クラウドサービスの主な利点の1つは、従量課金の方法です。 この課金方法を使用する場合、リソースは予約されません。 クラウドサービスには、課金要件があります。 このトピックでは、Simple Log Serviceに基づいて開発され、さまざまなクラウドサービスで使用される計測および課金ソリューションについて説明します。 このソリューションを使用して、1日あたり数千億の計測ログを処理できます。
計測ログに基づく課金の典型的なシナリオ
電力会社は、10秒間隔でログを受信する。 ログには、10 秒以内の各ユーザー ID の消費電力、ピーク消費電力、および平均消費電力が記録されます。 次に、会社は1時間ごと、1日ごと、または1か月ごとにユーザーの請求書を作成します。
キャリアは、10秒の間隔で基地局からログを受信する。 ログは、10秒以内に携帯電話番号によって使用されたサービスを記録します。 サービスには、インターネットアクセス、音声通話、テキストメッセージ、およびVoIP (voice over Internet Protocol) 通話が含まれます。 ログには、各サービスのトラフィックと期間も記録されます。 バックエンド課金プログラムは、期間中に発生する料金を計算します。
天気予報APIサービスは、APIタイプ、都市、クエリタイプ、クエリ結果のサイズなど、さまざまな要因に基づいてユーザーのリクエストに課金します。
要件と課題
計量および請求ソリューションは、次の基本要件を満たす必要があります。
精度と信頼性: 計算結果は正確でなければなりません。
柔軟性: データを補足することができます。 たとえば、一部のデータが時間内にプッシュされない場合、データが補足された後に料金を再度計算できます。
適時性: サービスは数秒で請求することができます。 アカウントに料金滞納がある場合は、サービスを直ちに停止できます。
追加要件:
請求書の修正: リアルタイムの請求が失敗した場合、課金ログに基づいて請求書を生成できます。
詳細クエリ: 消費の詳細を表示できます。
2つの大きな課題:
データサイズの増加: ユーザーと通話の数が増え続けるにつれて、データサイズは増加し続けます。 課題は、アーキテクチャの自動スケーリングを維持することです。
フォールトトレランス: 請求プログラムにバグがある可能性があります。 課題は、課金プログラムから独立した計測データを維持することである。
このトピックで説明する計量および請求ソリューションは、Simple Log Serviceに基づいてAlibaba Cloudによって開発されています。 このソリューションは、エラーやレイテンシの問題なしに何年も安定して動作しています。
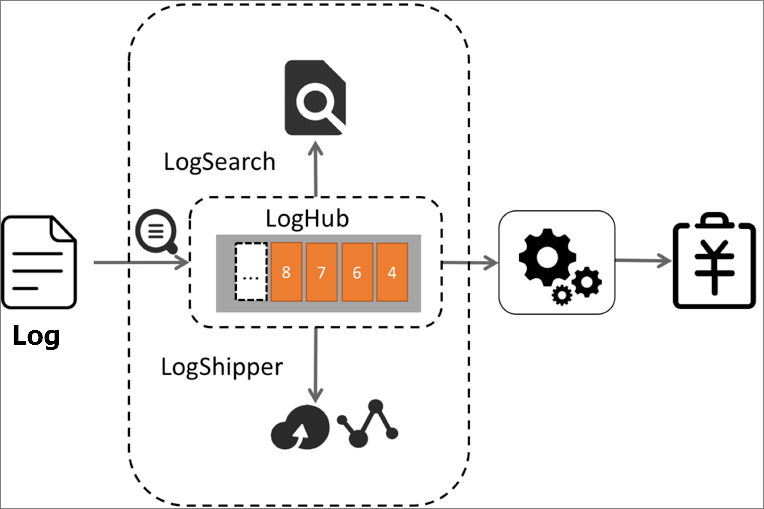
システムアーキテクチャ
次のリストは、計測および課金ソリューションでSimple Log ServiceのLogHubがどのように機能するかを示しています。
計測ログをリアルタイムで収集し、計測ログを計測プログラムに書き込みます。 LogHubは、計測ログの収集と書き込みに50を超えるメソッドをサポートしています。
メータリングプログラムが定期的に増分に基づいてLogHubデータを消費できるようにします。 次に、計測プログラムは、メモリ内のデータを計算して課金データを生成することができる。
(オプション) 詳細クエリをサポートするためにログを計測するインデックスを作成します。
