多次元インデックスは、転置インデックスと列ストアに基づいて、ビッグデータシナリオでの多次元データクエリと統計分析に使用されます。ビジネスに複雑なクエリとデータ分析が必要な場合は、多次元インデックスを作成し、必要な属性を多次元インデックスのフィールドとして指定できます。その後、多次元インデックスを使用してデータのクエリと分析を実行できます。たとえば、多次元インデックスを使用して、プライマリキー列以外に基づくクエリ、ブールクエリ、あいまい検索、全文検索、k 近傍(KNN)ベクタクエリを実行できます。また、多次元インデックスを使用して、最大値と最小値を取得したり、行数の統計を収集したり、クエリ結果をグループ化したりすることもできます。
背景情報
多次元インデックスは、Wide Column モデルにのみ適用されます。
多次元インデックスは、ビッグデータシナリオでの複雑なクエリの問題を解決できます。データベースや検索エンジンなどの他のシステムも、複雑なデータクエリの問題を解決できます。次の図は、Tablestore とデータベースおよび検索エンジンの違いを示しています。
Tablestore は、JOIN 操作、トランザクション処理、および検索結果の関連性以外のデータベースと検索エンジンのすべての機能を提供できます。 Tablestore はデータベースの高いデータ信頼性も備えており、検索エンジンの高度なクエリをサポートしています。したがって、Tablestore を使用して、データベースと検索エンジンで構成される一般的なアーキテクチャを置き換えることができます。
JOIN 操作、トランザクション処理、または検索結果の複雑な関連性分析が不要な場合は、Tablestore の多次元インデックス機能を使用することをお勧めします。

概要
多次元インデックスは、転置インデックスと列ストアに基づいて、ビッグデータシナリオでの多次元データクエリと統計分析に使用されます。 多次元インデックスは、プライマリキー列以外に基づくクエリ、プレフィックスクエリ、あいまい検索、ブールクエリ、ネストされたクエリ、ジオクエリ、全文検索、KNN ベクタクエリなど、さまざまなクエリメソッドをサポートしています。 多次元インデックスは、複数の集約操作もサポートしています。集約操作を実行して、最大値と最小値、行の数と重複を除いた数、合計、平均、パーセンタイル統計を取得したり、特定の条件で結果をグループ化したり、データをヒストグラムとして表示したりできます。
次の図は、多次元インデックスでの転置インデックスと列ストアの使用方法、および多次元空間インデックスの構造を示しています。
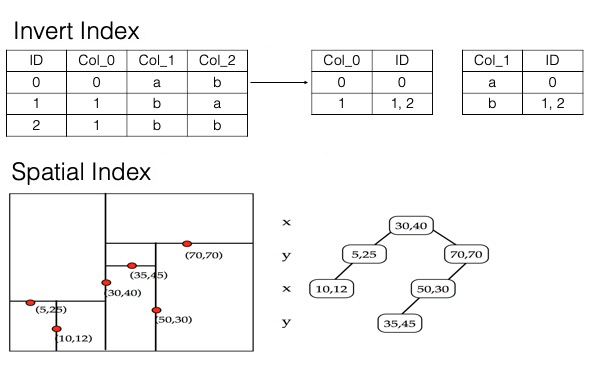
MySQL などの従来のデータベースサービスのインデックスと比較して、Tablestore の多次元インデックス機能は左端一致の原則に制約されません。したがって、多次元インデックス機能はより多くのシナリオで使用できます。ほとんどの場合、データテーブルに必要な多次元インデックスは 1 つだけです。たとえば、学生情報に関するデータテーブルには、学生名、ID、性別、学年、クラス、自宅住所などの列が含まれています。3 年生の張三という名前の学生、学校から 1 km 以内に住んでいる男子学生、指定された住宅街の 3 年生 2 組の学生など、条件の組み合わせを指定してデータテーブルのデータをクエリする場合、多次元インデックスを作成し、これらの列を多次元インデックスに追加できます。
比較
データテーブルのプライマリキー列に基づくクエリの他に、Tablestore は、データクエリの高速化のために、セカンダリインデックスと多次元インデックスという 2 つのインデックススキーマを提供しています。次の表に、3 種類のインデックスの違いを示します。
インデックスタイプ | 説明 | シナリオ |
データテーブルのプライマリキー | データテーブルは大きなマップに似ています。データテーブルは、プライマリキー列に基づくクエリのみをサポートしています。 | プライマリキーベースのクエリは、すべてのプライマリキー列の値またはプライマリキープレフィックスを決定できるシナリオに適しています。 |
セカンダリインデックス | データテーブルに 1 つ以上のインデックステーブルを作成し、インデックステーブルのプライマリキー列を使用してクエリを実行できます。インデックステーブルのプライマリキー列は、すべてのプライマリキー列と、インデックステーブルが作成されるデータテーブルの特定の数の事前定義列で構成されます。 | セカンダリインデックスは、クエリ対象の列を決定でき、クエリ対象の列の数が少なく、すべてのプライマリキー列の値またはプライマリキープレフィックスを決定できるシナリオに適しています。 |
