Knative提供了簡單易用的自動擴縮容KPA(Knative Pod Autoscaler)功能。您可以基於Pod並發數(Concurrency)、每秒請求數(RPS)配置自動擴縮容的條件。此外,Knative預設會在沒有業務請求時將Pod數量縮減至0,您可以通過KPA配置縮容相關參數(例如縮容至0的等待時間),以及是否需要縮容至0。
前提條件
已在叢集中部署Knative,請參見部署Knative。
實現原理
Knative Serving會為每個Pod注入一個名為queue-proxy的QUEUE代理容器,該容器負責向Autoscaler報告業務容器的並髮指標。Autoscaler接收到這些指標之後,會根據並發請求數及相應的演算法,調整Deployment的Pod數量,從而實現自動擴縮容。
演算法
Knative Pod Autoscaler(KPA)基於每個Pod的平均請求數(或並發數)進行自動擴縮容,Knative預設使用基於並發數的自動彈性,每個Pod的最大並發數為100。此外,Knative還提供了目標使用率(target-utilization-percentage)的概念,用於指定自動擴縮容的目標使用率。
基於並發數彈性為例,Pod數計算方式如為:Pod數=並發請求總數/(Pod最大並發數*目標使用率)
例如,如果服務中Pod最大並發數設定為10,目標使用率設定為0.7,此時如果接收到了100個並發請求,則Autoscaler就會建立15個Pod(即100/(0.7*10)≈15)。
KPA基於每個Pod的平均請求數(或並發數)來進行自動擴縮容,並結合了Stable穩定模式和Panic恐慌模式兩個概念,以實現精細化的彈性。
Stable穩定模式
在穩定模式中,KPA會在預設的穩定視窗期(預設為60秒)內計算Pod的平均並發數。根據這個平均並發數,KPA會調整Pod的數量,以保持穩定的負載水平。
Panic恐慌模式
在恐慌模式中,KPA會在恐慌視窗期(預設為6秒)內計算Pod的平均並發數。恐慌視窗期=穩定視窗期*panic-window-percentage(panic-window-percentage取值是0~1,預設是0.1)。當請求突然增加導致當前Pod的使用率超過恐慌視窗百分比時,KPA會快速增加Pod的數量以滿足負載需求。
在KPA中,彈性生效的判斷是基於恐慌模式下計算得出的Pod數量是否超過恐慌閾值(PanicThreshold)。恐慌閾值=panic-threshold-percentage/100,panic-threshold-percentage預設為200,即恐慌閾值預設為2。
綜上所述,如果在恐慌模式下計算得出的Pod數量大於或等於當前Ready Pod數量的兩倍,那麼KPA將使用恐慌模式下計算得出的Pod數量進行彈性生效;否則,將使用穩定模式下計算得出的Pod數量。
KPA配置介紹
