このトピックでは、CloudLens for SLSを使用して、エラーログとメトリクスに基づいてプロジェクトリソースのクォータ使用量と超過量を監視し、リソースクォータの増加を申請する方法について説明します。 エラーログとメトリックはグローバルログに属します。
背景情報
CloudLens for SLSは、Simple Log Serviceを使用して統合された可観測性を提供します。 このアプリケーションでは、数回クリックするだけで、インスタンスログとグローバルログのログ収集を有効にできます。 インスタンスログは、重要なログ、詳細ログ、およびジョブ操作ログに分類されます。 グローバルログは、監査ログ、請求ログ、エラーログ、およびメトリックに分類されます。
ログタイプ | サブタイプ | 監視シナリオ |
インスタンスログ | 詳細なログ | アクセストラフィックの監視 アクセス例外モニタリング |
重要なログ | カスタマーグループモニタリング Logtail収集モニタリング | |
ジョブ操作ログ | データ変換 (新) モニタリング スケジュールされたSQLジョブモニタリング | |
グローバルログ | 監査ログ | リソース操作のモニタリング |
エラーログ | クォータ超過モニタリング アクセス例外モニタリング 操作例外モニタリング | |
メトリクス | アクセストラフィックの監視 アクセス例外モニタリング リソースクォータ使用量のモニタリング | |
課金ログ | リソース使用量の追跡 |
ログタイプの詳細については、「CloudLensアプリケーションのログタイプ」をご参照ください。
前提条件
RAMユーザーが作成され、必要な権限がRAMユーザーに付与されます。 詳細については、「RAMユーザーの作成」および「CloudLens For SLSの操作権限をRAMユーザーに付与する」をご参照ください。
ログ収集機能は、エラーログとメトリックのグローバルログに対して有効になっています。 詳細については、「ログ収集機能の有効化」をご参照ください。
リソースのクォータ使用量をリアルタイムで監視するには、次のグローバルログ (エラーログとメトリック) のログ収集機能を有効にする必要があります。 2種類のグローバルログは、同じプロジェクトに保存する必要があります。
使用中のプロジェクトに監視ログが保存されている場合は、プロジェクトのリソースクォータが消費されます。 推奨リージョンにある専用プロジェクトを選択することを推奨します。 たとえば、中国 (杭州) リージョンの
log-service-{User ID}-cn-hangzhouプロジェクトです。
クォータモニタリングダッシュボードの表示
CloudLens for SLSのクォータモニタリングダッシュボードでは、リソースクォータアラートの概要、主要プロジェクトリソースのリアルタイムクォータ使用状況の詳細、およびプロジェクトリソースのクォータ超過の詳細を表示できます。
セクションで、[CloudLens for SLS] をクリックします。
左側のナビゲーションウィンドウで、 を選択してクォータ情報を表示します。
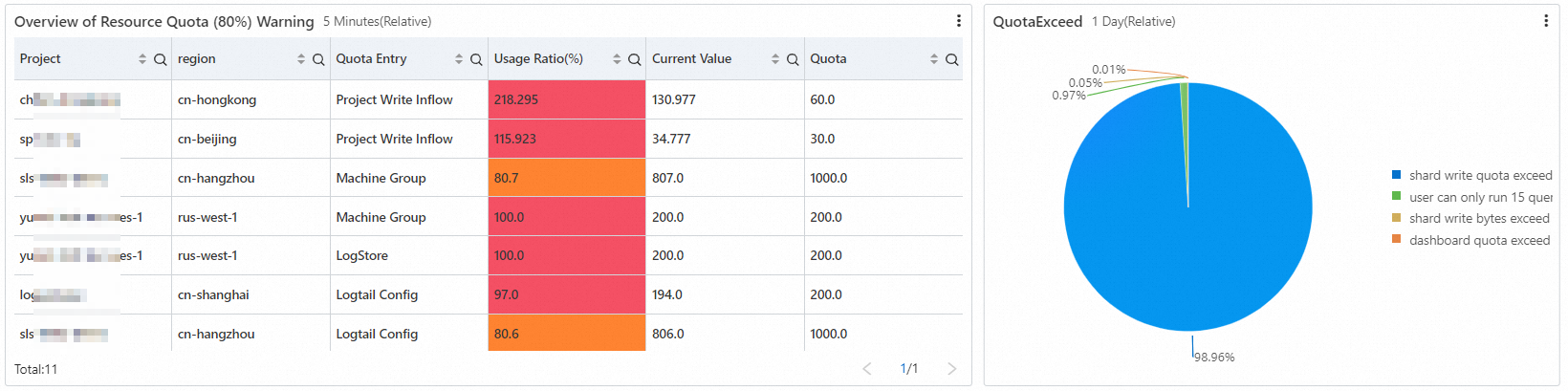
リソース割り当てアラートの概要
レポートには、クォータ使用量が上限を超えるリソースと、クォータ使用量が80% を超えるリソースの分布が表示されます。
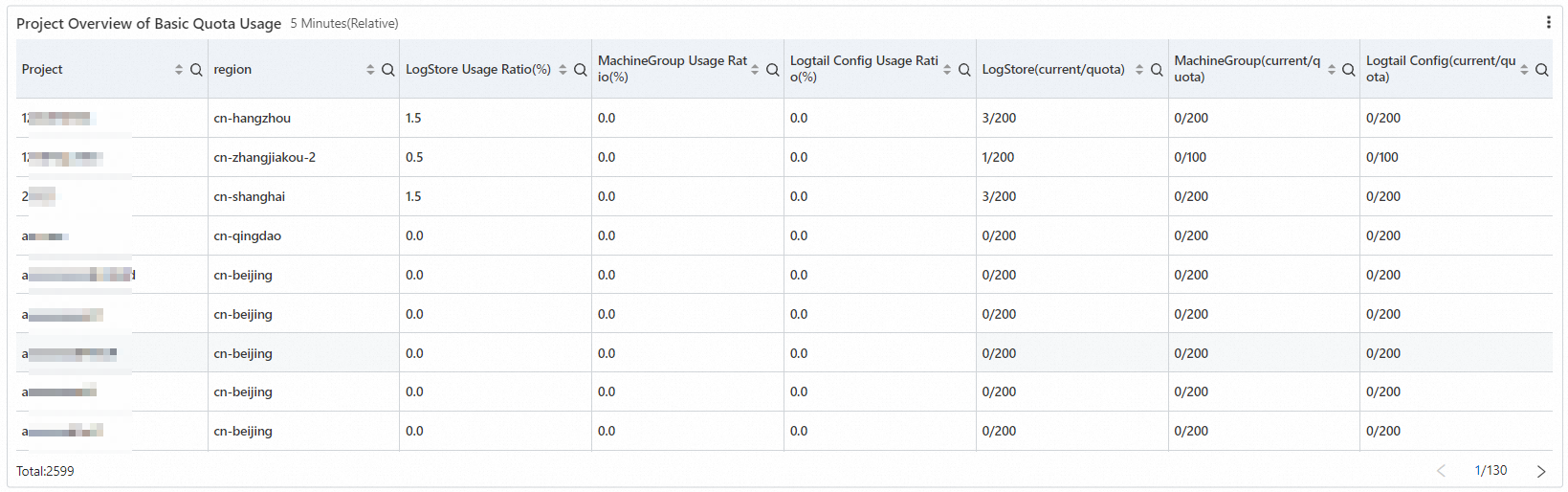
主要プロジェクトリソースのリアルタイムクォータ使用量の詳細
レポートには、基本的なプロジェクトリソースのクォータとデータの読み取り /書き込みクォータのリアルタイムの使用状況の詳細が表示されます。

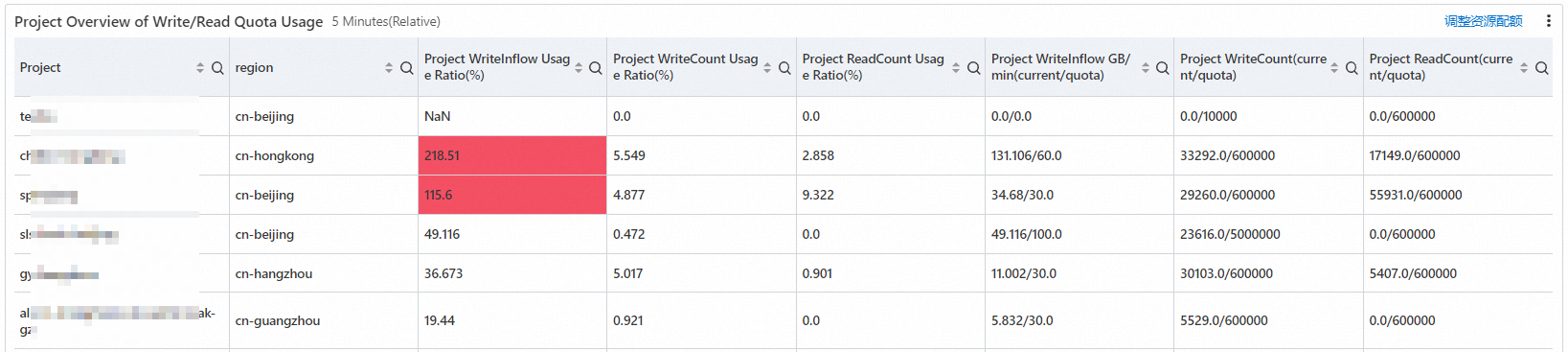
プロジェクトリソースのクォータ超過の詳細
レポートには、プロジェクトリソースのクォータ超過の詳細が表示されます。

リソースモニタリング
CloudLens for SLSは、リソースクォータとデータ読み書きクォータの基本モニタリングと、ログストア、マシングループ、プロジェクト書き込みの高度なモニタリングをサポートしています。
[ログアプリケーション] セクションで、[CloudLens for SLS] をクリックします。
[CloudLens for SLS] ページの左側のナビゲーションウィンドウで、[異常検出] をクリックして、リソースモニタリング用のアラートルールを設定します。
クォータモニタリング
次の表に、クォータモニタリングのメトリックカテゴリを示します。
カテゴリ | メトリック | 説明 |
リアルタイムの使用状況モニタリング |
| |
| ||
クォータ超過モニタリング |
|
基本的なリソースクォータ使用量
[アラートの作成] をクリックして、アラートルールを設定します。
アラートルールを作成するプロジェクトを選択します。 エラーログとメトリックを保存するプロジェクトを選択する必要があります。
ビジネスシナリオに基づいて、アラートトリガー条件とアラートポリシーを指定します。
次の表に、構成可能なパラメーターを示します。 他のパラメータのデフォルト設定を保持できます。 詳細については、「Simple Log Serviceでのアラートモニタリングルールの設定」をご参照ください。
パラメーター
値
ルール名
基本的なリソースクォータの使用
[チェック頻度]
固定間隔、15分
クエリ統計
タイプ: Metricstore
権限付与: デフォルト
Metricstore: internal-monitor-metric
時間範囲: 15分 (相対)
クエリ:
重要既定では、SQL文は最大100行のデータを返すことができます。 文の最後に制限1000を追加すると、最大1,000行のデータを返すことができます。
* | select Project, region, logstore_ratio, machine_group_ratio, logtail_config_ratio from (SELECT A.id as Project , A.region as region, round(COALESCE(SUM(B.count_logstore), 0)/cast(json_extract(A.quota, '$.logstore') as double) * 100, 3) as logstore_ratio, cast(json_extract(A.quota, '$.logstore') as double) as quota_logstore, round(COALESCE(SUM(C.count_machine_group), 0)/cast(json_extract(A.quota, '$.machine_group') as double) * 100, 3) as machine_group_ratio, cast(json_extract(A.quota, '$.machine_group') as double) as quota_machine_group, round(COALESCE(SUM(D.count_logtail_config), 0)/cast(json_extract(A.quota, '$.config') as double) * 100, 3) as logtail_config_ratio, cast(json_extract(A.quota, '$.config') as double) as quota_logtail_config FROM "resource.sls.cmdb.project" as A LEFT JOIN ( SELECT project, COUNT(*) AS count_logstore FROM "resource.sls.cmdb.logstore" as B GROUP BY project ) AS B ON A.id = B.project LEFT JOIN ( SELECT project, COUNT(*) AS count_machine_group FROM "resource.sls.cmdb.machine_group" as C GROUP BY project ) AS C ON A.id = C.project LEFT JOIN ( SELECT project, COUNT(*) AS count_logtail_config FROM "resource.sls.cmdb.logtail_config" as D GROUP BY project ) AS D ON A.id = D.project group by A.id, A.quota, A.region) where quota_logstore is not null and quota_machine_group is not null and quota_logtail_config is not null and (logstore_ratio > 80 or machine_group_ratio > 80 or logtail_config_ratio > 80) limit 10000
グループ評価
自動ラベル
トリガー条件
次のいずれかの条件が満たされると、重大なアラートがトリガーされます。Logstoreクォータ使用率が90% を超え、マシングループクォータ使用率が90% を超え、Logtail設定クォータ使用率が90% を超えます。
次のいずれかの条件が満たされると、中程度のアラートがトリガーされます。Logstoreクォータ使用率が80% を超え、マシングループクォータ使用率が80% を超え、Logtail設定クォータ使用率が80% を超えます。
データが式
logstore_ratio > 90 | | machine_group_ratio > 90 | | logtail_config_ratio > 90に一致する場合、重大度: クリティカルデータが式
logstore_ratio > 80 | | machine_group_ratio > 80 | | logtail_config_ratio > 80に一致する場合、重大度: 中程度
説明目的地
シンプルなLog Service通知
アラートポリシー
標準モード
アクションポリシー
ビジネス要件に基づいて既存のアクションポリシーを選択するか、[追加] をクリックしてアクションポリシーを作成します。 詳細については、「アクションポリシーの作成」をご参照ください。
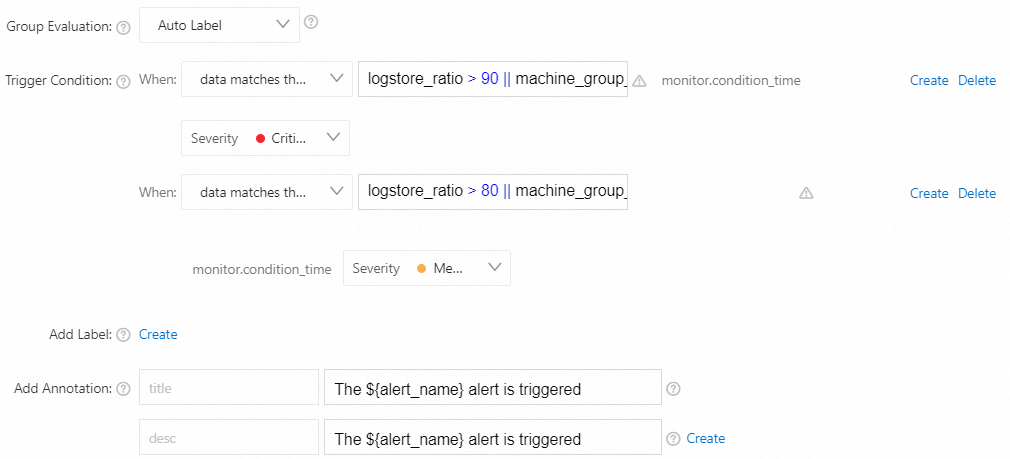
パラメーターを設定したら、[OK] をクリックします。
データ読み取り /書き込みクォータ使用量
[アラートの作成] をクリックして、アラートルールを設定します。
アラートルールを作成するプロジェクトを選択します。 エラーログとメトリックを保存するプロジェクトを選択する必要があります。
ビジネスシナリオに基づいて、アラートトリガー条件とアラートポリシーを指定します。
次の表に、構成可能なパラメーターを示します。 他のパラメータのデフォルト設定を保持できます。 詳細については、「Simple Log Serviceでのアラートモニタリングルールの設定」をご参照ください。
パラメーター
値
ルール名
データの読み取り /書き込みクォータの使用量
[チェック頻度]
固定間隔、15分
クエリ統計
タイプ: Metricstore
権限付与: デフォルト
Metricstore: internal-monitor-metric
時間範囲: 5分 (相対)
クエリ:
重要既定では、SQL文は最大100行のデータを返すことができます。 文の最後に制限1000を追加すると、最大1,000行のデータを返すことができます。
(*)| select Project, region, inflow_ratio, write_cnt_ratio from (SELECT cmdb.id as Project, cmdb.region as region, round(COALESCE(M.name1,0)/round(cast(json_extract(cmdb.quota, '$.inflow_per_min') as double)/1000000000, 3) * 100, 3) as inflow_ratio, round(COALESCE(M.name2,0)/cast(json_extract(cmdb.quota, '$.write_cnt_per_min') as double) * 100, 3) as write_cnt_ratio from "resource.sls.cmdb.project" as cmdb LEFT JOIN ( select project, round(MAX(name1)/1000000000, 3) as name1, MAX(name2) as name2 from (SELECT __time_nano__ as time, element_at( split_to_map(__labels__, '|', '#$#') , 'project') as project, sum(CASE WHEN __name__ = 'logstore_origin_inflow_bytes' THEN __value__ ELSE NULL END) AS name1, sum(CASE WHEN __name__ = 'logstore_write_count' THEN __value__ ELSE NULL END) AS name2 FROM "internal-monitor-metric.prom" where __name__ in ('logstore_origin_inflow_bytes','logstore_write_count' ) and regexp_like(element_at( split_to_map(__labels__, '|', '#$#') , 'project') , '.*') group by project,time )group by project) AS M ON cmdb.id = M.project) where inflow_ratio > 80 or write_cnt_ratio > 80 limit 10000
グループ評価
自動ラベル
トリガー条件
プロジェクトの書き込みトラフィッククォータの使用率が90% を超えるか、プロジェクトの書き込み操作クォータの使用率が90% を超えると、重大なアラートがトリガーされます。
プロジェクトの書き込みトラフィッククォータの使用率が80% を超えるか、プロジェクトの書き込み操作クォータの使用率が80% を超えると、中程度のアラートがトリガーされます。
データ
がinflow_ratio > 90 | | write_cnt_ratio > 90の式と一致する場合、重大度: クリティカルデータ
がinflow_ratio > 80 | | write_cnt_ratio > 80の式に一致する場合、重大度: 中
説明目的地
シンプルなLog Service通知
アラートポリシー
標準モード
アクションポリシー
ビジネス要件に基づいて既存のアクションポリシーを選択するか、[追加] をクリックしてアクションポリシーを作成します。 詳細については、「アクションポリシーの作成」をご参照ください。
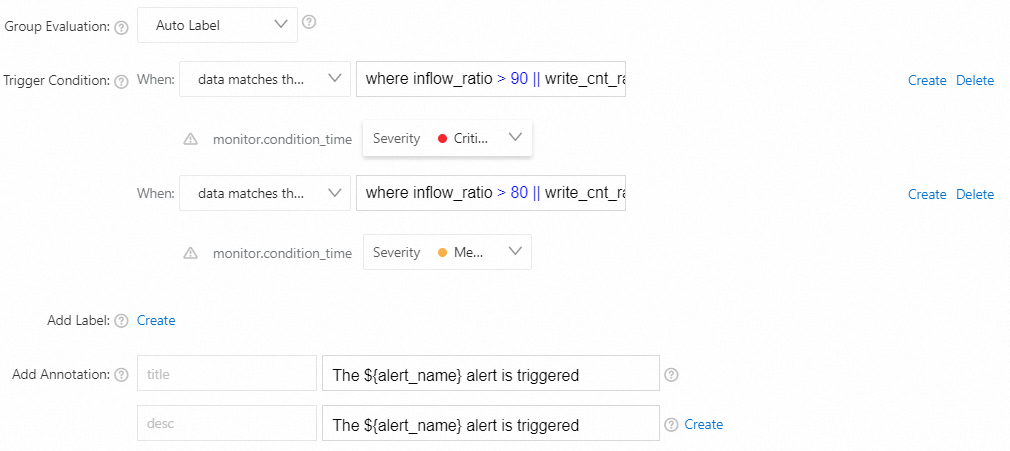
パラメーターを設定したら、[OK] をクリックします。
リソースクォータ超過カウント
[アラートの作成] をクリックして、アラートルールを設定します。
アラートルールを作成するプロジェクトを選択します。 エラーログとメトリックを保存するプロジェクトを選択する必要があります。
ビジネスシナリオに基づいて、アラートトリガー条件とアラートポリシーを指定します。
次の表に、構成可能なパラメーターを示します。 他のパラメータのデフォルト設定を保持できます。 詳細については、「Simple Log Serviceでのアラートモニタリングルールの設定」をご参照ください。
パラメーター
値
ルール名
リソースクォータ超過数
[チェック頻度]
固定間隔、15分
クエリ統計
タイプ: Logstore
権限付与: デフォルト
Logstore: internal-error_log
時間範囲: 15分 (相対)
クエリ:
重要既定では、SQL文は最大100行のデータを返すことができます。 文の最後に制限1000を追加すると、最大1,000行のデータを返すことができます。
((* and (ErrorCode: ExceedQuota or ErrorCode: QuotaExceed or ErrorCode: ProjectQuotaExceed or ErrorCode:WriteQuotaExceed or ErrorCode: ShardWriteQuotaExceed or ErrorCode: ShardReadQuotaExceed)))| SELECT Project, CASE WHEN ErrorMsg like '%Project write quota exceed: inflow%' then 'The project write traffic quota is exceeded.' WHEN ErrorMsg like '%Project write quota exceed: qps%' then 'The project write operation quota is exceeded.' WHEN ErrorMsg like '%dashboard quota exceed%' then 'The dashboard quota is exceeded.' WHEN ErrorMsg like '%config count%' then 'The Logtail configuration quota is exceeded.' WHEN ErrorMsg like '%machine group count%' then 'The Machine group quota is exceeded.' WHEN ErrorMsg like '%Alert count %' then 'The alert rule quota is exceeded.' WHEN ErrorMsg like '%logstore count %' then 'The Logstore quota is exceeded.' WHEN ErrorMsg like '%shard count%' then 'The shard quota is exceeded.' WHEN ErrorMsg like '%shard write bytes%' then 'The shard write traffic quota is exceeded.' WHEN ErrorMsg like '%shard write quota%' then 'The shard write operation quota is exceeded.' WHEN ErrorMsg like '%user can only run%' then 'The concurrent SQL analysis operation quota is exceeded.' ELSE ErrorMsg END AS ErrorMsg, COUNT(1) AS count GROUP BY Project, ErrorMsg Limit 1000
グループ評価
グループ化なし
トリガー条件
上記のクォータのいずれかを10回以上超えた場合、重大なアラートがトリガーされます。
前のクォータの1つが複数回超過した場合、中程度のアラートがトリガーされます。
データが式
count > 10に一致する場合、重大度: クリティカルデータが式
count > 1に一致する場合、重大度: 中
説明目的地
シンプルなLog Service通知
アラートポリシー
標準モード
アクションポリシー
ビジネス要件に基づいて既存のアクションポリシーを選択するか、[追加] をクリックしてアクションポリシーを作成します。 詳細については、「アクションポリシーの作成」をご参照ください。
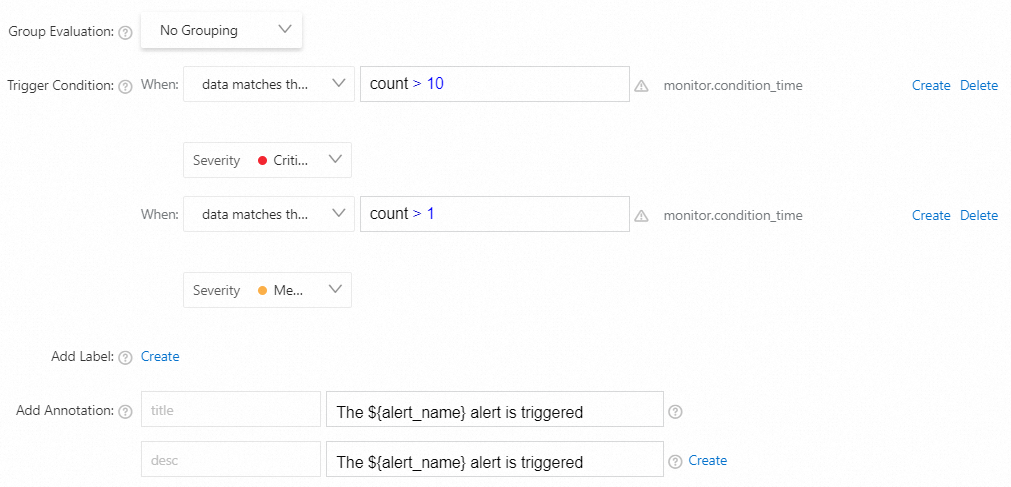
パラメーターを設定したら、[OK] をクリックします。
高度なモニタリング
次の表に、高度なモニタリングのメトリックカテゴリを示します。
カテゴリ | シナリオ | メトリック | 説明 |
基本的なリソースの割り当て | リアルタイム使用量 |
| |
クォータの超過 |
| ||
リアルタイム使用量 |
| ||
クォータの超過 |
| ||
リアルタイム使用量 |
| ||
クォータの超過 |
| ||
データの読み取り /書き込みクォータ | リアルタイム使用量 |
| |
クォータの超過 |
| ||
リアルタイム使用量 |
| ||
クォータの超過 |
|
Logstoreモニタリング
リアルタイム使用量
[アラートの作成] をクリックして、アラートルールを設定します。
アラートルールを作成するプロジェクトを選択します。 エラーログとメトリックを保存するプロジェクトを選択する必要があります。
ビジネスシナリオに基づいて、アラートトリガー条件とアラートポリシーを指定します。
次の表に、構成可能なパラメーターを示します。 他のパラメータのデフォルト設定を保持できます。 詳細については、「Simple Log Serviceでのアラートモニタリングルールの設定」をご参照ください。
パラメーター
値
ルール名
Logstoreクォータ使用量
[チェック頻度]
固定間隔、15分
クエリ統計
タイプ: Metricstore
権限付与: デフォルト
Metricstore: internal-monitor-metric
時間範囲: 15分 (相対)
クエリ:
重要既定では、SQL文は最大100行のデータを返すことができます。 文の最後に制限1000を追加すると、最大1,000行のデータを返すことができます。
* | select Project, region, round(count_logstore/quota_logstore * 100, 3) as logstore_ratio from (SELECT A.id as Project , A.region as region, COALESCE(SUM(B.count_logstore), 0) AS count_logstore , cast(json_extract(A.quota, '$.logstore') as double) as quota_logstore FROM "resource.sls.cmdb.project" as A LEFT JOIN ( SELECT project, COUNT(*) AS count_logstore FROM "resource.sls.cmdb.logstore" as B GROUP BY project ) AS B ON A.id = B.project group by A.id, A.quota, A.region) where quota_logstore is not null order by logstore_ratio desc limit 1000
グループ評価
自動ラベル
トリガー条件
プロジェクト内のLogstoreの数がクォータの90% を超えると、重大なアラートがトリガーされます。
プロジェクト内のLogstoreの数がクォータの80% を超えると、中程度のアラートがトリガーされます。
データが式
logstore_ratio > 90に一致する場合、重大度: クリティカルデータが式
logstore_ratio > 80に一致する場合、重大度: 中
説明目的地
シンプルなLog Service通知
アラートポリシー
標準モード
アクションポリシー
ビジネス要件に基づいて既存のアクションポリシーを選択するか、[追加] をクリックしてアクションポリシーを作成します。 詳細については、「アクションポリシーの作成」をご参照ください。
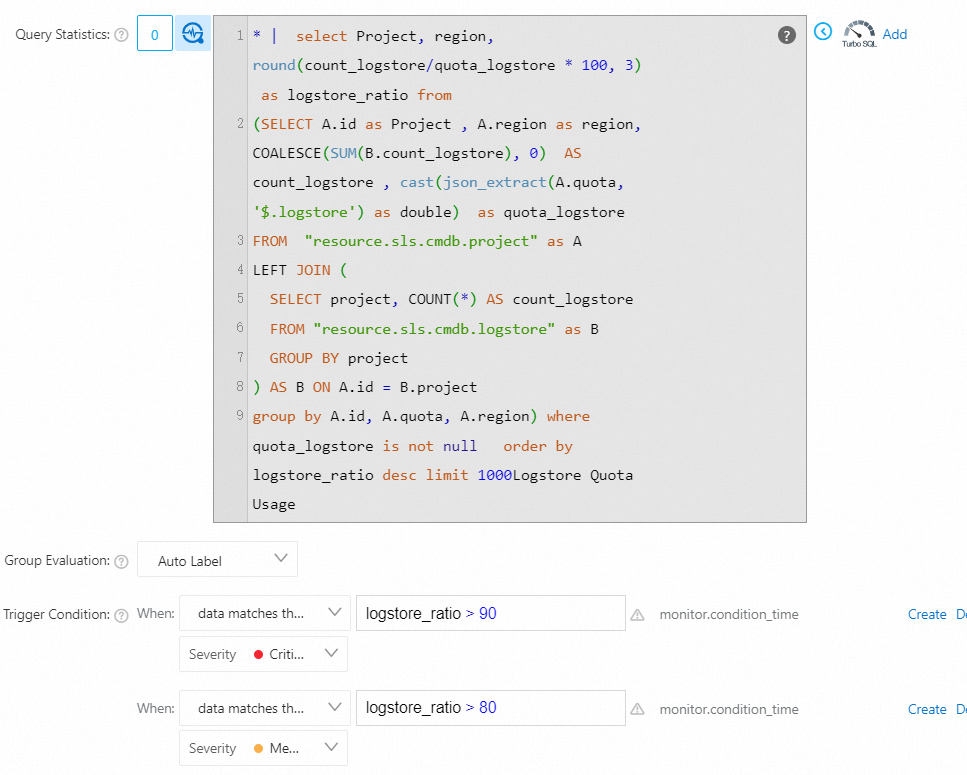
パラメーターを設定したら、[OK] をクリックします。
クォータの超過
[アラートの作成] をクリックして、アラートルールを設定します。
アラートルールを作成するプロジェクトを選択します。 エラーログとメトリックを保存するプロジェクトを選択する必要があります。
ビジネスシナリオに基づいて、アラートトリガー条件とアラートポリシーを指定します。
次の表に、構成可能なパラメーターを示します。 他のパラメータのデフォルト設定を保持できます。 詳細については、「Simple Log Serviceでのアラートモニタリングルールの設定」をご参照ください。
パラメーター
値
ルール名
Logstoreクォータを超えた
[チェック頻度]
固定間隔、15分
クエリ統計
タイプ: Logstore
権限付与: デフォルト
Logstore: internal-error_log
時間範囲: 15分 (相対)
クエリ:
重要既定では、SQL文は最大100行のデータを返すことができます。 文の最後に制限1000を追加すると、最大1,000行のデータを返すことができます。
* and (ErrorCode: ExceedQuota or ErrorCode: QuotaExceed or ErrorCode: ProjectQuotaExceed or ErrorCode:WriteQuotaExceed)| SELECT Project, COUNT(1) AS count where ErrorMsg like '%logstore count %' GROUP BY Project ORDER BY count DESC LIMIT 1000
グループ評価
グループ化なし
トリガー条件
プロジェクトのLogstoreクォータを10回以上超えた場合、重大なアラートがトリガーされます。
プロジェクトのLogstoreクォータを複数回超えた場合、中程度のアラートがトリガーされます。
データが式
count > 10に一致する場合、重大度: クリティカルデータが式
count > 1に一致する場合、重大度: 中
説明目的地
シンプルなLog Service通知
アラートポリシー
標準モード
アクションポリシー
ビジネス要件に基づいて既存のアクションポリシーを選択するか、[追加] をクリックしてアクションポリシーを作成します。 詳細については、「アクションポリシーの作成」をご参照ください。
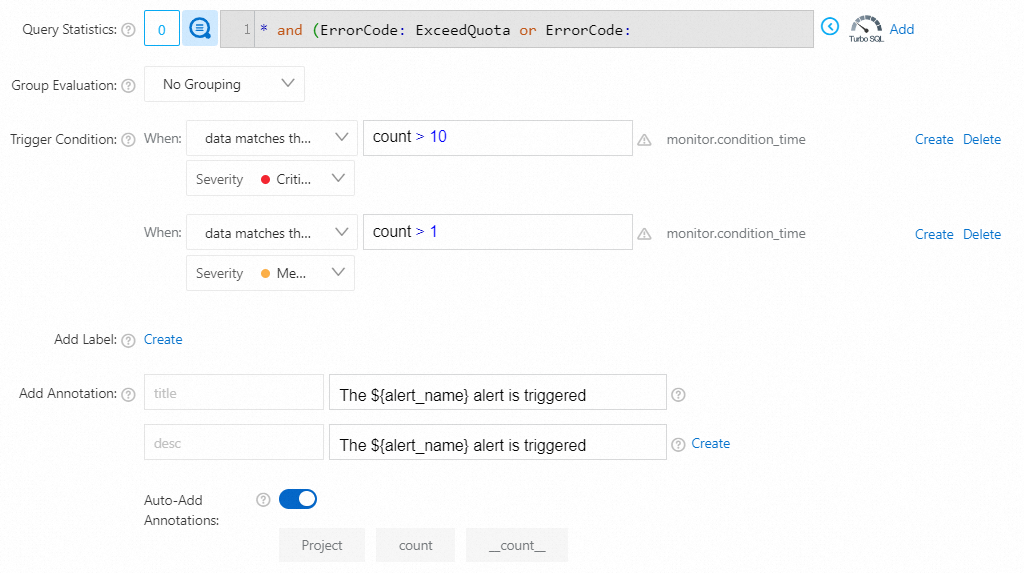
パラメーターを設定したら、[OK] をクリックします。
マシングループのモニタリング
リアルタイム使用量
[アラートの作成] をクリックして、アラートルールを設定します。
アラートルールを作成するプロジェクトを選択します。 エラーログとメトリックを保存するプロジェクトを選択する必要があります。
ビジネスシナリオに基づいて、アラートトリガー条件とアラートポリシーを指定します。
次の表に、構成可能なパラメーターを示します。 他のパラメータのデフォルト設定を保持できます。 詳細については、「Simple Log Serviceでのアラートモニタリングルールの設定」をご参照ください。
パラメーター
値
ルール名
マシングループのクォータ使用量
[チェック頻度]
固定間隔、15分
クエリ統計
タイプ: Metricstore
権限付与: デフォルト
Metricstore: internal-monitor-metric
時間範囲: 15分 (相対)
クエリ:
重要既定では、SQL文は最大100行のデータを返すことができます。 文の最後に制限1000を追加すると、最大1,000行のデータを返すことができます。
* | select Project, region, round(count_machine_group/quota_machine_group * 100, 3) as machine_group_ratio from (SELECT A.id as Project , A.region as region, COALESCE(SUM(B.count_machine_group), 0) AS count_machine_group , cast(json_extract(A.quota, '$.machine_group') as double) as quota_machine_group FROM "resource.sls.cmdb.project" as A LEFT JOIN ( SELECT project, COUNT(*) AS count_machine_group FROM "resource.sls.cmdb.machine_group" as B GROUP BY project ) AS B ON A.id = B.project group by A.id, A.quota, A.region) where quota_machine_group is not null order by machine_group_ratio desc limit 1000
グループ評価
自動ラベル
トリガー条件
プロジェクト内のマシングループの数がクォータの90% を超えると、重大なアラートがトリガーされます。
プロジェクト内のマシングループの数がクォータの80% を超えると、中程度のアラートがトリガーされます。
データが式
machine_group_ratio > 90に一致する場合、重大度: クリティカルデータが式
machine_group_ratio > 80に一致する場合、重大度: 中
説明目的地
シンプルなLog Service通知
アラートポリシー
標準モード
アクションポリシー
ビジネス要件に基づいて既存のアクションポリシーを選択するか、[追加] をクリックしてアクションポリシーを作成します。 詳細については、「アクションポリシーの作成」をご参照ください。
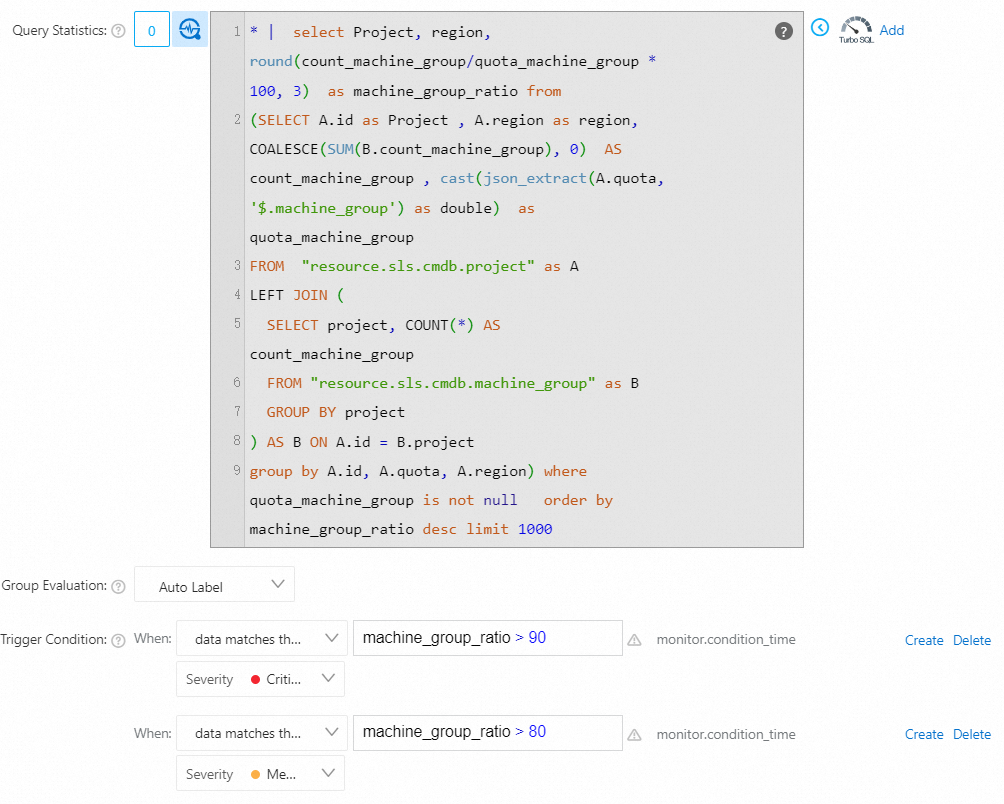
パラメーターを設定したら、[OK] をクリックします。
クォータの超過
[アラートの作成] をクリックして、アラートルールを設定します。
アラートルールを作成するプロジェクトを選択します。 エラーログとメトリックを保存するプロジェクトを選択する必要があります。
ビジネスシナリオに基づいて、アラートトリガー条件とアラートポリシーを指定します。
次の表に、構成可能なパラメーターを示します。 他のパラメータのデフォルト設定を保持できます。 詳細については、「Simple Log Serviceでのアラートモニタリングルールの設定」をご参照ください。
パラメーター
値
ルール名
マシングループのクォータを超えた
[チェック頻度]
固定間隔、15分
クエリ統計
タイプ: Logstore
権限付与: デフォルト
Logstore: internal-error_log
時間範囲: 15分 (相対)
クエリ:
重要既定では、SQL文は最大100行のデータを返すことができます。 文の最後に制限1000を追加すると、最大1,000行のデータを返すことができます。
* and (ErrorCode: ExceedQuota or ErrorCode: QuotaExceed or ErrorCode: ProjectQuotaExceed or ErrorCode:WriteQuotaExceed)| SELECT Project, COUNT(1) AS count where ErrorMsg like '%machine group count%' GROUP BY Project ORDER BY count DESC LIMIT 1000のようなErrorMsg
グループ評価
グループ化なし
トリガー条件
プロジェクトのマシングループのクォータが10回を超えた場合、重大なアラートがトリガーされます。
プロジェクトのマシングループのクォータが複数回超過した場合、中程度のアラートがトリガーされます。
データが式
count > 10に一致する場合、重大度: クリティカルデータが式
count > 1に一致する場合、重大度: 中
説明目的地
シンプルなLog Service通知
アラートポリシー
標準モード
アクションポリシー
ビジネス要件に基づいて既存のアクションポリシーを選択するか、[追加] をクリックしてアクションポリシーを作成します。 詳細については、「アクションポリシーの作成」をご参照ください。
パラメーターを設定したら、[OK] をクリックします。
Logtail設定のモニタリング
リアルタイム使用量
[アラートの作成] をクリックして、アラートルールを設定します。
アラートルールを作成するプロジェクトを選択します。 エラーログとメトリックを保存するプロジェクトを選択する必要があります。
ビジネスシナリオに基づいて、アラートトリガー条件とアラートポリシーを指定します。
次の表に、設定できるパラメーターを示します。 他のパラメータのデフォルト設定を保持できます。 詳細については、「Simple Log Serviceでのアラートモニタリングルールの設定」をご参照ください。
パラメーター
値
ルール名
Logtail設定クォータ使用量
[チェック頻度]
固定間隔、15分
クエリ統計
タイプ: Metricstore
権限付与: デフォルト
Metricstore: internal-monitor-metric
時間範囲: 15分 (相対)
クエリ:
重要既定では、SQL文は最大100行のデータを返すことができます。 文の最後に制限1000を追加すると、最大1,000行のデータを返すことができます。
* | select Project, region, round(count_logtail_config/quota_logtail_config * 100, 3) as logtail_config_ratio from (SELECT A.id as Project , A.region as region, COALESCE(SUM(B.count_logtail_config), 0) AS count_logtail_config , cast(json_extract(A.quota, '$.config') as double) as quota_logtail_config FROM "resource.sls.cmdb.project" as A LEFT JOIN ( SELECT project, COUNT(*) AS count_logtail_config FROM "resource.sls.cmdb.logtail_config" as B GROUP BY project ) AS B ON A.id = B.project group by A.id, A.quota, A.region) where quota_logtail_config is not null order by logtail_config_ratio desc limit 1000
グループ評価
自動ラベル
トリガー条件
プロジェクト内のLogtail設定の数がクォータの90% を超えると、重大なアラートがトリガーされます。
プロジェクト内のLogtail設定の数がクォータの80% を超えると、中程度のアラートがトリガーされます。
データが式
logtail_config_ratio > 90に一致する場合、重大度: クリティカルデータが式
logtail_config_ratio > 80に一致する場合、重大度: 中
説明目的地
シンプルなLog Service通知
アラートポリシー
標準モード
アクションポリシー
ビジネス要件に基づいて既存のアクションポリシーを選択するか、[追加] をクリックしてアクションポリシーを作成します。 詳細については、「アクションポリシーの作成」をご参照ください。
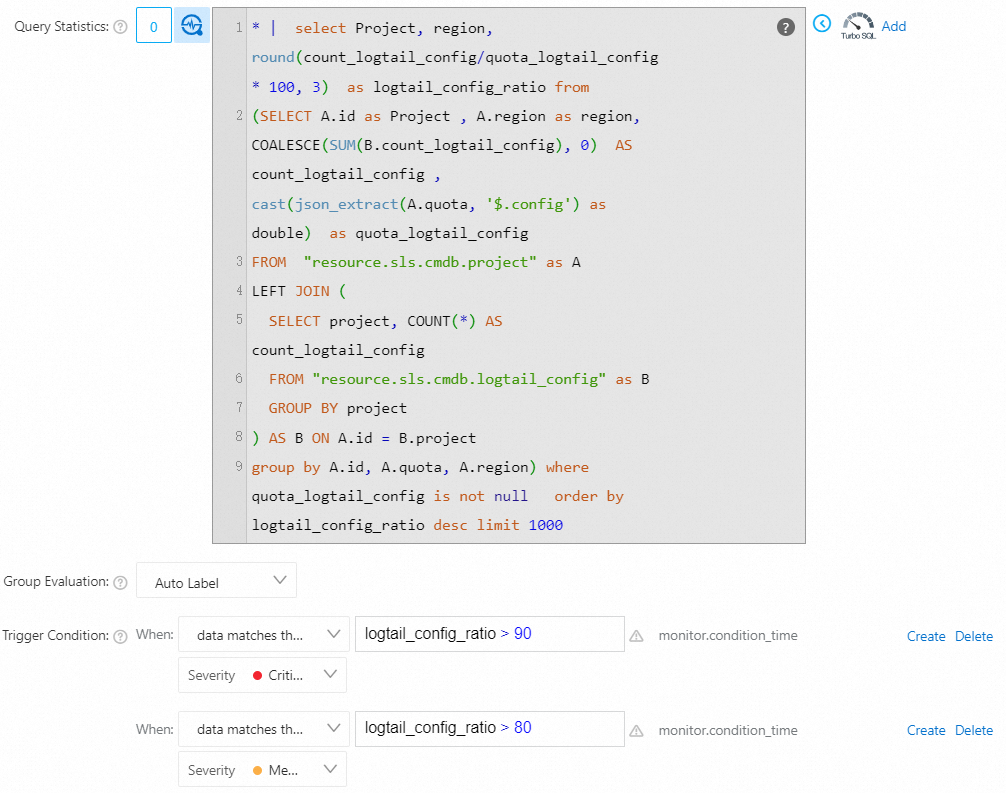
パラメーターを設定したら、[OK] をクリックします。
クォータの超過
[アラートの作成] をクリックして、アラートルールを設定します。
アラートルールを作成するプロジェクトを選択します。 エラーログとメトリックを保存するプロジェクトを選択する必要があります。
ビジネスシナリオに基づいて、アラートトリガー条件とアラートポリシーを指定します。
次の表に、構成可能なパラメーターを示します。 他のパラメータのデフォルト設定を保持できます。 詳細については、「Simple Log Serviceでのアラートモニタリングルールの設定」をご参照ください。
パラメーター
値
ルール名
Logtail設定クォータを超えた
[チェック頻度]
固定間隔、15分
クエリ統計
タイプ: Logstore
権限付与: デフォルト
Logstore: internal-error_log
時間範囲: 15分 (相対)
クエリ:
重要既定では、SQL文は最大100行のデータを返すことができます。 文の最後に制限1000を追加すると、最大1,000行のデータを返すことができます。
* and (ErrorCode: ExceedQuota or ErrorCode: QuotaExceed or ErrorCode: ProjectQuotaExceed or ErrorCode:WriteQuotaExceed)| SELECT Project, COUNT(1) AS count where ErrorMsg like '%config count%' GROUP BY Project ORDER BY count DESC LIMIT 1000
グループ評価
グループ化なし
トリガー条件
プロジェクトのLogtail設定クォータを10回以上超えた場合、重大なアラートがトリガーされます。
プロジェクトのLogtail設定クォータを複数回超えた場合、中程度のアラートがトリガーされます。
データが式
count > 10に一致する場合、重大度: クリティカルデータが式
count > 1に一致する場合、重大度: 中
説明目的地
シンプルなLog Service通知
アラートポリシー
標準モード
アクションポリシー
ビジネス要件に基づいて既存のアクションポリシーを選択するか、[追加] をクリックしてアクションポリシーを作成します。 詳細については、「アクションポリシーの作成」をご参照ください。
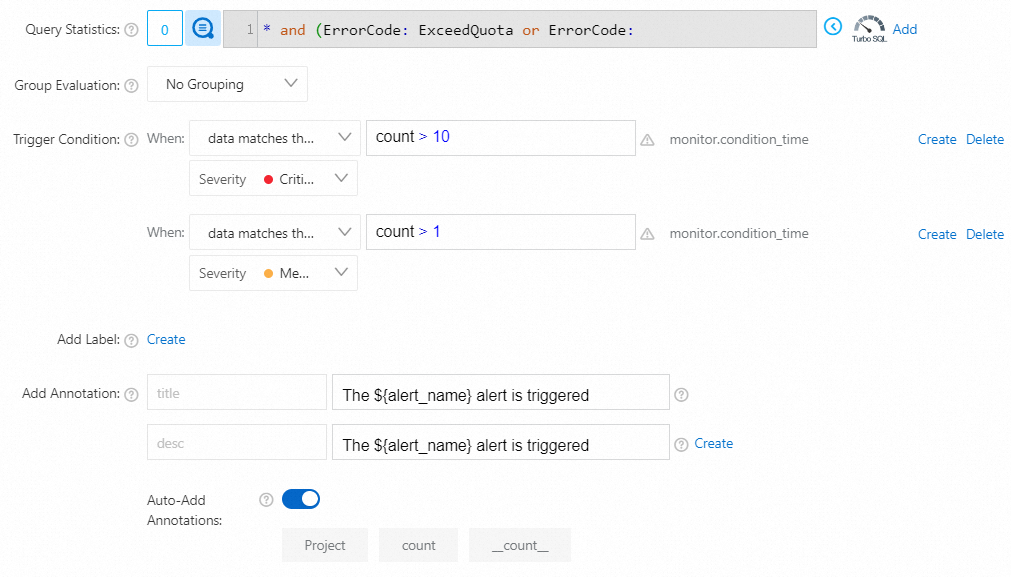
パラメーターを設定したら、[OK] をクリックします。
プロジェクト書き込みトラフィックモニタリング
リアルタイム使用量
[アラートの作成] をクリックして、アラートルールを設定します。
アラートルールを作成するプロジェクトを選択します。 エラーログとメトリックを保存するプロジェクトを選択する必要があります。
ビジネスシナリオに基づいて、アラートトリガー条件とアラートポリシーを指定します。
次の表に、設定できるパラメーターを示します。 他のパラメータのデフォルト設定を保持できます。 詳細については、「Simple Log Serviceでのアラートモニタリングルールの設定」をご参照ください。
