Tablestore を Grafana に接続した後、Grafana を使用して Tablestore のデータを可視化します。
前提条件
Resource Access Management (RAM) コンソールで、次の操作を実行していること。
RAM ユーザーを作成し、RAM ユーザーに Tablestore を管理する権限 (AliyunOTSFullAccess) を付与していること。
警告Alibaba Cloud アカウントの AccessKey ペアが漏洩すると、クラウドリソースが危険にさらされます。RAM ユーザーの AccessKey ペアを使用して操作を実行することを推奨します。これにより、AccessKey ペアが漏洩した場合のセキュリティリスクが軽減されます。
Tablestore コンソールで、次の操作を実行していること。
Tablestore を有効化し、インスタンスを作成していること。
テーブルのマッピングを作成し、多値モデルのマッピングを作成していること。
オープンソースの Grafana をインストールしていること。Grafana のバージョンは 8.0.0 以降である必要があります。このトピックでは、Grafana v10.4.2 を例として使用します。詳細については、「Grafana 公式ドキュメント」をご参照ください。
背景情報
Grafana は、Prometheus、Graphite、OpenTSDB、InfluxDB、Elasticsearch、MySQL、PostgreSQL などのさまざまなデータソースのデータクエリと可視化をサポートするオープンソースの可視化および分析プラットフォームです。詳細については、「Grafana 公式ドキュメント」をご参照ください。
Tablestore を Grafana に接続した後、Grafana を使用してテーブルデータに基づいてダッシュボードパネルを生成し、データをリアルタイムで表示します。
使用上の注意
Grafana を使用して、中国 (杭州)、中国 (上海)、中国 (北京)、中国 (張家口)、中国 (深圳)、シンガポールの各リージョンで Tablestore データを可視化できます。
ステップ 1: Tablestore プラグインのインストール
Windows
Tablestore 用 Grafana プラグインパッケージをダウンロードします。
パッケージを解凍し、プラグインファイルを Grafana インストールの plugins-bundled ディレクトリに移動します。
Grafana 構成ファイルを変更します。
テキストエディターを使用して、conf ディレクトリにある defaults.ini 構成ファイルを開きます。
構成ファイルの [plugins] セクションで、allow_loading_unsigned_plugins パラメーターを設定します。
allow_loading_unsigned_plugins = aliyun-tablestore-grafana-datasource
タスクマネージャーで、grafana-server.exe プロセスを再起動します。
Mac/Linux
次のコマンドを実行して、Tablestore 用の Grafana プラグインパッケージをダウンロードします。
wget https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20220527/ygdf/tablestore-grafana-plugin-1.0.0.zipパッケージを Grafana プラグインディレクトリに解凍します。
Grafana のインストール方法に対応するコマンドを実行します。
Yellowdog Updater, Modified (YUM) リポジトリまたは RPM Package Manager (RPM) パッケージから Grafana をインストールした場合 (Linux のみ): unzip tablestore-grafana-plugin-1.0.0.zip -d /var/lib/grafana/plugins
.zip ファイルから Grafana をインストールした場合: unzip tablestore-grafana-plugin-1.0.0.zip -d {PATH_TO}/grafana-{VERSION}/data/plugins
説明コマンドの
{PATH_TO}/grafana-{VERSION}は Grafana のインストールパスを指定し、{VERSION}は Grafana のバージョン番号を指定します。
Grafana 構成ファイルを変更します。
構成ファイルを開きます。
YUM リポジトリまたは RPM パッケージから Grafana をインストールした場合 (Linux のみ): /etc/grafana/grafana.ini
.zip ファイルから Grafana をインストールした場合: {PATH_TO}/grafana-{VERSION}/conf/defaults.ini
説明パスの
{PATH_TO}/grafana-{VERSION}は Grafana のインストールパスを指定し、{VERSION}は Grafana のバージョン番号を指定します。
構成ファイルの [plugins] セクションで、allow_loading_unsigned_plugins パラメーターを設定します。
allow_loading_unsigned_plugins = aliyun-tablestore-grafana-datasource
Grafana を再起動します。
kill コマンドを実行して Grafana プロセスを停止します。
インストール方法に対応するコマンドを実行して Grafana を起動します。
YUM リポジトリまたは RPM パッケージから Grafana をインストールした場合 (Linux のみ): systemctl restart grafana-server
.zip ファイルから Grafana をインストールした場合: ./bin/grafana-server web
ステップ 2: データソースの構成
Grafana にログインします。
ブラウザで
http://<x.x.x.x>:3000/と入力して Grafana ログインページを開きます。説明<x.x.x.x>は Grafana がデプロイされているサーバーの IP アドレスを指定します。たとえば、Grafana が Windows 環境にインストールされている場合、ログインアドレスはhttp://localhost:3000です。メールアドレスまたはユーザー名とパスワードを入力し、[ログイン] をクリックします。
説明デフォルトのユーザー名とパスワードはどちらも admin です。初めてログインすると、パスワードの変更を求められます。
Grafana のホームページで、左上隅にある
 アイコンをクリックします。
アイコンをクリックします。左側のナビゲーションウィンドウで、 を選択します。
[データソース] ページで、[+ 新しいデータソースを追加] をクリックします。
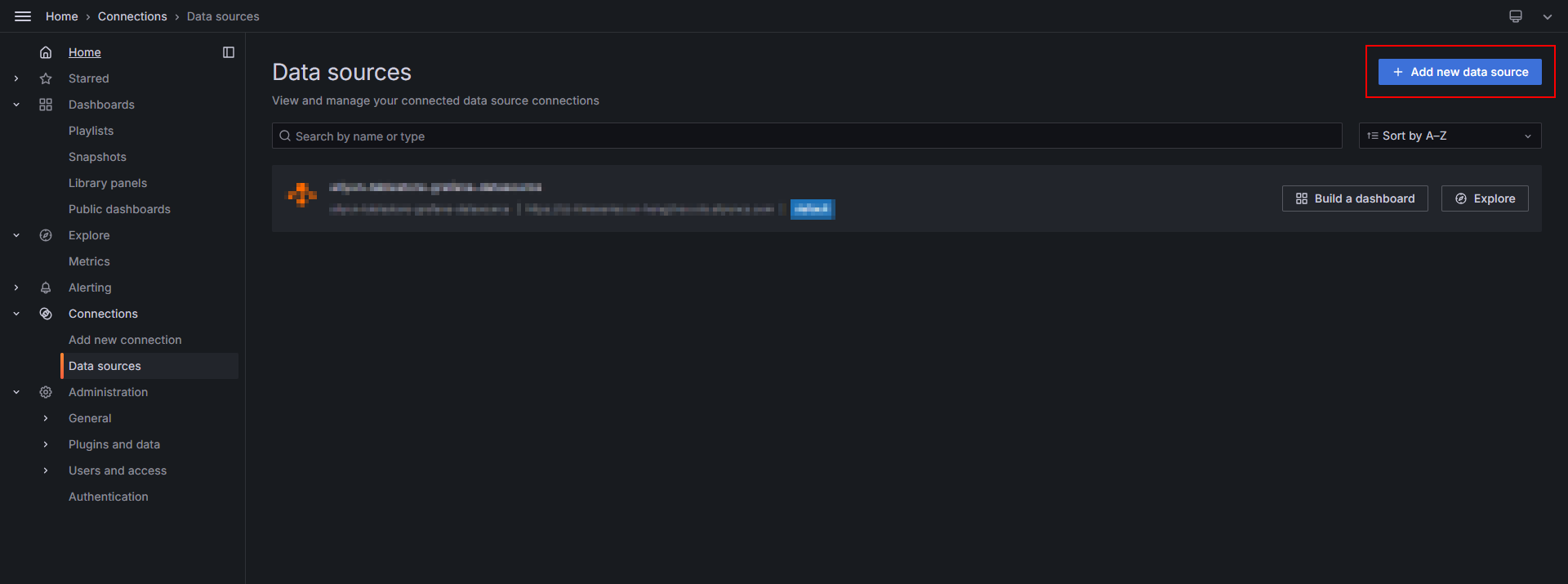
[データソースの追加] ページの [その他] セクションで、[aliyun-tablestore-grafana-datasource] をクリックします。
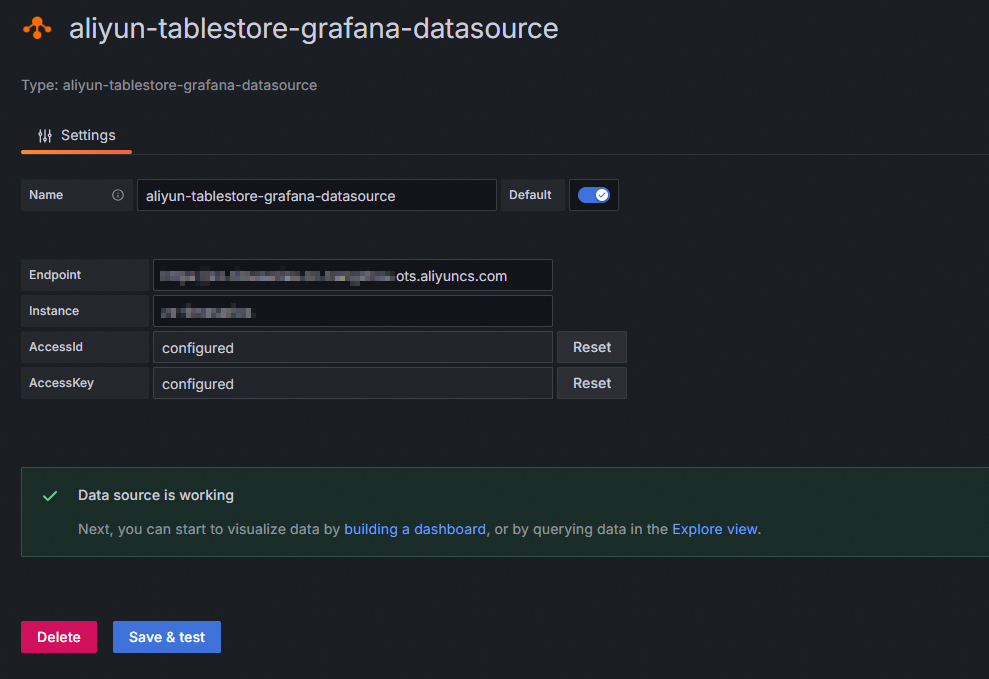
[設定] ページで、次の表の説明に従ってパラメーターを構成します。
パラメーター
例
説明
名前
aliyun-tablestore-grafana-datasource
データソースの名前。カスタム名を入力できます。デフォルト値は aliyun-tablestore-grafana-datasource です。
エンドポイント
https://myinstance.cn-hangzhou.ots.aliyuncs.com
Tablestore インスタンスのエンドポイント。アクセスするインスタンスのエンドポイントを入力します。詳細については、「エンドポイント」をご参照ください。
インスタンス
myinstance
Tablestore インスタンスの名前。
AccessId
************************
Tablestore へのアクセス権限を持つ Alibaba Cloud アカウントまたは RAM ユーザーの AccessKey ID。
AccessKey
********************************
Tablestore へのアクセス権限を持つ Alibaba Cloud アカウントまたは RAM ユーザーの AccessKey シークレット。
[保存 & テスト] をクリックします。
接続に成功すると、[データソースは動作しています] というメッセージが表示されます。
ステップ 3: ダッシュボードパネルの作成
Grafana のホームページで、左上隅にある
アイコンをクリックします。左側のナビゲーションウィンドウで、[ダッシュボード] をクリックします。
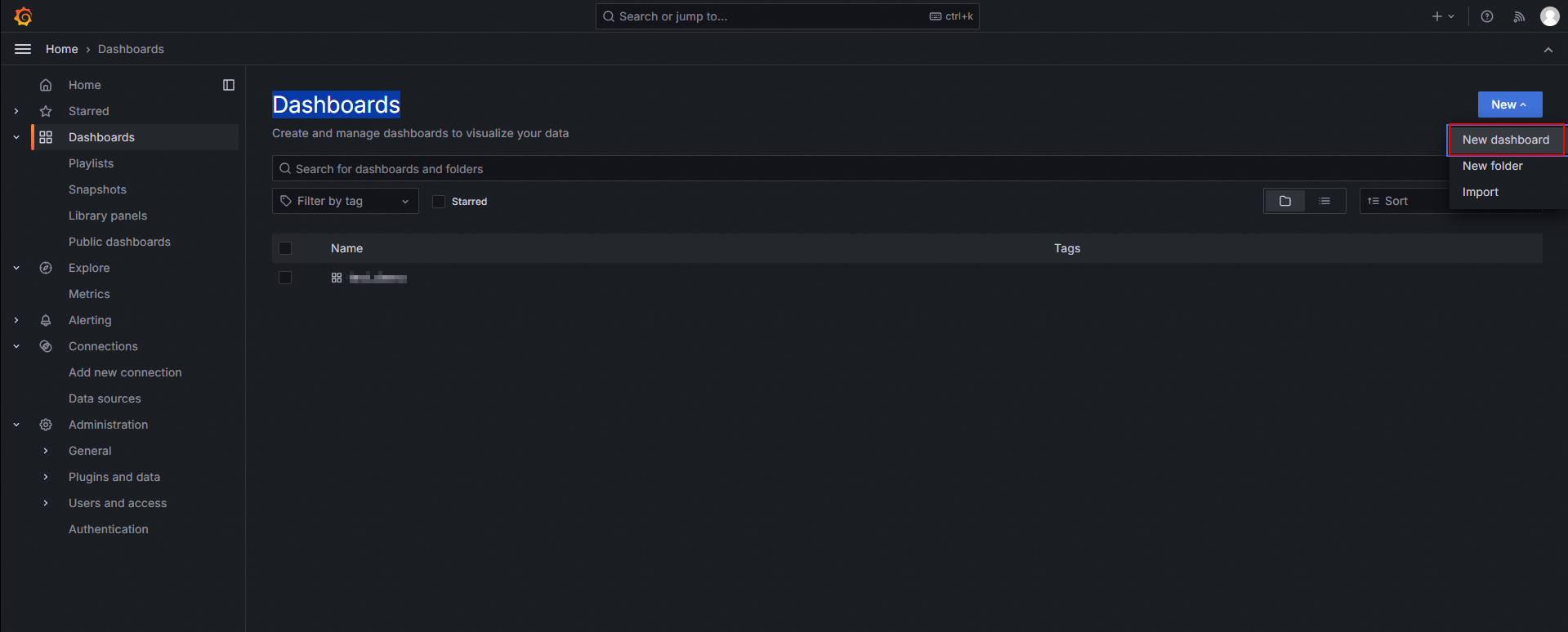
[ダッシュボード] ページで、[新規] をクリックし、[新しいダッシュボード] を選択します。
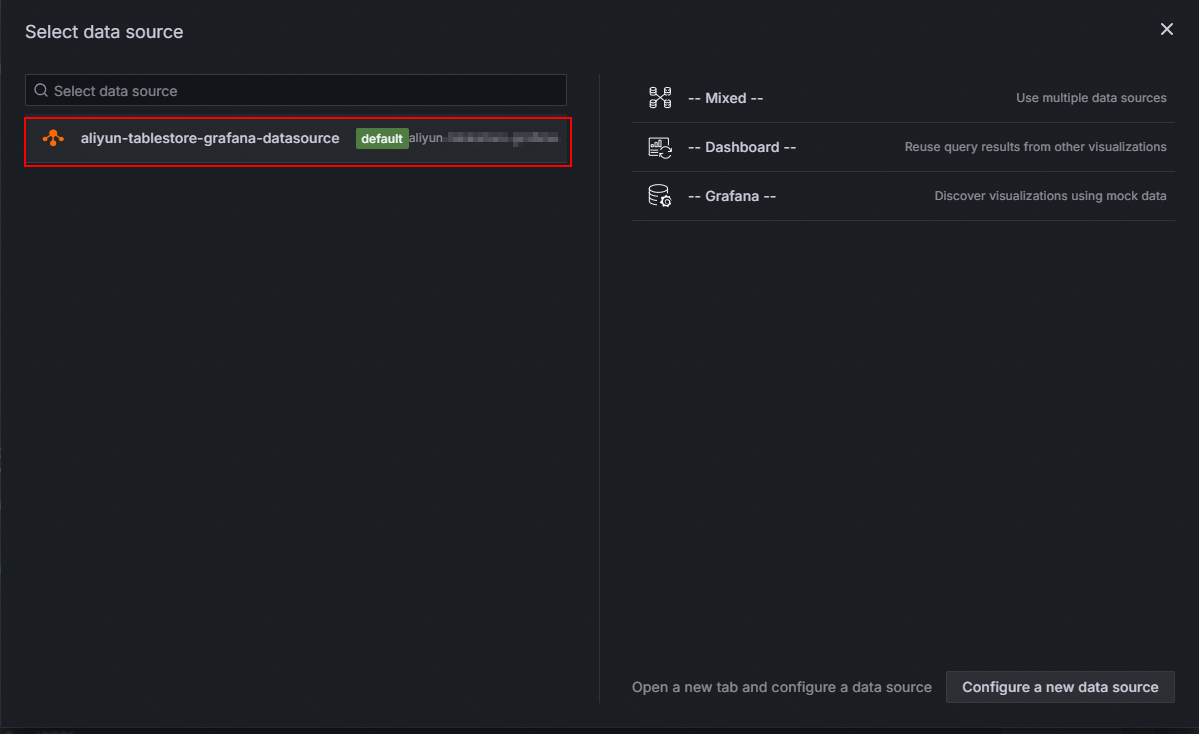
[新しいダッシュボード] ページで、[+ 可視化を追加] をクリックします。
[データソースの選択] ダイアログボックスで、構成済みの Tablestore データソースを選択します。
[編集] ページの [クエリ] セクションで、クエリ条件を構成します。
次の表にパラメーターを説明します。
パラメーター
例
説明
クエリ
SELECT * FROM your_table WHERE $__unixMicroTimeRangeFilter(_time)AND _m_name = "your_measurement" AND tag_value_at(_tags, "your_tag")="your_tag_value"LIMIT 1000SQL クエリ文。詳細については、「データのクエリ」をご参照ください。
重要WHERE 句では、例の
$__unixMicroTimeRangeFilterのように、定義済みのマクロを使用して時間範囲でデータをフィルター処理する必要があります。その他の時間マクロを表示するには、構成ページで [ヘルプの表示] をクリックします。時系列グラフにデータを表示する場合、クエリは数値タイムスタンプで表される時間列を返す必要があります。また、時間列の名前を構成する必要もあります。
フォーマット形式
Timeseries
結果のフォーマット。有効値:
Timeseries (デフォルト): 標準の時系列グラフ。
FlowGraph: 多次元グラフ。
Table: 標準テーブル。
時間列
_time
返されたデータの時間列の名前。時間列は、時系列グラフの x 軸として使用されます。このパラメーターは、[フォーマット形式] を [Timeseries] または [FlowGraph] に設定した場合に使用できます。
集計列
_field_name#:#_double_value
同じ時点の複数行の単一列データを、単一行の複数列データに変換します。これは、Tablestore 時系列 SQL クエリからの単一値モデルデータを多値モデルデータに変換するのに役立ちます。このパラメーターは、[フォーマット形式] を [FlowGraph] に設定した場合に使用できます。フォーマットは
<データポイント名列>#:#<値列>です。[SQL の実行] をクリックして SQL 文を実行し、データを表示してデバッグします。
ダッシュボードパネルを構成して保存します。
右側のペインで、モニタリングチャートの名前、タイプ、表示スタイルを設定します。
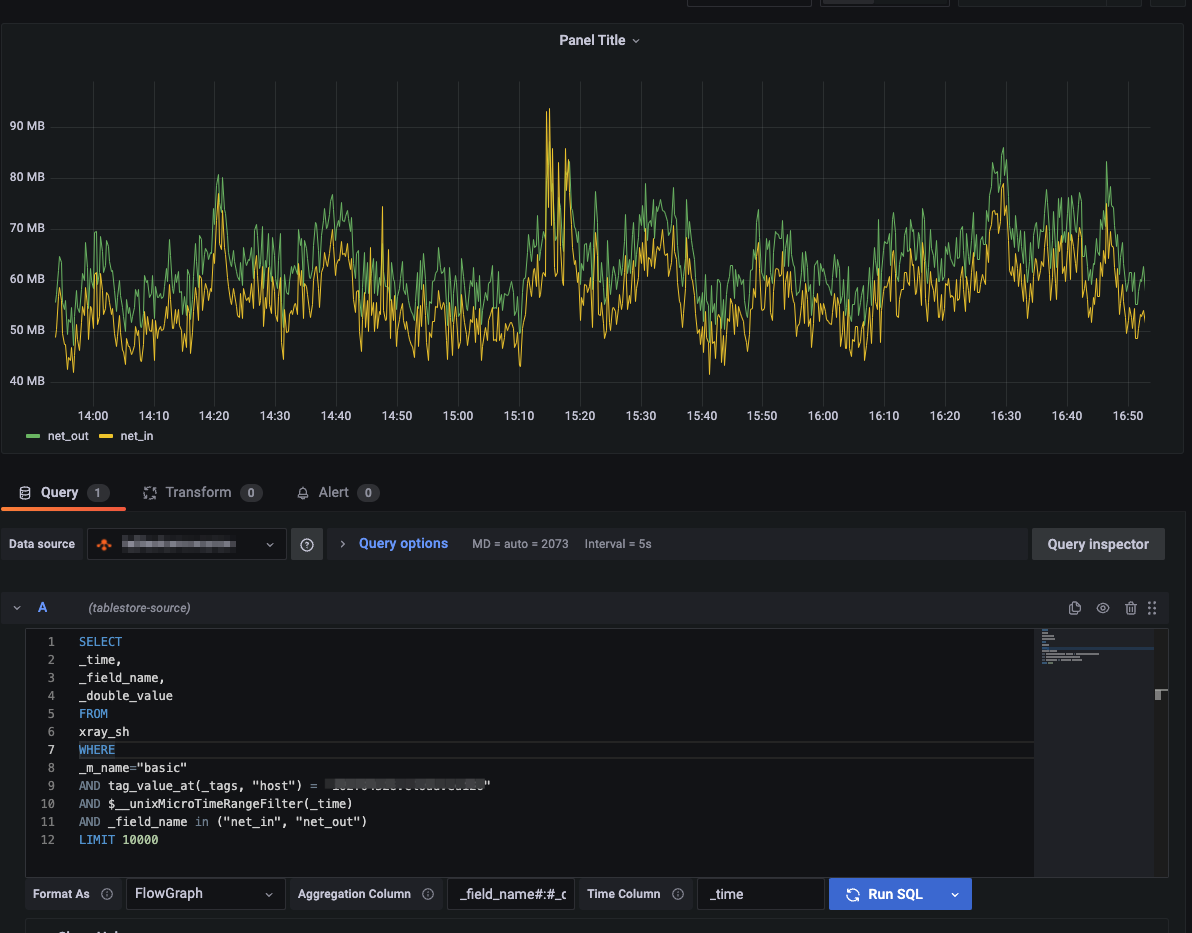
右上隅にある [適用] をクリックします。
右上隅にある [保存] をクリックします。[ダッシュボードの保存] ダイアログボックスで、タイトル、説明、フォルダーの各パラメーターを設定し、[保存] をクリックします。
ステップ 4: モニタリングデータの表示
Grafana のホームページで、左上隅にある
アイコンをクリックします。左側のナビゲーションウィンドウで、[ダッシュボード] を選択します。宛先フォルダー内のダッシュボードをクリックして、そのすべてのモニタリングチャートを表示します。