Simple Log Service でログを収集した後、ログのキーワードに基づいてアラートを作成できます。
背景情報
ログは、システムの操作プロセスと例外を記録します。例としては、警告ログ、エラーログ、Go のパニックエラー、Java の java.lang.StackOverflowError エラー、支払い失敗などのイベントのシステムステータスログなどがあります。ログのキーワードを取得し、アラートを監視することは、一般的なシステム操作です。ログからキーワードを取得してアラートを設定することで、問題を迅速に検出して特定できます。Simple Log Service は、メンテナンスフリーでパフォーマンス専有型、かつ柔軟なアラートソリューションを提供し、ログのキーワードに基づいたアラートの作成を支援します。
シナリオ 1: キーワードが出現したときにアラートをトリガーする
このシナリオでは、特定のキーワードがログに表示されたときにアラートをトリガーするための検索文とアラートルールの設定方法について説明します。
検索文
時間範囲を [15 Minutes (Relative)] に設定します。次に、次の文を実行して、`ERROR` キーワードを含むログをクエリします。詳細については、「ログクエリと分析のクイックスタート」をご参照ください。
ERRORクエリ結果
クエリ結果は、過去 15 分間に `ERROR` キーワードが 1 回出現したことを示しています。

アラートルールの構成
クエリ結果に基づいてアラートルールを作成します。詳細については、「アラートルールの作成」をご参照ください。主要な設定項目は次のとおりです。
[トリガー条件] を [データが存在する] に設定します。ログに `ERROR` キーワードが出現すると、アラートがトリガーされます。
[アノテーション] セクションで、[説明] を [${logging}] に、[コンテンツテンプレート] を [SLS 組み込みコンテンツテンプレート] に設定します。これにより、アラート通知には、元のログの logging フィールドの内容が含まれるようになります。

アラート通知
アラートルールを作成すると、ログに `ERROR` キーワードが出現するたびに、DingTalk グループでアラート通知を受け取ります。[詳細] をクリックして、アラートをトリガーしたログを表示し、ソースを追跡することもできます。
シナリオ 2: キーワードの出現回数に基づいてアラートを設定する
このシナリオでは、キーワードが時間範囲内で特定の回数出現した場合にのみアラートをトリガーするように、検索および分析文とアラートルールを設定する方法について説明します。
検索および分析文
時間範囲を [1 Hour (Relative)] に設定します。次に、次の文を実行して、1 時間以内に `ERROR` キーワードが出現した回数をカウントします。詳細については、「ログクエリと分析のクイックスタート」をご参照ください。
ERROR | SELECT count(*) AS cntクエリ分析結果
クエリと分析の結果、過去 1 時間に `ERROR` キーワードが 11 回出現したことがわかります。

アラートルールの構成
クエリと分析の結果に基づいてアラートルールを作成します。詳細については、「アラートルールの作成」をご参照ください。主要な設定項目は次のとおりです。
[トリガー条件] を [データが式に一致, Cnt > 5] に設定します。`ERROR` キーワードが 1 時間に 5 回を超えて出現した場合にアラートがトリガーされます。
[アノテーション] セクションで、[説明] を [過去 1 時間に ERROR キーワードが ${cnt} 回出現しました] に、[コンテンツテンプレート] を [SLS 組み込みコンテンツテンプレート] に設定します。これにより、アラート通知には、過去 1 時間に `ERROR` キーワードが出現した回数が表示されます。

アラート通知
アラートルールを作成すると、過去 1 時間に `ERROR` キーワードが 5 回を超えて出現するたびに、DingTalk グループでアラート通知を受け取ります。[詳細] をクリックして、アラートをトリガーしたログを表示し、ソースを追跡することもできます。
シナリオ 3: 前日とのキーワード出現回数を比較してアラートを設定する
キーワードは、夜間よりも日中に多く出現するなど、周期的に出現することがあります。このような場合、出現回数などの絶対値を使用してシステムが異常かどうかを判断するのは適切ではありません。比較関数を使用して、異なる日の同じ期間におけるキーワードの出現率を計算し、この比率に基づいてアラートを設定できます。
検索および分析文
時間範囲を [1 Hour (Relative)] に設定します。次に、次の文を実行して、過去 1 時間と昨日の同じ期間の `ERROR` キーワードの出現率を計算します。詳細については、「ログクエリと分析のクイックスタート」をご参照ください。`compare` 関数の詳細については、「比較関数」をご参照ください。
ERROR | SELECT diff [1] AS today, diff [2] AS yesterday, round((diff [3]-1) * 100, 2) AS ratio FROM ( SELECT compare(cnt, 86400) AS diff FROM ( SELECT COUNT(*) AS cnt FROM log ) )クエリと分析の結果
クエリと分析の結果、`ERROR` キーワードが過去 1 時間に 11 回、昨日の同じ期間に 6 回出現したことがわかります。増加率は 83.33% です。

