フィールド処理プラグインは、フィールドの追加、削除、変更、パック、展開、抽出に使用されます。
フィールド処理の例
次の表は、Simple Log Service に保存された後の生ログのデータ構造を示しています。この表では、区切り文字モードでフィールド抽出プラグインを使用した場合の結果と、プラグインを使用しない場合の結果を比較しています。抽出プラグインを使用するとデータが構造化され、その後のクエリが容易になります。
生ログ | フィールド処理プラグインなし | 区切り文字モードでフィールド抽出プラグインを使用 |
| Content: "time:2022.09.12 20:55:36\t json:{\"key1\" : \"xx\", \"key2\": false, \"key3\":123.456, \"key4\" : { \"inner1\" : 1, \"inner2\" : false}}" | フィールド値は区切り文字モードで抽出されます。フィールド名は time、val_key1、val_key2、val_key3、value_key4_inner1、および value_key4_inner2 に設定されます。 |
フィールド処理プラグインの概要
Simple Log Service は、次のタイプのフィールド処理プラグインを提供します。要件に基づいてプラグインを選択できます。
プラグイン名 | タイプ | 説明 |
フィールドの抽出 | 拡張 | 次のモードをサポートしています:
|
フィールドの追加 | 拡張 | ログに新しいフィールドを追加します。 |
フィールドの削除 | 拡張 | 指定されたフィールドを削除します。 |
フィールド名の変更 | 拡張 | フィールド名を変更します。 |
フィールドのパック | 拡張 | 複数のフィールドを単一の JSON オブジェクトにパックします。 |
JSON フィールドの展開 | 拡張 | JSON 文字列フィールドを個別のフィールドに展開します。 |
フィールド値のマッピング | 拡張 | マッピングテーブルに基づいてフィールド値を置換または変換します。 |
文字列の置換 | 拡張 | テキストログの全文置換、正規表現ベースの置換、またはエスケープ文字の削除を実行します。 |
エントリポイント
Logtail プラグインを使用してログを処理する場合は、Logtail 構成を作成または変更するときに Logtail プラグイン構成を追加できます。詳細については、「概要」をご参照ください。
制限
テキストログとコンテナーの標準出力は、フォームベースの構成のみをサポートします。他の入力ソースは JSON 構成のみをサポートします。
正規表現モードでフィールドを抽出する場合、次の制限が適用されます。
Go の正規表現エンジンは RE2 に基づいています。PCRE エンジンと比較して、次の制限があります:
名前付きグループ構文の違い
Go は
(?P<name>...)構文を使用し、PCRE で使用される(?<name>...)構文は使用しません。サポートされていない正規表現パターン
アサーション:
(?=...)、(?!...)、(?<=...)、(?<!...)。条件式:
(?(condition)true|false)。再帰的マッチング:
(?R)、(?0)。サブルーチン参照:
(?&name)、(?P>name)。アトミックグループ:
(?>...)。
Regex101 などのツールで正規表現をデバッグする場合は、上記のサポートされていないパターンを避けてください。そうしないと、プラグインはログを処理できません。
フィールド抽出プラグイン
正規表現モード、区切り文字モード、CSV モード、単一文字区切りモード、複数文字区切りモード、キーと値のペアモード、または Grok モードでログフィールドを抽出します。
正規表現モード
正規表現を使用してターゲットフィールドを抽出します。
フォームベースの構成
パラメーター
[プロセッサタイプ] を [フィールドの抽出 (正規表現モード)] に設定します。次の表にパラメーターを示します。
パラメーター
説明
ソースフィールド
ソースフィールドの名前。
正規表現
正規表現。括弧
()を使用して、抽出するフィールドをマークします。結果フィールド
抽出されたコンテンツの名前。複数のフィールド名を追加できます。
ソースフィールドが見つからない場合にエラーを報告
このオプションを選択すると、生ログにソースフィールドが見つからない場合にエラーが報告されます。
一致しない場合にエラーを報告
このオプションを選択すると、正規表現がソースフィールドの値と一致しない場合にエラーが報告されます。
ソースフィールドを保持
このオプションを選択すると、解析されたログにソースフィールドが保持されます。
解析失敗時にソースフィールドを保持
このオプションを選択すると、解析に失敗した場合に解析されたログにソースフィールドが保持されます。
完全一致
このオプションを選択すると、[結果フィールド] で設定されたすべてのフィールドが、指定された正規表現に基づいてソースフィールド値と一致する場合にのみ、フィールド値が抽出されます。
例
正規表現モードで content フィールドの値を抽出し、フィールド名を
ip、time、method、url、request_time、request_length、status、length、ref_url、および browser に設定します。以下に構成例を示します。生ログ
"content" : "10.200.**.** - - [10/Aug/2022:14:57:51 +0800] \"POST /PutData? Category=YunOsAccountOpLog&AccessKeyId=<yourAccessKeyId>&Date=Fri%2C%2028%20Jun%202013%2006%3A53%3A30%20GMT&Topic=raw&Signature=<yourSignature> HTTP/1.1\" 0.024 18204 200 37 \"-\" \"aliyun-sdk-java"Logtail プラグイン構成
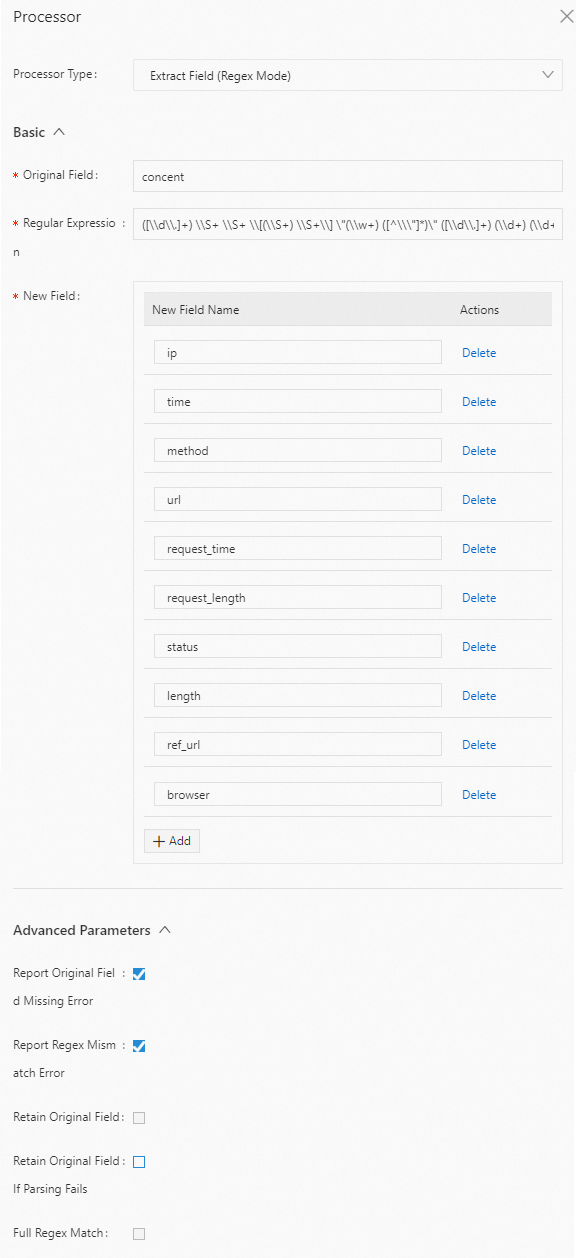
結果
"ip" : "10.200.**.**" "time" : "10/Aug/2022:14:57:51" "method" : "POST" "url" : "/PutData?Category=YunOsAccountOpLog&AccessKeyId=<yourAccessKeyId>&Date=Fri%2C%2028%20Jun%202013%2006%3A53%3A30%20GMT&Topic=raw&Signature=<yourSignature>" "request_time" : "0.024" "request_length" : "18204" "status" : "200" "length" : "27" "ref_url" : "-" "browser" : "aliyun-sdk-java"
JSON 構成
パラメーター
type を processor_regex に設定します。次の表に detail のパラメーターを示します。
パラメーター
タイプ
必須
説明
SourceKey
String
はい
ソースフィールドの名前。
Regex
String
はい
正規表現。括弧
()を使用して、抽出するフィールドをマークします。Keys
文字列配列
はい
抽出されたコンテンツの名前。例: ["ip", "time", "method"]。
NoKeyError
ブール値
いいえ
生ログにソースフィールドが見つからない場合にエラーを報告するかどうかを指定します。
true: エラーが報告されます。
false (デフォルト): エラーは報告されません。
NoMatchError
ブール値
いいえ
正規表現がソースフィールドの値と一致しない場合にエラーを報告するかどうかを指定します。
true (デフォルト): エラーが報告されます。
false: エラーは報告されません。
KeepSource
ブール値
いいえ
解析されたログにソースフィールドを保持するかどうかを指定します。
true: ソースフィールドを保持します。
false (デフォルト): ソースフィールドを保持しません。
FullMatch
ブール値
いいえ
完全一致が見つかった場合にのみフィールド値を抽出するかどうかを指定します。
true (デフォルト): Keys パラメーターで設定したすべてのフィールドが、Regex パラメーターの正規表現に基づいてソースフィールドの値と一致する場合にのみ、フィールド値が抽出されます。
false: 部分一致が見つかった場合でもフィールド値が抽出されます。
KeepSourceIfParseError
ブール値
いいえ
解析に失敗した場合に解析されたログにソースフィールドを保持するかどうかを指定します。
true (デフォルト): ソースフィールドを保持します。
false: ソースフィールドを保持しません。
例
正規表現モードで content フィールドの値を抽出し、フィールド名を ip、time、method、url、request_time、request_length、status、length、ref_url、および browser に設定します。以下に構成例を示します。
生ログ
"content" : "10.200.**.** - - [10/Aug/2022:14:57:51 +0800] \"POST /PutData? Category=YunOsAccountOpLog&AccessKeyId=<yourAccessKeyId>&Date=Fri%2C%2028%20Jun%202013%2006%3A53%3A30%20GMT&Topic=raw&Signature=<yourSignature> HTTP/1.1\" 0.024 18204 200 37 \"-\" \"aliyun-sdk-java"Logtail プラグイン構成
{ "type" : "processor_regex", "detail" : {"SourceKey" : "content", "Regex" : "([\\d\\.]+) \\S+ \\S+ \\[(\\S+) \\S+\\] \"(\\w+) ([^\\\"]*)\" ([\\d\\.]+) (\\d+) (\\d+) (\\d+|-) \"([^\\\"]*)\" \"([^\\\"]*)\" (\\d+)", "Keys" : ["ip", "time", "method", "url", "request_time", "request_length", "status", "length", "ref_url", "browser"], "NoKeyError" : true, "NoMatchError" : true, "KeepSource" : false } }結果