部分配置支援通過Annotation在Revision層級生效,也支援通過ConfigMap配置針對全域生效。如果您同時配置兩種方式,那麼Revision層級配置的優先順序將高於全域配置。
config-autoscaler配置介紹
配置KPA,需要配置config-autoscaler,該參數預設已配置,以下為重點參數介紹。
執行以下命令,查看config-autoscaler。
kubectl -n knative-serving describe cm config-autoscaler預期輸出(config-autoscaler預設的ConfigMap):
apiVersion: v1
kind: ConfigMap
metadata:
name: config-autoscaler
namespace: knative-serving
data:
# 預設Pod最大並發數,預設值為100。
container-concurrency-target-default: "100"
# 並發數目標使用率。預設值為70,70實際表示0.7。
container-concurrency-target-percentage: "70"
# 預設每秒請求數(RPS)。預設值為200。
requests-per-second-target-default: "200"
# 突發請求容量參數主要是為了應對突發流量,以防止Pod業務容器被過載。當前預設值211,也就意味著當前如果服務設定的目標閾值*Ready的Pod數小於 211,那麼會通過Activator進行路由
# 它通過Activator作為請求緩衝區,通過這個參數的計算結果,來調節是否請求通過Activator組件。
# 當該值為0時,只有Pod縮容到0時,才切換到Activator。
# 當該值大於0並且container-concurrency-target-percentage設定為100時,請求總是會通過Activator。
# 當該值為-1,表示無限的請求突發容量。請求也總是會通過Activator。其他負值無效。
# 如果當前Ready Pod數*最大並發數-突發請求容量-恐慌模式計算出來的並發數<0,意味著突發流量超過了容量閾值,則切換到Activator進行請求緩衝。
target-burst-capacity: "211"
# 穩定視窗,預設值為60秒。
stable-window: "60s"
# 恐慌視窗比例,預設值為10,則表示預設恐慌視窗期為6秒(60*0.1=6)。
panic-window-percentage: "10.0"
# 恐慌閾值比例,預設值200。
panic-threshold-percentage: "200.0"
# 最大擴縮容速率,表示一次擴容最大數。實際計算方式:math.Ceil(MaxScaleUpRate*readyPodsCount) 。
max-scale-up-rate: "1000.0"
# 最大縮容速率,預設值為2,表示每次縮容一半。
max-scale-down-rate: "2.0"
