GPU監控基於NVIDIA DCGM構建功能強大的GPU監控體系。本文介紹如何開啟叢集GPU監控。
前提條件
已開通ARMS。
背景資訊
對於Kubernetes叢集的大規模GPU裝置管理,需建立完善的監控體系。通過監測GPU相關指標,可以瞭解整個叢集的GPU的使用方式、健康狀態、工作負載效能等,從而實現對異常問題的快速診斷、最佳化GPU資源的分配、提升資源使用率等。除營運人員以外,其他人員(例如資料科學家、AI演算法工程師等)也能通過相關監控指標瞭解業務的GPU使用方式,以助於進行容量規劃和任務調度。
NVIDIA支援使用資料中心GPU管理器DCGM(Data Center GPU Manager)來管理大規模叢集中的GPU。基於NVIDIA DCGM構建的GPU監控系統具有更強大的功能,提供了多種GPU監控指標,其主要功能包括:
GPU行為監控
GPU組態管理
GPU Policy管理
GPU健康診斷
GPU層級統計和線程層級統計
NVSwitch配置和監控
使用限制
節點NVIDIA驅動需為418.87.01及以上版本。您可以登入GPU節點,執行
nvidia-smi命令查看驅動版本。若您需要使用GPU Profiling Metrics,則節點NVIDIA驅動需為450.80.02及以上版本。關於GPU Profiling Metrics的更多資訊,請參見Feature Overview。
不支援對NVIDIA MIG進行監控。
費用說明
關於阿里雲Prometheus的收費策略,請參見計費概述。
1. 開啟Prometheus監控
請確保ack-arms-prometheus組件為1.1.7及以上版本。可查看ack-arms-prometheus組件版本,確認組件版本後,升級組件。
建立叢集時開啟


在已有叢集中開啟
登入Container Service管理主控台,在左側導覽列選擇叢集列表。
在叢集列表頁面,單擊目的地組群名稱,然後在左側導覽列,選擇。
在Prometheus 監控頁面,按照頁面提示完成相關組件的安裝和監控大盤的檢查。
控制台會自動安裝組件、檢查監控大盤。安裝完成後,您可以單擊各個頁簽查看相應監控資料。
如果您想瞭解更多關於開啟Prometheus監控的操作,請參見開啟阿里雲Prometheus監控。
當採用開源自建的Prometheus服務,您如果需要GPU監測能力,需要安裝ack-gpu-exporter組件。
2. 部署樣本應用
使用以下YAML內容,建立tensorflow-benchmark.yaml檔案。