"ip" : "10.200.**.**" "time" : "10/Aug/2022:14:57:51" "method" : "POST" "url" : "/PutData?Category=YunOsAccountOpLog&AccessKeyId=<yourAccessKeyId>&Date=Fri%2C%2028%20Jun%202013%2006%3A53%3A30%20GMT&Topic=raw&Signature=<yourSignature>" "request_time" : "0.024" "request_length" : "18204" "status" : "200" "length" : "27" "ref_url" : "-" "browser" : "aliyun-sdk-java"
区切り文字モード
開始キーワードと終了キーワードを指定してフィールドを抽出します。フィールドが JSON 形式の場合、展開できます。
フォームベースの構成
パラメーター
[プロセッサタイプ] を [フィールドの抽出 (区切り文字モード)] に設定します。次の表にパラメーターを示します。
パラメーター
説明
ソースフィールド
ソースフィールドの名前。
キャリブレーション項目リスト
キャリブレーション項目のリスト。
開始キーワード
開始キーワード。このパラメーターを空のままにすると、一致は文字列の先頭から開始されます。
終了キーワード
終了キーワード。このパラメーターを空のままにすると、一致は文字列の末尾まで拡張されます。
結果フィールド
抽出されたコンテンツの名前。
フィールドタイプ
フィールドのタイプ。有効な値は string と json です。
JSON の展開
JSON フィールドを展開するかどうかを指定します。
JSON 展開コネクタ
JSON 展開用のコネクタ。デフォルト値はアンダースコア (_) です。
最大 JSON 展開深度
JSON 展開の最大深度。デフォルト値は 0 で、制限がないことを意味します。
ソースフィールドが見つからない場合にエラーを報告
このオプションを選択すると、生ログにソースフィールドが見つからない場合にエラーが報告されます。
区切り項目が見つからない場合にエラーを報告
このオプションを選択すると、生ログに一致する区切り項目が見つからない場合にエラーが報告されます。
ソースフィールドを保持
このオプションを選択すると、解析されたログにソースフィールドが保持されます。
例
区切り文字モードで content フィールドの値を抽出し、フィールド名を time、val_key1、val_key2、val_key3、value_key4_inner1、および value_key4_inner2 に設定します。以下に構成例を示します。
生ログ
"content" : "time:2022.09.12 20:55:36\t json:{\"key1\" : \"xx\", \"key2\": false, \"key3\":123.456, \"key4\" : { \"inner1\" : 1, \"inner2\" : false}}"Logtail プラグイン構成
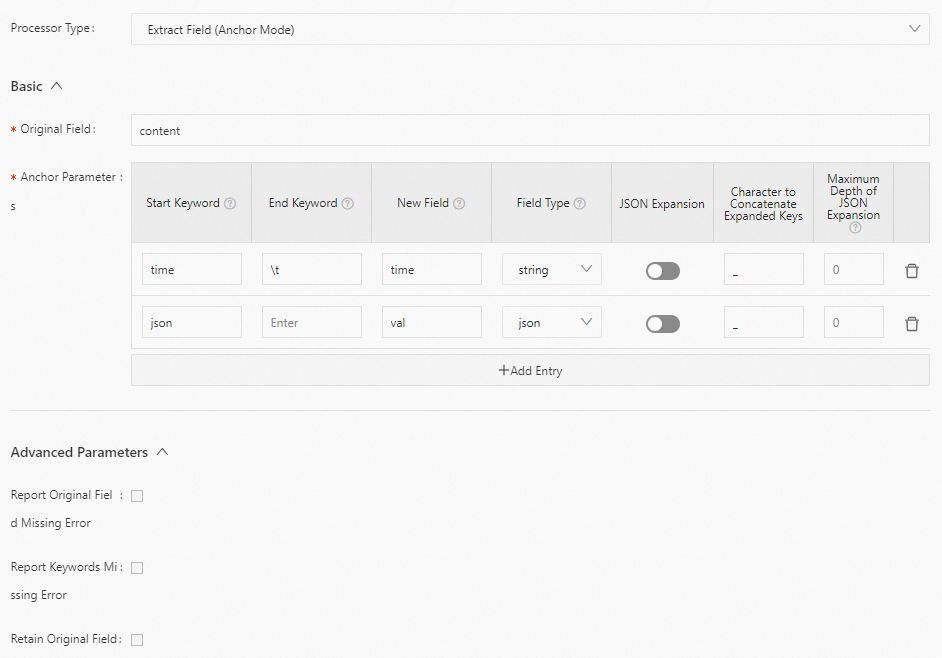
結果
"time" : "2022.09.12 20:55:36" "val_key1" : "xx" "val_key2" : "false" "val_key3" : "123.456" "value_key4_inner1" : "1" "value_key4_inner2" : "false"
JSON 構成
パラメーター
type を processor_anchor に設定します。次の表に detail のパラメーターを示します。
パラメーター
タイプ
必須
説明
SourceKey
String
はい
ソースフィールドの名前。
Anchors
アンカー配列
はい
キャリブレーション項目。
Start
String
はい
開始キーワード。これが空の場合、文字列の先頭に一致します。
Stop
String
はい
終了キーワード。これが空の場合、文字列の末尾に一致します。
FieldName
String
はい
抽出されたコンテンツの名前。
FieldType
String
はい
フィールドのタイプ。有効な値は string と json です。
ExpondJson
ブール値
いいえ
JSON フィールドを展開するかどうかを指定します。
true: フィールドを展開します。
false (デフォルト): フィールドを展開しません。
このパラメーターは、FieldType が json に設定されている場合にのみ有効です。
ExpondConnecter
String
いいえ
JSON 展開用のコネクタ。デフォルト値はアンダースコア (_) です。
MaxExpondDepth
Int
いいえ
JSON 展開の最大深度。デフォルト値は 0 で、制限がないことを意味します。
NoAnchorError
ブール値
いいえ
区切り項目が見つからない場合にエラーを報告するかどうかを指定します。
true: エラーが報告されます。
false (デフォルト): エラーは報告されません。
NoKeyError
ブール値
いいえ
生ログにソースフィールドが見つからない場合にエラーを報告するかどうかを指定します。
true: エラーが報告されます。
false (デフォルト): エラーは報告されません。
KeepSource
ブール値
いいえ
解析されたログにソースフィールドを保持するかどうかを指定します。
true: ソースフィールドを保持します。
false (デフォルト): ソースフィールドを保持しません。
例
区切り文字モードで content フィールドの値を抽出し、フィールド名を time、val_key1、val_key2、val_key3、value_key4_inner1、および value_key4_inner2 に設定します。以下に構成例を示します。
生ログ
"content" : "time:2022.09.12 20:55:36\t json:{\"key1\" : \"xx\", \"key2\": false, \"key3\":123.456, \"key4\" : { \"inner1\" : 1, \"inner2\" : false}}"Logtail プラグイン構成
{ "type" : "processor_anchor", "detail" : {"SourceKey" : "content", "Anchors" : [ { "Start" : "time", "Stop" : "\t", "FieldName" : "time", "FieldType" : "string", "ExpondJson" : false }, { "Start" : "json:", "Stop" : "", "FieldName" : "val", "FieldType" : "json", "ExpondJson" : true } ] } }結果
"time" : "2022.09.12 20:55:36" "val_key1" : "xx" "val_key2" : "false" "val_key3" : "123.456" "value_key4_inner1" : "1" "value_key4_inner2" : "false"
CSV モード
CSV 形式のログを解析します。
フォームベースの構成
パラメーター
[プロセッサタイプ] を [フィールドの抽出 (CSV モード)] に設定します。次の表にパラメーターを示します。
パラメーター
説明
ソースフィールド
ソースフィールドの名前。
結果フィールド
抽出されたコンテンツの名前。複数のフィールド名を追加できます。
重要[結果フィールド] のフィールド数より分割するフィールド数が少ない場合、[結果フィールド] の余分なフィールドは無視されます。
区切り文字
区切り文字。デフォルト値はカンマ (,) です。
残りの部分を保持
このオプションを選択すると、分割するフィールドの数が [結果フィールド] のフィールド数より大きい場合、システムは残りのコンテンツを保持します。
残りの部分を解析
このオプションを選択すると、システムは残りのコンテンツを解析し、[残りの部分のフィールドプレフィックス] の値を残りのフィールド名のプレフィックスとして使用します。
[残りの部分を保持] を選択し、[残りの部分を解析] を選択しない場合、残りのコンテンツは _decode_preserve_ フィールドに保存されます。
説明残りのコンテンツが標準の CSV 形式でない場合は、保存する前に標準化する必要があります。
残りの部分のフィールドプレフィックス
残りのフィールド名のプレフィックス。たとえば、これを expand_ に設定すると、フィールド名は expand_1、expand_2 などになります。
先頭のスペースを無視
このオプションを選択すると、システムはフィールド値の先頭のスペースを無視します。
ソースフィールドを保持
このオプションを選択すると、解析されたログにソースフィールドが保持されます。
ソースフィールドが見つからない場合にエラーを報告
このオプションを選択すると、ログにソースフィールドが見つからない場合にエラーが報告されます。
例
csv フィールドの値を抽出します。以下に構成例を示します。
生ログ
{ "csv": "2022-06-09,192.0.2.0,\"{\"\"key1\"\":\"\"value\"\",\"\"key2\"\":{\"\"key3\"\":\"\"string\"\"}}\"", ...... }Logtail プラグイン構成
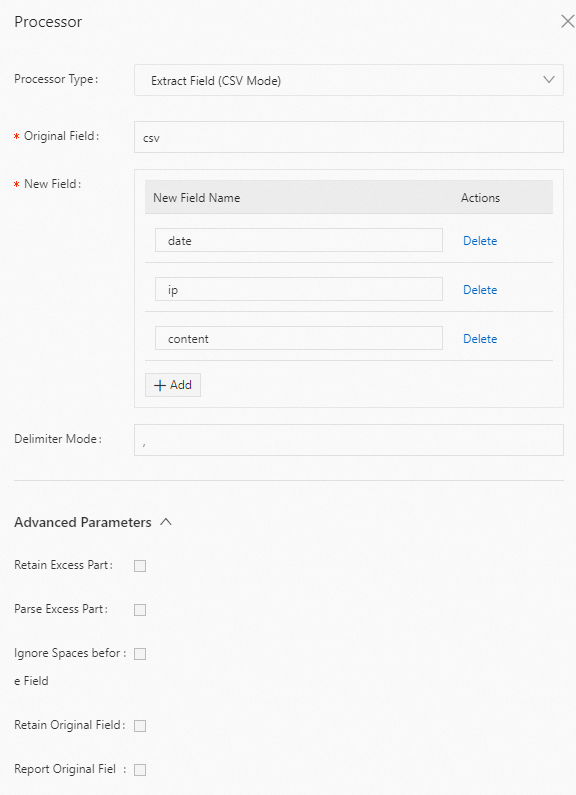
結果
{ "date": "2022-06-09", "ip": "192.0.2.0", "content": "{\"key1\":\"value\",\"key2\":{\"key3\":\"string\"}}" ...... }
JSON 構成
パラメーター
type を processor_csv に設定します。次の表に detail のパラメーターを示します。
パラメーター
タイプ
必須
説明
SourceKey
String
はい
ソースフィールドの名前。
SplitKeys
文字列配列
はい
抽出されたコンテンツの名前。例: ["date", "ip", "content"]。
重要SplitKeys パラメーターのフィールド数より分割するフィールド数が少ない場合、SplitKeys パラメーターの余分なフィールドは無視されます。
PreserveOthers
ブール値
いいえ
分割するフィールドの数が SplitKeys パラメーターのフィールド数より大きい場合に、残りの部分を保持するかどうかを指定します。
true: 残りの部分を保持します。
false (デフォルト): 残りの部分を保持しません。
ExpandOthers
ブール値
いいえ
残りの部分を解析するかどうかを指定します。
true: 残りの部分を解析します。
ExpandOthers パラメーターを使用して残りの部分を解析し、ExpandKeyPrefix パラメーターを使用して残りのフィールド名のプレフィックスを指定できます。
false (デフォルト): 残りの部分を解析しません。
PreserveOthers を true に、ExpandOthers を false に設定すると、残りのコンテンツは _decode_preserve_ フィールドに保存されます。