(オプション) 計測ログをObject Storage Service (OSS) に出荷オフラインストレージ用。 このようにして、アカウントを確認し、T + 1ベースで統計を収集できます。
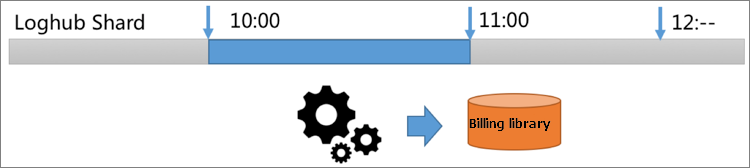
以下のリストは、計測プログラムの内部ロジックを示しています。
GetCursor操作を呼び出して、LogHubから10:00〜11:00などの指定された期間内のログのカーソルを取得します。
PullLogs操作を呼び出して、指定された期間のデータを消費します。
統計を収集し、メモリ内のデータを計算し、課金データを生成します。
ビジネス要件を満たす期間を指定できます。 たとえば、1分または10秒の時間を指定できます。
次のリストは、計測および課金ソリューションのパフォーマンスを分析しています。
分析は次の条件に基づいています。1日あたり10億個のメータリングログが生成され、各ログのサイズは200バイト、1日あたりの合計データサイズは200 GBです。
デフォルトでは、SDKまたはエージェントは少なくとも5:1の圧縮率でデータ圧縮をサポートしています。 この場合、1日あたり40 GBの計測ログを保存し、1時間あたり1.6 GBの計測ログを保存する必要があります。
LogHubは、一度に最大1,000パケットを読み取ります。 パケットの最大サイズは5 MBです。 1ギガビットネットワークでは、1.6 GBの計量ログを2秒以内に読み取ることができます。
1時間以内に生成された1.6 GBの計測ログは、5秒以内に課金データを生成するために消費されます。 これには、統計を収集し、メモリ内のデータを計算するために使用される時間が含まれます。
メータリングログに基づいて生成された請求書
メータリングログは請求可能なアイテムを記録します。 バックエンド課金プログラムは、特定のルールに基づいて課金可能アイテムを計算し、課金データを生成します。 たとえば、次の生アクセスログはプロジェクトの使用状況を記録します。
microtime:1457517269818107 Method:PostLogStoreLogs Status:200 Source:203.0.113.10 ClientIP:198.51.100.10 Latency:1968 InFlow:1409 NetFlow:474 OutFlow:0 UserId:44 AliUid:1264425845****** ProjectName:app-myapplication ProjectId:573 LogStore:perf UserAgent:ali-sls-logtail APIVersion:0.5.0 RequestId:56DFF2D58B3D939D691323C7計測プログラムは、生ログを読み取り、特定のルールに基づいて様々なディメンションから使用データを生成する。 次の図は、インバウンドトラフィック、データの使用回数、アウトバウンドトラフィックを含む、生成された使用状況データを示しています。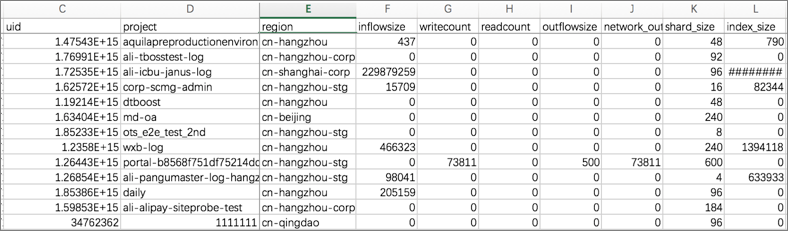
データサイズが大きいシナリオへの解決策