多次元インデックス | 多次元インデックスは、さまざまなクエリシナリオで転置インデックス、Bkd ツリー、および列ストアを使用します。 | 多次元インデックスは、データテーブルのプライマリキー列とセカンダリインデックスに基づくクエリではビジネス要件を満たすことができないすべてのクエリおよび分析シナリオに適しています。たとえば、多次元インデックスを使用して、プライマリキー列以外に基づくクエリ、ブールクエリ、リレーショナルクエリ、全文検索、ジオクエリ、あいまい検索、ネストされたクエリ、Exists クエリ、および集約操作を実行できます。 |
シナリオ
多次元インデックスは、データクエリと分析のためのさまざまなアプリケーションシステムで広く使用できます。次の表に、多次元インデックスを使用できるいくつかのシナリオを示します。
アプリケーションシステム | シナリオ |
E コマース プラットフォーム | E コマース プラットフォームで多次元インデックスを使用して、製品を分類し、属性をフィルタリングできます。これにより、顧客は製品を簡単に検索してフィルタリングできます。 |
ソーシャルメディア アプリケーション | ソーシャルメディア アプリケーションで多次元インデックスを使用して、ユーザー間のフォロワーとフレンドのつながりをクエリし、ユーザーの興味に基づいておすすめとマッチング機能を提供できます。 |
ログ分析 | 多次元インデックスを使用して、キーワードや時間範囲などの条件に基づいてログをクエリできます。これにより、問題を効率的に特定し、ログデータを分析できます。 |
IoT のデータ分析 | 多次元インデックスを使用して、モノのインターネット(IoT)シナリオでデバイスデータをクエリおよび分析できます。たとえば、デバイスタイプと地理的な場所に基づいてデバイスデータをフィルタリングし、統計を収集できます。 |
アプリケーション パフォーマンス モニタリング | 多次元インデックスを使用して、メトリックデータを集約およびクエリできます。これは、アプリケーション パフォーマンスのモニタリングに不可欠です。たとえば、時間範囲とアプリケーション名でデータをフィルタリングおよび集約できます。 |
位置情報サービス | 多次元インデックスを使用して、地理的な場所をクエリし、店舗、アトラクション、サービスなどの近くのPOI を検索できます。 |
テキスト検索エンジン | テキスト検索エンジンで、多次元インデックスを全文検索と関連性に基づく並べ替えに使用できます。これにより、ドキュメントや記事などの情報を効率的に検索できます。 |
機能の説明
機能
次の表に、多次元インデックスの機能を示します。
機能 | 説明 | 参照 |
プライマリキー列とプライマリキー列以外に基づくクエリ | 多次元インデックスを使用して、ランダムな列に基づいてデータをクエリできます。この機能は、ほとんどのシナリオのクエリ要件を満たします。 プライマリキー列またはプライマリキープレフィックスに基づくクエリがビジネス要件を満たさない場合は、多次元インデックスを作成し、データをクエリする列を多次元インデックスに追加できます。これにより、多次元インデックスを使用して、列に基づいてデータをクエリできます。 | 基本的なクエリなどの、多次元インデックスによって提供されるクエリメソッドのドキュメント |
ブールクエリ | 複数のフィールドを組み合わせて、データを効率的にクエリできます。この機能は、複数の条件に基づいてデータをフィルタリングする注文システム、ログ分析、ユーザープロファイルなどのシナリオに適しています。 たとえば、注文シナリオのデータテーブルには、数十のフィールドが含まれている場合があります。リレーショナルデータベースでさまざまなフィールドの組み合わせに基づいてデータをクエリするには、数百のインデックスを作成する必要がある場合があります。さらに、事前に組み合わせが考慮されておらず、対応するインデックスが作成されていない場合は、データを効率的にクエリできません。 ただし、Tablestore を使用する場合、多次元インデックスを作成し、データをクエリするフィールドを多次元インデックスに追加するだけで済みます。多次元インデックスを使用してデータをクエリする場合、ビジネス要件に基づいて、多次元インデックス内のフィールドの組み合わせに基づいて条件を指定できます。 多次元インデックスは、AND、OR、NOT などの論理演算子もサポートしています。 | 詳細については、「ブールクエリ」をご参照ください。 |