アラートルールの構成
クエリと分析の結果に基づいてアラートルールを作成します。詳細については、「アラートルールの作成」をご参照ください。主要な設定項目は次のとおりです。
[トリガー条件] を [データが式に一致, Ratio > 10] に設定します。過去 1 時間と昨日の同じ期間の `ERROR` キーワードの出現率が 10% を超えると、アラートがトリガーされます。
[アノテーション] セクションで、[説明] を [過去 1 時間のエラー: ${today}。昨日の同期間: ${yesterday}。増加率: ${ratio}%] に、[コンテンツテンプレート] を [SLS 組み込みコンテンツテンプレート] に設定します。これにより、アラート通知には、過去 1 時間の `ERROR` キーワードの出現回数、昨日の同じ期間のカウント、および変化率が表示されます。

アラート通知
アラートルールを作成すると、過去 1 時間と昨日の同じ期間の `ERROR` キーワードの出現率が 10% を超えるたびに、DingTalk グループでアラート通知を受け取ります。[詳細] をクリックして、アラートをトリガーしたログを表示し、ソースを追跡することもできます。
シナリオ 4: 機械学習アルゴリズムを使用した異常検知アラート
前のシナリオでは、基本的なキーワードアラートについて説明しました。ただし、一部の特殊なシナリオでは、Simple Log Service の機械学習アルゴリズムを使用する必要があります。たとえば、キーワードの出現頻度が一日を通して安定しているにもかかわらず、ある瞬間に突然急増または急減する場合があります。この変化を迅速に検出したい場合は、Simple Log Service の機械学習アルゴリズムを使用して時系列予測と異常検知を行うことができます。機械学習アルゴリズムの詳細については、「機械学習関数」をご参照ください。
検索および分析文
時間範囲を [4 Hours (Relative)] に設定します。次に、次の文を実行して、過去 4 時間以内の `ERROR` の出現における異常の数をカウントします。詳細については、「ログクエリと分析のクイックスタート」をご参照ください。`ts_predicate_simple` 関数の詳細については、「ts_predicate_simple」をご参照ください。
ERROR | SELECT ts_predicate_simple(stamp, value, 6) FROM ( select __time__-__time__ % 30 AS stamp, count(1) AS value FROM log GROUP BY stamp ORDER BY stamp )クエリと分析の結果
クエリと分析の結果、返された列に `src`、`predict`、`upper`、`lower`、および `anomaly_prob` が含まれていることがわかります。`anomaly_prob` の値が 0 より大きい場合は異常を示します。`anomaly_prob` の値が 0 より大きいデータエントリの数は、異常点の数を表します。したがって、この数に基づいてアラートを設定できます。
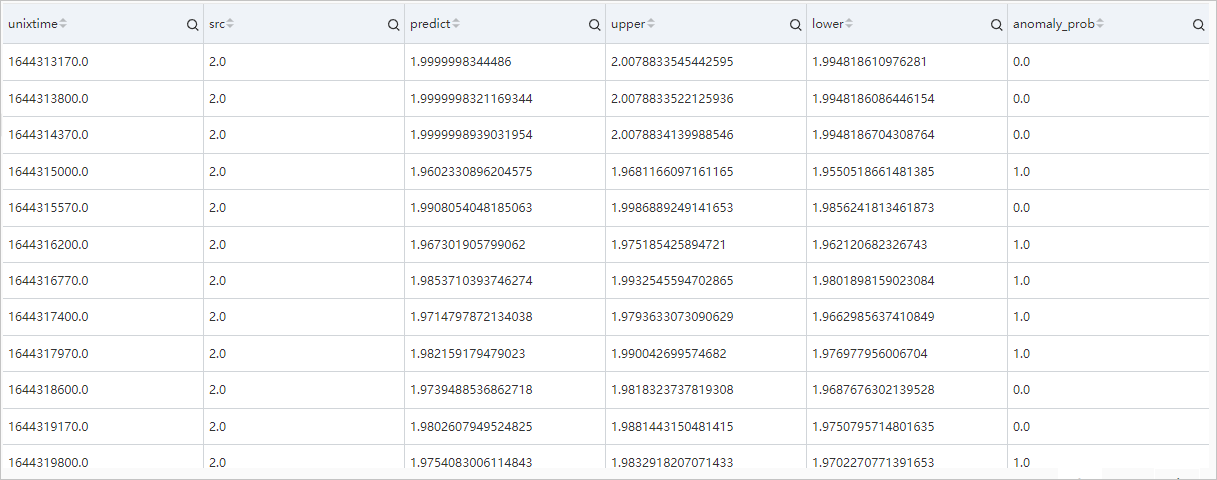
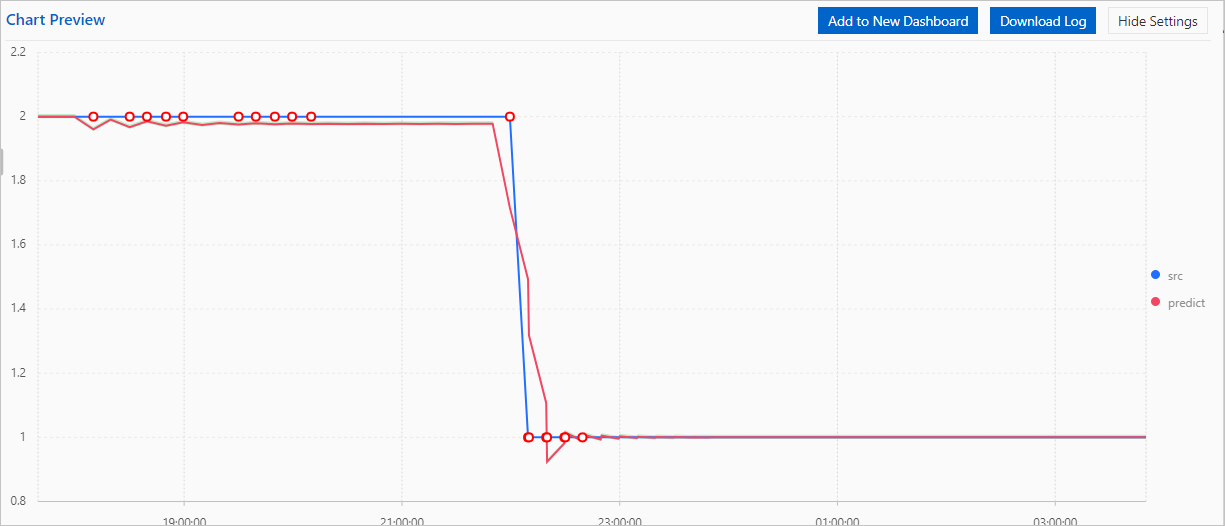
クエリと分析の結果を時系列グラフとして表示することもでき、データのドロップをより直感的に視覚化できます。時系列グラフの小さな赤い丸は異常点を表します。グラフは、現在の期間に 15 個の異常点が発生したことを示しています。
アラートルールの構成
クエリと分析の結果に基づいてアラートルールを作成します。詳細については、「アラートルールの作成」をご参照ください。主要な設定項目は次のとおりです。
[トリガー条件] を [特定数のデータが一致, >, 5, Anomaly_prob > 0] に設定します。過去 4 時間の異常数が 5 を超えると、アラートがトリガーされます。
[アノテーション] セクションで、[説明] を [過去 4 時間に 5 件を超える ERROR の異常] に、[コンテンツテンプレート] を [SLS 組み込みコンテンツテンプレート] に設定します。これにより、アラート通知には、過去 4 時間に発生した異常点の数が表示されます。

アラート通知
アラートルールを作成すると、過去 4 時間の異常数が 5 を超えるたびに、DingTalk グループでアラート通知を受け取ります。[詳細] をクリックして、アラートをトリガーしたログを表示し、ソースを追跡することもできます。