本文為您介紹阿里雲共用GPU方案、共用GPU專業版的優勢、共用GPU的基礎版與專業版的功能對比及使用情境,協助您瞭解和更好地使用共用GPU的能力。
背景介紹
阿里雲Container Service for Kubernetes (ACK)在開源GPU共用調度之後,您可以在阿里雲和自有資料中心的容器叢集上,通過GPU共用調度架構,實現多個容器共用同一GPU裝置,進而降低使用成本。然而,在實現經濟節約的同時,還需要確保GPU上的容器可以穩定運行。通過隔離技術,可以限制同一GPU上多個容器的資源使用量,從而避免資源超標導致的相互影響。為此,業界探索了多種方案,如NVIDIA vGPU、MPS和vCUDA,以實現更精細的GPU使用管理。
基於以上需求,阿里雲Container Service團隊提供了共用GPU方案,既能夠實現一個GPU供多個任務使用,同時也能夠實現一個GPU上對各個應用進行顯存隔離以及GPU算力分割的目標。
功能及優勢
阿里雲提供的共用GPU方案通過自主研發的宿主機核心驅動,實現對NVIDIA GPU的底層nv驅動更有效利用。共用GPU功能如下:
更加開放:適配開源標準的Kubernetes和NVIDIA Docker方案。
更加簡單:優秀的使用者體驗。AI應用無需重編譯,無需構建新的容器鏡像進行CUDA庫替換。
更加穩定:針對NVIDIA裝置的底層操作更加穩定和收斂,而CUDA層的API變化多端,同時一些Cudnn非開放的API也不容易捕獲。
完整隔離:同時支援GPU的顯存和算力隔離。
阿里雲提供的共用GPU方案是一套低成本、可靠、方便使用的規模化GPU調度和隔離方案,歡迎使用。
優勢 | 說明 |
支援共用調度和顯存隔離。 |
|
支援共用和隔離策略的靈活配置。 |
|
GPU資源全方位監控。 | 支援同時監控獨佔和共用GPU。 |
免費 | 在使用共用GPU調度前,需開通雲原生AI套件。自2024年06月06日00:00:00起,雲原生AI套件全面開放免費使用。 |
使用說明
目前共用GPU調度僅支援ACK叢集Pro版。關於如何安裝和使用共用GPU調度,請參考:
除此以外,還有一些進階能力,您可以根據業務需求選擇:
相關概念
共用GPU調度 vs 獨佔GPU調度
共用GPU調度指的是多個Pod共同使用一張GPU卡,如下圖:
獨佔GPU調度指的是一個Pod完整佔用一張卡或多張卡。如下圖:
顯存隔離
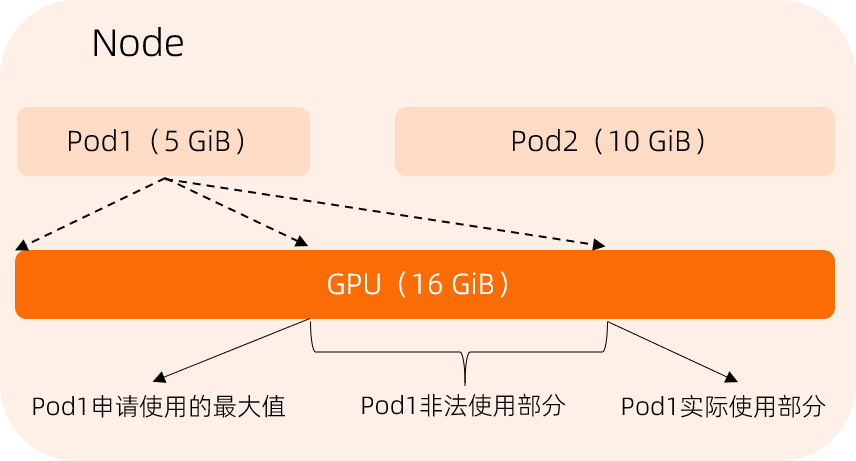
如果沒有GPU隔離模組參與,那麼共用GPU調度僅能夠保證多個Pod運行在一張GPU卡上,並不能解決Pod之間相互影響的問題。以下是一個顯存使用的例子。
假設Pod1需要申請5 GiB顯存使用,Pod2需要申請10 GiB顯存使用。在沒有GPU隔離模組的參與的情況下,Pod1實際使用達到10 GiB,這會導致Pod2無法正常運行,相當於Pod1非法使用了5 GiB顯存。有了GPU隔離模組後,當Pod1試圖使用的GPU顯存大於申請的值時,隔離模組將使Pod1失敗退出。
節點選卡策略Binpack和Spread
在共用GPU調度中,如果節點存在多張GPU卡,從節點中挑選GPU卡分配給Pod時,有兩種策略可以考慮:
Binpack:預設策略,調度系統先分配完節點的一張GPU卡後,再分配節點上另一張GPU卡,避免節點出現GPU資源片段。
Spread:調度系統會盡量將Pod分散到這個節點的各個GPU上,避免一張GPU卡壞掉後,影響的業務過多。
以下樣本表示,某個節點有2張GPU卡,每張卡有15 GiB顯存,Pod1申請2 GiB顯存,Pod2申請3 GiB顯存。
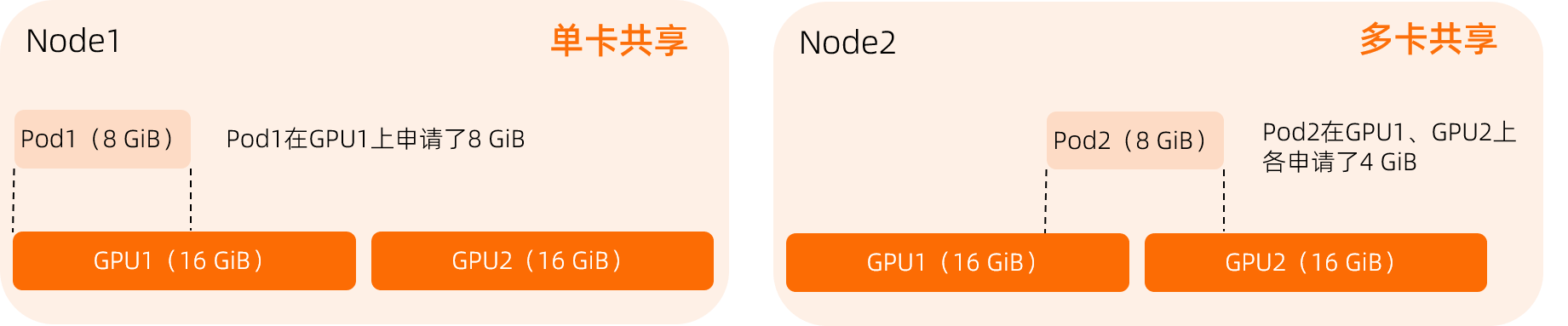
單卡共用 vs 多卡共用
單卡共用:一個Pod僅申請一張GPU卡,佔用該GPU部分資源。
多卡共用:一個Pod申請多張GPU卡,每張GPU提供部分資源,且每張GPU提供的資源量相同。