# 是否開始縮容到0,預設開啟。
enable-scale-to-zero: "true"
# 優雅縮容到0的時間,即延遲多久縮容到0,預設30秒。
scale-to-zero-grace-period: "30s"
# Pod縮容到0保留期,該參數適用於Pod啟動成本較高的情況
scale-to-zero-pod-retention-period: "0s"
# 彈性外掛程式類型,當前支援的彈性外掛程式包括:KPA、HPA、AHPA。
pod-autoscaler-class: "kpa.autoscaling.knative.dev"
# activator請求容量。
activator-capacity: "100.0"
# 建立revision時,初始化啟動的Pod數,預設1。
initial-scale: "1"
# 是否允許建立revision時,初始化0個Pod, 預設false,表示不允許。
allow-zero-initial-scale: "false"
# revision層級最小保留的Pod數量。預設0,表示最小值可以為0。
min-scale: "0"
# revision層級最大擴容的Pod數量。預設0,表示無最大擴容上限。
max-scale: "0"
# 表示延遲縮容時間。預設0,表示立即縮容。
scale-down-delay: "0s"指標配置介紹
您可以通過autoscaling.knative.dev/metricAnnotation為每個Revision配置指標,不同的彈性外掛程式支援的指標配置不同。
支援的指標:
"concurrency"、"rps"、"cpu"、"memory"以及其他自訂指標。預設指標:
"concurrency"。
目標閾值配置介紹
您可以通過autoscaling.knative.dev/targetAnnotation為每一個Revision配置目標閾值,也通過container-concurrency-target-defaultAnnotation為ConfigMap全域配置目標閾值。
Revision層級
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: helloworld-go
namespace: default
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/target: "50"全域層級
apiVersion: v1
kind: ConfigMap
metadata:
name: config-autoscaler
namespace: knative-serving
data:
container-concurrency-target-default: "200"縮容到0配置介紹
通過全域配置是否縮容到0
enable-scale-to-zero參數可取值為"false"或"true",用於指定Knative服務在空閑時是否自動縮減為零副本。