ジオクエリ | モバイルデバイスの人気が高まるにつれて、地理的な位置データの重要性が増しています。地理的な位置データは、ソーシャルメディア アプリ、フードデリバリー アプリ、スポーツ アプリ、インターネット of Vehicles(IoV)アプリなど、さまざまなアプリで使用されています。地理的な位置データに基づくクエリが必要です。 多次元インデックスは、地理的な位置データに基づく次のクエリ機能をサポートしています。
Tablestore の多次元インデックスを使用すると、他のデータベースサービスや検索エンジンを使用せずに、これらの機能を使用して地理的な位置データをクエリできます。 |
|
全文検索 | 特定の文字列を含むデータをクエリできます。この機能は、ビッグデータ分析、コンテンツ検索、ナレッジ マネジメント、ソーシャルメディア分析、ログ分析、インテリジェントな Q&A システム、コンプライアンス レビュー、インテリジェントおすすめなどのシナリオに適しています。 多次元インデックスは、全文検索をサポートするためにデータをトークン化できます。 多次元インデックスを使用して、BM25 ベースのキーワード関連性スコアのみに基づいてクエリ結果を並べ替えることができます。複雑な関連性スコアに基づいてクエリ結果を並べ替える場合は、検索システムを使用することをお勧めします。 多次元インデックスは、単語トークン化、デリミタトークン化、最小意味単位ベースのトークン化、最大意味単位ベースのトークン化、あいまいトークン化などのトークン化メソッドをサポートしています。要件に基づいてトークン化メソッドを選択できます。クエリ結果でクエリ文字列を強調表示する場合は、強調表示機能を使用できます。 | |
KNN ベクタクエリ | 多次元インデックスは、KNN ベクタクエリ機能を提供します。ベクタを使用して近似最近傍検索を実行することにより、大規模なデータセットで最も類似したデータ項目を見つけることができます。この機能は、検索拡張生成(RAG)、おすすめシステム、画像、動画、音声の類似性検出、自然言語処理(NLP)などのシナリオに適しています。 | 詳細については、「KNN ベクタクエリ」をご参照ください。 |
あいまい検索 | Tablestore の多次元インデックスは、ワイルドカードクエリ、プレフィックスクエリ、およびサフィックスクエリ機能をサポートしており、さまざまなシナリオであいまい検索の要件を満たします。
|
|
Exists クエリ | 行の列が存在するかどうかをクエリできます。Exists クエリは、NULL クエリまたは NULL 値クエリとも呼ばれます。この機能は、データ整合性チェックやデータクレンジングなどのシナリオに適しています。 | 詳細については、「Exists クエリ」をご参照ください。 |
ネストされたクエリ | フラットな構造に加えて、オンライン アプリケーションによって生成されるデータは、タグ付き画像など、複雑で多層的な構造になっていることがよくあります。たとえば、データベースに多数の画像が保存されており、各画像には家、車、人などの複数の要素があります。画像内の各要素には、一意の重みスコアがあります。スコアは、画像内の要素のサイズと位置に基づいて評価されます。したがって、各画像には複数のタグがあります。各タグには、名前と重みスコアがあります。 タグ条件に基づいて画像をフィルタリングする場合は、ネストされたクエリ機能を使用できます。画像タグは JSON 形式で保存されます。例: ネストされたクエリ機能を使用すると、複雑なデータのモデリングを容易にする、多層論理関係を持つデータのストレージとクエリ要件を効率的に処理できます。 JSON などの複雑なデータ構造のネストされたフィールドの場合、強調表示機能を有効にして、必要な情報を正確に特定することもできます。 |
|
折りたたみ(重複排除) | 多次元インデックスは、折りたたみ(重複排除)機能をサポートしており、クエリ結果の多様性を向上させます。この機能は、クエリリクエストのクエリ結果における属性の最大発生回数を制限します。これにより、同じ属性を持つ過剰なクエリ結果が回避されます。たとえば、E コマース シナリオで | 詳細については、「折りたたみ(重複排除)」をご参照ください。 |
並べ替え | Tablestore では、テーブルデータはプライマリキーのアルファベット順に自動的に並べ替えられます。他のフィールドに基づいてデータを並べ替えるには、多次元インデックスの並べ替え機能を使用する必要があります。 多次元インデックスは、1 つ以上の条件に基づいて昇順または降順での並べ替えをサポートしています。並べ替えは、多次元インデックス内のすべてのデータに対してグローバルに実行されます。デフォルトでは、多次元インデックスの返される結果は、データテーブルのプライマリキーに基づいて並べ替えられます。 |
|
すべてに一致するクエリ | 多次元インデックスを使用してデータをクエリする場合、クエリ条件を満たす行の総数を Tablestore が返すように指定できます。この機能は、データ検証やデータドリブン操作などのシナリオに適しています。
|
|
集約 | 多次元インデックスを使用すると、集約操作を実行して、最大値、最小値、平均値、合計、行の数と重複を除いた数、パーセンタイル、ヒストグラム統計を取得できます。また、多次元インデックスを使用して結果をグループ化することもできます。これにより、軽量の統計分析を実行できます。 | 詳細については、「集約」をご参照ください。 |
サポートされているリージョン
多次元インデックス機能は、中国(杭州)、中国(上海)、中国(青島)、中国(北京)、中国(張家口)、中国(ウランチャブ)、中国(深セン)、中国(広州)、中国(成都)、中国(香港)、日本(東京)、シンガポール、マレーシア(クアラルンプール)、インドネシア(ジャカルタ)、フィリピン(マニラ)、タイ(バンコク)、ドイツ(フランクフルト)、英国(ロンドン)、米国(シリコンバレー)、米国(バージニア)、SAU(リヤド - パートナーリージョン)でご利用いただけます。KNN ベクタクエリ機能は、米国(シリコンバレー)リージョンではサポートされていません。
ディザスタリカバリ機能
デフォルトでは、多次元インデックスは、ゾーン冗長ストレージ(ZRS)機能をサポートするリージョンで、ゾーン冗長ディザスタリカバリ機能を提供します。リージョンでは、データは複数のゾーンに保存されます。ゾーンで停電、ネットワーク停止、火災などの障害が発生した場合でも、データの読み取りと書き込みは影響を受けません。
多次元インデックスは、中国(北京)、中国(上海)、中国(杭州)、中国(深セン)、中国(張家口)、中国(ウランチャブ)、中国(香港)、日本(東京)、インドネシア(ジャカルタ)、シンガポール、ドイツ(フランクフルト)の各リージョンで ZRS 機能をサポートしています。
生存時間
データテーブルで UpdateRow 操作が無効になっている場合は、データテーブルに作成された多次元インデックスの生存時間(TTL)機能を使用できます。詳細については、「多次元インデックスの TTL の指定」をご参照ください。
一定期間だけデータを保持し、時間フィールドを更新する必要がない場合は、時間フィールドに基づいてデータテーブルを複数のデータテーブルにパーティション分割することで TTL 機能を実装できます。次の表に、時間によるテーブルパーティショニングの原則、ルール、および利点を示します。
項目 | 時間によるテーブルパーティショニング |
原則 | 日次、週次、月次、年次など、一定期間に基づいてデータテーブルをパーティション分割します。次に、パーティション分割された各テーブルに多次元インデックスを作成します。これにより、ビジネス要件に基づいて、指定された期間、テーブルを保持できます。 たとえば、6 か月間データを保持するには、各月のデータをデータテーブルに保存します。データテーブルに table_1 から table_6 までのラベルを順番に付け、各データテーブルに多次元インデックスを作成します。各データテーブルとその多次元インデックスには、それぞれの月のデータのみが保存されていることを確認してください。TTL 機能を実装するには、6 か月以上保持されているデータテーブルとそれに関連付けられた多次元インデックスを削除するだけで済みます。 多次元インデックスを使用してデータをクエリする場合、データテーブルに必要な時間範囲内のすべてのデータが含まれている場合は、特定のデータテーブルのみをクエリする必要があります。必要な時間範囲内のデータが複数のデータテーブルにまたがる場合は、これらのすべてのデータテーブルをクエリし、クエリ結果をマージする必要があります。 |