キャリアやIoTの課金など、一部の課金シナリオでは、多数の計測ログが生成されます。 たとえば、1日あたり10兆個のログが生成され、合計データサイズは1日あたり2 PBです。 圧縮後、1時間以内に生成されるデータのサイズは16テラバイトです。 10 GEネットワークでは、1時間以内に生成されたすべてのデータを読み取るのに1,600秒かかります。 このパフォーマンスは、このシナリオの課金要件には適していません。
生成されるメータリングデータのサイズを制限する
計測ログを生成するNGINXなどのプログラムを変更します。 プログラムは、最初にメモリ内のメータリングログを集約し、集約されたメータリングログを毎分ダンプします。 このようにして、ユーザの総数は、データサイズと関連付けられる。 たとえば、NGINXは1,000のユーザーにサービスを提供します。 1時間以内に生成される計測ログのサイズは、次の式を使用して計算されます。1000 × 200 × 60 = 12 GB。 メータリングデータが圧縮された後、データサイズはわずか240 MBになります。
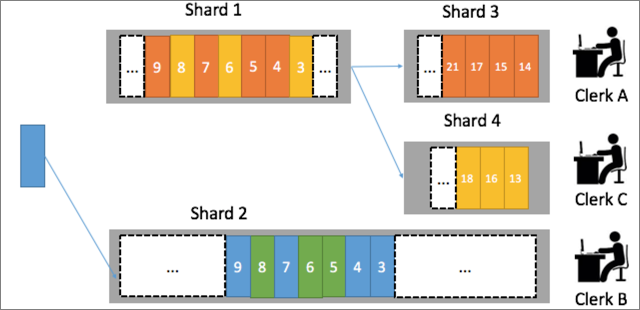
計測ログ処理の並列化
LogHubでは、各Logstoreに複数のシャードを含めることができます。 たとえば、Logstoreには3つのシャードが含まれ、3つのメータリングプログラムが割り当てられます。 ユーザーのメータリングデータが常に同じメータリングプログラムで処理されるようにするには、ハッシュ関数を使用してユーザーIDでユーザーをシャードにマッピングします。 たとえば、杭州のXihu地区のユーザーのメータリングデータはShard1に書き込まれ、杭州のShangcheng地区のユーザーのメータリングデータはShard2に書き込まれます。 この場合、バックエンド計測プログラムは、計測データを2つのシャードで並列に処理することができる。
よくある質問
データを補足するにはどうすればよいですか。
LogHub では、各ログストアのライフサイクルを 1 ~ 365 日の範囲で設定することができます。 請求プログラムがデータを再度消費する必要がある場合、請求プログラムはLogstoreのライフサイクル内の期間ごとにデータを計算できます。
計測ログが複数のサーバーに分散している場合はどうすればよいですか?
Logtailを使用して、各サーバーからリアルタイムでログを収集します。
サーバーのカスタムIDを使用して、自動スケーリング用の動的マシングループを定義します。
消費の詳細をクエリするにはどうすればよいですか?
LogHub データのインデックスを作成して、リアルタイムのクエリと統計分析をサポートすることができます。 次の文は、検索文の例です。
Inflow>300000 and Method=Post* and Status in [200 300]検索文の後に分析文を追加することもできます。
Inflow>300000 and Method=Post* and Status in [200 300] | select max(Inflow) as s, ProjectName group by ProjectName order by s descT + 1 ベースでログを保存してアカウントを確認するにはどうすればよいですか。
Simple Log Serviceは、LogHubデータを他のシステムに送信できます。 パーティションとストレージ形式をカスタマイズして、OSSにログを保存できます. 次に、E-MapReduceを使用し、 Hadoop、Hive、Presto、またはSparkを使用してログデータを計算します。