apiVersion: v1
kind: ConfigMap
metadata:
name: config-autoscaler
namespace: knative-serving
data:
enable-scale-to-zero: "false" # 值被設定為"false",表示自動縮容功能被禁用,即Knative服務在空閑時不會自動縮減為零副本。全域配置優雅縮容到0的時間
scale-to-zero-grace-period參數用於指定Knative服務在縮減為0副本之前的等待時間。
apiVersion: v1
kind: ConfigMap
metadata:
name: config-autoscaler
namespace: knative-serving
data:
scale-to-zero-grace-period: "40s"Pod縮容到0保留期
Revision層級
autoscaling.knative.dev/scale-to-zero-pod-retention-periodAnnotation用於配置Knative服務的自動縮容功能,指定在服務空閑一段時間後保留的Pod的時間周期。
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: helloworld-go
namespace: default
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/scale-to-zero-pod-retention-period: "1m5s"
spec:
containers:
- image: registry.cn-hangzhou.aliyuncs.com/knative-sample/helloworld-go:73fbdd56全域層級
scale-to-zero-pod-retention-period的配置項用於指定Knative服務在縮減為零副本之前保留的Pod的時間周期。
apiVersion: v1
kind: ConfigMap
metadata:
name: config-autoscaler
namespace: knative-serving
data:
scale-to-zero-pod-retention-period: "42s"並發數配置介紹
並發數表示單個Pod能同時處理的最大請求數量。可以通過並發軟式節流配置、並發硬限制配置、目標使用率配置、每秒請求數(RPS)配置來設定並發數。
並發軟式節流配置
並發軟式節流是有針對性的限制,而不是嚴格執行的界限。在某些情況下,特別是請求突然爆發時,可能會超過該值。
Revision層級
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: helloworld-go
namespace: default
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/target: "200"全域層級
apiVersion: v1
kind: ConfigMap
metadata:
name: config-autoscaler
namespace: knative-serving
data:
container-concurrency-target-default: "200" # 指定Knative服務的預設容器並發目標。
並發硬限制配置(Revision層級)
僅當您的應用程式有明確的執行並發上限時,才建議使用硬限制配置。因為指定較低的硬限制可能會對應用程式的輸送量和延遲產生負面影響。
並發硬限制是強制上限。如果並發達到硬限制,多餘的請求將被queue-proxy或者activator緩衝,直到有足夠的可用資源來執行請求。
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: helloworld-go
namespace: default
spec:
template:
spec:
containerConcurrency: 50目標使用率
使用目標利用率值調整並發值,該值指定Autoscaler實際目標值的百分比。這也稱為資源預熱,可以在請求達到定義的硬限制之前進行擴容。
例如,containerConcurrency設定為10,目標利用率值設定為70(百分比),則當所有現有Pod的平均並發請求數達到7時,Autoscaler將建立一個新Pod。因為Pod從建立到Ready需要一定的時間,通過降低目標利用率值可以提前擴容Pod,從而減少冷啟動導致的響應延遲等問題。
Revision層級
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: helloworld-go
namespace: default
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/target-utilization-percentage: "70" # 配置Knative服務的自動縮放功能,指定了目標資源使用率的百分比。
spec:
containers:
- image: registry.cn-hangzhou.aliyuncs.com/knative-sample/helloworld-go:73fbdd56全域層級
apiVersion: v1
kind: ConfigMap
metadata:
name: config-autoscaler
namespace: knative-serving
data:
container-concurrency-target-percentage: "70" # Knative將盡量確保每個Pod的並發數不超過當前可用資源的70%。每秒請求數(RPS)配置
