このトピックでは、Classic Load Balancer(CLB)のヘルスチェックに関するよくある質問への回答を提供します。
ヘルスチェックはどのように機能しますか?
ヘルスチェックを実行するには、バックエンドサーバーに定期的にリクエストを送信して、サーバーのステータスを確認します。
CLB インスタンスはクラスターにデプロイされます。クラスター内のノードは、ネットワークトラフィックの転送とヘルスチェックの実行を担当します。このようなクラスター内のノードによって実行されたヘルスチェックにバックエンドサーバーが失敗した場合、クラスター内のすべてのノードは、異常なバックエンドサーバーへのリクエストの配信を停止します。
CLB ヘルスチェックは CIDR ブロック 100.64.0.0/10 を使用します。これはバックエンドサーバーによってブロックすることはできません。 iptables などのセキュリティルールが設定されていない限り、CIDR ブロック 100.64.0.0/10 からのアクセスを許可するセキュリティグループルールを設定する必要はありません。 CIDR ブロックは Alibaba Cloud によって予約されているため、100.64.0.0/10 を許可しても潜在的なリスクは増加しません。 CIDR ブロック内の IP アドレスはユーザーに割り当てられません。
詳細については、「CLB ヘルスチェック」をご参照ください。
推奨されるヘルスチェックの設定は何ですか?
次の表を参照してください。
パラメーター | TCP、HTTP、および HTTPS リスナーの場合 | UDP リスナーの場合 |
ヘルスチェック応答タイムアウト | 5 秒 | 10 秒 |
ヘルスチェック間隔 | 2 秒 | 5 秒 |
正常なしきい値 | 3 回 | 3 回 |
異常なしきい値 | 3 回 | 3 回 |
CLB は、指定されたタイムウィンドウ内で指定された回数だけ連続してヘルスチェックに合格または失敗した場合にのみ、バックエンドサーバーを正常または異常と宣言します。詳細については、「CLB ヘルスチェックの設定と管理」をご参照ください。
バックエンドサーバーがヘルスチェックに失敗した後にサービスがすぐに回復するように、これらの設定を使用することをお勧めします。必要に応じて、より短い応答タイムアウト期間を指定できます。ただし、指定されたタイムアウト期間がバックエンドサーバーの通常の応答時間よりも長いことを確認する必要があります。
ヘルスチェック機能を無効にすることはできますか?
はい、できます。詳細については、「ヘルスチェックの無効化」をご参照ください。
ヘルスチェック機能を無効にすると、リクエストが異常なバックエンドサーバーに配信される可能性があります。これにより、サービス中断が発生する可能性があります。
ビジネスがトラフィックの変動に非常に敏感な場合、頻繁なヘルスチェックはビジネスの可用性に影響を与える可能性があります。ヘルスチェックがビジネスに与える影響を軽減するには、ヘルスチェックの頻度を減らすか、ヘルスチェック間隔を増やすか、レイヤー 7 ヘルスチェックをレイヤー 4 ヘルスチェックに変更します。業務継続性を確保するために、ヘルスチェック機能を有効にすることをお勧めします。
TCP リスナーはどのようにヘルスチェックを実行しますか?
TCP リスナーは、HTTP および TCP ヘルスチェックをサポートしています。
TCP ヘルスチェック:リスナーは、SYN パケットを送信することでバックエンドポートの可用性をチェックします。
HTTP ヘルスチェック:リスナーは、ブラウザがサーバーにアクセスする方法と同様に、HEAD または GET リクエストを送信することでバックエンドサーバーの可用性をチェックします。
TCP ヘルスチェックは、サーバーリソースの消費が少ないです。バックエンドサーバーのワークロードが重い場合、バックエンドポートが開いているかどうかだけを確認したい場合は、TCP ヘルスチェックを設定できます。より正確なヘルスチェック結果が必要な場合は、HTTP ヘルスチェックを設定します。
ECS インスタンスの重みをゼロに設定するとどうなりますか?
ECS インスタンスの重みをゼロに設定すると、CLB は ECS インスタンスにネットワークトラフィックを転送しなくなります。ただし、これはヘルスチェックの結果には影響しません。
ECS インスタンスの重みをゼロに設定した後、ECS インスタンスはワークロードを提供しなくなります。 ECS インスタンスを再起動したり、設定を変更したりする場合は、ECS インスタンスの重みをゼロに設定できます。
HTTP リスナーはどのようなメソッドを使用してバックエンド ECS インスタンスでヘルスチェックを実行しますか?
HTTP リスナーは、HEAD リクエストを送信することでヘルスチェックを実行します。
HEAD リクエストをサポートしていない ECS インスタンスは、ヘルスチェックに失敗します。 ECS インスタンスで次のコマンドを実行して IP アドレスにアクセスし、ECS インスタンスが HEAD リクエストをサポートしているかどうかを確認することをお勧めします。
curl -v -0 -I -H "Host:" -X HEAD http://IP:portHTTP リスナーが ECS インスタンスでヘルスチェックを実行するために使用する IP アドレスは何ですか?
CLB はヘルスチェックに 100.64.0.0/10 を使用します。この CIDR ブロックから送信されたリクエストが ECS インスタンスによって許可されていることを確認してください。 iptables などのセキュリティルールが設定されていない限り、CIDR ブロック 100.64.0.0/10 からのアクセスを許可するセキュリティグループルールを設定する必要はありません。この CIDR ブロックは Alibaba Cloud によって予約されているため、100.64.0.0/10 を許可しても潜在的なリスクは増加しません。 CIDR ブロック内の IP アドレスはユーザーに割り当てられません。
Web ログに記録されたヘルスチェック率がコンソールでのヘルスチェック構成と異なるのはなぜですか?
ヘルスチェックは、単一障害点を防ぐためにサーバーのグループによって実行されます。 CLB は複数のサーバーにデプロイされています。各サーバーは独立してヘルスチェックを実行するため、実際に実行されるヘルスチェックの総数が増加します。したがって、ログに記録されたヘルスチェック率はコンソールの構成とは異なります。
バックエンドデータベースの障害によって発生したヘルスチェックの失敗をどのように処理すればよいですか?
問題
静的 Web サイト
www.example.comと動的 Web サイトaliyundoc.comが ECS インスタンスにデプロイされています。 CLB は、Web サイトに負荷分散サービスを提供するために使用されます。バックエンドデータベースがダウンしています。その結果、www.example.comにアクセスすると HTTP 502 エラーが発生します。考えられる原因
ヘルスチェックドメイン名が
aliyundoc.comに設定されています。 ApsaraDB RDS インスタンスまたは自己管理データベースがダウンすると、aliyundoc.comへのアクセスが失敗し、ヘルスチェックが失敗します。ソリューション
ヘルスチェックドメイン名を
www.example.comに変更します。
バックエンドポートが TCP ヘルスチェックに合格しているにもかかわらず、ログデータがバックエンドポートへの接続失敗を示しているのはなぜですか?
問題
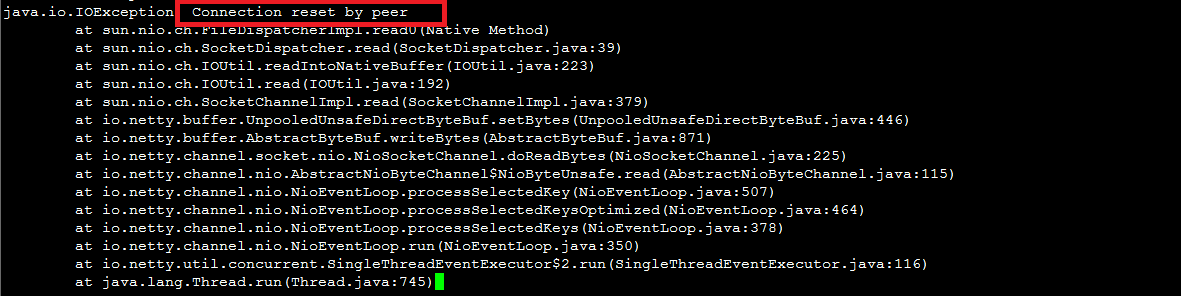
次の図に示すログデータは、TCP リスナーのバックエンドポートへの頻繁な接続失敗を示しています。パケットキャプチャツールを使用して、接続リクエストの送信元を特定します。結果は、接続リクエストが CLB によって送信されたことを示しています。パケットキャプチャツールは、CLB によって送信された RST パケットもキャプチャしています。
考えられる原因
この問題は、ヘルスチェックメカニズムに関連しています。
バックエンドポートでの TCP ヘルスチェックでは、CLB はバックエンドポートとの接続を確立し、3 ウェイハンドシェイクを完了し、RST パケットを送信して接続を閉じます。プロセスは次のとおりです。
CLB が SYN パケットを送信します。
バックエンド ポートは SYN-ACK パケットを返します。
CLB が応答を受信すると、CLB はバックエンド ポートに到達可能であると見なします。この場合、ヘルスチェックは成功します。
その後、CLB は接続を介してサービス リクエストを送信する代わりに、RST パケットを送信して接続を閉じます。
CLB がヘルスチェックを完了した後、TCP 接続は閉じられます。TCP 接続のステータスは、アプリケーション層のサービス ( 例えば、Java 接続プール ) の接続プールには更新されません。そのため、
Connection reset by peerエラーが発生します。解決策
CLB が TCP ヘルスチェックではなく HTTP ヘルスチェックを実行するように構成します。
さらに、CLB の CIDR ブロックからのリクエストを記録するログエントリを除外し、関連するエラーメッセージを無視します。
正常に動作しているバックエンドサーバーがヘルスチェックに失敗するのはなぜですか?
問題
HTTP ヘルスチェックは常に失敗しますが、
curl -Iコマンドを実行すると、返される状態コードは正常です。考えられる原因
コンソールのヘルスチェック構成で返される状態コードが指定されていない場合、バックエンドサーバーはヘルスチェックに失敗します。たとえば、コンソールで HTTP 2xx 状態コードを指定し、別の状態コードが返された場合、バックエンドサーバーはヘルスチェックに失敗します。
Tengine または NGINX で
curlコマンドを実行すると、結果は宛先に到達可能であることを示します。ただし、echoコマンドを実行してテストファイル test.html にアクセスすると、デフォルトの Web サイトにリダイレクトされ、HTTP 404 エラーコードが返されます。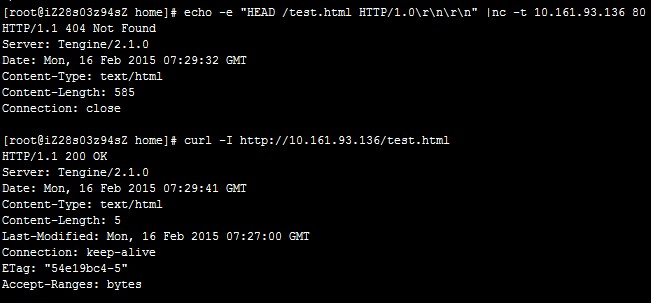
解決策
メイン構成ファイルを変更し、デフォルトのサイトをコメントアウトします。
ヘルスチェックに使用されるドメイン名をヘルスチェック構成に追加します。