apiVersion: batch/v1 kind: Job metadata: name: tensorflow-benchmark spec: parallelism: 1 template: metadata: labels: app: tensorflow-benchmark spec: containers: - name: tensorflow-benchmark image: registry.cn-beijing.aliyuncs.com/ai-samples/gpushare-sample:benchmark-tensorflow-2.2.3 command: - bash - run.sh - --num_batches=50000 - --batch_size=8 resources: limits: nvidia.com/gpu: 1 #申請1張GPU卡。 workingDir: /root restartPolicy: Never執行以下命令,在GPU節點上部署tensorflow-benchmark應用。
kubectl apply -f tensorflow-benchmark.yaml執行以下命令,查看Pod狀態。
kubectl get pod預期輸出:
NAME READY STATUS RESTARTS AGE tensorflow-benchmark-k*** 1/1 Running 0 114s
3. 查看叢集GPU監控
登入Container Service管理主控台,在左側導覽列單擊叢集列表。
在叢集列表頁面,單擊目的地組群名稱,然後在左側導覽列,選擇。
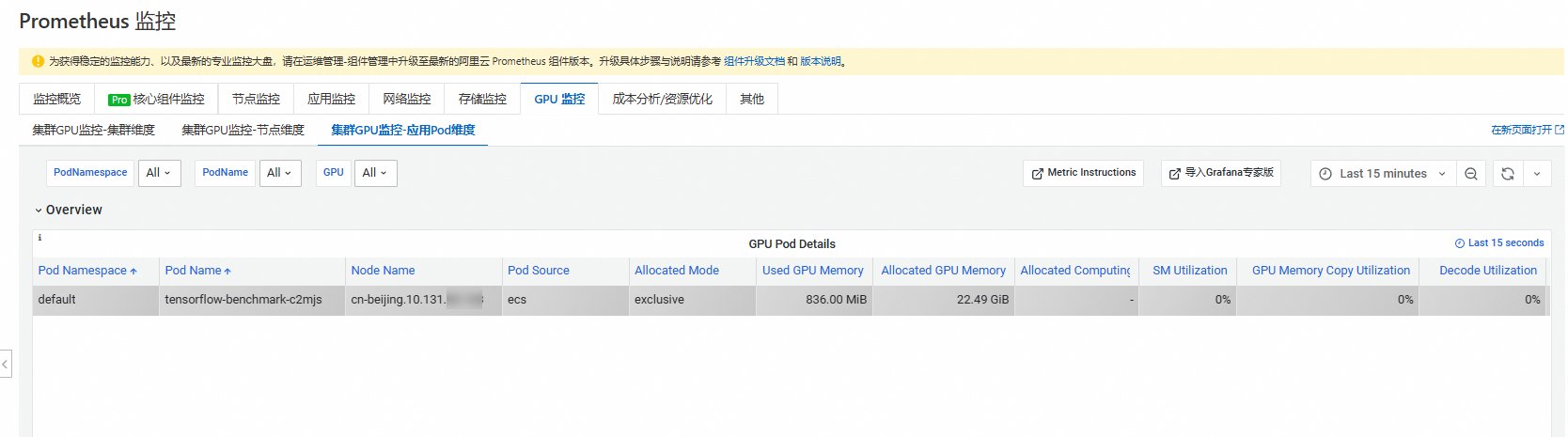
在Prometheus監控頁面,單擊GPU監控頁簽,然後單擊叢集GPU監控-應用Pod維度頁簽。
通過監控可以看到GPU Pod運行在節點cn-beijing.10.131.xx.xxx上。
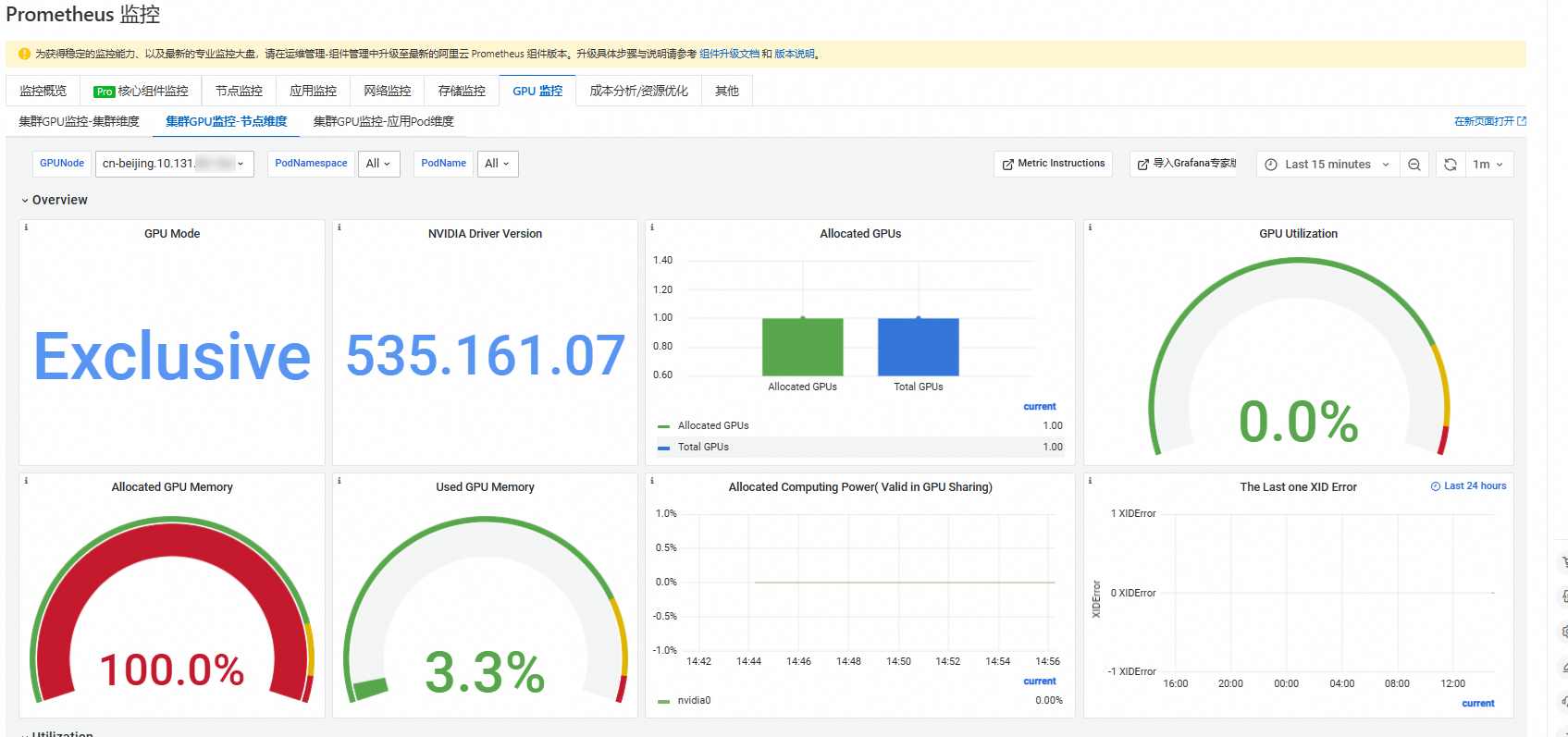
單擊叢集GPU監控-節點維度頁簽,選擇GPUNode為cn-beijing.10.131.xx.xxx,查看該節點的GPU詳細資料。可參見監控面板說明瞭解各參數詳情。
常見問題
DCGM記憶體流失
背景:DCGM(Data Center GPU Manager)是NVIDIA提供的一款用於管理和監控GPU的工具。
ack-prometheus-gpu-exporter是安裝阿里雲Prometheus組件後啟動的一個DaemonSet類型的Pod。原因:DCGM記憶體流失是指在運行過程中,DCGM佔用的記憶體未能被正確釋放,導致記憶體使用量量持續增加。