RPS表示單個Pod每秒能處理的請求數。
Revision層級
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: helloworld-go
namespace: default
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/target: "150"
autoscaling.knative.dev/metric: "rps" # 表示服務的自動縮放將根據每秒請求數(RPS)來調整副本數。
spec:
containers:
- image: registry.cn-hangzhou.aliyuncs.com/knative-sample/helloworld-go:73fbdd56全域層級
apiVersion: v1
kind: ConfigMap
metadata:
name: config-autoscaler
namespace: knative-serving
data:
requests-per-second-target-default: "150"情境一:設定並發請求數實現自動擴縮容
設定並發請求數,通過KPA實現自動擴縮容。
為叢集部署Knative,具體操作,請參見在ACK叢集中部署Knative、在ACK Serverless叢集中部署Knative。
建立autoscale-go.yaml,並部署到叢集中。
apiVersion: serving.knative.dev/v1 kind: Service metadata: name: autoscale-go namespace: default spec: template: metadata: labels: app: autoscale-go annotations: autoscaling.knative.dev/target: "10" # 設定當前最大並發請求數為10。 spec: containers: - image: registry.cn-hangzhou.aliyuncs.com/knative-sample/autoscale-go:0.1kubectl apply -f autoscale-go.yaml擷取服務訪問網關。
ALB
執行以下命令,擷取服務訪問網關。
kubectl get albconfig knative-internet預期輸出:
NAME ALBID DNSNAME PORT&PROTOCOL CERTID AGE knative-internet alb-hvd8nngl0lsdra15g0 alb-hvd8nng******.cn-beijing.alb.aliyuncs.com 2MSE
執行以下命令,擷取服務訪問網關。
kubectl -n knative-serving get ing stats-ingress預期輸出:
NAME CLASS HOSTS ADDRESS PORTS AGE stats-ingress knative-ingressclass * 101.201.XX.XX,192.168.XX.XX 80 15dASM
執行以下命令,擷取服務訪問網關。
kubectl get svc istio-ingressgateway --namespace istio-system --output jsonpath="{.status.loadBalancer.ingress[*]['ip']}"預期輸出:
121.XX.XX.XXKourier
執行以下命令,擷取服務訪問網關。
kubectl -n knative-serving get svc kourier預期輸出:
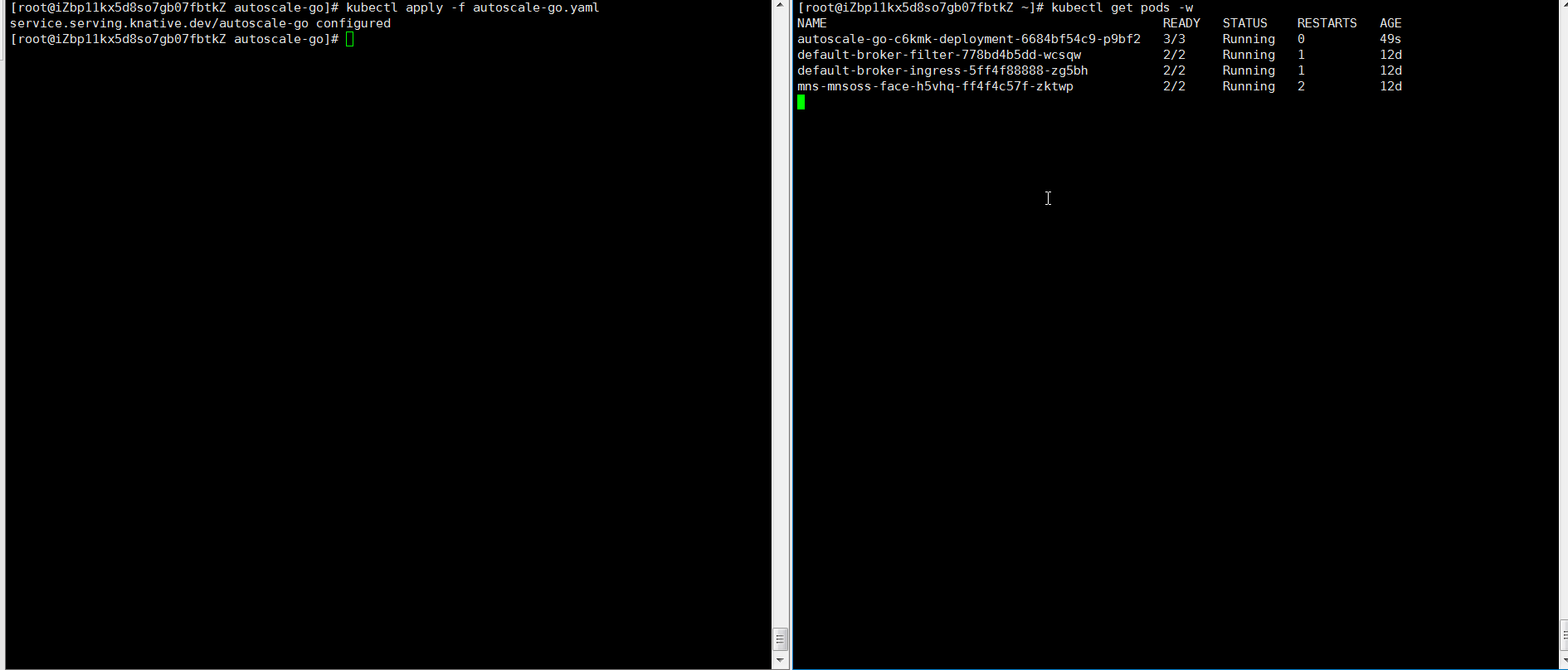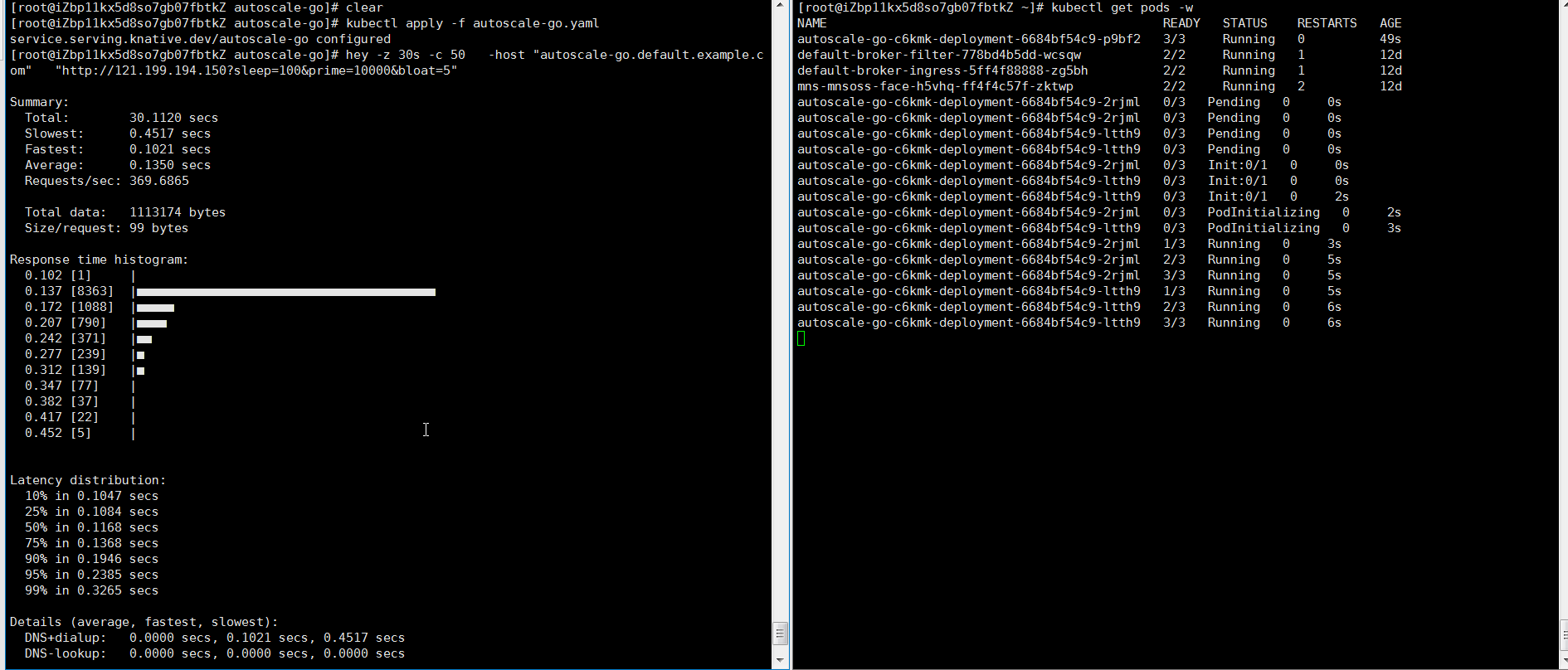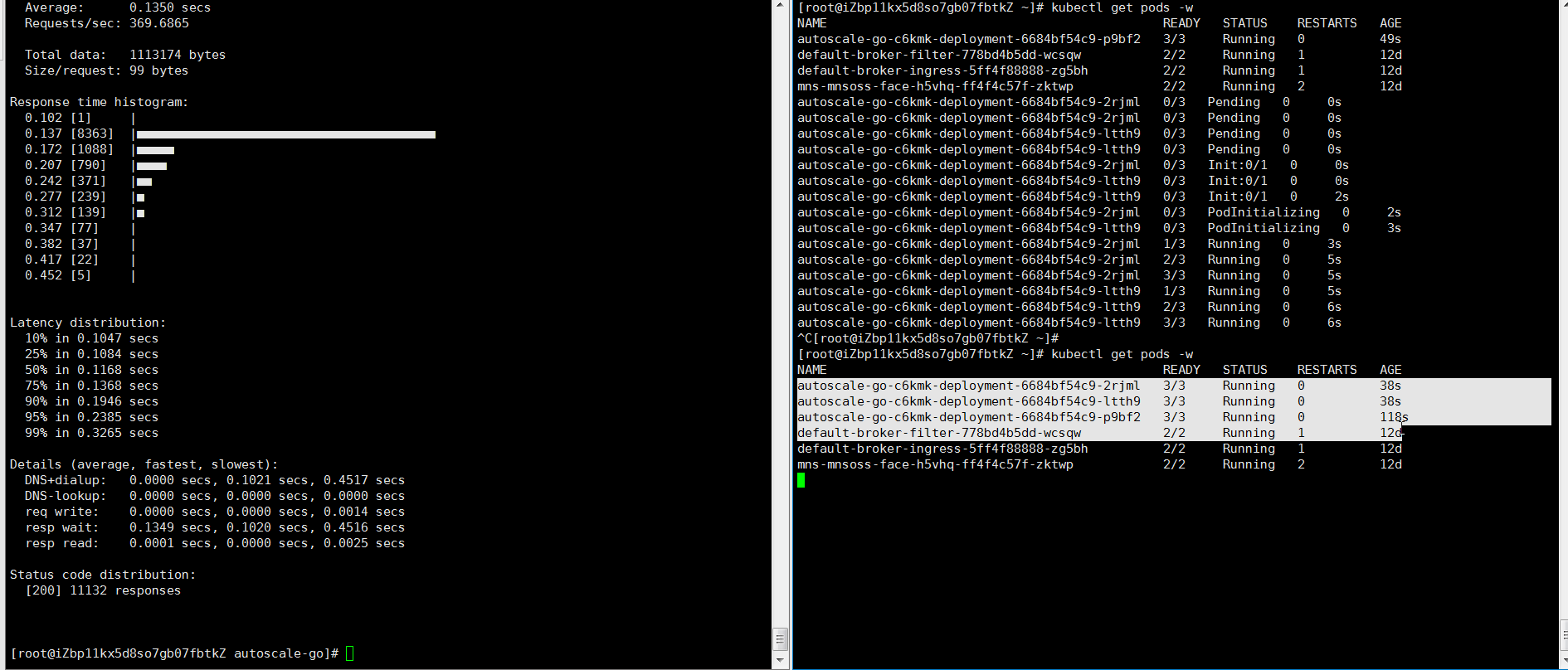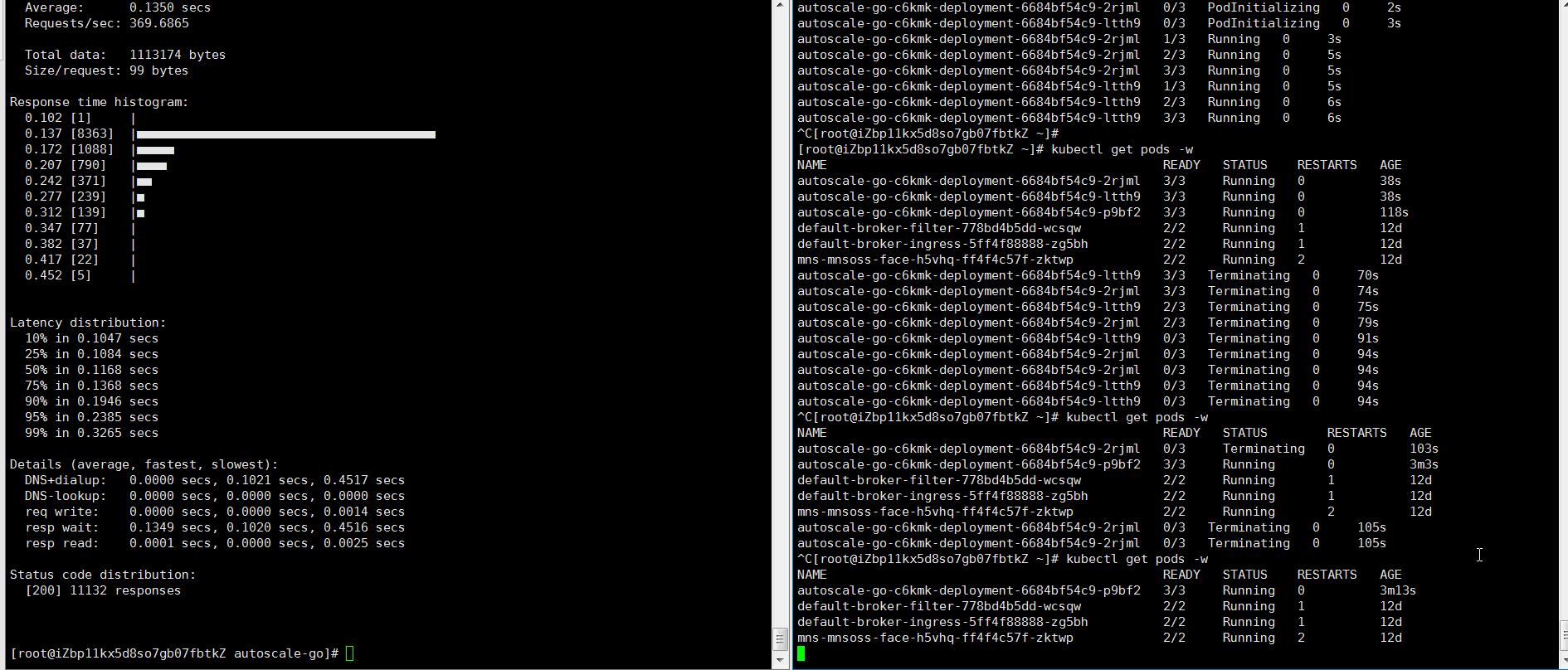
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kourier LoadBalancer 10.0.XX.XX 39.104.XX.XX 80:31133/TCP,443:32515/TCP 49m使用Hey壓測工具,執行30s內保持50個並發請求。
說明Hey壓測工具的詳細介紹,請參見Hey。
hey -z 30s -c 50 -host "autoscale-go.default.example.com" "http://121.199.XXX.XXX" # 121.199.XXX.XXX為網關IP。預期輸出:
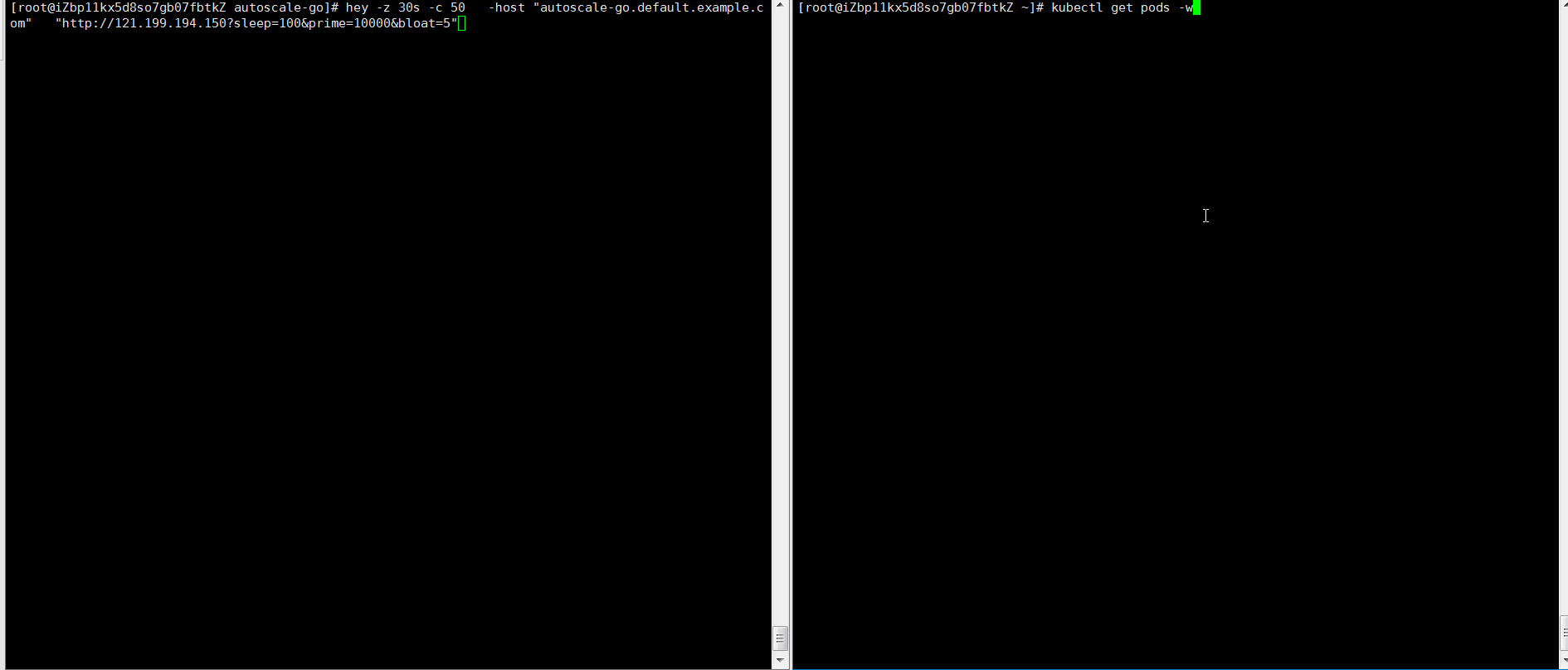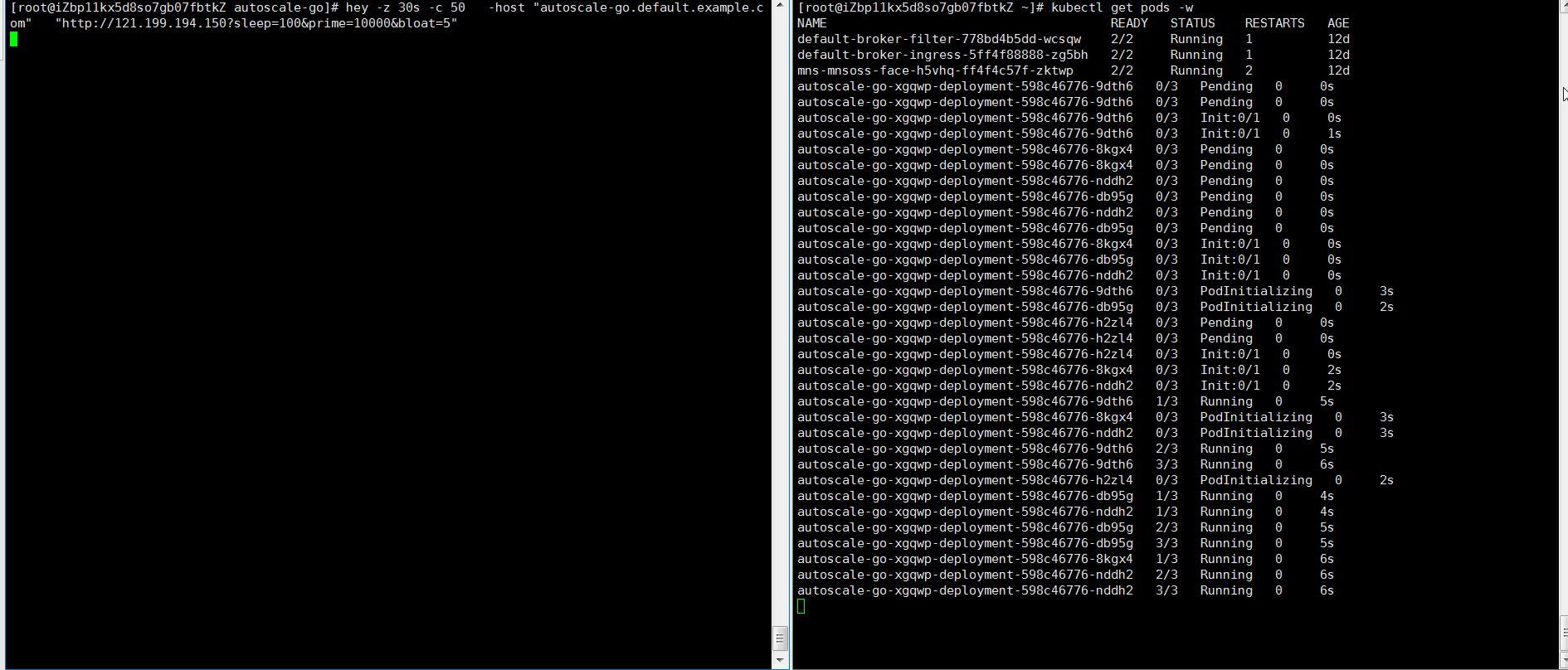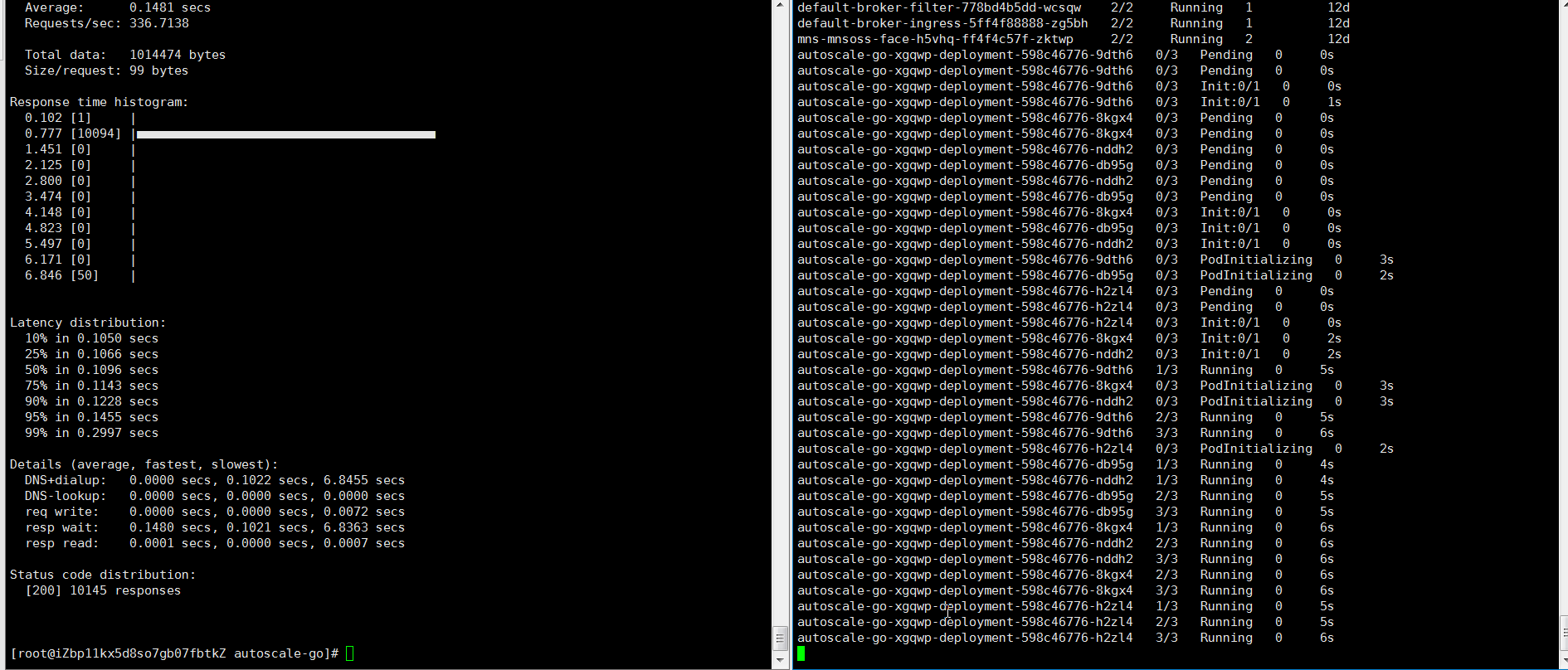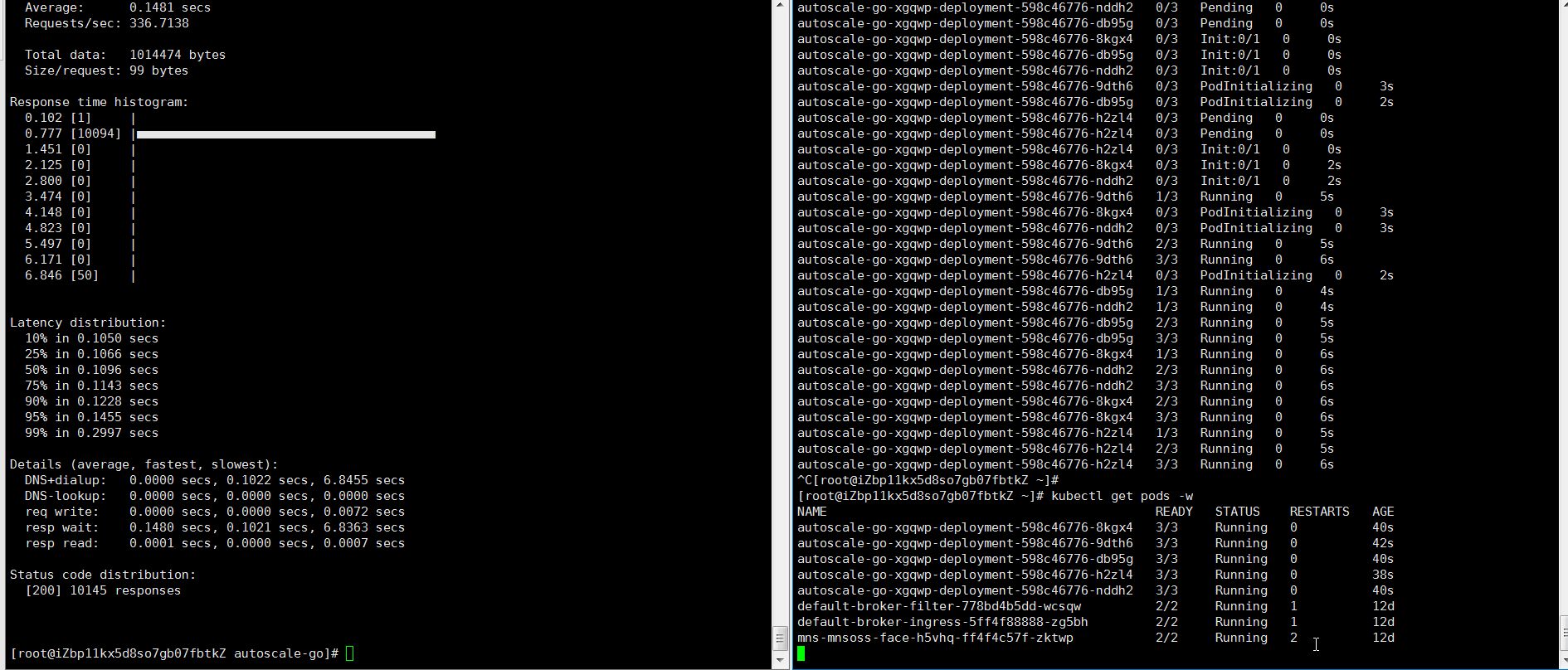
擴容了5個Pod,符合預期。
情境二:設定擴縮容邊界實現自動擴縮容
擴縮容邊界指應用程式提供服務的最小和最大Pod數量。通過設定應用程式提供服務的最小和最大Pod數量實現自動擴縮容。
為叢集部署Knative,具體操作,請參見在ACK叢集中部署Knative、在ACK Serverless叢集中部署Knative。
建立autoscale-go.yaml,並部署到叢集中。
樣本YAML設定最大並發請求數為10,