ルール | 1 つの多次元インデックスのサイズは最大 500 億行まで可能です。最適なクエリ パフォーマンスを確保するために、1 つの多次元インデックスのサイズを 200 億行以下に制限することをお勧めします。 |
利点 |
|
バージョンの最大数
max versions パラメータを指定したデータテーブルの多次元インデックスは作成できません。
単一バージョンのみを許可する列にデータを書き込むときに、タイムスタンプを指定できます。バージョン番号が大きいデータを先に書き込み、次にバージョン番号が小さいデータを書き込むと、バージョン番号が大きいデータがバージョン番号が小さいデータによって上書きされる場合があります。
Search リクエストと ParallelScan リクエストの結果には、タイムスタンプ属性が含まれていない場合があります。
制限
多次元インデックスは、データテーブルからデータを非同期的に同期します。データ遅延が発生し、データをリアルタイムでクエリすることはできません。遅延は通常 3 秒未満です。 多次元インデックスの制限の詳細については、「多次元インデックスの制限」をご参照ください。
課金
多次元インデックスを作成すると、多次元インデックスのデータはストレージスペースを占有します。 多次元インデックスを使用してデータのクエリと分析を行うと、計算リソースが消費されます。ストレージの使用量と消費された計算リソースに対して課金されます。詳細については、「課金の概要」をご参照ください。
開発統合
API 操作
Tablestore は、多次元インデックスを管理し、多次元インデックスを使用してデータをクエリするための API 操作を提供します。Search または ParallelScan 操作を呼び出して、データをクエリできます。2 つの API 操作によって提供されるほとんどの機能は同じです。ただし、パフォーマンスとスループットを向上させるために、ParallelScan 操作では Search 操作の一部の機能は提供されていません。
カテゴリ | 操作 | 説明 |
インデックス管理 | 多次元インデックスを作成します。 | |
TTL とスキーマ構成を含む、多次元インデックスの構成を更新します。 | ||
多次元インデックスの詳細をクエリします。 | ||
多次元インデックスのリストをクエリします。 | ||
多次元インデックスを削除します。 | ||
データクエリ | 多次元インデックスのすべての機能をサポートしています。Search 操作を呼び出して、サポートされているすべてのクエリメソッドを使用してデータをクエリし、並べ替えと集約操作を実行してデータを分析できます。クエリ結果は、指定された順序で返されます。
| |
データを並列でエクスポートします。ParallelScan 操作を呼び出して、サポートされているすべてのクエリメソッドを使用してデータをクエリできます。ただし、クエリ結果の取得を高速化するために、ParallelScan 操作では、並べ替えや集約などの分析機能はサポートされていません。 ParallelScan 操作は、Search 操作と比較して優れたクエリ パフォーマンスを提供します。ParallelScan 操作が並列スキャン タスクを含む単一のクエリリクエストを処理する場合、そのスループットは Search 操作の 5 倍です。
この操作を呼び出すときは、ComputeSplits 操作を呼び出して、1 つの ParallelScan リクエストの並列スキャン タスクの最大数をクエリする必要があります。 |
統合方法
Tablestore SDK または Tablestore CLI を使用して、多次元インデックスに対する操作を実行できます。
詳細については、「Tablestore コンソールでの多次元インデックスの使用」をご参照ください。
詳細については、「Tablestore CLI の使用」をご参照ください。
Tablestore SDK の使用
Java 用 Tablestore SDK:詳細については、「多次元インデックス」をご参照ください。
Go 用 Tablestore SDK:詳細については、「多次元インデックス」をご参照ください。
Python 用 Tablestore SDK:詳細については、「多次元インデックス」をご参照ください。
Node.js 用 Tablestore SDK:詳細については、「多次元インデックス」をご参照ください。
.NET 用 Tablestore SDK:詳細については、「多次元インデックス」をご参照ください。
PHP 用 Tablestore SDK:詳細については、「多次元インデックス」をご参照ください。
FAQ
詳細については、「セカンダリインデックスと多次元インデックスの選択方法」をご参照ください。
詳細については、「多次元インデックスに対して Search 操作を呼び出したときにデータが見つからない場合の対処方法」をご参照ください。
詳細については、「GetRange 操作と Search 操作の違い」をご参照ください。
詳細については、「Tablestore は JSON 形式でのデータの保存をサポートしていますか?」をご参照ください。
詳細については、「テーブルの行の総数をクエリする方法」をご参照ください。
詳細については、「Tablestore は IN 演算子と BETWEEN...AND 演算子をサポートしていますか?」をご参照ください。
詳細については、「多次元インデックス機能の Search 操作を呼び出してデータをクエリするときに、limit パラメータの値を 1000 に増やす方法」をご参照ください。
詳細については、「多次元インデックスを使用するときに、予約済み読み取り CU が生成されるのはなぜですか?」をご参照ください。
詳細については、「多次元インデックスの予約済み読み取り CU 設定を変更できますか?」をご参照ください。
詳細については、「容量型インスタンスで多次元インデックスを使用するときに、パフォーマンス専有型のストレージと読み取り/書き込み CU の料金が発生するのはなぜですか?」をご参照ください。
詳細については、「多次元インデックスの計測データを表示する方法」をご参照ください。
詳細については、「予約済み CU プランを使用して、多次元インデックスの予約済み読み取りスループットに対して発生する料金を相殺できますか?」をご参照ください。
参照
付録:SQL 文と多次元インデックスの機能のマッピング
多次元インデックスの一部の機能は、特定の SQL 文と同等です。次の表に、SQL 文と多次元インデックスの機能のマッピングを示します。
SQL | 多次元インデックス機能 | 参照 |
Show | DescribeSearchIndex | 詳細については、「多次元インデックスの説明のクエリ」をご参照ください。 |
Select | クエリの ColumnsToGet パラメータ | 基本的なクエリなどの、多次元インデックスによって提供されるクエリメソッドのドキュメント |
From | クエリの IndexName パラメータ 重要 単一列インデックスはサポートされています。複数列インデックスはサポートされていません。 | 基本的なクエリなどの、多次元インデックスによって提供されるクエリメソッドのドキュメント |
Where | クエリの条件 | 基本的なクエリなどの、多次元インデックスによって提供されるクエリメソッドのドキュメント |
Order by | クエリの sort パラメータ | 詳細については、「並べ替えとページングの実行」をご参照ください。 |
Limit | クエリの limit パラメータ | 詳細については、「並べ替えとページングの実行」をご参照ください。 |
Delete |
| |
Like | WildcardQuery | 詳細については、「ワイルドカードクエリ」をご参照ください。 |
And | BoolQuery の operator = and | 詳細については、「ブールクエリ」をご参照ください。 |
Or | BoolQuery の operator = or | |
Not | BoolQuery(mustNotQueries) | |
Between | RangeQuery | 詳細については、「範囲クエリ」をご参照ください。 |
Null | ExistsQuery | 詳細については、「Exists クエリ」をご参照ください。 |
In | TermsQuery | 詳細については、「Terms クエリ」をご参照ください。 |
Min | 集約:min | 詳細については、「集約」をご参照ください。 |
Max | 集約:max | |
Avg | 集約:avg | |
Count | 集約:count | |
Count(distinct) | 集約:distinctCount | |
Sum | 集約:sum | |
Group By | GroupBy |