflow:1.5.0-devel-gpu \ --sync-mode=git \ --sync-source=https://code.aliyun.com/xiaozhou/tensorflow-sample-code.git \ "python code/tensorflow-sample-code/tfjob/docker/mnist/main.py --max_steps 10000 --data_dir=code/tensorflow-sample-code/data"執行以下命令列出目前使用者提交的作業。
arena list預期輸出:
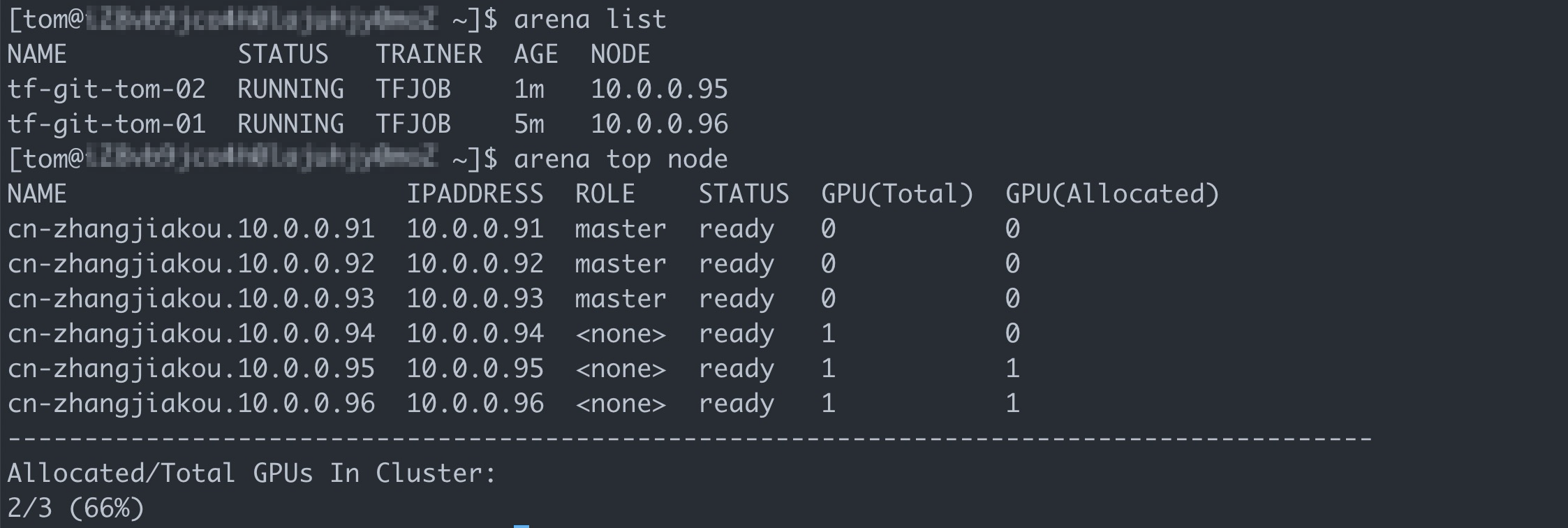
執行結果
從上述操作可以看到,目前分別位於兩個組的使用者bob、tom可以通過自己的帳號登入Client機器獨立地使用Arena ,並通過Arena查看和使用使用者當前所在組可訪問的儲存資源和計算資源,以及管理各自的作業。