説明残りのコンテンツが標準の CSV 形式でない場合は、保存する前に標準化する必要があります。
ExpandKeyPrefix
String
いいえ
残りのフィールド名のプレフィックス。たとえば、これを expand_ に設定すると、フィールド名は expand_1、expand_2 などになります。
TrimLeadingSpace
ブール値
いいえ
フィールド値の先頭のスペースを無視するかどうかを指定します。
true: 先頭のスペースを無視します。
false (デフォルト): 先頭のスペースを無視しません。
SplitSep
String
いいえ
区切り文字。デフォルト値はカンマ (,) です。
KeepSource
ブール値
いいえ
解析されたログにソースフィールドを保持するかどうかを指定します。
true: ソースフィールドを保持します。
false (デフォルト): ソースフィールドを保持しません。
NoKeyError
ブール値
いいえ
生ログにソースフィールドが見つからない場合にエラーを報告するかどうかを指定します。
true: エラーが報告されます。
false (デフォルト): エラーは報告されません。
例
csv フィールドの値を抽出します。以下に構成例を示します。
生ログ
{ "csv": "2022-06-09,192.0.2.0,\"{\"\"key1\"\":\"\"value\"\",\"\"key2\"\":{\"\"key3\"\":\"\"string\"\"}}\"", ...... }Logtail プラグイン構成
{ ...... "type":"processor_csv", "detail":{ "SourceKey":"csv", "SplitKeys":["date", "ip", "content"], } ...... }結果
{ "date": "2022-06-09", "ip": "192.0.2.0", "content": "{\"key1\":\"value\",\"key2\":{\"key3\":\"string\"}}" ...... }
単一文字区切りモード
単一文字の区切り文字を使用してフィールドを抽出します。このモードは、区切り文字を含むフィールドを囲む引用符文字の使用をサポートします。
フォームベースの構成
パラメーター
[プロセッサタイプ] を [フィールドの抽出 (単一文字区切りモード)] に設定します。次の表にパラメーターを示します。
パラメーター
説明
ソースフィールド
ソースフィールドの名前。
区切り文字
区切り文字。単一の文字である必要があります。\u0001 のような印刷不可能な文字に設定できます。
結果フィールド
抽出されたコンテンツの名前。
引用符文字を使用
引用符文字を使用するかどうかを指定します。
引用符文字
引用符文字。単一の文字である必要があります。\u0001 のような印刷不可能な文字に設定できます。
ソースフィールドが見つからない場合にエラーを報告
このオプションを選択すると、生ログにソースフィールドが見つからない場合にエラーが報告されます。
区切り文字が一致しない場合にエラーを報告
このオプションを選択すると、指定された区切り文字でログを分割できない場合にエラーが報告されます。
ソースフィールドを保持
このオプションを選択すると、解析されたログにソースフィールドが保持されます。
例
区切り文字として縦棒 (|) を使用して content フィールドの値を抽出し、フィールド名を ip、time、method、url、request_time、request_length、status、length、ref_url、および browser に設定します。以下に構成例を示します。
生ログ
"content" : "10.**.**.**|10/Aug/2022:14:57:51 +0800|POST|PutData? Category=YunOsAccountOpLog&AccessKeyId=<yourAccessKeyId>&Date=Fri%2C%2028%20Jun%202013%2006%3A53%3A30%20GMT&Topic=raw&Signature=<yourSignature>|0.024|18204|200|37|-| aliyun-sdk-java"Logtail プラグイン構成
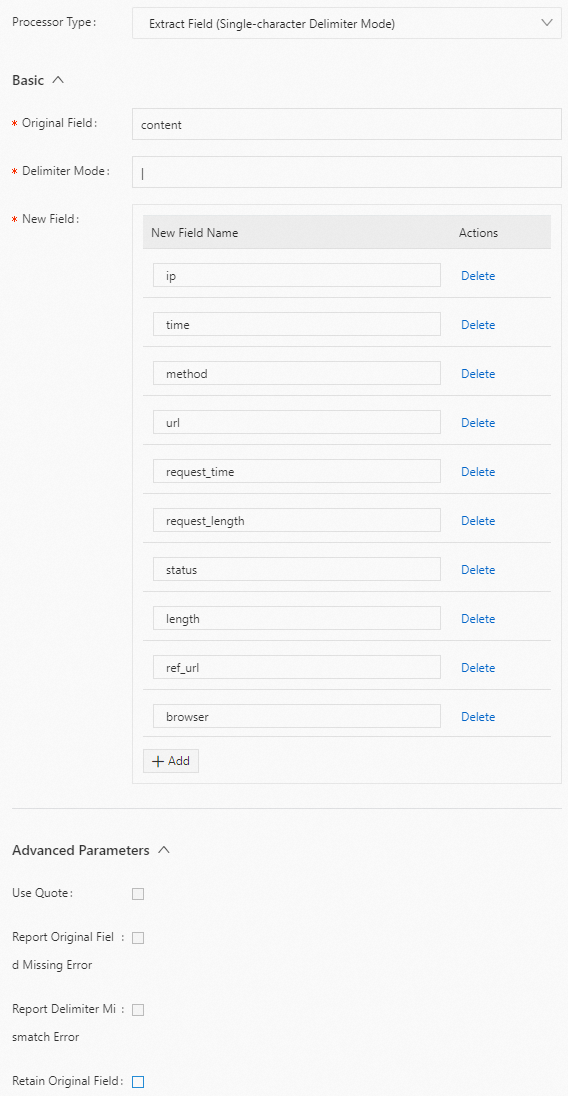
結果
"ip" : "10.**.**.**" "time" : "10/Aug/2022:14:57:51 +0800" "method" : "POST" "url" : "/PutData?Category=YunOsAccountOpLog&AccessKeyId=<yourAccessKeyId>&Date=Fri%2C%2028%20Jun%202013%2006%3A53%3A30%20GMT&Topic=raw&Signature=<yourSignature>" "request_time" : "0.024" "request_length" : "18204" "status" : "200" "length" : "27" "ref_url" : "-" "browser" : "aliyun-sdk-java"
JSON 構成
パラメーター
type を processor_split_char に設定します。次の表に detail のパラメーターを示します。
パラメーター
タイプ
必須
説明
SourceKey
String
はい
ソースフィールドの名前。
SplitSep
String
はい
区切り文字。単一の文字である必要があります。\u0001 のような印刷不可能な文字に設定できます。
SplitKeys
文字列配列
はい
抽出されたコンテンツの名前。例: ["ip", "time", "method"]。
PreserveOthers
ブール値
いいえ
分割するフィールドの数が SplitKeys パラメーターのフィールド数より大きい場合に、残りの部分を保持するかどうかを指定します。
true: 残りの部分を保持します。
false (デフォルト): 残りの部分を保持しません。
QuoteFlag
ブール値
いいえ
引用符文字を使用するかどうかを指定します。
true: 有効
false (デフォルト): 引用符文字を使用しません。
Quote
String
いいえ
引用符文字。単一の文字である必要があります。\u0001 のような印刷不可能な文字に設定できます。
このパラメーターは、QuoteFlag が true に設定されている場合にのみ有効です。
NoKeyError
ブール値
いいえ
生ログにソースフィールドが見つからない場合にエラーを報告するかどうかを指定します。
true: エラーが報告されます。
false (デフォルト): エラーは報告されません。
NoMatchError
ブール値
いいえ
指定された区切り文字がログの区切り文字と一致しない場合にエラーを報告するかどうかを指定します。
true: エラーが報告されます。
false (デフォルト): エラーは報告されません。
KeepSource
ブール値
いいえ
解析されたログにソースフィールドを保持するかどうかを指定します。
true: ソースフィールドを保持します。
false (デフォルト): ソースフィールドを保持しません。
例
区切り文字として縦棒 (|) を使用して content フィールドの値を抽出し、フィールド名を ip、time、method、url、request_time、request_length、status、length、ref_url、および browser に設定します。以下に構成例を示します。
生ログ
"content" : "10.**.**.**|10/Aug/2022:14:57:51 +0800|POST|PutData? Category=YunOsAccountOpLog&AccessKeyId=<yourAccessKeyId>&Date=Fri%2C%2028%20Jun%202013%2006%3A53%3A30%20GMT&Topic=raw&Signature=<yourSignature>|0.024|18204|200|37|-| aliyun-sdk-java"Logtail プラグイン構成
{ "type" : "processor_split_char", "detail" : {"SourceKey" : "content", "SplitSep" : "|", "SplitKeys" : ["ip", "time", "method", "url", "request_time", "request_length", "status", "length", "ref_url", "browser"] } }結果
"ip" : "10.**.**.**" "time" : "10/Aug/2022:14:57:51 +0800" "method" : "POST" "url" : "/PutData?Category=YunOsAccountOpLog&AccessKeyId=<yourAccessKeyId>&Date=Fri%2C%2028%20Jun%202013%2006%3A53%3A30%20GMT&Topic=raw&Signature=<yourSignature>" "request_time" : "0.024" "request_length" : "18204" "status" : "200" "length" : "27" "ref_url" : "-" "browser" : "aliyun-sdk-java"
複数文字区切りモード
複数文字の区切り文字を使用してフィールドを抽出します。このモードは、フィールドを囲む引用符文字の使用をサポートしていません。
フォームベースの構成
パラメーター
[プロセッサタイプ] を [フィールドの抽出 (複数文字区切りモード)] に設定します。次の表にパラメーターを示します。
パラメーター
説明
ソースフィールド
ソースフィールドの名前。
区切り文字列
区切り文字。 \u0001\u0002 のような印刷不可能な文字に設定できます。
結果フィールド
抽出されたログコンテンツの名前。
重要ログを分割して生成されるフィールド数が [結果フィールド] で指定されたフィールド数より少ない場合、[結果フィールド] の余分なフィールド名は無視されます。
ソースフィールドが見つからない場合にエラーを報告
このオプションを選択すると、ログにソースフィールドが見つからない場合にエラーが報告されます。
区切り文字が一致しない場合にエラーを報告
このオプションを選択すると、指定された区切り文字でログを分割できない場合にエラーが報告されます。
ソースフィールドを保持
このオプションを選択すると、解析されたログにソースフィールドが保持されます。
残りの部分を保持
このオプションを選択すると、ログを分割して生成されるフィールド数が [結果フィールド] で指定されたフィールド数より多い場合、システムは残りのコンテンツを保持します。
残りの部分を解析
