このトピックでは、数理統計関数の構文について説明します。 このトピックでは、関数の使用方法の例も示します。
次の表に、Simple Log Serviceでサポートされている数理統計関数を示します。
分析ステートメントで文字列を使用する場合は、文字列を単一引用符 ('') で囲む必要があります。 囲まれていない文字列または二重引用符 ("") で囲まれている文字列は、フィールド名または列名を示します。 たとえば、'status' はステータス文字列を示し、statusまたは "status" はステータスログフィールドを示します。
カテゴリ | 関数 | 構文 | 説明 | SQLでサポート | SPLでサポート |
相関関数 | corr( x, y) | xとyの相関係数を返します。 戻り値は [0,1] の範囲です。 | √ | × | |
分散と標準偏差関数 | covar_pop( x, y) | xとyの母集団共分散を返します。 | √ | × | |
covar_samp( x, y) | xとyのサンプル共分散を返します。 | √ | × | ||
stddev( x) | xのサンプル標準偏差を返します。 この関数はstddev_samp関数と同じです。 | √ | × | ||
stddev_samp( x) | xのサンプル標準偏差を返します。 | √ | × | ||
stddev_pop( x) | xの母集団標準偏差を返します。 | √ | × | ||
分散 (x) | xのサンプル分散を返します。 この関数はvar_samp関数と同じです。 | √ | × | ||
var_samp( x) | xのサンプル分散を返します。 | √ | × | ||
var_pop( x) | xの母集団分散を返します。 | √ | × | ||
線形回帰関数 | regr_intercept( y, x) |
| √ | × | |
regr_slope( y, x) |
| √ | × | ||
累積分布関数 (CDF) | beta_cdf( α, β, v) | ベータ分布の値を返します。 この関数は、以下の式を使用する。P(N ≦ v; α, β) ここで、α および β は、ベータCDFのパラメータである。 | √ | × | |
binomial_cdf( x, y, v) | 二項分布の値を返します。 この関数は、以下の式を使用する。P(N <= v) ここで、xは試行の数を示し、yは試行の成功確率 (POS) を示す。 | √ | × | ||
cauchy_cdf( x, y, v) | コーシー分布の値を返します。 この関数は、以下の式を使用する。P(N ≦ v; x, y) ここで、xは分布のピークを示す位置パラメータであり、yはスケールパラメータである。 | √ | × | ||
chi_squared_cdf( k, v) | カイ二乗分布の値を返します。 この関数は、以下の式を使用する。P(N ≦ v; k) ここで、kは自由度を示す。 | √ | × | ||
inverse_beta_cdf(α, β, p) | ベータ分布の逆数の値を返します。 pは、P(N <= v; α, β) 式を使用するベータCDFの結果を示す。 逆inverse_beta_cdf関数はvを計算する。 | √ | × | ||
inverse_binomial_cdf(x, y, p) | 二項分布の逆数の値を返します。 pは、P(N <= v) 式を使用する二項CDFの結果を示す。 逆inverse_binomial_cdf関数は、vを計算する。 | √ | × | ||
inverse_cauchy_cdf(x, y, p) | コーシー分布の逆数の値を返します。 pは、P(N ≦ v; x, y) 式を使用するコーシーCDFの結果を示す。 逆inverse_cauchy_cdf関数はvを計算する。 | √ | × | ||
inverse_chi_squared_cdf( k, p) | カイ二乗分布の逆数の値を返します。 pは、P(N <= v; k) 式を使用するカイ二乗CDFの結果を示す。 逆inverse_chi_squared_cdf関数はvを計算する。 | √ | × | ||
inverse_laplace_cdf(μ, b, p) | ラプラス分布の逆数の値を返します。 pは、P(N <= v; μ, b) 式を使用するラプラスCDFの結果を示す。 逆inverse_laplace_cdf関数はvを計算します。 | √ | × | ||
inverse_normal_cdf( x, y, p) | 正規分布の逆数の値を返します。 pは、P(N < v; x, y) 式を使用する正常なCDFの結果を示す。 逆inverse_normal_cdf関数はvを計算する。 | √ | × | ||
inverse_poisson_cdf( x, y, p) | ポアソン分布の逆数の値を返します。 pは、P(N <= v; λ) 式を使用するポアソンCDFの結果を示す。 逆inverse_poisson_cdf関数はvを計算します。 | √ | × | ||
inverse_weibull_cdf( x, y, p) | ワイブル分布の逆数の値を返します。 pは、P(N <= v; x, y) 式を使用するワイブルCDFの結果を示す。 逆inverse_weibull_cdf関数はvを計算する。 | √ | × | ||
laplace_cdf( μ 、b、v) | ラプラス分布の値を返します。 この関数は、以下の式を使用する。P(N ≦ v; μ, b) ここで、μ は位置パラメータであり、bはスケールパラメータである。 | √ | × | ||
normal_cdf( x, y, v) | 正規分布の値を返します。 この関数は、以下の式を使用する。P(N < v; x, y) ここで、xは正規分布の平均値を示し、yは正規分布の標準偏差を示す。 | √ | × | ||
poisson_cdf( λ, v) | ポアソン分布の値を返します。 この関数は、以下の式を使用する。P(N ≦ v; λ) ここで、λ は、ランダム事象の平均確率を示す。 | √ | × | ||
weibull_cdf( x, y, v) | ワイブル分布の値を返します。 この関数は、以下の式を使用する。P(N ≦ v; x, y) ここで、xはスケールパラメータであり、yは形状パラメータである。 | √ | × |
corr関数
corr関数は、xとyの相関係数を返します。 戻り値が大きいほど相関が高いことを示す。
構文
corr(x, y)パラメーター
パラメーター | 説明 |
x | このパラメーターの値はdouble型です。 |
y | このパラメーターの値はdouble型です。 |
戻り値のデータ型
ダブルタイプ。 戻り値は [0,1] の範囲です。
例
request_lengthフィールドとrequest_timeフィールドの値の相関係数を計算します。
クエリ文
* | SELECT corr(request_length,request_time)クエリと分析結果

covar_pop関数
covar_pop関数は、xとyの母集団共分散を返します。
構文
covar_pop(x, y)パラメーター
パラメーター | 説明 |
x | このパラメーターの値はdouble型です。 |
y | このパラメーターの値はdouble型です。 |
戻り値のデータ型
ダブルタイプ。
例
毎分の税引前利益と税引前売上高の母集団共分散を計算します。
クエリ文
*| SELECT covar_pop(PretaxGrossAmount, PretaxAmount) AS "Population covariance", time_series(__time__, '1m', '%H:%i:%s', '0') AS time GROUP BY timeクエリと分析結果

covar_samp関数
covar_samp関数は、xとyのサンプル共分散を返します。
構文
covar_samp(x, y)パラメーター
パラメーター | 説明 |
x | このパラメーターの値はdouble型です。 |
y | このパラメーターの値はdouble型です。 |
戻り値のデータ型
ダブルタイプ。
例
毎分の税引前利益と税引前売上高のサンプル共分散を計算します。
クエリ文
*| SELECT covar_samp(PretaxGrossAmount, PretaxAmount) AS "Sample covariance", time_series(__time__, '1m', '%H:%i:%s', '0') AS time GROUP BY timeクエリと分析結果

stddev関数
stddev関数は、xのサンプル標準偏差を返します。 この関数はstddev_samp関数と同じです。
構文
stddev(x)パラメーター
パラメーター | 説明 |
x | このパラメーターの値はdouble型またはbigint型です。 |
戻り値のデータ型
ダブルタイプ。
例
税引前所得のサンプル標準偏差と人口標準偏差を計算し、計算された値を折れ線グラフに表示します。
クエリ文
* | SELECT stddev(PretaxGrossAmount) as "Sample standard deviation", stddev_pop(PretaxGrossAmount) as "Population standard deviation", time_series(__time__, '1m', '%H:%i:%s', '0') AS time GROUP BY timeクエリと分析結果
stddev_samp関数
stddev_samp関数は、xのサンプル標準偏差を返します。
構文
stddev_samp(x)パラメーター
パラメーター | 説明 |
x | このパラメーターの値はdouble型またはbigint型です。 |
戻り値のデータ型
ダブルタイプ。
例
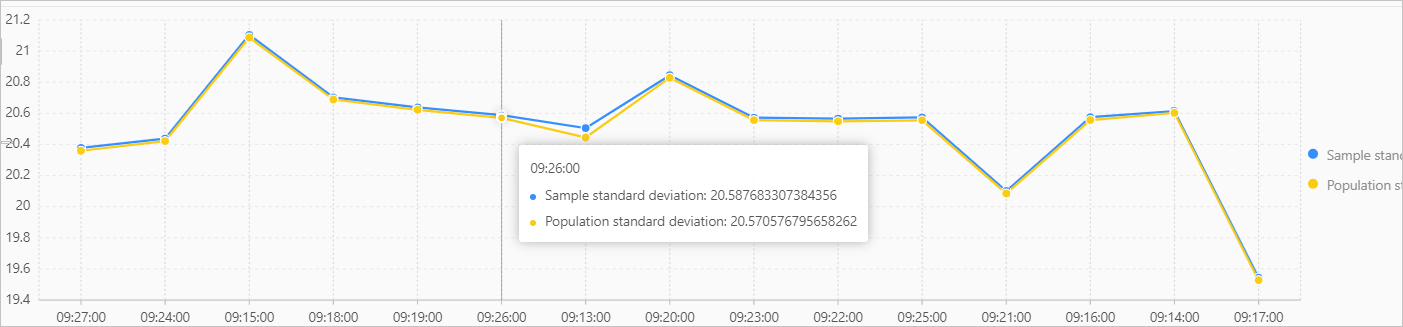
税引前所得のサンプル標準偏差と人口標準偏差を計算し、計算された値を折れ線グラフに表示します。
クエリ文
* | SELECT stddev_samp(PretaxGrossAmount) as "Sample standard deviation", stddev_pop(PretaxGrossAmount) as "Population standard deviation", time_series(__time__, '1m', '%H:%i:%s', '0') AS time GROUP BY timeクエリと分析結果
stddev_pop関数
stddev_pop関数は、xの母集団標準偏差を返します。
構文
stddev_pop(x)パラメーター
パラメーター | 説明 |
x | このパラメーターの値はdouble型またはbigint型です。 |
戻り値のデータ型
ダブルタイプ。
例
税引前所得のサンプル標準偏差と人口標準偏差を計算し、計算された値を折れ線グラフに表示します。
クエリ文
* | SELECT stddev(PretaxGrossAmount) as "Sample standard deviation", stddev_pop(PretaxGrossAmount) as "Population standard deviation", time_series(__time__, '1m', '%H:%i:%s', '0') AS time GROUP BY timeクエリと分析結果
分散関数
分散関数は、xのサンプル分散を返します。 この関数はvar_samp関数と同じです。
構文
variance(x)パラメーター
パラメーター | 説明 |
x | このパラメーターの値はdouble型またはbigint型です。 |
戻り値のデータ型
ダブルタイプ。
例
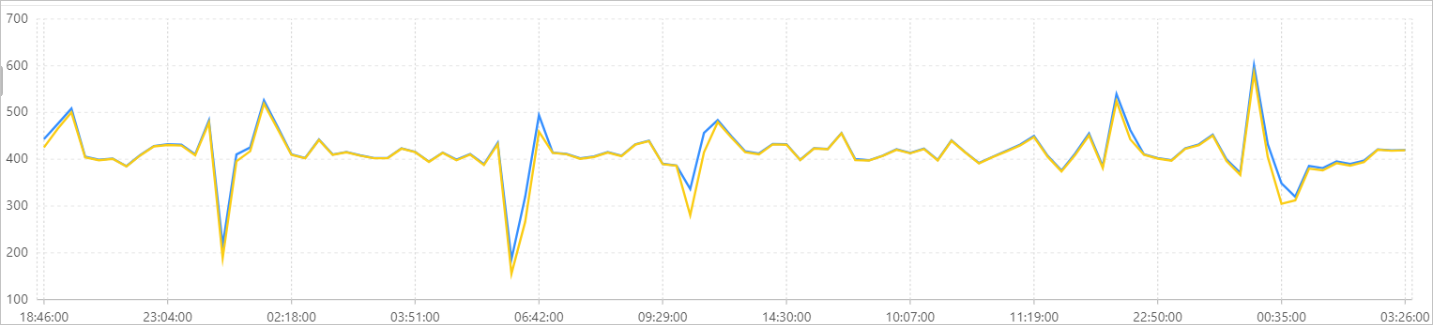
税引前所得のサンプル分散と母集団分散を計算し、計算された値を折れ線グラフに表示します。
クエリ文
* | SELECT variance(PretaxGrossAmount) as "Sample variance", var_pop(PretaxGrossAmount) as "Population variance", time_series(__time__, '1m', '%H:%i:%s', '0') as time GROUP BY timeクエリと分析結果
var_samp関数
var_samp関数は、xのサンプル分散を返します。
構文
var_samp(x)パラメーター
パラメーター | 説明 |
x | このパラメーターの値はdouble型またはbigint型です。 |
戻り値のデータ型
ダブルタイプ。
例
税引前所得のサンプル分散と母集団分散を計算し、計算された値を折れ線グラフに表示します。
クエリ文
* | SELECT var_samp(PretaxGrossAmount) as "Sample variance", var_pop(PretaxGrossAmount) as "Population variance", time_series(__time__, '1m', '%H:%i:%s', '0') as time GROUP BY timeクエリと分析結果
var_pop関数
var_pop関数は、xの母集団分散を返します。
構文
var_pop(x)パラメーター
パラメーター | 説明 |
x | このパラメーターの値はdouble型またはbigint型です。 |
戻り値のデータ型
ダブルタイプ。
例
税引前所得のサンプル分散と母集団分散を計算し、計算された値を折れ線グラフに表示します。
クエリ文
* | SELECT variance(PretaxGrossAmount) as "Sample variance", var_pop(PretaxGrossAmount) as "Population variance", time_series(__time__, '1m', '%H:%i:%s', '0') as time GROUP BY timeクエリと分析結果
regr_intercept関数
regr_intercept関数は、(x,y) のペアによって決定される線形方程式の線のy切片を返します。 xは従属値です。 yは独立した値です。