min-scale最小保留執行個體數為1,max-scale最大擴容執行個體數為3。apiVersion: serving.knative.dev/v1 kind: Service metadata: name: autoscale-go namespace: default spec: template: metadata: labels: app: autoscale-go annotations: autoscaling.knative.dev/target: "10" autoscaling.knative.dev/min-scale: "1" autoscaling.knative.dev/max-scale: "3" spec: containers: - image: registry.cn-hangzhou.aliyuncs.com/knative-sample/autoscale-go:0.1kubectl apply -f autoscale-go.yaml擷取服務訪問網關。
ALB
執行以下命令,擷取服務訪問網關。
kubectl get albconfig knative-internet預期輸出:
NAME ALBID DNSNAME PORT&PROTOCOL CERTID AGE knative-internet alb-hvd8nngl0lsdra15g0 alb-hvd8nng******.cn-beijing.alb.aliyuncs.com 2MSE
執行以下命令,擷取服務訪問網關。
kubectl -n knative-serving get ing stats-ingress預期輸出:
NAME CLASS HOSTS ADDRESS PORTS AGE stats-ingress knative-ingressclass * 101.201.XX.XX,192.168.XX.XX 80 15dASM
執行以下命令,擷取服務訪問網關。
kubectl get svc istio-ingressgateway --namespace istio-system --output jsonpath="{.status.loadBalancer.ingress[*]['ip']}"預期輸出:
121.XX.XX.XXKourier
執行以下命令,擷取服務訪問網關。
kubectl -n knative-serving get svc kourier預期輸出:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kourier LoadBalancer 10.0.XX.XX 39.104.XX.XX 80:31133/TCP,443:32515/TCP 49m使用Hey壓測工具,執行30s內保持50個並發請求。
說明Hey壓測工具的詳細介紹,請參見Hey。
hey -z 30s -c 50 -host "autoscale-go.default.example.com" "http://121.199.XXX.XXX" # 121.199.XXX.XXX為網關IP。預期輸出:
最多擴容出3個Pod,並且即使在無訪問請求流量的情況下,保持了1個Pod處於運行中,符合預期。