検索インデックスは、LONG、DOUBLE、BOOLEAN、KEYWORD、TEXT などの基本的なフィールドタイプの他に、NESTED フィールドタイプもサポートしています。NESTED はネストされたドキュメントを示します。ネストされたドキュメントは、データの行(ドキュメント)に複数の子行(子ドキュメント)が含まれている場合に使用されます。複数の子行は NESTED フィールドに格納されます。このトピックでは、SQL クエリ機能を使用して NESTED フィールドのデータをクエリする方法について説明します。
NESTED タイプの詳細については、ARRAY および Nested フィールドタイプを参照してください。
使用上の注意
NESTED フィールドのデータをクエリする場合、関連するテーブルの NESTED フィールドのデータは STRING タイプである必要があります。フィールドの検索インデックスを作成する場合、インデックスフィールドのデータ型を NESTED に設定し、インデックスフィールドの子フィールドのデータとデータ型を正しく指定する必要があります。
データ型マッピング
テーブルのデータ型 | 検索インデックスのデータ型 | SQL のデータ型 |
STRING | NESTED。子フィールドのデータ型は、子フィールドに書き込まれるデータの型と同じです。 |
|
検索インデックスのマッピングテーブルを作成する
SQL ステートメントを実行して NESTED フィールドのデータをクエリする場合、検索インデックスのマッピングテーブルを作成する必要があります。検索インデックスのマッピングテーブルの作成方法の詳細については、検索インデックスのマッピングテーブルを作成するを参照してください。
CREATE TABLE ステートメントでは、NESTED フィールドの有効な名前と、SQL でマッピングされたデータ型を指定する必要があります。NESTED フィールドの子フィールドは自動的に作成されます。検索インデックスのマッピングテーブルを作成する場合は、SQL で NESTED フィールドのデータ型として MEDIUMTEXT を指定することをお勧めします。
ALTER TABLE ステートメントを実行して NESTED フィールドを作成または削除すると、NESTED フィールドの子フィールドは自動的に作成または削除されます。
次の SQL ステートメントの例は、NESTED フィールドを含む検索インデックスのマッピングテーブルを作成する方法を示しています。
CREATE TABLE `test_table__test_table_index`(
`col_nested` MEDIUMTEXT
)
ENGINE='searchindex'
ENGINE_ATTRIBUTE='{"index_name":"test_table_index", "table_name":"test_table"}';SQL ステートメントを実行してデータをクエリする
SQL ステートメントを実行して NESTED フィールドのデータをクエリする場合、NESTED フィールドの子フィールドを演算子と一緒に直接使用して、col_nested.col_long= 1 などのクエリ条件を指定できます。また、NESTED_QUERY(subcol_column_condition) 関数を使用してクエリ条件を指定することもできます。実際のシナリオでは、クエリ要件に基づいて、上記のいずれかの方法を選択します。関数の subcol_column_condition は、同じレベルの子フィールドをクエリするための条件を示します。