解決辦法:當前DCGM可能會出現記憶體流失情況,已通過為
ack-prometheus-gpu-exporter所在的Pod設定resources.limits來規避這個問題。當記憶體使用量達到limits限制時,ack-prometheus-gpu-exporter會重啟(一般一個月左右重啟一次),重啟後將正常上報指標,但在重啟後的幾分鐘內,Grafana可能會出現某些指標的顯示異常(例如節點數突然變多),之後恢複正常。問題詳情請參見The DCGM has a memory leak?。
ack-prometheus-gpu-exporter出現OOM Kill
背景:
ack-prometheus-gpu-exporter是安裝阿里雲Prometheus組件後啟動的一個DaemonSet類型的Pod,可能導致開啟監控出現問題。原因:由於ACK叢集上的
ack-prometheus-gpu-exporter採用的是DCGM的embedding的模式,這種模式下DCGM會在多卡情況下佔用較多的記憶體,且會出現記憶體泄露的問題。所以如果在具有多個GPU的執行個體上運行多個GPU進程,並且ack-prometheus-gpu-exporter分配的記憶體較少,可能會導致exporter Pod被OOM Kill。解決辦法:這種情況下,通常等待Pod重啟後即可重新上報Metrics。如果頻繁的出現OOM Kill的情況,可以手動提升
arms-prom命名空間中DaemonSetack-prometheus-gpu-exporter的limits來解決這個問題。
ack-prometheus-gpu-exporter報錯
背景:
ack-prometheus-gpu-exporter是安裝阿里雲Prometheus組件後啟動的一個DaemonSet類型的Pod,報錯可能導致監控出現問題。原因:若
ack-prometheus-gpu-exporter的Pod日誌出現類似如下的報錯資訊:failed to get all process informations of gpu nvidia1,reason: failed to get gpu utilizations for all processes on device 1,reason: Not Found這是由於舊版本的
ack-prometheus-gpu-exporter在某些GPU卡上未運行具體任務時,無法擷取相關容器的GPU指標。解決辦法:此問題已在最新版本中修複。請升級ack-arms-prometheus組件到最新版本以解決該問題。