このオプションを選択すると、ログを分割して生成されるフィールド数が [結果フィールド] のフィールド数より多い場合、システムは残りのコンテンツを解析します。[残りのフィールド名のプレフィックス] を使用して、残りのフィールド名のプレフィックスを指定できます。
残りのフィールド名のプレフィックス
残りのフィールド名のプレフィックス。たとえば、これを expand_ に設定すると、フィールド名は expand_1、expand_2 などになります。
例
区切り文字 |#| を使用して content フィールドの値を抽出し、フィールド名を ip、time、method、url、request_time、request_length、status、expand_1、expand_2、および expand_3 に設定します。以下に構成例を示します。
生ログ
"content" : "10.**.**.**|#|10/Aug/2022:14:57:51 +0800|#|POST|#|PutData? Category=YunOsAccountOpLog&AccessKeyId=<yourAccessKeyId>&Date=Fri%2C%2028%20Jun%202013%2006%3A53%3A30%20GMT&Topic=raw&Signature=<yourSignature>|#|0.024|#|18204|#|200|#|27|#|-|#| aliyun-sdk-java"Logtail プラグイン構成
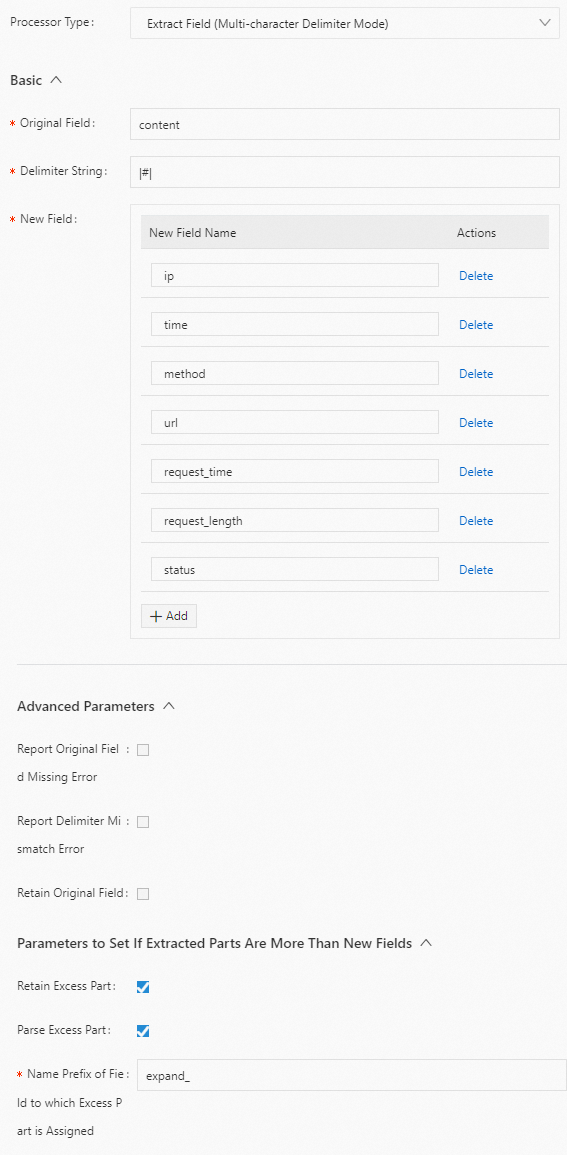
結果
"ip" : "10.**.**.**" "time" : "10/Aug/2022:14:57:51 +0800" "method" : "POST" "url" : "/PutData?Category=YunOsAccountOpLog&AccessKeyId=<yourAccessKeyId>&Date=Fri%2C%2028%20Jun%202013%2006%3A53%3A30%20GMT&Topic=raw&Signature=<yourSignature>" "request_time" : "0.024" "request_length" : "18204" "status" : "200" "expand_1" : "27" "expand_2" : "-" "expand_3" : "aliyun-sdk-java"
JSON 構成
パラメーター
type を processor_split_string に設定します。次の表に detail のパラメーターを示します。
パラメーター
タイプ
必須
説明
SourceKey
String
はい
ソースフィールドの名前。
SplitSep
String
はい
区切り文字。 \u0001\u0002 のような印刷不可能な文字に設定できます。
SplitKeys
文字列配列
はい
抽出されたログコンテンツの名前。例: ["key1","key2"]。
説明SplitKeys パラメーターのフィールド数より分割するフィールド数が少ない場合、SplitKeys パラメーターの余分なフィールドは無視されます。
PreserveOthers
ブール値
いいえ
分割するフィールドの数が SplitKeys パラメーターのフィールド数より大きい場合に、残りの部分を保持するかどうかを指定します。
true: 残りの部分を保持します。
false (デフォルト): 残りの部分を保持しません。
ExpandOthers
ブール値
いいえ
分割するフィールドの数が SplitKeys パラメーターのフィールド数より大きい場合に、残りの部分を解析するかどうかを指定します。
true: 残りの部分を解析します。
ExpandOthers パラメーターを使用して残りの部分を解析し、ExpandKeyPrefix パラメーターを使用して残りのフィールド名のプレフィックスを指定できます。
false (デフォルト): 残りの部分を解析しません。
ExpandKeyPrefix
String
いいえ
残りのフィールド名のプレフィックス。たとえば、これを expand_ に設定すると、フィールド名は expand_1、expand_2 などになります。
NoKeyError
ブール値
いいえ
生ログにソースフィールドが見つからない場合にエラーを報告するかどうかを指定します。
true: エラーが報告されます。
false (デフォルト): エラーは報告されません。
NoMatchError
ブール値
いいえ
指定された区切り文字がログの区切り文字と一致しない場合にエラーを報告するかどうかを指定します。
true: エラーが報告されます。
false (デフォルト): エラーは報告されません。
KeepSource
ブール値
いいえ
解析されたログにソースフィールドを保持するかどうかを指定します。
true: ソースフィールドを保持します。
false (デフォルト): ソースフィールドを保持しません。
例
区切り文字 |#| を使用して content フィールドの値を抽出し、フィールド名を ip、time、method、url、request_time、request_length、status、expand_1、expand_2、および expand_3 に設定します。以下に構成例を示します。
生ログ
"content" : "10.**.**.**|#|10/Aug/2022:14:57:51 +0800|#|POST|#|PutData? Category=YunOsAccountOpLog&AccessKeyId=<yourAccessKeyId>&Date=Fri%2C%2028%20Jun%202013%2006%3A53%3A30%20GMT&Topic=raw&Signature=<yourSignature>|#|0.024|#|18204|#|200|#|27|#|-|#| aliyun-sdk-java"Logtail プラグイン構成
{ "type" : "processor_split_string", "detail" : {"SourceKey" : "content", "SplitSep" : "|#|", "SplitKeys" : ["ip", "time", "method", "url", "request_time", "request_length", "status"], "PreserveOthers" : true, "ExpandOthers" : true, "ExpandKeyPrefix" : "expand_" } }結果
"ip" : "10.**.**.**" "time" : "10/Aug/2022:14:57:51 +0800" "method" : "POST" "url" : "/PutData?Category=YunOsAccountOpLog&AccessKeyId=<yourAccessKeyId>&Date=Fri%2C%2028%20Jun%202013%2006%3A53%3A30%20GMT&Topic=raw&Signature=<yourSignature>" "request_time" : "0.024" "request_length" : "18204" "status" : "200" "expand_1" : "27" "expand_2" : "-" "expand_3" : "aliyun-sdk-java"
キーと値のペアモード
キーと値のペアを分割してフィールドを抽出します。
processor_split_key_value プラグインは Logtail 0.16.26 以降でサポートされています。
フォームベースの構成
パラメーター
[プロセッサタイプ] を [フィールドの抽出 (キーと値のペアモード)] に設定します。次の表にパラメーターを示します。
パラメーター
説明
ソースフィールド
ソースフィールドの名前。
キーと値のペアの区切り文字
キーと値のペア間の区切り文字。デフォルト値はタブ文字
\tです。キーと値の区切り文字
キーと値のペア内のキーと値の間の区切り文字。デフォルト値はコロン (:) です。
ソースフィールドを保持
このオプションを選択すると、システムはソースフィールドを保持します。
ソースフィールドが見つからない場合にエラーを報告
このオプションを選択すると、ログにソースフィールドが見つからない場合にエラーが報告されます。
区切り文字が一致しない場合はキーと値のペアを破棄
このオプションを選択すると、指定されたキーと値の区切り文字が含まれていない場合、システムはキーと値のペアを破棄します。
キーと値の区切り文字が見つからない場合にエラーを報告
このオプションを選択すると、キーと値のペアに指定されたキーと値の区切り文字が含まれていない場合にエラーが報告されます。
キーが空の場合にエラーを報告
このオプションを選択すると、分割後にキーが空の場合にエラーが報告されます。
引用符文字
値が引用符文字で囲まれている場合、引用符文字内の値が抽出されます。複数の文字を設定できます。
重要引用符で囲まれた値内でバックスラッシュ (\) を使用して引用符文字をエスケープする場合、バックスラッシュ (\) は値の一部として保持されます。
例
例 1: キーと値のペアを分割します。
content フィールドの値をキーと値のペアに分割します。キーと値のペア間の区切り文字はタブ文字
\tで、キーと値のペア内の区切り文字はコロン (:) です。以下に構成例を示します。生ログ
"content": "class:main\tuserid:123456\tmethod:get\tmessage:\"wrong user\""Logtail プラグイン構成
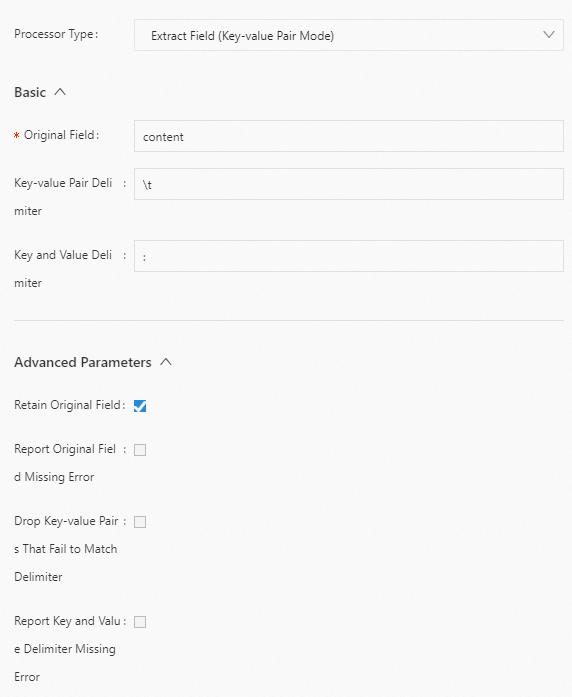
結果
"content": "class:main\tuserid:123456\tmethod:get\tmessage:\"wrong user\"" "class": "main" "userid": "123456" "method": "get" "message": "\"wrong user\""
例 2: 引用符文字を含むキーと値のペアを分割します。
content フィールドの値をキーと値のペアに分割します。キーと値のペア間の区切り文字はタブ文字
\t、キーと値のペア内の区切り文字はコロン (:)、引用符文字は二重引用符 (") です。以下に構成例を示します。生ログ
"content": "class:main http_user_agent:\"User Agent\" \"Chinese\" \"hello\\t\\\"ilogtail\\\"\\tworld\""Logtail プラグイン構成
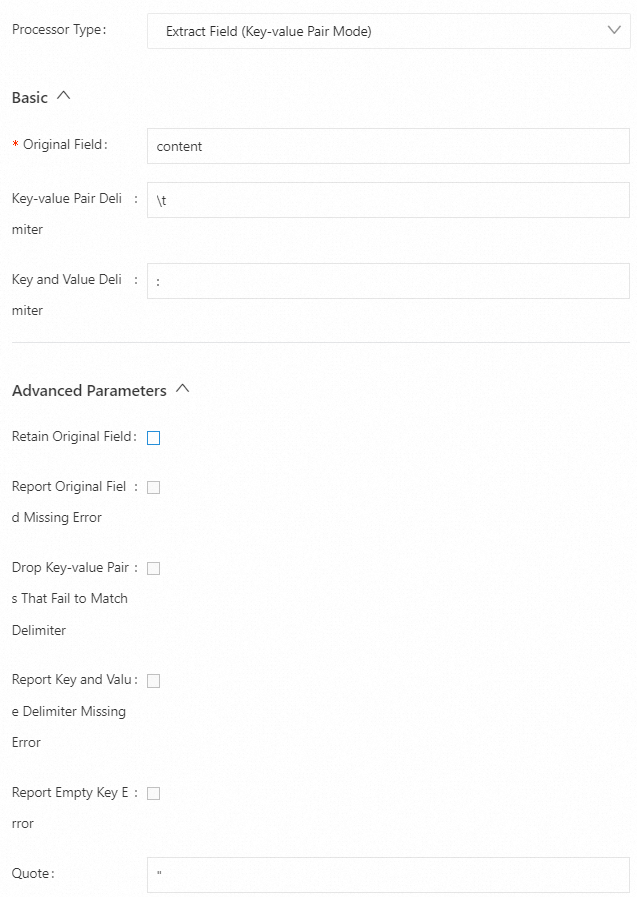
結果
"class": "main", "http_user_agent": "User Agent", "no_separator_key_0": "Chinese", "no_separator_key_1": "hello\t\"ilogtail\"\tworld",
例 3: 複数文字の引用符文字を含むキーと値のペアを分割します。
content フィールドの値をキーと値のペアに分割します。キーと値のペア間の区切り文字はタブ文字