NESTED フィールドを使用してクエリ条件を指定する場合は、'NESTED フィールド名.子フィールド名' の形式で NESTED フィールドの子フィールドの名前を指定します。NESTED フィールドに複数レベルのフィールドが含まれている場合は、データクエリのために、前の子フィールド名の後に子フィールドの名前を追加できます。子フィールド名はピリオド(.)で区切ります。たとえば、NESTED フィールドの名前が col_nested で、NESTED フィールドの子フィールドの名前が col_long の場合、クエリ条件では子フィールドの名前は 'col_nested.col_long' になります。NESTED フィールドの名前が col1 で、col1 NESTED フィールドに col2 という名前の子フィールドがあり、col2 子フィールドに col3 という名前の子フィールドがある場合、クエリ条件では col3 子フィールドの名前は 'col1.col2.col3' になります。
NESTED_QUERY(subcol_column_condition) 関数を使用してクエリ条件を指定する場合、行の子フィールドの JSON 要素はすべてのクエリ条件を満たす必要があります。
この例では、NESTED フィールドの名前は tags で、NESTED フィールドの 1 行のみに 2 つの JSON 要素が含まれています:[{"tagName":"tag1", "score":0.8} and {"tagName":"tag2", "score":0.2}]。次のステートメントの例は、NESTED フィールドのデータをクエリするために使用される 2 つの方法の違いを説明しています。
NESTED フィールドの子フィールドを演算子と一緒に使用する
SQL ステートメントの例:
SELECT tags FROM `test_table__test_table_index` WHERE `tags.tagName` = 'tag1' AND `tags.score` = 0.2;行の最初の JSON 要素は
'tags.tagName' = 'tag1'クエリ条件を満たし、行の 2 番目の JSON 要素は'tags.score' = 0.2クエリ条件を満たします。したがって、次の結果が返されます。[{"tagName":"tag1", "score":0.8}, {"tagName":"tag2", "score":0.2}]NESTED_QUERY(subcol_column_condition)関数を使用するSQL ステートメントの例:
SELECT tags FROM `test_table__test_table_index` WHERE NESTED_QUERY(`tags.tagName` = 'tag1' AND `tags.score` = 0.2);'tags.tagName' = 'tag1'と'tags.score' = 0.2の両方のクエリ条件を満たす JSON 要素はありません。したがって、結果は返されません。
制限事項
NESTED_QUERY(subcol_column_condition)関数を使用して、同じレベルの NESTED フィールドの子フィールドをクエリできます。NESTED フィールドの行でクエリされる JSON 要素は、すべてのクエリ条件を満たす必要があります。SQL ステートメントの例:SELECT * FROM `test_table__test_table_index` WHERE NESTED_QUERY(`col1.col2` = 1 AND NESTED_QUERY(`col1.col3.col4` = 2));NESTED フィールドの子フィールドを演算子または
NESTED_QUERY(subcol_column_condition)関数と一緒に使用できるのは、検索インデックスのマッピングテーブル内のみです。NESTED_QUERY(subcol_column_condition)関数を使用して指定できる式は 1 つだけです。複数の式を接続するには、AND や OR などの論理演算子を使用する必要があります。この関数は SELECT ステートメントの WHERE 句としてのみ使用でき、SELECT ステートメントの列式、集計関数、またはソートには使用できません。NESTED フィールドは、SELECT ステートメントのフィールド名または列式、あるいは集計関数として使用できません。NESTED フィールドは、グループ化またはソートに使用できません。
ALTER TABLEステートメントを使用して NESTED フィールドを作成または削除する場合、NESTED フィールドの子フィールドを直接作成または削除することはできません。テーブルに存在する NESTED フィールドのみを作成または削除できます。NESTED フィールドの子フィールドは自動的に作成または削除されます。NESTED フィールドの子フィールドのデータは、データ型の変換後、または検索インデックスの関数にプッシュダウンして計算することはできません。NESTED フィールドの子フィールドのデータをクエリする場合は、NESTED フィールドの子フィールドのデータ型が有効であることを確認してください。
例
次の例では、データがクエリされるテーブルの名前は test_table で、テーブルには STRING 型の col_nested フィールドが含まれています。
SQL ステートメントを実行してテーブルの NESTED フィールドのデータをクエリする場合、テーブルの検索インデックスを作成し、検索インデックスのマッピングテーブルを作成する必要があります。これを行うには、次の手順を実行します。
検索インデックスを作成します。詳細については、Tablestore コンソールで検索インデックスを使用するまたはTablestore SDK を使用するを参照してください。
検索インデックスの名前は
test_table_indexです。検索インデックスには、NESTED 型のcol_nestedフィールドが含まれています。次の図は、Tablestore コンソールを使用して検索インデックスを作成する方法を示しています。
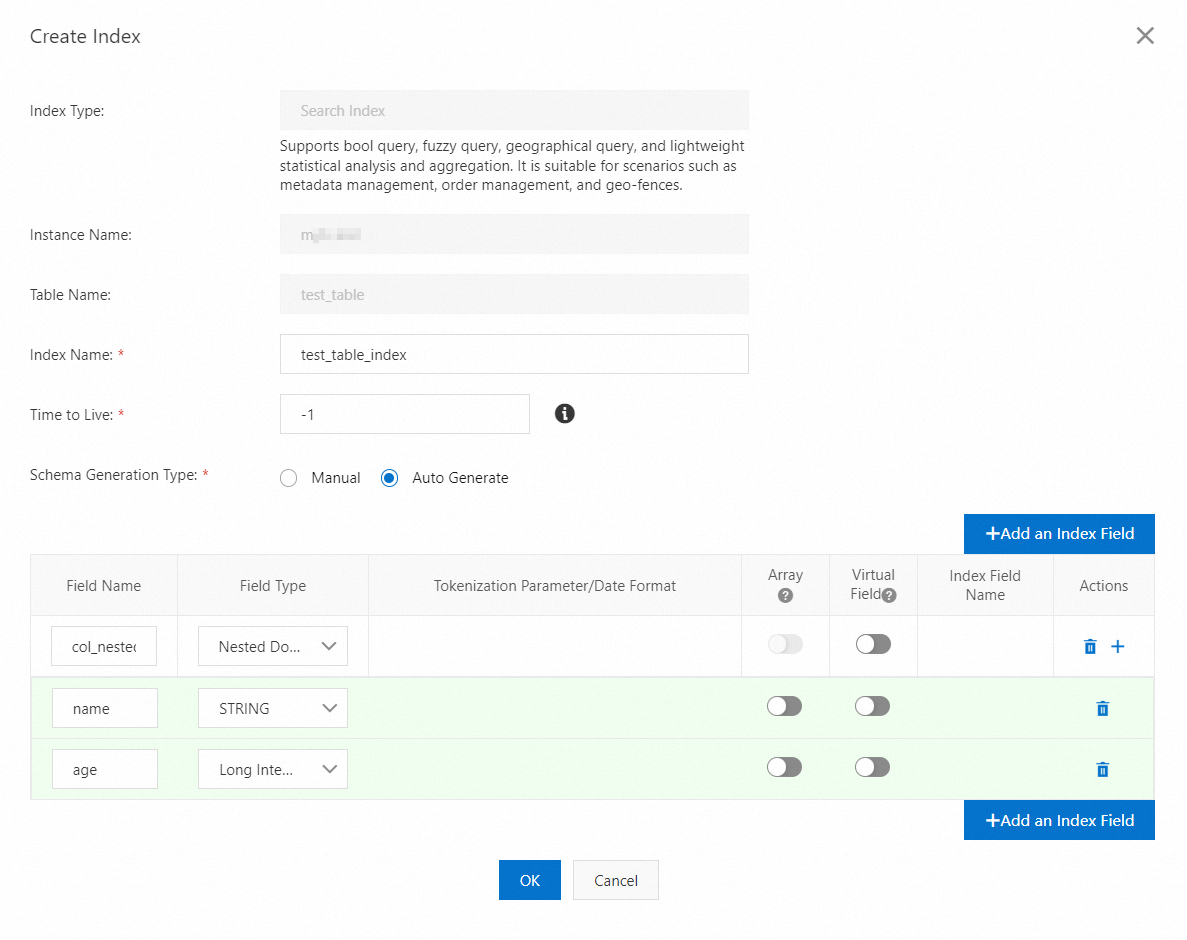
検索インデックスのマッピングテーブルを作成します。詳細については、検索インデックスのマッピングテーブルを作成するを参照してください。
検索インデックスのマッピングテーブルの名前は
test_table__test_table_indexで、マッピングテーブルのcol_nestedフィールドの SQL データ型はMEDIUMTEXTです。SQL ステートメントの例:
CREATE TABLE `test_table__test_table_index`( `col_nested` MEDIUMTEXT ) ENGINE='searchindex' ENGINE_ATTRIBUTE='{"index_name":"test_table_index", "table_name":"test_table"}';test_table_index のマッピングテーブルを作成したら、ビジネス要件に基づいて次の操作を実行します。
テーブルの説明をクエリします。詳細については、テーブルに関する情報をクエリするを参照してください。
次のステートメントを実行して、
test_table__test_table_indexの説明をクエリします。DESCRIBE `test_table__test_table_index`;次の図は、クエリ結果を示しています。NESTED フィールド
col_nestedの子フィールドnameとageは自動的に作成されます。name 子フィールドの名前はcol_nested.nameで、age 子フィールドの名前はcol_nested.ageです。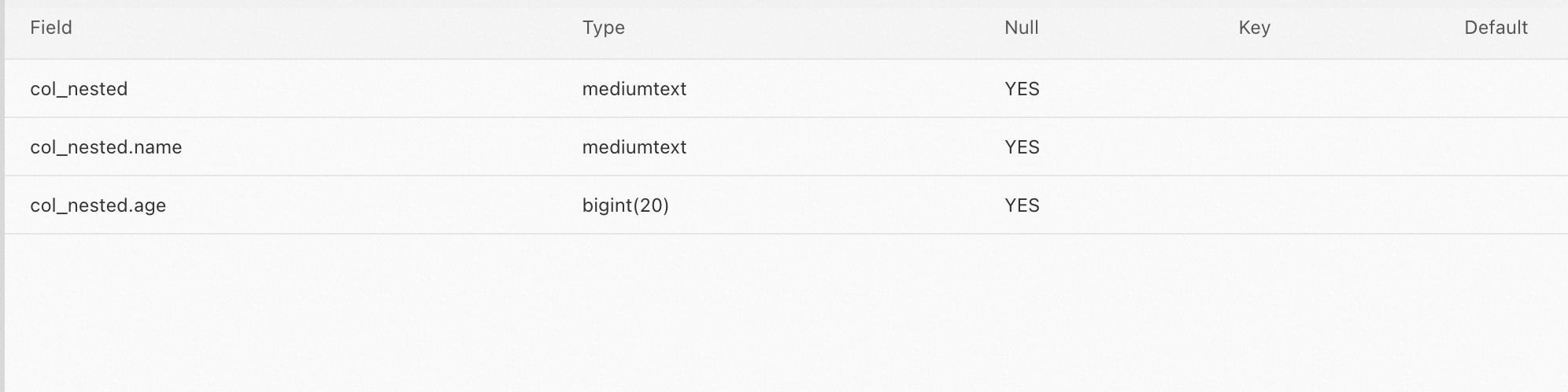
テーブルからデータをクエリします。
次のステートメントを実行して、test_table__test_table_index からデータをクエリします。
SELECT * FROM `test_table__test_table_index`;次の図は、クエリ結果を示しています。この例では、
test_table__test_table_indexマッピングテーブルには 5 つのデータレコードが含まれています。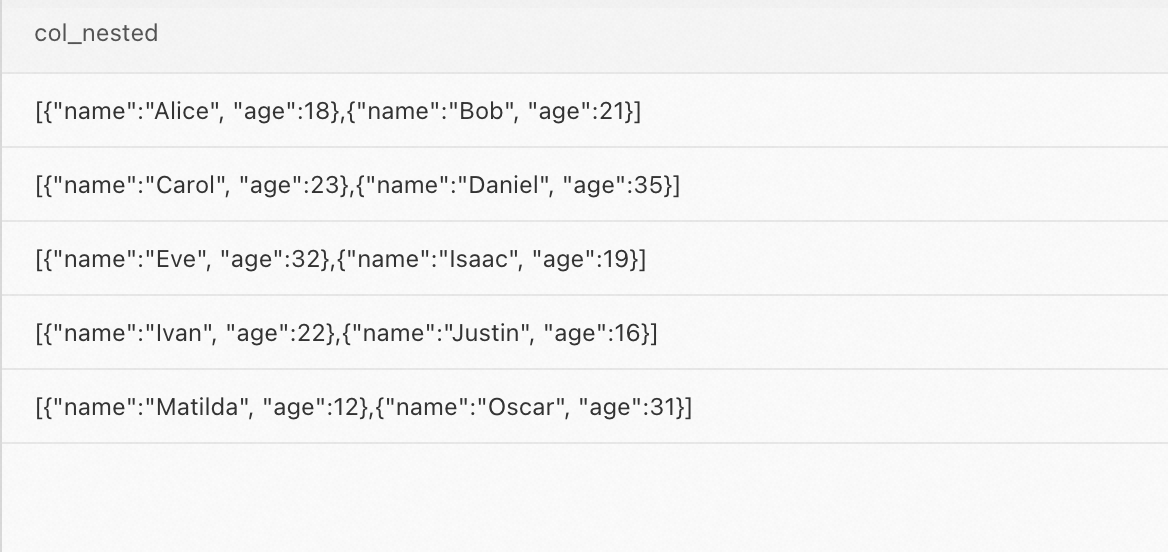
SELECT ステートメントを実行してデータをクエリします。
例 1:
col_long_arrayから、値が 30 より大きいageを含む配列要素を持つ行をクエリします。SELECT * FROM `test_table__test_table_index` WHERE `col_nest.age` >30;次の図は、クエリ結果を示しています。

例 2:
col_long_arrayから、1 つ以上の JSON 要素に、値がIで始まるnameと、値が 20 未満のageが含まれる行をクエリします。SELECT * FROM `test_table__test_table_index` WHERE `col_nested.name` like 'I%' AND `col_nested.age` < 20;次の図は、クエリ結果を示しています。
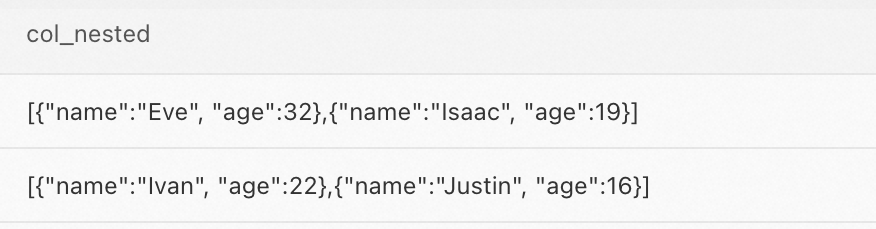
例 3:
col_long_arrayから、値がIで始まるnameと、値が 20 未満のageを含む JSON 要素をクエリします。この例では、
NESTED_QUERY(subcol_column_condition)関数が必要です。SELECT * FROM `test_table__test_table_index` WHERE NESTED_QUERY(`col_nested.name` like 'I%' AND `col_nested.age` < 20);次の図は、クエリ結果を示しています。