構文
regr_intercept(y, x)パラメーター
パラメーター | 説明 |
y | このパラメーターの値はdouble型です。 |
x | このパラメーターの値はdouble型です。 |
戻り値のデータ型
ダブルタイプ。
例
request_timeフィールドとrequest_lengthフィールドの値によって決定される線形方程式の線のy切片を計算します。
クエリ文
* | SELECT regr_intercept(request_length,request_time)クエリと分析結果

regr_slope関数
regr_slope関数は、(x,y) のペアによって決定される線形方程式の直線の傾きを返します。 xは従属値です。 yは独立した値です。
構文
regr_slope(y, x)パラメーター
パラメーター | 説明 |
y | このパラメーターの値はdouble型です。 |
x | このパラメーターの値はdouble型です。 |
戻り値のデータ型
ダブルタイプ。
例
request_timeフィールドとrequest_lengthフィールドの値によって決定される線形方程式の直線の傾きを計算します。
クエリ文
* | SELECT regr_slope(request_length,request_time)クエリと分析結果

beta_cdf関数
beta_cdf関数は、ベータ分布の値を返します。
構文
beta_cdf(α, β, v)パラメーター
パラメーター | 説明 |
α | ベータCDFのパラメーター。 このパラメーターの値はdouble型です。 値は0より大きい。 |
β | ベータCDFのパラメーター。 このパラメーターの値はdouble型です。 値は0より大きい。 |
v | ベータCDFの入力パラメーター。 このパラメーターの値はdouble型です。 値の範囲: [0 , 1] |
戻り値のデータ型
ダブルタイプ。
例
クエリ文
* | SELECT beta_cdf(0.1, 0.5, 0.7)クエリと分析結果
binomial_cdf関数
binomial_cdf関数は、二項分布の値を返します。
構文
binomial_cdf(x, y, v)パラメーター
パラメーター | 説明 |
x | トライアルの数。 このパラメーターの値は整数型です。 値は0より大きい。 |
y | トライアルのPOS。 このパラメーターの値はdouble型です。 値の範囲: [0 , 1] |
v | 二項CDFの入力パラメーター。 このパラメーターの値は整数型です。 |
戻り値のデータ型
ダブルタイプ。
例
クエリ文
* | select binomial_cdf(10, 0.1, 1)クエリと分析結果
cauchy_cdf関数
cauchy_cdf関数は、コーシー分布の値を返します。
構文
cauchy_cdf(x, y, v)パラメーター
パラメーター | 説明 |
x | 分布のピークを示すlocationパラメーター。 このパラメーターの値はdouble型です。 |
y | scaleパラメーター。 このパラメーターの値はdouble型です。 値は0より大きくなければなりません。 |
v | コーシーCDFの入力パラメーター。 このパラメーターの値はdouble型です。 |
戻り値のデータ型
ダブルタイプ。
例
クエリ文
* | select cauchy_cdf(-10, 5, -12)クエリと分析結果
chi_squared_cdf関数
chi_squared_cdf関数は、カイ二乗分布の値を返します。
構文
chi_squared_cdf(k, v)パラメーター
パラメーター | 説明 |
k | 自由度。 このパラメーターの値はdouble型です。 値は0より大きい。 |
v | カイ二乗CDFの入力パラメータ。 このパラメーターの値はdouble型です。 値は0以上です。 |
戻り値のデータ型
ダブルタイプ。
例
クエリ文
* | select chi_squared_cdf(3, 10)クエリと分析結果
inverse_beta_cdf関数
inverse_beta_cdf関数は、ベータ分布の逆数の値を返します。
構文
inverse_beta_cdf(α, β, p)パラメーター
パラメーター | 説明 |
α | ベータCDFのパラメーター。 このパラメーターの値はdouble型です。 値は0より大きい。 |
β | ベータCDFのパラメーター。 このパラメーターの値はdouble型です。 値は0より大きい。 |
p | ベータCDFの逆数の入力パラメーター。 このパラメーターの値はdouble型です。 値の範囲: [0 , 1] |
戻り値のデータ型
ダブルタイプ。
例
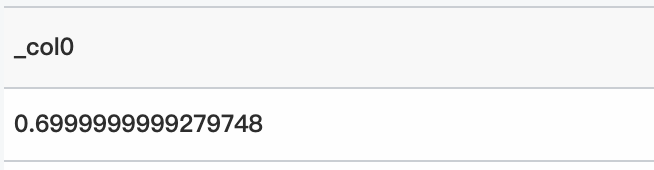
クエリ文
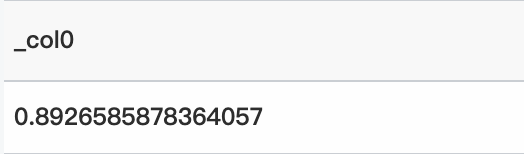
* | select inverse_beta_cdf(0.1, 0.5, 0.8926585878364057)クエリと分析結果
inverse_binomial_cdf関数
inverse_binomial_cdf関数は、二項分布の逆関数の値を返します。
構文
inverse_binomial_cdf(x, y, p)パラメーター
パラメーター | 説明 |
x | トライアルの数。 このパラメーターの値は整数型です。 値は0より大きい。 |
y | トライアルのPOS。 このパラメーターの値はdouble型です。 値の範囲: [0 , 1] |
p | 二項CDFの逆数の入力パラメーター。 このパラメーターの値はdouble型です。 値の範囲: [0 , 1] |
戻り値のデータ型
整数型。
例
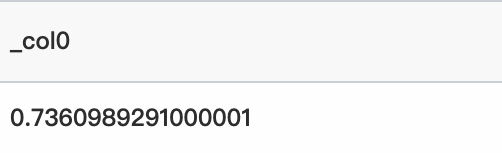
クエリ文
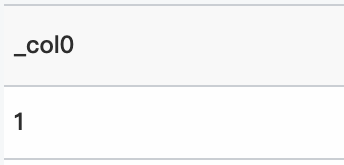
* | select inverse_binomial_cdf(10、0.1、0.7360989291000001)クエリと分析結果
inverse_cauchy_cdf関数
inverse_cauchy_cdf関数は、コーシー分布の逆数の値を返します。
構文
inverse_cauchy_cdf(x, y, p)パラメーター
パラメーター | 説明 |
x | 分布のピークを示すlocationパラメーター。 このパラメーターの値はdouble型です。 |
y | scaleパラメーター。 このパラメーターの値はdouble型です。 値は0より大きい。 |
p | コーシーCDFの逆数の入力パラメーター。 このパラメーターの値はdouble型です。 値の範囲: [0 , 1] |
戻り値のデータ型
ダブルタイプ。
例
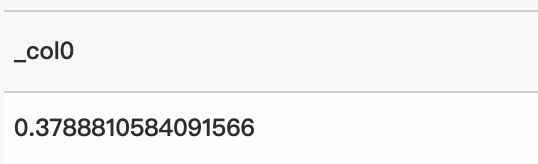
クエリ文
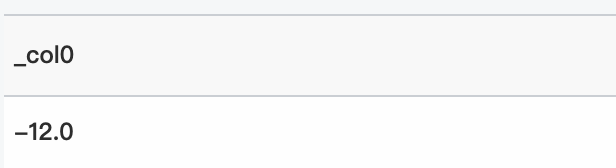
* | select inverse_cauchy_cdf(-10、5、0.3788810584091566)クエリと分析結果
inverse_chi_squared_cdf関数
inverse_chi_squared_cdf関数は、カイ二乗分布の逆数の値を返します。
構文
chi_squared_cdf(k, p)パラメーター
パラメーター | 説明 |
k | 自由度。 このパラメーターの値はdouble型です。 値は0より大きい。 |
p | カイ二乗CDFの逆数の入力パラメータ。 このパラメーターの値はdouble型です。 値の範囲: [0 , 1] |
戻り値のデータ型
ダブルタイプ。
例
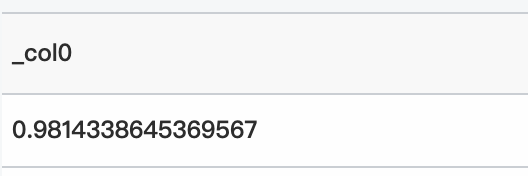
クエリ文
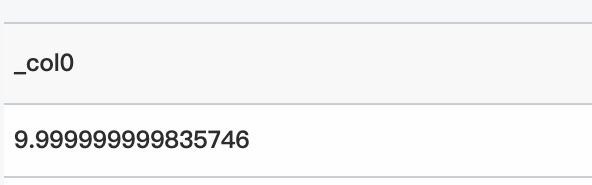
* | select inverse_chi_squared_cdf(3, 0.9814338645369567)クエリと分析結果
inverse_laplace_cdf関数
inverse_laplace_cdf関数は、ラプラス分布の逆数の値を返します。
構文
inverse_laplace_cdf(μ, b, p)パラメーター
パラメーター | 説明 |
μ | ラプラスCDFの位置パラメーター。 このパラメーターの値はdouble型です。 |
b | ラプラスCDFのスケールパラメータ。 このパラメーターの値はdouble型です。 値は0より大きい。 |
p | ラプラスCDFの逆数の入力パラメータ。 このパラメーターの値はdouble型です。 値の範囲: [0 , 1] |
戻り値のデータ型
ダブルタイプ。
例
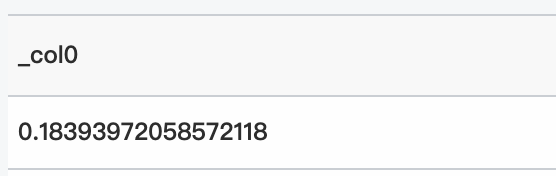
クエリ文
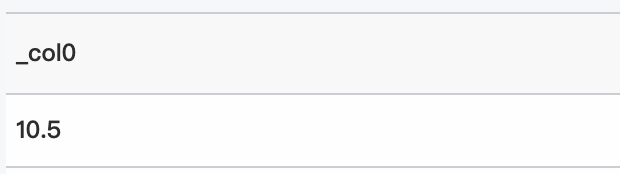
* | select inverse_laplace_cdf(11、0.5、0.18393972058572118)クエリと分析結果
inverse_normal_cdf関数
inverse_normal_cdf関数は、正規分布の逆数の値を返します。
構文
inverse_normal_cdf(x, y, p)パラメーター
パラメーター | 説明 |
x | 正規分布の平均値。 このパラメーターの値はdouble型です。 |
y | 正規分布の標準偏差。 このパラメーターの値はdouble型です。 値は0より大きい。 |
p | 通常のCDFの逆数の入力パラメータ。 このパラメーターの値はdouble型です。 有効な値: (0,1) 。 |
戻り値のデータ型
ダブルタイプ。
例
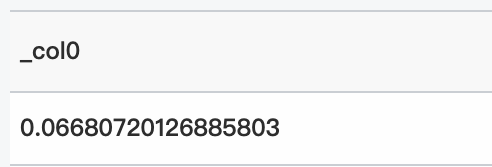
クエリ文
* | select inverse_normal_cdf(85、10、0.06680720126885803)クエリと分析結果
inverse_poisson_cdf関数
inverse_poisson_cdf関数は、ポアソン分布の逆関数の値を返します。
構文
inverse_poisson_cdf(λ, p)パラメーター
パラメーター | 説明 |
λ | ランダムイベントの平均確率。 |
p | ポアソンCDFの逆関数の入力パラメータ。 このパラメーターの値はdouble型です。 値の範囲: [0 , 1] |
戻り値のデータ型
整数型。
例
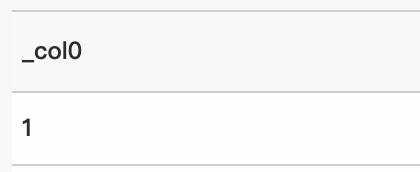
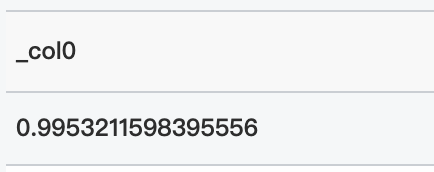
クエリ文
* | select inverse_poisson_cdf(0.1、0.9953211598395556)クエリと分析結果
inverse_weibull_cdf関数
inverse_weibull_cdf関数は、ワイブル分布の逆数の値を返します。
構文
inverse_weibull_cdf(x, y, p)パラメーター
パラメーター | 説明 |
x | ワイブルCDFのスケールパラメータ。 このパラメーターの値はdouble型です。 値は0より大きい。 |
y | ワイブルCDFの形状パラメータ。 このパラメーターの値はdouble型です。 値は0より大きい。 |
p | ワイブルCDFの逆数の入力パラメータ。 このパラメーターの値はdouble型です。 有効な値: [0,1] 。 |
戻り値のデータ型
ダブルタイプ。
例
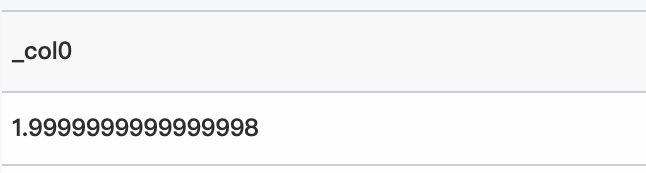
クエリ文
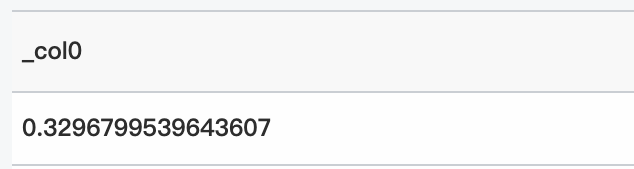
* | select inverse_weibull_cdf(1, 5, 0.3296799539643607)クエリと分析結果
laplace_cdf関数
laplace_cdf関数は、ラプラス分布の値を返します。
構文
laplace_cdf(μ 、b、v)パラメーター
パラメーター | 説明 |
μ | ラプラスCDFの位置パラメーター。 このパラメーターの値はdouble型です。 |
b | ラプラスCDFのスケールパラメータ。 このパラメーターの値はdouble型です。 値は0より大きい。 |
v | ラプラスCDFの入力パラメーター。 このパラメーターの値はdouble型です。 |
戻り値のデータ型
ダブルタイプ。
例
クエリ文
* | select laplace_cdf(11、0.5、10.5)クエリと分析結果
normal_cdf関数
normal_cdf関数は、正規分布の値を返します。
構文
normal_cdf(x, y, v)パラメーター
パラメーター | 説明 |
x | 正規分布の平均値。 このパラメーターの値はdouble型です。 |
y | 正規分布の標準偏差。 このパラメーターの値はdouble型です。 値は0より大きい。 |
v | 通常のCDFの入力パラメーター。 このパラメーターの値はdouble型です。 |
戻り値のデータ型
ダブルタイプ。
例
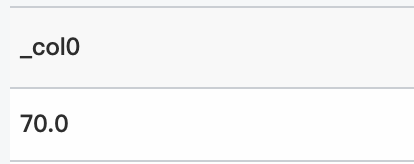
クエリ文
* | select normal_cdf (85, 10, 70)クエリと分析結果
poisson_cdf関数
poisson_cdf関数は、ポアソン分布の値を返します。
構文
poisson_cdf(λ, v)パラメーター
パラメーター | 説明 |
λ | ランダムイベントの平均確率。 |
v | ポアソンCDFの入力パラメーター。 このパラメーターの値は整数型です。 値は0以上です。 |
戻り値のデータ型
ダブルタイプ。
例
クエリ文
* | select poisson_cdf(0.1, 1)クエリと分析結果
weibull_cdf関数
weibull_cdf関数は、ワイブル分布の値を返します。
構文
weibull_cdf(x, y, v)パラメーター
パラメーター | 説明 |
x | ワイブルCDFのスケールパラメータ。 このパラメーターの値はdouble型です。 値は0より大きい。 |
y | ワイブルCDFの形状パラメータ。 このパラメーターの値はdouble型です。 値は0より大きい。 |
v | ワイブルCDFの入力パラメーター。 このパラメーターの値はdouble型です。 |
戻り値のデータ型
例
クエリ文
* | select weibull_cdf(1, 5, 2)クエリと分析結果