\t、キーと値のペア内の区切り文字はコロン (:)、引用符文字は二重引用符 ("") です。以下に構成例を示します。生ログ
"content": "class:main http_user_agent:\"\"\"User Agent\"\"\" \"\"\"Chinese\"\"\""Logtail プラグイン構成
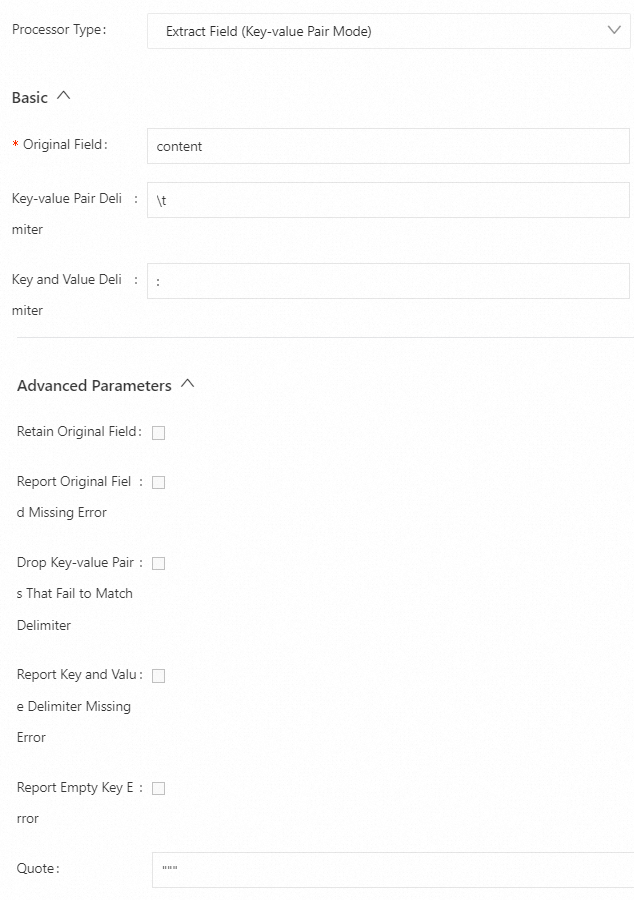
結果
"class": "main", "http_user_agent": "User Agent", "no_separator_key_0": "Chinese",
JSON 構成
パラメーター
type を processor_split_key_value に設定します。次の表に detail のパラメーターを示します。
パラメーター
タイプ
必須
説明
SourceKey
string
はい
ソースフィールドの名前。
Delimiter
string
いいえ
キーと値のペア間の区切り文字。デフォルト値はタブ文字
\tです。Separator
string
いいえ
キーと値のペア内のキーと値の間の区切り文字。デフォルト値はコロン (:) です。
KeepSource
ブール値
いいえ
解析されたログにソースフィールドを保持するかどうかを指定します。
true: ソースフィールドを保持します。
false (デフォルト): ソースフィールドを保持しません。
ErrIfSourceKeyNotFound
ブール値
いいえ
生ログにソースフィールドが見つからない場合にエラーを報告するかどうかを指定します。
true (デフォルト): エラーが報告されます。
false: エラーは報告されません。
DiscardWhenSeparatorNotFound
ブール値
いいえ
一致する区切り文字が見つからない場合にキーと値のペアを破棄するかどうかを指定します。
true: ペアを破棄します。
false (デフォルト): ペアを破棄しません。
ErrIfSeparatorNotFound
ブール値
いいえ
指定された区切り文字が見つからない場合にエラーを報告するかどうかを指定します。
true (デフォルト): エラーが報告されます。
false: エラーは報告されません。
ErrIfKeyIsEmpty
ブール値
いいえ
分割後にキーが空の場合にエラーを報告するかどうかを指定します。
true (デフォルト): エラーが報告されます。
false: エラーは報告されません。
Quote
String
いいえ
引用符文字。これを設定し、値が引用符文字で囲まれている場合、引用符文字内の値が抽出されます。複数の文字を設定できます。デフォルトでは、引用符文字機能は無効になっています。
重要引用符文字が二重引用符 ("") の場合は、エスケープ文字であるバックスラッシュ (\) を追加する必要があります。
引用符文字内でバックスラッシュ (\) を使用して引用符文字をエスケープする場合、バックスラッシュ (\) は値の一部として含まれます。
例
例 1: キーと値のペアを分割します。
content フィールドの値をキーと値のペアに分割します。キーと値のペア間の区切り文字はタブ文字
\tで、キーと値のペア内の区切り文字はコロン (:) です。以下に構成例を示します。生ログ
"content": "class:main\tuserid:123456\tmethod:get\tmessage:\"wrong user\""Logtail プラグイン構成
{ "processors":[ { "type":"processor_split_key_value", "detail": { "SourceKey": "content", "Delimiter": "\t", "Separator": ":", "KeepSource": true } } ] }結果
"content": "class:main\tuserid:123456\tmethod:get\tmessage:\"wrong user\"" "class": "main" "userid": "123456" "method": "get" "message": "\"wrong user\""
例 2: キーと値のペアを分割します。
content フィールドの値をキーと値のペアに分割します。キーと値のペア間の区切り文字はタブ文字
\t、キーと値のペア内の区切り文字はコロン (:)、引用符文字は二重引用符 (") です。以下に構成例を示します。生ログ
"content": "class:main http_user_agent:\"User Agent\" \"Chinese\" \"hello\\t\\\"ilogtail\\\"\\tworld\""Logtail プラグイン構成
{ "processors":[ { "type":"processor_split_key_value", "detail": { "SourceKey": "content", "Delimiter": " ", "Separator": ":", "Quote": "\"" } } ] }結果
"class": "main", "http_user_agent": "User Agent", "no_separator_key_0": "Chinese", "no_separator_key_1": "hello\t\"ilogtail\"\tworld",
例 3: キーと値のペアを分割します。
content フィールドの値をキーと値のペアに分割します。キーと値のペア間の区切り文字はタブ文字
\t、キーと値のペア内の区切り文字はコロン (:)、引用符文字は三重引用符 (""") です。以下に構成例を示します。生ログ
"content": "class:main http_user_agent:\"\"\"User Agent\"\"\" \"\"\"Chinese\"\"\""Logtail プラグイン構成
{ "processors":[ { "type":"processor_split_key_value", "detail": { "SourceKey": "content", "Delimiter": " ", "Separator": ":", "Quote": "\"\"\"" } } ] }結果
"class": "main", "http_user_agent": "User Agent", "no_separator_key_0": "Chinese",
Grok モード
Grok 式を使用してターゲットフィールドを抽出します。
processor_grok プラグインは Logtail 1.2.0 以降でサポートされています。
フォームベースの構成
パラメーター
[プロセッサタイプ] を [フィールドの抽出 (Grok モード)] に設定します。次の表にパラメーターを示します。
パラメーター
説明
ソースフィールド
ソースフィールドの名前。
一致パターン
Grok 式の配列。processor_grok プラグインは、このリストの式に対して上から順にログを照合し、最初に成功した一致の結果を返します。
デフォルトでサポートされている式のリストについては、「processor_grok」をご参照ください。必要な式がリストにない場合は、[カスタム Grok パターン] にカスタム Grok 式を入力します。
説明複数の Grok 式を構成すると、パフォーマンスに影響する可能性があります。5 つ以下の式を使用することをお勧めします。
カスタム Grok パターン
カスタムルール名と Grok 式を入力します。
カスタム Grok パターンファイルのディレクトリ
カスタム Grok パターンファイルが配置されているディレクトリ。processor_grok プラグインは、ディレクトリ内のすべてのファイルを読み取ります。
重要カスタム Grok パターンファイルを更新した後、変更を有効にするには Logtail を再起動する必要があります。
最大一致時間
Grok 式でフィールドを抽出しようとする最大時間 (ミリ秒)。0 に設定するか、空のままにすると、タイムアウトなしを意味します。
解析失敗時にログを保持
このオプションを選択すると、解析に失敗した場合にシステムはログを保持します。
ソースフィールドを保持
このオプションを選択すると、解析されたログにソースフィールドが保持されます。
ソースフィールドが見つからない場合にエラーを報告
このオプションを選択すると、生ログにソースフィールドが見つからない場合にエラーが報告されます。
パターンが一致しない場合にエラーを報告
このオプションを選択すると、[一致パターン] のどの式もログに一致しない場合にエラーが報告されます。
一致タイムアウト時にエラーを報告
このオプションを選択すると、一致がタイムアウトした場合にエラーが報告されます。
例
Grok モードで content フィールドの値を抽出し、抽出されたフィールドに year、month、および day という名前を付けます。以下に構成例を示します。
生ログ
"content" : "2022 October 17"Logtail プラグイン構成
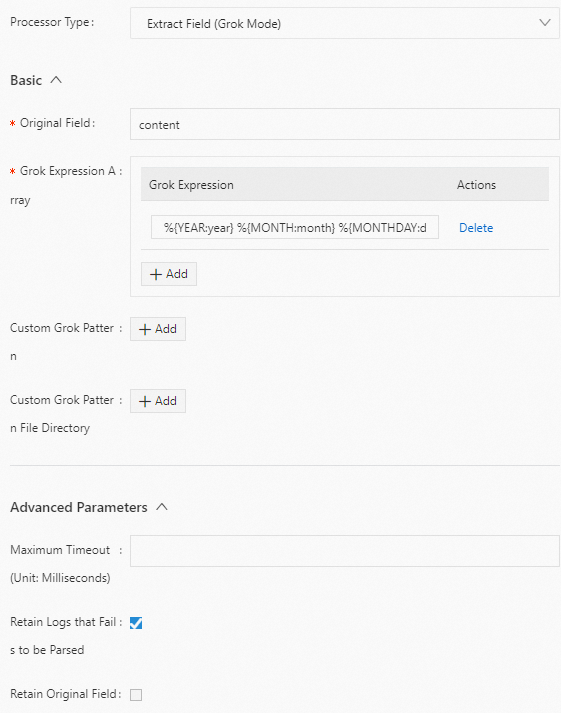
結果
"year":"2022" "month":"October" "day":"17"
JSON 構成
パラメーター
type を processor_grok に設定します。次の表に detail のパラメーターを示します。
パラメーター
タイプ
必須
説明
CustomPatternDir
文字列配列
いいえ
カスタム Grok パターンファイルが配置されているディレクトリ。processor_grok プラグインは、ディレクトリ内のすべてのファイルを読み取ります。
このパラメーターが追加されていない場合、カスタム Grok パターンファイルはインポートされません。
重要カスタム Grok パターンファイルを更新した後、変更を有効にするには Logtail を再起動する必要があります。
CustomPatterns
マップ
いいえ
カスタム GROK パターン。key はルール名で、value は Grok 式です。
デフォルトでサポートされている式のリストについては、「processor_grok」をご参照ください。必要な式がリストにない場合は、Match にカスタム Grok 式を入力します。
このパラメーターが追加されていない場合、カスタム GROK パターンは使用されません。
SourceKey
String
いいえ
ソースフィールドの名前。デフォルト値は content フィールドです。
Match
文字列配列
はい
Grok 式の配列。processor_grok プラグインは、このリストの式に対して上から順にログを照合し、最初に成功した一致の結果を返します。
説明複数の Grok 式を構成すると、パフォーマンスに影響する可能性があります。5 つ以下の式を使用することをお勧めします。
TimeoutMilliSeconds
Long
いいえ
Grok 式でフィールドを抽出しようとする最大時間 (ミリ秒)。
