このトピックでは、文字列関数の基本的な構文と例について説明します。
Simple Log Service は、次の文字列関数をサポートしています。
関数名 | 構文 | 説明 | SQL サポート | SPL サポート |
chr(x) | ASCII コードを文字に変換します。 | √ | √ | |
codepoint(x) | 文字を ASCII コードに変換します。 | √ | √ | |
concat(x, y...) | 複数の文字列を 1 つの文字列に連結します。 | √ | √ | |
from_utf8(x) | バイナリ文字列を UTF-8 エンコード形式にデコードし、無効な UTF-8 文字をデフォルト文字 U+FFFD に置き換えます。 | √ | √ | |
from_utf8(x, replace_string) | バイナリ文字列を UTF-8 エンコード形式にデコードし、無効な UTF-8 文字をカスタム文字列に置き換えます。 | √ | √ | |
length(x) | 文字列の長さを計算します。 | √ | √ | |
levenshtein_distance(x, y) | x と y の間の最小編集距離を計算します。 | √ | × | |
lower(x) | 文字列を小文字に変換します。 | √ | √ | |
lpad(x, length, lpad_string) | 文字列の先頭を指定された文字で指定された長さまでパディングし、結果の文字列を返します。 | √ | √ | |
ltrim(x) | 文字列の先頭からスペースを削除します。 | √ | √ | |
normalize(x) | 文字列を NFC 形式にフォーマットします。 | √ | × | |
position(sub_string in x) | 文字列内の部分文字列の位置を返します。 | √ | × | |
replace(x, sub_string ) | 文字列から一致した文字を削除します。 | √ | √ | |
replace(x, sub_string, replace_string) | 文字列内の一致した文字を指定された文字に置き換えます。 | √ | √ | |
reverse(x) | 文字列を逆順で返します。 | √ | √ | |
rpad(x, length, rpad_string) | 文字列の末尾を指定された文字で指定された長さまでパディングし、結果の文字列を返します。 | √ | √ | |
rtrim(x) | 文字列の末尾からスペースを削除します。 | √ | √ | |
split(x, delimeter) | 指定された区切り文字を使用して文字列を分割し、部分文字列のコレクションを返します。 | √ | √ | |
split(x, delimeter, limit) | 指定された区切り文字を使用して文字列を分割し、limit を使用して分割数を制限し、分割された部分文字列のコレクションを返します。 | √ | √ | |
split_part(x, delimeter, part) | 指定された区切り文字を使用して文字列を分割し、指定された位置のコンテンツを返します。 | √ | √ | |
split_to_map(x, delimiter01, delimiter02) | 指定された最初の区切り文字を使用して文字列を分割し、次に指定された 2 番目の区切り文字を使用して文字列を再度分割します。 | √ | √ | |
strpos(x, sub_string) | 文字列内の部分文字列の位置を返します。この関数は position(sub_string in x) 関数と同等です。 | √ | √ | |
substr(x, start) | 文字列内の指定された位置から部分文字列を返します。 | √ | √ | |
substr(x, start, length) | 文字列内の指定された位置から指定された長さの部分文字列を返します。 | √ | √ | |
to_utf8(x) | 文字列を UTF-8 エンコード形式に変換します。 | √ | √ | |
trim(x) | 文字列の先頭と末尾からスペースを削除します。 | √ | √ | |
upper(x) | 文字列を大文字に変換します。 | √ | √ | |
csv_extract_map(x, delimeter, quote, keys) | ターゲット文字列から 1 行の CSV 情報を抽出します。 | √ | × | |
ilike(x, pattern) | 文字列が指定された文字パターンに一致するかどうかをチェックします。このチェックでは大文字と小文字は区別されません。 | √ | √ | |
str_uuid() | ランダムな 128 ビット ID を生成し、それを文字列形式で返します。 | × | √ | |
gzip_compress(data, compression_level) | 文字列オブジェクトを受け取り、GZIP アルゴリズムを使用して圧縮し、圧縮されたバイナリストリームを返します。 | × | √ | |
gzip_decompress(binary_data) | GZIP で圧縮されたバイナリデータ (Varbinary) を受け取り、それを解凍します。 | × | √ |
chr 関数
chr 関数は、ASCII コードを文字に変換します。
構文
chr(x)パラメーター
パラメーター | 説明 |
x | ASCII コード。 |
戻り値の型
varchar。
例
region フィールドの値が c で始まるかどうかを確認します。ASCII コード 99 は小文字の c を表します。
フィールド例
region:cn-shanghaiクエリ・分析文 (テスト)
* | SELECT substr(region, 1, 1) = chr(99)クエリ・分析結果

codepoint 関数
codepoint 関数は、文字を ASCII コードに変換します。
構文
codepoint(x)パラメーター
パラメーター | 説明 |
x | 値は varchar 型です。 |
戻り値の型
integer。
例
region フィールドの値が c で始まるかどうかを確認します。ASCII コード 99 は小文字の c を表します。
フィールド例
upstream_status:200クエリ・分析文 (テスト)
* | SELECT codepoint(cast (substr(region, 1, 1) AS char(1))) = 99クエリ・分析結果

concat 関数
concat 関数は、複数の文字列を 1 つの文字列に連結します。
構文
concat(x, y...)パラメーター
パラメーター | 説明 |
x | 値は varchar 型です。 |
y | 値は varchar 型です。 |
戻り値の型
varchar。
例
region フィールドと request_method フィールドの値を連結します。
フィールド例
region:cn-shanghai time:14/Jul/2021:02:19:40クエリ・分析文 (テスト)
* | SELECT concat(region, '-', time)クエリ・分析結果

from_utf8 関数
from_utf8 関数は、バイナリ文字列を UTF-8 エンコード形式にデコードします。
構文
無効な UTF-8 文字をデフォルト文字 U+FFFD に置き換えます。
from_utf8(x)無効な UTF-8 文字をカスタム文字に置き換えます。
from_utf8(x,replace_string)
パラメーター
パラメーター | 説明 |
x | 値はバイナリ型です。 |
replace_string | 置換に使用される文字列。文字列は 1 文字またはスペースのみです。 |
戻り値の型
varchar。
例


length 関数
length 関数は、文字列の長さを計算します。
構文
length(x)パラメーター
パラメーター | |
x | 値は varchar 型です。 |
戻り値の型
bigint。
例
http_user_agent フィールドの値の長さを計算します。
フィールド例
http_user_agent:Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.2 (KHTML, like Gecko) Chrome/22.0.1216.0 Safari/537.2クエリ・分析文 (テスト)
* | SELECT length(http_user_agent)クエリ・分析結果

levenshtein_distance 関数
levenshtein_distance 関数は、2 つの文字列間の最小編集距離を計算します。
構文
levenshtein_distance(x, y)パラメーター
パラメーター | 説明 |
x | 値は varchar 型です。 |
y | 値は varchar 型です。 |
戻り値の型
bigint。
例
instance_id フィールドの値と owner_id フィールドの値の間の最小編集距離を計算します。
サンプルフィールド
instance_id:i-01 owner_id:owner-01クエリ・分析文 (テスト)
* | SELECT levenshtein_distance(owner_id, instance_id)クエリ・分析結果

lower 関数
lower 関数は、文字列を小文字に変換します。
構文
lower(x)パラメーター
パラメーター | 説明 |
x | 値は varchar 型です。 |
戻り値の型
varchar。
例
request_method フィールドの値を小文字に変換します。
フィールド例
request_method:GETクエリ・分析文 (テスト)
* | SELECT lower(request_method)クエリ・分析結果

lpad 関数
lpad 関数は、文字列の先頭を指定された文字で指定された長さまでパディングします。
構文
lpad(x, length, lpad_string)パラメーター
パラメーター | 説明 |
x | 値は varchar 型です。 |
length | 結果の文字列の長さを指定する整数。
|
lpad_string | パディング用の新しい文字。 |
戻り値の型
varchar。
例
instance_id フィールドの値の先頭を 0 でパディングして、合計 10 文字にします。
フィールド例
instance_id:i-01クエリ・分析文 (テスト)
* | SELECT lpad(instance_id, 10, '0')クエリ・分析結果

ltrim 関数
ltrim 関数は、文字列から先頭のスペースを削除します。
構文
ltrim(x)パラメーター
パラメーター | 説明 |
x | 値は varchar 型です。 |
戻り値の型
varchar。
例
region フィールドの値から先頭のスペースを削除します。
フィールド例
region: cn-shanghaiクエリ・分析文 (テスト)
* | SELECT ltrim(region)クエリ・分析結果

normalize 関数
normalize 関数は、文字列を正規化形式 C (NFC) 形式にフォーマットします。
構文
normalize(x)パラメーター
パラメーター | 説明 |
x | 値は varchar 型です。 |
戻り値の型
varchar。
例
文字列 schön を NFC 形式にフォーマットします。
クエリ・分析文 (テスト)
* | SELECT normalize('schön')クエリ・分析結果

position 関数
position 関数は、文字列内のターゲット部分文字列の位置を返します。
構文
position(sub_string in x)パラメーター
パラメーター | 説明 |
sub_string | ターゲット部分文字列。 |
x | 値は varchar 型です。 |
戻り値の型
int。値は 1 から始まります。ターゲット部分文字列が見つからない場合、関数は 0 を返します。
例
region フィールドの値から部分文字列 cn の位置を見つけます。
フィールド例
region:cn-shanghaiクエリ・分析文 (テスト)
* | SELECT position('cn' in region)クエリ・分析結果

replace 関数
replace 関数は、文字列から文字を削除するか、他の文字に置き換えます。
構文
文字列から一致した文字を削除します。
replace(x, sub_string)部分文字列のすべての出現箇所を別の文字列に置き換えます。
replace(x, sub_string, replace_string)
パラメーター
パラメーター | 説明 |
x | 値は varchar 型です。 |
sub_string | ターゲット部分文字列。 |
replace_string | 置換に使用される部分文字列。 |
戻り値の型
varchar。
例


reverse 関数
reverse 関数は、文字列を逆順で返します。
構文
reverse(x)パラメーター
パラメーター | 説明 |
x | 値は varchar 型です。 |
戻り値の型
varchar。
例
request_method フィールドの値を逆順にします。
フィールド例
request_method:GETクエリ・分析文 (テスト)
* | SELECT reverse(request_method)クエリ・分析結果

rpad 関数
rpad 関数は、文字列の末尾を指定された文字で指定された長さまでパディングします。
構文
rpad(x, length, rpad_string)パラメーター
パラメーター | 説明 |
x | 値は varchar 型です。 |
length | 結果の文字列の長さを指定する整数。
|
rpad_string | パディング用の新しい文字。 |
戻り値の型
varchar。
例
instance_id フィールドの値の末尾を 0 でパディングして、合計 10 文字にします。
フィールド例
instance_id:i-01クエリ・分析文 (テスト)
* | SELECT rpad(instance_id, 10, '0')クエリ・分析結果

rtrim 関数
rtrim 関数は、文字列から末尾のスペースを削除します。
構文
rtrim(x)パラメーター
パラメーター | 説明 |
x | 値は varchar 型です。 |
戻り値の型
varchar。
例
instance_id フィールドの値から末尾のスペースを削除します。
フィールド例
instance_id:i-01クエリ・分析文 (テスト)
* | SELECT rtrim(instance_id)クエリ・分析結果

split 関数
split 関数は、指定された区切り文字を使用して文字列を分割し、結果の部分文字列の配列を返します。
構文
指定された区切り文字を使用して文字列を分割します。
split(x, delimeter)指定された区切り文字を使用して、文字列を指定された数の部分文字列に分割します。
split(x,delimeter,limit)
パラメーター
パラメーター | 説明 |
x | 値は varchar 型です。 |
delimeter | 区切り文字。 |
limit | 分割数。値は 0 より大きい整数である必要があります。 |
戻り値の型
データ型は配列です。
例
例 1:
request_uriフィールドの値をスラッシュ (/) を使用して 4 つの部分文字列に分割し、部分文字列の配列を返します。フィールド例
request_uri:/request/path-1/file-9クエリ・分析文 (テスト)
* | SELECT split(request_uri, '/')クエリ・分析結果

例 2:
request_uriフィールドの値をスラッシュ (/) を使用して 3 つの部分文字列に分割し、部分文字列の配列を返します。フィールド例
request_uri:/request/path-1/file-9クエリ・分析文 (テスト)
* | SELECT split(request_uri, '/', 3)クエリ・分析結果

split_part 関数
split_part 関数は、指定された区切り文字を使用して文字列を分割し、指定された位置の部分文字列を返します。
構文
split_part(x, delimeter, part)パラメーター
パラメーター | 説明 |
x | 値は varchar 型です。 |
delimeter | 区切り文字。 |
part | 0 より大きい整数。 |
戻り値の型
varchar。
例
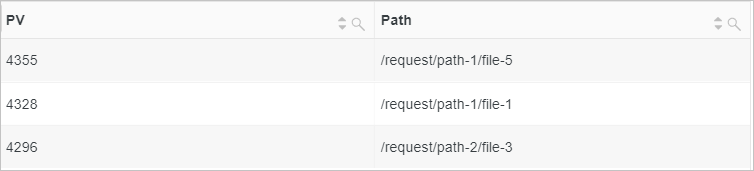
request_uri フィールドの値を疑問符 (?) を使用して分割し、最初の部分文字列 (ファイルパス) を返します。次に、各パスのリクエスト数をカウントします。
フィールド例
request_uri: /request/path-2/file-6?name=value&age=18 request_uri: /request/path-2/file-0?name=value&age=18 request_uri: /request/path-3/file-2?name=value&age=18クエリ・分析文 (テスト)
* | SELECT count(*) AS PV, split_part(request_uri, '?', 1) AS Path GROUP BY Path ORDER BY pv DESCクエリ・分析結果
split_to_map 関数
split_to_map 関数は、2 つの指定された区切り文字を使用して文字列をキーと値のペアに分割します。
構文
split_to_map(x, delimiter01, delimiter02)パラメーター
パラメーター | 説明 |
x | 値は varchar 型です。 |
delimeter01 | 区切り文字。 |
delimeter02 | 区切り文字。 |
戻り値の型
マップ。
例
time フィールドの値をカンマ (,) とコロン (:) を使用して分割します。結果はマップです。
フィールド例
time:upstream_response_time:"80", request_time:"40"クエリ・分析文
* | SELECT split_to_map(time, ',', ':')クエリ・分析結果

strpos 関数
strpos 関数は、文字列内のターゲット部分文字列の位置を返します。この関数は position 関数と同等です。
構文
strpos(x, sub_string)パラメーター
パラメーター | 説明 |
x | 値は varchar 型です。 |
sub_string | ターゲット部分文字列。 |
戻り値の型
int。値は 1 から始まります。ターゲット部分文字列が見つからない場合、関数は 0 を返します。
例
server_protocol フィールドの値から文字 H の位置を見つけます。
クエリ・分析文 (テスト)
* | SELECT strpos(server_protocol, 'H')クエリ・分析結果

substr 関数
substr 関数は、文字列内の指定された位置から部分文字列を返します。
構文
指定された開始位置から文字列の末尾までの部分文字列を返します。
substr(x, start)指定された開始位置から指定された長さの部分文字列を返します。
substr(x,start,length)
パラメーター
パラメーター | 説明 |
x | 値は varchar 型です。 |
start | 部分文字列の抽出を開始する位置。値は 1 から始まります。 |
length | 部分文字列の長さ。 |
戻り値の型
varchar。
例
server_protocol フィールドの値から最初の 4 文字 (HTTP) を抽出します。次に、HTTP プロトコルを使用するリクエストの数をカウントします。
フィールド例
server_protocol:HTTP/2.0クエリ・分析文 (テスト)
* | SELECT substr(server_protocol, 1, 4) AS protocol, count(*) AS count GROUP BY server_protocolクエリ・分析結果

to_utf8 関数
to_utf8 関数は、文字列を UTF-8 バイナリ表現にエンコードします。
構文
to_utf8(x)パラメーター
パラメーター | 説明 |
x | 値は varchar 型です。 |
戻り値の型
varbinary。
例
文字列 'log' を UTF-8 形式にエンコードします。
クエリ・分析文 (テスト)
* | SELECT to_utf8('log')クエリ・分析結果

trim 関数
trim 関数は、文字列から先頭と末尾のスペースを削除します。
構文
trim(x)パラメーター
パラメーター | 説明 |
x | 値は varchar 型です。 |
戻り値の型
varchar。
例
instance_id フィールドの値から先頭と末尾のスペースを削除します。
フィールド例
instance_id: i-01クエリ・分析文 (テスト)
* | SELECT trim(instance_id)クエリ・分析結果
upper 関数
upper 関数は、ターゲット文字列を大文字に変換します。
構文
upper(x)パラメーター
パラメーター | 説明 |
x | 値は varchar 型です。 |
戻り値の型
varchar。
例
region フィールドの値を大文字に変換します。
フィールド例
region:cn-shanghaiクエリ・分析文 (テスト)
* | SELECT upper(region)クエリ・分析結果

csv_extract_map 関数
csv_extract_map 関数は、ターゲット文字列から 1 行の CSV 情報を抽出します。
構文
csv_extract_map(x, delimeter, quote, keys)パラメーター
パラメーター | 説明 |
x | 値は varchar 型です。 |
delimeter | CSV 区切り文字。値は varchar 型で、長さは 1 です。 |
quote | CSV 引用符。値は varchar 型で、長さは 1 です。 |
keys | CSV 情報の出力のキー名。値は配列型です。要素の数がデータ内の CSV 情報の数と異なる場合、null が返されます。 |
戻り値の型
map(varchar, varchar)。
例
content フィールドから CSV 情報を抽出します。
フィールド例
content: '192.168.0.100,"10/Jun/2019:11:32:16,127 +0800",example.aliyundoc.com'クエリ・分析文
select csv_extract_map(content, ',', '"', array['ip', 'time', 'host']) as item出力データ

ilike 関数
ilike 関数は、入力文字列が指定された文字パターンに一致するかどうかをチェックします。このチェックでは大文字と小文字は区別されません。
構文
ilike(x, pattern)パラメーター
パラメーター | 説明 |
x | 値は varchar 型です。 |
pattern | 文字列とワイルドカード文字を含む文字パターン。次の表にワイルドカード文字を示します。
|
戻り値の型
boolean
例
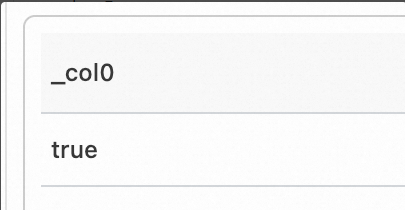
request_uri が file-6 で終わるかどうかを確認します。
フィールド例
request_uri: '/request/path-2/File-6'クエリ・分析文
select ilike(request_uri, '%file-6')出力データ
str_uuid 関数
str_uuid() 関数は、ランダムな 128 ビット ID を生成し、それを文字列として返します。
構文
str_uuid()戻り値
戻り値の型:
VARCHARフォーマット: 32 個の 16 進数の数字と 4 つのハイフン (
-) を含む標準の 36 文字の文字列。構造例:
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx
例
この関数を使用して、ステージング環境で多数の一意の識別子を迅速に生成できます。
* | extend uuid = str_uuid()gzip_compress 関数
gzip_compress 関数は、GZIP アルゴリズムを使用して文字列オブジェクトを圧縮し、圧縮されたバイナリデータを返します。
構文
-- 方法 1: デフォルトレベル (6)
gzip_compress(data)
-- 方法 2: 指定レベル
gzip_compress(data, compression_level)パラメーター
パラメーター | 型 | 説明 |
data | VARCHAR | 圧縮する文字列。 |
compression_level | BIGINT | 圧縮レベル。値は 1 から 9 までの整数です。 |
戻り値
戻り値の型:
VARBINARY説明: 圧縮されたバイナリデータ。
例
例 1: 基本的な圧縮
* | extend compress_data = gzip_compress('Hello World')例 2: 大きなテキストの最大圧縮率
数万語を含むログがあり、ストレージ容量が懸念される場合は、レベル
9を使用します:* | extend compress_data = gzip_compress('Hello World',9)
gzip_decompress 関数
gzip_decompress 関数は、GZIP で圧縮されたバイナリデータ (Varbinary) を解凍します。
構文
gzip_decompress(binary_data)パラメーター
binary_data は、通常 gzip_compress によって生成される、有効な GZIP 圧縮データである必要があります。入力が標準の GZIP 形式でない場合、関数は NULL を返します。
戻り値
戻り値の型:
VARCHAR説明: 元の解凍されたプレーンテキストのコンテンツ。
例
単純な圧縮と展開のパイプライン:
* | extend original_content = gzip_decompress(gzip_compress('Hello SLS!')) -- 出力: "Hello SLS!"