パラメーター
値
ルール名
プロジェクト書き込みトラフィック
[チェック頻度]
固定間隔、15分
クエリ統計
タイプ: Metricstore
権限付与: デフォルト
Metricstore: internal-monitor-metric
時間範囲: 15分 (相対)
クエリ:
重要既定では、SQL文は最大100行のデータを返すことができます。 文の最後に制限1000を追加すると、最大1,000行のデータを返すことができます。
(*)| SELECT Project, region , round(count_inflow/cast(quota_inflow as double) * 100, 3) as inflow_ratio FROM (SELECT cmdb.id as Project, cmdb.region as region, COALESCE(M.name1,0) as count_inflow, round(cast(json_extract(cmdb.quota, '$.inflow_per_min') as double)/1000000000, 3) as quota_inflow from "resource.sls.cmdb.project" as cmdb LEFT JOIN ( select project, round(MAX(name1)/1000000000, 3) as name1 from (SELECT __time_nano__ as time, element_at( split_to_map(__labels__, '|', '#$#') , 'project') as project, sum(CASE WHEN __name__ = 'logstore_origin_inflow_bytes' THEN __value__ ELSE NULL END) AS name1 FROM "internal-monitor-metric.prom" where __name__ ='logstore_origin_inflow_bytes' and regexp_like(element_at( split_to_map(__labels__, '|', '#$#') , 'project') , '.*') group by project,time )group by project) AS M ON cmdb.id = M.project )order by inflow_ratio desc limit 1000
グループ評価
自動ラベル
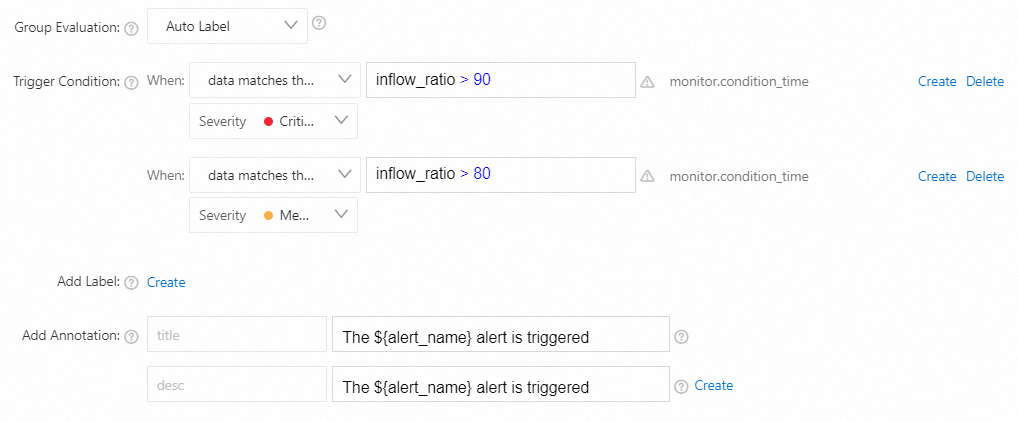
トリガー条件
プロジェクトの書き込みトラフィッククォータの使用量が90% を超えると、重大なアラートがトリガーされます。
プロジェクトの書き込みトラフィッククォータの使用量が80% を超えると、中程度のアラートがトリガーされます。
データが式
inflow_ratio > 90に一致する場合、重大度: クリティカルデータが式
inflow_ratio > 80に一致する場合、重大度: 中
説明目的地
シンプルなLog Service通知
アラートポリシー
標準モード
アクションポリシー
ビジネス要件に基づいて既存のアクションポリシーを選択するか、[追加] をクリックしてアクションポリシーを作成します。 詳細については、「アクションポリシーの作成」をご参照ください。
パラメーターを設定したら、[OK] をクリックします。
クォータの超過
[アラートの作成] をクリックして、アラートルールを設定します。
アラートルールを作成するプロジェクトを選択します。 エラーログとメトリックを保存するプロジェクトを選択する必要があります。
ビジネスシナリオに基づいて、アラートトリガー条件とアラートポリシーを指定します。
次の表に、設定できるパラメーターを示します。 他のパラメータのデフォルト設定を保持できます。 詳細については、「Simple Log Serviceでのアラートモニタリングルールの設定」をご参照ください。
パラメーター
値
ルール名
プロジェクト書き込みトラフィッククォータを超えた
[チェック頻度]
固定間隔、15分
クエリ統計
タイプ: Logstore
権限付与: デフォルト
Logstore: internal-error_log
時間範囲: 15分 (相対)
クエリ:
重要既定では、SQL文は最大100行のデータを返すことができます。 文の最後に制限1000を追加すると、最大1,000行のデータを返すことができます。
* and (ErrorCode: ExceedQuota or ErrorCode: QuotaExceed or ErrorCode: ProjectQuotaExceed or ErrorCode:WriteQuotaExceed)| SELECT Project, COUNT(1) AS count where ErrorMsg like '%Project write quota exceed: inflow%' GROUP BY Project ORDER BY count DESC LIMIT 1000
グループ評価
グループ化なし
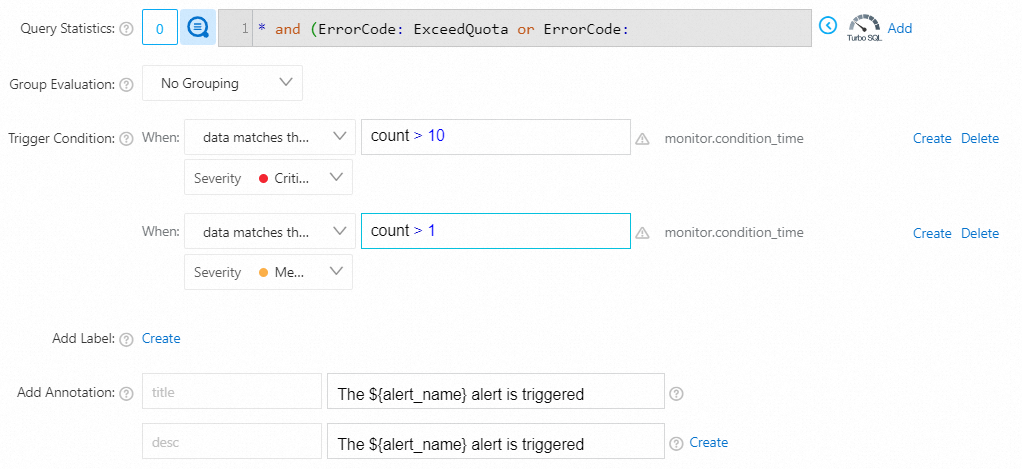
トリガー条件
プロジェクトの書き込みトラフィッククォータが10回を超えた場合、重大なアラートがトリガーされます。
プロジェクトの書き込みトラフィックのクォータを複数回超えた場合、中程度のアラートがトリガーされます。
データが式
count > 10に一致する場合、重大度: クリティカルデータが式
count > 1に一致する場合、重大度: 中
説明目的地
シンプルなLog Service通知
アラートポリシー
標準モード
アクションポリシー
ビジネス要件に基づいて既存のアクションポリシーを選択するか、[追加] をクリックしてアクションポリシーを作成します。 詳細については、「アクションポリシーの作成」をご参照ください。
パラメーターを設定したら、[OK] をクリックします。
プロジェクト書き込み操作の監視
リアルタイム使用量
[アラートの作成] をクリックして、アラートルールを設定します。
アラートルールを作成するプロジェクトを選択します。 エラーログとメトリックを保存するプロジェクトを選択する必要があります。
ビジネスシナリオに基づいて、アラートトリガー条件とアラートポリシーを指定します。
次の表に、設定できるパラメーターを示します。 他のパラメータのデフォルト設定を保持できます。 詳細については、「Simple Log Serviceでのアラートモニタリングルールの設定」をご参照ください。
パラメーター
値
ルール名
プロジェクト書き込み操作クォータの使用
[チェック頻度]
固定間隔、15分
クエリ統計
タイプ: Metricstore
権限付与: デフォルト
Metricstore: internal-monitor-metric
時間範囲: 15分 (相対)
クエリ:
重要既定では、SQL文は最大100行のデータを返すことができます。 文の最後に制限1000を追加すると、最大1,000行のデータを返すことができます。
(*)| SELECT Project, region, round(count_write_cnt/cast(quota_write_cnt as double) * 100, 3) as write_cnt_ratio FROM (SELECT cmdb.id as Project, cmdb.region as region, COALESCE(M.name1,0) as count_write_cnt, cast(json_extract(cmdb.quota, '$.write_cnt_per_min') as bigint) as quota_write_cnt from "resource.sls.cmdb.project" as cmdb LEFT JOIN ( select project, MAX(name1) as name1 from (SELECT __time_nano__ as time, element_at( split_to_map(__labels__, '|', '#$#') , 'project') as project, sum(CASE WHEN __name__ = 'logstore_write_count' THEN __value__ ELSE NULL END) AS name1 FROM "internal-monitor-metric.prom" where __name__ = 'logstore_write_count' and regexp_like(element_at( split_to_map(__labels__, '|', '#$#') , 'project') , '.*') group by project,time )group by project) AS M ON cmdb.id = M.project ) order by write_cnt_ratio desc limit 1000プロジェクト比率1000
グループ評価
自動ラベル
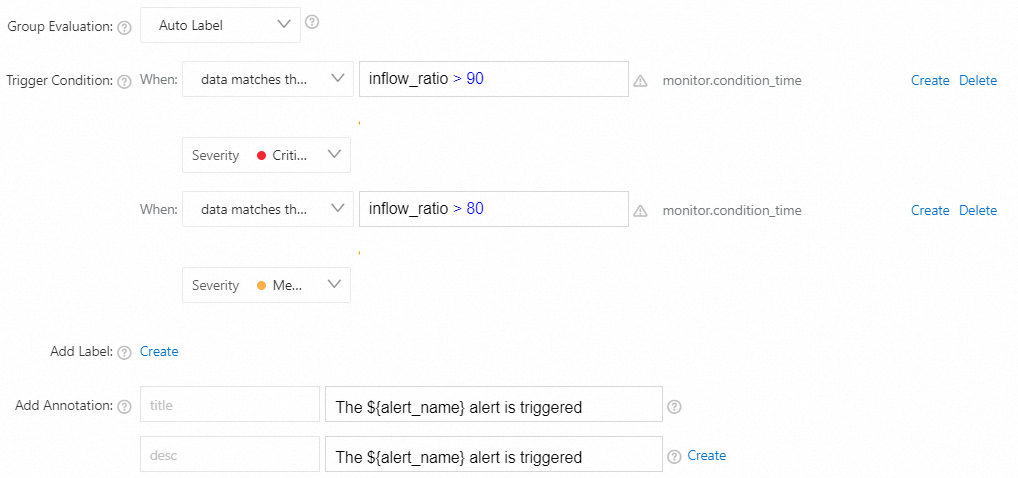
トリガー条件
プロジェクトの書き込み操作の数がクォータの90% を超えると、重大なアラートがトリガーされます。
プロジェクトの書き込み操作の数がクォータの80% を超えると、中程度のアラートがトリガーされます。
データが式
inflow_ratio > 90に一致する場合、重大度: クリティカルデータが式
inflow_ratio > 80に一致する場合、重大度: 中
説明目的地
シンプルなLog Service通知
アラートポリシー
標準モード
アクションポリシー
ビジネス要件に基づいて既存のアクションポリシーを選択するか、[追加] をクリックしてアクションポリシーを作成します。 詳細については、「アクションポリシーの作成」をご参照ください。
パラメーターを設定したら、[OK] をクリックします。
クォータの超過
[アラートの作成] をクリックして、アラートルールを設定します。
アラートルールを作成するプロジェクトを選択します。 エラーログとメトリックを保存するプロジェクトを選択する必要があります。
ビジネスシナリオに基づいて、アラートトリガー条件とアラートポリシーを指定します。
次の表に、構成可能なパラメーターを示します。 他のパラメータのデフォルト設定を保持できます。 詳細については、「Simple Log Serviceでのアラートモニタリングルールの設定」をご参照ください。
パラメーター
値
ルール名
プロジェクト書き込み操作クォータを超えた
[チェック頻度]
固定間隔、15分
クエリ統計
タイプ: Logstore
権限付与: デフォルト
Logstore: internal-error_log
時間範囲: 15分 (相対)
クエリ:
重要既定では、SQL文は最大100行のデータを返すことができます。 文の最後に制限1000を追加すると、最大1,000行のデータを返すことができます。
* and (ErrorCode: ExceedQuota or ErrorCode: QuotaExceed or ErrorCode: ProjectQuotaExceed or ErrorCode:WriteQuotaExceed)| SELECT Project, COUNT(1) AS count where ErrorMsg like '%Project write quota exceed: qps%' GROUP BY Project ORDER BY count DESC LIMIT 1000
グループ評価
グループ化なし
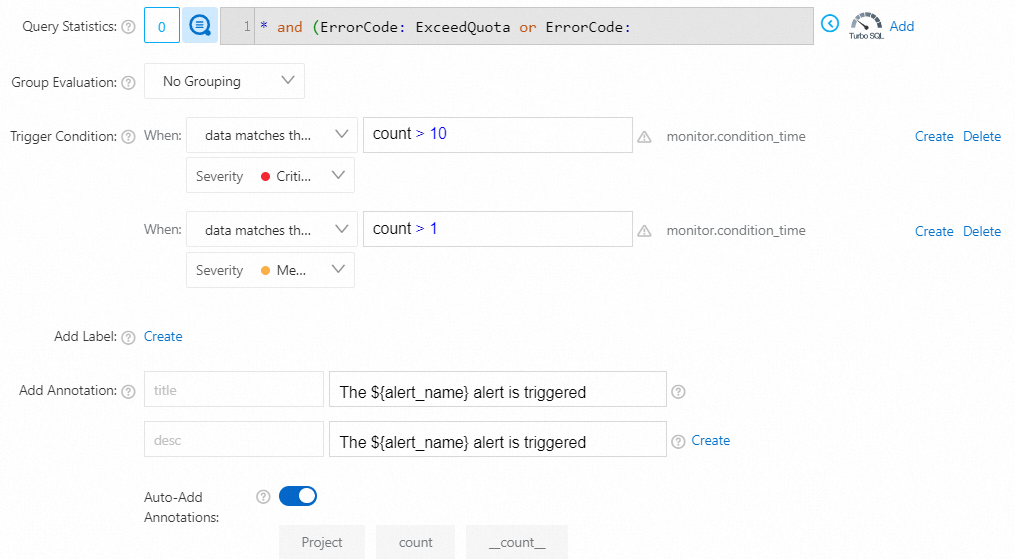
トリガー条件
プロジェクトの書き込み操作クォータを10回以上超えた場合、重大なアラートがトリガーされます。
プロジェクトの書き込み操作クォータを複数回超えた場合、中程度のアラートがトリガーされます。
データが式
count > 10に一致する場合、重大度: クリティカルデータが式
count > 1に一致する場合、重大度: 中
説明目的地
シンプルなLog Service通知
アラートポリシー
標準モード
アクションポリシー
ビジネス要件に基づいて既存のアクションポリシーを選択するか、[追加] をクリックしてアクションポリシーを作成します。 詳細については、「アクションポリシーの作成」をご参照ください。
パラメーターを設定したら、[OK] をクリックします。
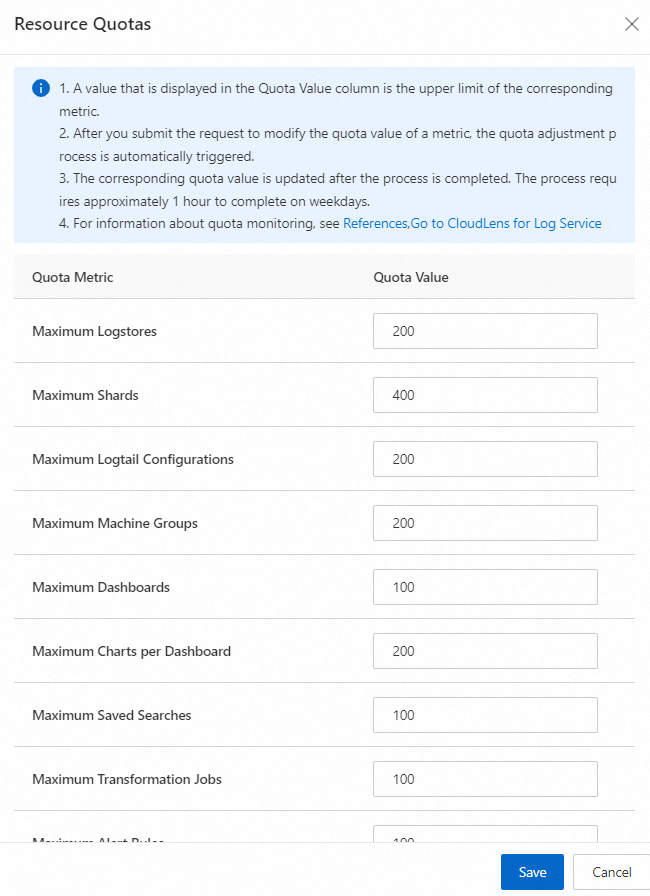
申請してリソースクォータを増やす
[プロジェクト] セクションで、管理するプロジェクトをクリックします。

 アイコンをクリックします。
アイコンをクリックします。 [リソースクォータ] の横にある [管理] をクリックします。
[リソースのクォータ] パネルで、必要なリソースのクォータを増やし、[保存] をクリックします。