このパラメーターが追加されていないか、0 に設定されている場合、タイムアウトなしを意味します。
IgnoreParseFailure
ブール値
いいえ
解析に失敗したログを無視するかどうかを指定します。
true (デフォルト): ログを無視します。
false: アイテムを削除します。
KeepSource
ブール値
いいえ
解析成功後にソースフィールドを保持するかどうかを指定します。
true (デフォルト): ソースフィールドを保持します。
false: ソースフィールドを破棄します。
NoKeyError
ブール値
いいえ
生ログにソースフィールドが見つからない場合にエラーを報告するかどうかを指定します。
true: エラーが報告されます。
false (デフォルト): エラーは報告されません。
NoMatchError
ブール値
いいえ
Match パラメーターで設定されたどの式もログに一致しない場合にエラーを報告するかどうかを指定します。
true (デフォルト): エラーが報告されます。
false: エラーは報告されません。
TimeoutError
ブール値
いいえ
一致がタイムアウトした場合にエラーを報告するかどうかを指定します。
true (デフォルト): エラーが報告されます。
false: エラーは報告されません。
例 1
Grok モードで content フィールドの値を抽出し、抽出されたフィールドに year、month、および day という名前を付けます。以下に構成例を示します。
生ログ
"content" : "2022 October 17"Logtail プラグイン構成
{ "type" : "processor_grok", "detail" : { "KeepSource" : false, "Match" : [ "%{YEAR:year} %{MONTH:month} %{MONTHDAY:day}" ], "IgnoreParseFailure" : false } }結果
"year":"2022" "month":"October" "day":"17"
例 2
複数のログから content フィールドの値を抽出し、異なる Grok 式に基づいて異なる結果に解析します。以下に構成例を示します。
生ログ
{ "content" : "begin 123.456 end" } { "content" : "2019 June 24 \"I am iron man"\" } { "content" : "WRONG LOG" } { "content" : "10.0.0.0 GET /index.html 15824 0.043" }Logtail プラグイン構成
{ "type" : "processor_grok", "detail" : { "CustomPatterns" : { "HTTP" : "%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}" }, "IgnoreParseFailure" : false, "KeepSource" : false, "Match" : [ "%{HTTP}", "%{WORD:word1} %{NUMBER:request_time} %{WORD:word2}", "%{YEAR:year} %{MONTH:month} %{MONTHDAY:day} %{QUOTEDSTRING:motto}" ], "SourceKey" : "content" }, }結果
最初のログについて、processor_grok プラグインは Match パラメーターの最初の式
%{HTTP}との一致に失敗しますが、2 番目の式%{WORD:word1} %{NUMBER:request_time} %{WORD:word2}とは正常に一致します。したがって、抽出結果は 2 番目の式に基づいています。KeepSource パラメーターが false に設定されているため、生ログの content フィールドは破棄されます。
2 番目のログエントリでは、processor_grok プラグインは [Match] パラメーター内の 1 番目の式
%{HTTP}と 2 番目の式%{WORD:word1} %{NUMBER:request_time} %{WORD:word2}にはエントリが一致しませんが、3 番目の式%{YEAR:year} %{MONTH:month} %{MONTHDAY:day} %{QUOTEDSTRING:motto}には一致します。そのため、プラグインは 3 番目の式に基づいて抽出結果を返します。3 番目のログについて、processor_grok プラグインは Match パラメーターの 3 つの式のいずれとも一致しません。IgnoreParseFailure パラメーターを false に設定したため、3 番目のログは破棄されます。
4 番目のログについて、processor_grok プラグインは Match パラメーターの最初の式
%{HTTP}と正常に一致します。したがって、抽出結果は最初の式に基づいています。
{ "word1":"begin", "request_time":"123.456", "word2":"end", } { "year":"2019", "month":"June", "day":"24", "motto":"\"I am iron man"\", } { "client":"10.0.0.0", "method":"GET", "request":"/index.html", "bytes":"15824", "duration":"0.043", }
フィールド追加プラグイン
processor_add_fields プラグインを使用してログフィールドを追加します。このセクションでは、processor_add_fields プラグインのパラメーターについて説明し、構成例を示します。
構成
processor_add_fields プラグインは Logtail 0.16.28 以降でサポートされています。
フォームベースの構成
パラメーター
[プロセッサタイプ] を [フィールドの追加] に設定します。次の表にパラメーターを示します。
パラメーター
説明
追加するフィールド
追加するフィールドの名前と値。複数のフィールドを追加できます。
重複フィールドを無視
同じ名前のフィールドが既に存在する場合にフィールドを無視するかどうかを指定します。
例
aaa2と aaa3 フィールドを追加します。以下に構成例を示します。生ログ
"aaa1":"value1"Logtail プラグイン構成
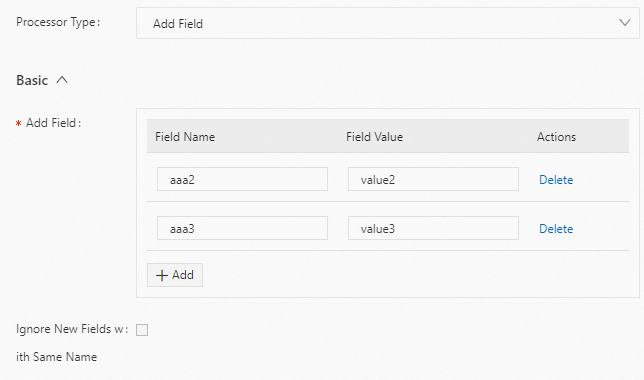
結果
"aaa1":"value1" "aaa2":"value2" "aaa3":"value3"
JSON 構成
パラメーター
typeをprocessor_add_fieldsに設定します。次の表にdetailのパラメーターを示します。パラメーター
タイプ
必須
説明
Fields
マップ
はい
追加するフィールドの名前と値。これはキーと値のペア形式です。複数のフィールドを追加できます。
IgnoreIfExist
ブール値
いいえ
同じ名前のフィールドが既に存在する場合にフィールドを無視するかどうかを指定します。
true: フィールドを無視します。
false (デフォルト): フィールドを無視しません。
構成例
aaa2 と aaa3 フィールドを追加します。以下に構成例を示します。
生ログ
"aaa1":"value1"Logtail プラグイン構成
{ "processors":[ { "type":"processor_add_fields", "detail": { "Fields": { "aaa2": "value2", "aaa3": "value3" } } } ] }結果
"aaa1":"value1" "aaa2":"value2" "aaa3":"value3"
フィールド削除プラグイン
processor_drop プラグインを使用してログフィールドを削除します。このセクションでは、processor_drop プラグインのパラメーターについて説明し、構成例を示します。
構成
processor_drop プラグインは Logtail 0.16.28 以降でサポートされています。
フォームベースの構成
パラメーター
[プロセッサタイプ] を [フィールドの削除] に設定します。次の表にパラメーターを示します。
パラメーター
説明
削除するフィールド
削除するフィールド。複数のフィールドを指定できます。
例
ログから
aaa1とaaa2フィールドを削除します。以下に構成例を示します。生ログ
"aaa1":"value1" "aaa2":"value2" "aaa3":"value3"Logtail プラグイン構成
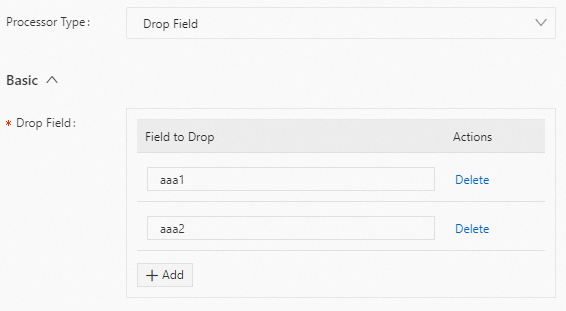
結果
"aaa3":"value3"
JSON 構成
パラメーター
type を processor_drop に設定します。次の表に detail のパラメーターを示します。
パラメーター
タイプ
必須
説明
DropKeys
文字列配列
はい
削除するフィールド。複数のフィールドを指定できます。
例
ログから aaa1 と aaa2 フィールドを削除します。以下に構成例を示します。
生ログ
"aaa1":"value1" "aaa2":"value2" "aaa3":"value3"Logtail プラグイン構成
{ "processors":[ { "type":"processor_drop", "detail": { "DropKeys": ["aaa1","aaa2"] } } ] }結果
"aaa3":"value3"
フィールド名変更プラグイン
processor_rename プラグインを使用してフィールド名を変更できます。このセクションでは、processor_rename プラグインのパラメーターについて説明し、構成例を示します。
構成
processor_rename プラグインは Logtail 0.16.28 以降でサポートされています。
フォームベースの構成
パラメーター設定
[処理プラグインタイプ] を [フィールド名の変更] に設定します。次の表にパラメーターを示します。
パラメーター
説明
ソースフィールド
名前を変更するソースフィールド。
結果フィールド
フィールドの新しい名前。
ソースフィールドが見つからない場合にエラーを報告
このオプションを選択すると、ログにソースフィールドが見つからない場合にエラーが報告されます。
例
aaa1フィールドの名前を bbb1 に、aaa2 フィールドの名前を bbb2 に変更します。以下に構成例を示します。生ログ
"aaa1":"value1" "aaa2":"value2" "aaa3":"value3"Logtail プラグイン構成
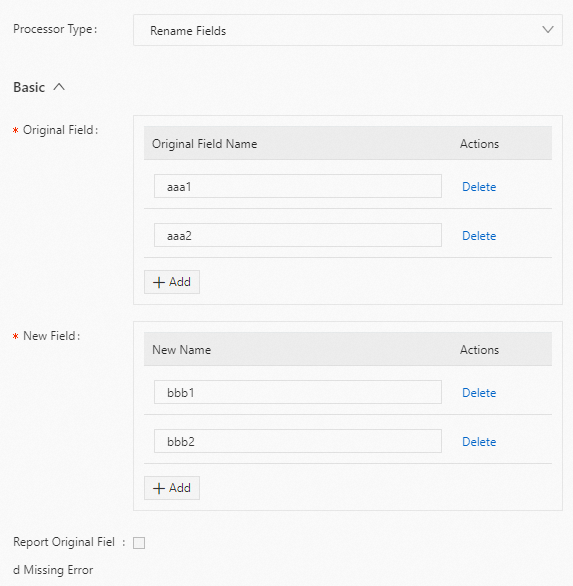
結果
"bbb1":"value1" "bbb2":"value2" "aaa3":"value3"
JSON 構成
パラメーター設定
typeをprocessor_renameに設定します。次の表にdetailオブジェクトのパラメーターを示します。パラメーター
タイプ
必須
説明
NoKeyErrorブール値
いいえ
ログにソースフィールドが見つからない場合にエラーを報告するかどうかを指定します。
true: エラーが報告されます。
false (デフォルト): エラーは報告されません。
SourceKeys文字列配列
はい
名前を変更するソースフィールド。
DestKeys文字列配列
はい
フィールドの新しい名前。
例
aaa1フィールドの名前をbbb1に、aaa2フィールドの名前をbbb2に変更します。以下に構成例を示します。生ログ
"aaa1":"value1" "aaa2":"value2" "aaa3":"value3"Logtail プラグイン構成
{ "processors":[ { "type":"processor_rename", "detail": { "SourceKeys": ["aaa1","aaa2"], "DestKeys": ["bbb1","bbb2"], "NoKeyError": true } } ] }結果
"bbb1":"value1" "bbb2":"value2" "aaa3":"value3"
フィールドパックプラグイン
processor_packjson プラグインを使用して、1 つ以上のフィールドを JSON オブジェクトフィールドにパックできます。このセクションでは、processor_packjson プラグインのパラメーターについて説明し、構成例を示します。
構成
processor_packjson プラグインは Logtail 0.16.28 以降でサポートされています。
フォームベースの構成
パラメーター
[プロセッサタイプ] を [フィールドのパック] に設定します。次の表にパラメーターを示します。
パラメーター
説明
ソースフィールド
パックするソースフィールド。
結果フィールド
パック後のフィールド。
ソースフィールドを保持
このオプションを選択すると、解析されたログにソースフィールドが保持されます。
ソースフィールドが見つからない場合にエラーを報告
このオプションを選択すると、生ログにソースフィールドが見つからない場合にエラーが報告されます。
例
指定された a と b フィールドを d_key という名前の JSON フィールドにパックします。以下に構成例を示します。
生ログ
"a":"1" "b":"2"Logtail プラグイン構成
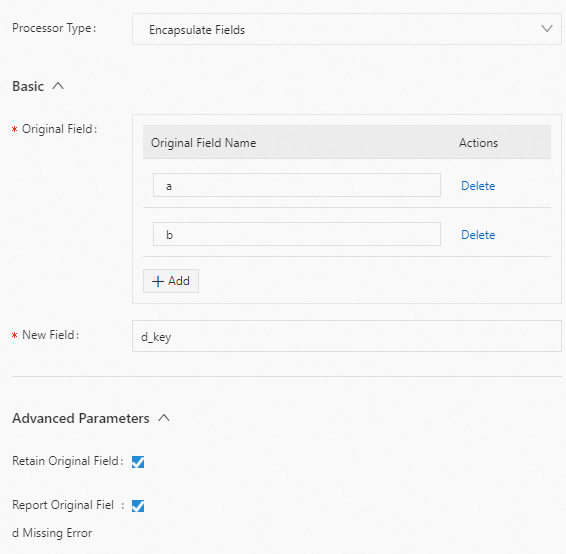
結果
"a":"1" "b":"2" "d_key":"{\"a\":\"1\",\"b\":\"2\"}"
JSON 構成
パラメーター
type を processor_packjson に設定します。次の表に detail のパラメーターを示します。
パラメーター
タイプ
必須
説明
SourceKeys
文字列配列
はい
パックするソースフィールド。
DestKey
String
いいえ
パック後のフィールド。
KeepSource
ブール値
いいえ
解析されたログにソースフィールドを保持するかどうかを指定します。
true (デフォルト): ソースフィールドを保持します。
false: ソースフィールドを保持しません。
AlarmIfIncomplete
ブール値
いいえ
生ログにソースフィールドが見つからない場合にエラーを報告するかどうかを指定します。
true (デフォルト): エラーが報告されます。
false: エラーは報告されません。
構成例
指定された a と b フィールドを d_key という名前の JSON フィールドにパックします。以下に構成例を示します。
生ログ
"a":"1" "b":"2"Logtail プラグイン構成
{ "processors":[ { "type":"processor_packjson", "detail": { "SourceKeys": ["a","b"], "DestKey":"d_key", "KeepSource":true, "AlarmIfEmpty":true } } ] }結果
"a":"1" "b":"2" "d_key":"{\"a\":\"1\",\"b\":\"2\"}"
JSON フィールド展開プラグイン
processor_json プラグインを使用して JSON フィールドを展開します。このセクションでは、processor_json プラグインのパラメーターについて説明し、構成例を示します。
構成
processor_json プラグインは Logtail 0.16.28 以降でサポートされています。
フォームベースの構成
パラメーター
[プロセッサタイプ] を [JSON フィールドの展開] に設定します。次の表にパラメーターを示します。
パラメーター
説明
ソースフィールド
展開するソースフィールドの名前。
JSON 展開深度
JSON 展開の深度。デフォルト値は 0 で、制限がないことを示します。値 1 は現在のレベルを示します。
JSON 展開コネクタ
JSON 展開用のコネクタ。デフォルト値はアンダースコア (_) です。
JSON 展開フィールドプレフィックス
JSON 展開中にフィールド名に追加するプレフィックス。
配列の展開
配列タイプを展開するかどうかを指定します。このパラメーターは Logtail 1.8.0 以降で利用可能です。
ソースフィールドを保持
このオプションを選択すると、解析されたログにソースフィールドが保持されます。
ソースフィールドが見つからない場合にエラーを報告
このオプションを選択すると、生ログにソースフィールドが見つからない場合にエラーが報告されます。
展開されたフィールドのプレフィックスとしてソースフィールド名を使用
このオプションを選択すると、ソースフィールド名がすべての展開された JSON フィールド名のプレフィックスとして使用されます。
解析失敗時に生ログを保持
このオプションを選択すると、解析に失敗した場合に生ログが保持されます。
例
この例では、
s_keyフィールドを展開します。プレフィックスとしてjを使用し、展開されたフィールド名のプレフィックスとしてソースフィールド名s_keyを使用します。以下に構成例を示します。生ログ (Logtail によって読み取られるファイルパス)
{"s_key":"{\"k1\":{\"k2\":{\"k3\":{\"k4\":{\"k51\":\"51\",\"k52\":\"52\"},\"k41\":\"41\"}}}}"}Logtail プラグイン構成

結果

JSON 構成
パラメーター
typeをprocessor_jsonに設定します。次の表にdetailのパラメーターを示します。パラメーター
タイプ
必須
説明
SourceKey
String
はい
展開するソースフィールドの名前。
NoKeyError
ブール値
いいえ
生ログにソースフィールドが見つからない場合にエラーを報告するかどうかを指定します。
true (デフォルト): エラーが報告されます。
false: エラーは報告されません。
ExpandDepth
Int
いいえ
JSON 展開の深度。デフォルト値は 0 で、制限がないことを意味します。値 1 は現在のレベルを示し、以下同様です。
ExpandConnector
String
いいえ
JSON 展開用のコネクタ。デフォルト値はアンダースコア (_) です。
Prefix
String
いいえ
JSON 展開中にフィールド名に追加するプレフィックス。
KeepSource
ブール値
いいえ
解析されたログにソースフィールドを保持するかどうかを指定します。
true (デフォルト): ソースフィールドを保持します。
false: ソースフィールドを保持しません。
UseSourceKeyAsPrefix
ブール値
いいえ
ソースフィールド名をすべての展開された JSON フィールド名のプレフィックスとして使用するかどうかを指定します。
KeepSourceIfParseError
ブール値
いいえ
解析に失敗した場合に生ログを保持するかどうかを指定します。
true (デフォルト): 生ログを保持します。
false: 生ログを保持しません。
ExpandArray
ブール値
いいえ
配列タイプを展開するかどうかを指定します。このパラメーターは Logtail 1.8.0 以降でサポートされています。
false (デフォルト): 配列を展開しません。
true: 配列を展開します。たとえば、
{"k":["1","2"]}は{"k[0]":"1","k[1]":"2"}に展開されます。
例
この例では、
s_keyフィールドを展開します。プレフィックスとしてjを使用し、展開されたフィールド名のプレフィックスとしてソースフィールド名s_keyを使用します。以下に構成例を示します。生ログ (Logtail によって読み取られるファイルパス)
{"s_key":"{\"k1\":{\"k2\":{\"k3\":{\"k4\":{\"k51\":\"51\",\"k52\":\"52\"},\"k41\":\"41\"}}}}"}Logtail プラグイン構成
{ "processors":[ { "type":"processor_json", "detail": { "SourceKey": "content", "NoKeyError":true, "ExpandDepth":0, "ExpandConnector":"-", "Prefix":"j", "KeepSource": false, "UseSourceKeyAsPrefix": true } } ] }結果
フィールド値マッピングプラグイン
processor_dict_map プラグインはフィールド値をマッピングします。このセクションでは、そのパラメーターについて説明し、構成例を示します。
構成
フォーム構成
[プロセッサタイプ] を [フィールド値マッピング] に設定します。次の表にパラメーターを示します。
パラメーター | 説明 |
ソースフィールド | ソースフィールド名。 |
結果フィールド | マッピングされたフィールドの名前。 |
マッピング辞書 | キーを値にマッピングする辞書。 このパラメーターを使用して、小さなマッピング辞書を直接構成します。これにより、ローカルの CSV 辞書ファイルが不要になります。 重要 [ローカル辞書] を設定した場合、[マッピング辞書] の構成は有効になりません。 |
ローカル辞書 | CSV 形式の辞書ファイル。このファイルは、区切り文字としてカンマ (,) を使用し、フィールド参照を囲むために二重引用符 (") を使用します。 |
詳細パラメーター>ソースフィールドが見つからない場合の処理 | このオプションを選択すると、生ログにソースフィールドがない場合のケースを処理します。システムは、[結果フィールドのパディング値] で指定された値で結果フィールドを埋めます。 |
詳細パラメーター>最大マッピング辞書サイズ | マッピング辞書の最大サイズ。デフォルト値は 1000 で、最大 1000 個のマッピングルールを保存できることを意味します。 サーバー上のプラグインのメモリ使用量を制限するには、この値を小さくします。 |
詳細パラメーター>生ログ処理メソッド | マッピングされたフィールドが生ログに既に存在する場合の処理方法を指定します。
|
JSON 構成
type を processor_dict_map に設定します。次の表に detail のパラメーターを示します。
パラメーター | タイプ | 必須 | 説明 |
SourceKey | String | はい | ソースフィールド名。 |
MapDict | マップ | いいえ | マッピング辞書。 このパラメーターを使用して、小さなマッピング辞書を直接構成します。これにより、ローカルの CSV 辞書ファイルが不要になります。 重要 MapDict パラメーターは、DictFilePath パラメーターを設定した場合は効果がありません。 |
DictFilePath | 文字列 | いいえ | CSV フォーマットの辞書ファイルです。このファイルは、区切り文字としてカンマ (,) を使用し、フィールド参照を囲むために二重引用符 (") を使用します。 |
DestKey | String | いいえ | マップされたフィールドの名前。 |
HandleMissing | ブール値 | いいえ | ターゲットフィールドが存在しない場合に、生のログを処理するかどうかを指定します。
|
欠落 | 文字列 | いいえ | raw ログにソースフィールドが存在しない場合、結果フィールドに使用する値です。デフォルト値は このパラメーターは、HandleMissing を true に設定した場合にのみ有効になります。 |
MaxDictSize | 整数 | いいえ | マッピング辞書の最大サイズ。デフォルト値は 1000 で、最大 1000 個のマッピングルールを格納できます。 サーバー上のプラグインのメモリ使用量を制限するには、この値を小さくします。 |
モード | 文字列 | いいえ | マップされたフィールドが生ログに既に存在する場合の処理方法を指定します。
|
文字列の置換
processor_string_replace プラグインを使用して、ログの全文を置換したり、正規表現に基づいてテキストを置換したり、エスケープ文字を削除したりします。
構成の説明
processor_string_replace プラグインは Logtail 1.6.0 以降でサポートされています。
フォームを使用した構成
[プロセッサータイプ] を [文字列の置換] に設定します。次の表にパラメーターを示します。
パラメーター | 説明 |
ソースフィールド | ソースフィールドの名前。 |
一致メソッド | 一致メソッドを指定します。有効な値:
|
コンテンツの一致 | 一致させるコンテンツを入力します。
|
置換 | 置換に使用する文字列。
|
結果フィールド | 置換されたコンテンツの新しいフィールドを指定します。 |
JSON を使用した構成
type パラメーターを processor_string_replace に設定します。次の表に detail オブジェクトのパラメーターを示します。
パラメーター | タイプ | 必須 | 説明 |
| 文字列 | はい | ソースフィールドの名前。 |
| 文字列 | はい | 一致メソッドを指定します。有効な値:
|
| 文字列 | いいえ | 一致させるコンテンツを入力します。
|
| 文字列 | いいえ | 置換に使用する文字列。デフォルト値は "" です。
|
| 文字列 | いいえ | 置換されたコンテンツの新しいフィールドを指定します。このパラメーターを指定しない場合、新しいフィールドは作成されません。 |
構成例
文字列一致を使用したコンテンツの置換
文字列一致を使用して、Error: フィールドの content を空の文字列に置換します。
フォームを使用した構成
元のログ:
"content": "2023-05-20 10:01:23 Error: Unable to connect to database."Logtail プラグイン構成:

結果:
"content": "2023-05-20 10:01:23 Unable to connect to database."
JSON を使用した構成
元のログ:
"content": "2023-05-20 10:01:23 Error: Unable to connect to database."Logtail プラグイン構成:
{ "processors":[ { "type":"processor_string_replace", "detail": { "SourceKey": "content", "Method": "const", "Match": "Error: ", "ReplaceString": "" } } ] }結果:
"content": "2023-05-20 10:01:23 Unable to connect to database.",
正規表現を使用したコンテンツの置換
正規表現を使用して、content フィールド内の正規表現 \\u\w+\[\d{1,3};*\d{1,3}m|N/A に一致する文字列を空の文字列に置換します。
フォームを使用した構成
元のログ:
"content": "2022-09-16 09:03:31.013 \u001b[32mINFO \u001b[0;39m \u001b[34m[TID: N/A]\u001b[0;39m [\u001b[35mThread-30\u001b[0;39m] \u001b[36mc.s.govern.polygonsync.job.BlockTask\u001b[0;39m : Block collection------end------\r"Logtail プラグイン構成:

結果:
"content": "2022-09-16 09:03:31.013 INFO [TID: ] [Thread-30] c.s.govern.polygonsync.job.BlockTask : Block collection------end------\r",
JSON を使用した構成
元のログ:
"content": "2022-09-16 09:03:31.013 \u001b[32mINFO \u001b[0;39m \u001b[34m[TID: N/A]\u001b[0;39m [\u001b[35mThread-30\u001b[0;39m] \u001b[36mc.s.govern.polygonsync.job.BlockTask\u001b[0;39m : Block collection------end------\r"Logtail プラグイン構成:
{ "processors":[ { "type":"processor_string_replace", "detail": { "SourceKey": "content", "Method": "regex", "Match": "\\\\u\\w+\\[\\d{1,3};*\\d{1,3}m|N/A", "ReplaceString": "" } } ] }結果:
"content": "2022-09-16 09:03:31.013 INFO [TID: ] [Thread-30] c.s.govern.polygonsync.job.BlockTask : Block collection------end------\r",
正規表現グループを使用したコンテンツの置換
正規表現グループを使用して、content フィールドの 16 を */24 に置換し、結果を new_ip という名前の新しいフィールドに書き込みます。
正規表現グループを使用してコンテンツを置換する場合、置換文字列に {} を含めることはできません。$1 や $2 などのフォーマットのみ使用できます。
フォームを使用した構成
元のログ:
"content": "10.10.239.16"Logtail プラグイン構成:

結果:
"content": "10.10.239.16", "new_ip": "10.10.239.*/24",
JSON を使用した構成
元のログ:
"content": "10.10.239.16"Logtail プラグイン構成:
{ "processors":[ { "type":"processor_string_replace", "detail": { "SourceKey": "content", "Method": "regex", "Match": "(\\d.*\\.)\\d+", "ReplaceString": "$1*/24", "DestKey": "new_ip" } } ] }結果:
"content": "10.10.239.16", "new_ip": "10.10.239.*/24",
エスケープ文字の削除
フォームを使用した構成
元のログ:
"content": "{\\x22UNAME\\x22:\\x22\\x22,\\x22GID\\x22:\\x22\\x22,\\x22PAID\\x22:\\x22\\x22,\\x22UUID\\x22:\\x22\\x22,\\x22STARTTIME\\x22:\\x22\\x22,\\x22ENDTIME\\x22:\\x22\\x22,\\x22UID\\x22:\\x222154212790\\x22,\\x22page_num\\x22:1,\\x22page_size\\x22:10}"Logtail プラグイン構成:

結果:
"content": "{\"UNAME\":\"\",\"GID\":\"\",\"PAID\":\"\",\"UUID\":\"\",\"STARTTIME\":\"\",\"ENDTIME\":\"\",\"UID\":\"2154212790\",\"page_num\":1,\"page_size\":10}",
JSON を使用した構成
元のログ:
"content": "{\\x22UNAME\\x22:\\x22\\x22,\\x22GID\\x22:\\x22\\x22,\\x22PAID\\x22:\\x22\\x22,\\x22UUID\\x22:\\x22\\x22,\\x22STARTTIME\\x22:\\x22\\x22,\\x22ENDTIME\\x22:\\x22\\x22,\\x22UID\\x22:\\x222154212790\\x22,\\x22page_num\\x22:1,\\x22page_size\\x22:10}"Logtail プラグイン構成:
{ "processors":[ { "type":"processor_string_replace", "detail": { "SourceKey": "content", "Method": "unquote" } } ] }結果:
"content": "{\"UNAME\":\"\",\"GID\":\"\",\"PAID\":\"\",\"UUID\":\"\",\"STARTTIME\":\"\",\"ENDTIME\":\"\",\"UID\":\"2154212790\",\"page_num\":1,\"page_size\":10}",
関連資料
API 操作を使用した Logtail パイプラインの設定:
コンソールでの処理プラグインの設定: