ALB は、ヘルスチェックでバックエンドサーバーの稼働状況を定期的に確認します。ヘルスチェックの結果をもとに、ALB はリクエストを送信するサーバーを選別します。このトピックでは、ヘルスチェックに不合格した際のトラブルシューティング方法について説明します。
問題
ALB インスタンスのリスナーの [ヘルスチェックステータス] 列に [異常] と表示されます。
原因
ヘルスチェックを初回設定する時に異常になった場合、ヘルスチェックの設定が不適切であることが原因である可能性があります。以下の考えられる原因を確認する必要があります。
ヘルスチェック設定完了後に異常になった場合、バクエンドサーバーに不具合があることが原因である可能性があります。この場合は、以下の原因を確認してください。
解決策
ヘルスチェック初回設定時の異常
原因 1:パラメーター設定が不適切
ALB コンソール にログインします。
上部のナビゲーションバーで、管理する ALB インスタンスがデプロイされているリージョンを選択します。
左側のナビゲーションウィンドウで、 を選択します。
サーバーグループ ページで、ALB インスタンスに関連付けられているサーバーグループを見つけ、サーバーグループ ID をクリックします。
サーバーグループの詳細ページで、ヘルスチェックセクションのヘルスチェックの変更をクリックします。
ヘルスチェックの変更ダイアログボックスで、パラメーターの設定を確認します。デフォルト設定を使用することを推奨します。
詳細については、「ヘルスチェック」をご参照ください。
原因 2:チェックを行うポートが不適切
ALB コンソール にログインします。
上部のナビゲーションバーで、管理する ALB インスタンスがデプロイされているリージョンを選択します。
左側のナビゲーションウィンドウで、 を選択します。
サーバーグループページで、ALB インスタンスに関連付けられているサーバーグループを見つけ、サーバーグループ ID をクリックします。
サーバーグループの詳細ページで、バックエンドサーバータブをクリックし、バックエンドサーバーのポートをメモしておきます。
サーバーグループの詳細ページで、詳細タブをクリックします。次に、ヘルスチェックセクションのヘルスチェックの変更をクリックします。ヘルスチェックの変更ダイアログボックスで、ヘルスチェックの設定をメモしておきます。
バックエンドサーバーにログインし、nc または curl コマンドを実行してバックエンドサーバーをプローブします。
ECS インスタンスへのログイン方法の詳細については、「インスタンス接続のガイドライン」をご参照ください。
# The nc コマンド: echo -e "[$Method] [$PATH] [$VERSION]\r\nHost: [$Domain]\r\n\r\n" | nc -t [$IP] [$Port] #形式 echo -e "HEAD /index.html HTTP/1.0\r\nHost: wwww.example.org\r\n\r\n" | nc -t 127.0.0.1 80 #例 # The curl コマンド: curl -X [$Method] -H "Host: [$Domain]" -I http://[$IP]:[$Port][$PATH] #形式 curl -X HEAD --http1.0 -H "Host: www.example.org" -I http://127.0.0.1:80/index.html # 例説明[$Method] : ヘルスチェック方法
[$PATH] :ヘルスチェックパス
[$VERSION] : ヘルスチェックプロトコルバージョン (HTTP/1.0 など)
[$Domain] : ヘルスチェックドメイン名。
ドメイン名が ----- の場合、ECS インスタンスのプライベート IP アドレスがヘルスチェックドメイン名として使用されます。この場合、[$Domain] を [$IP] に置き換えることができます。
[$IP] : ECS インスタンスのプライベート IP アドレス
[$Port] : ヘルスチェックポート。
返された HTTP ステータスコードを表示し、業務に応じて正常なレスポンスであるかどうかを確認します。
正常な状態を示すレスポンスである場合、ヘルスチェック設定を変更し、ヘルスチェックステータスコード項目で該当コードにチェックを入れてください。
異常な状態を示すレスポンス場合、次の表を参照してトラブルシューティングを行ってください。
ステータスコード
説明
トラブルシューティング
400
HTTP リクエストの形式が無効です。
HTTP リクエストの形式を確認します (Content-Length ヘッダーが空であるか、HTTP リクエストが HTTPS ポートに転送されるよう設定されたかなど)。
404
リクエストされたリソースが見つかりません。
リクエストされた URL が有効かどうかを確認します。
405
ヘルスチェック方法はサポートされていません。
バックエンドサービスがヘルスチェック方法をサポートしているかどうかを確認します。
500
サーバーに内部エラーがあるため、リクエストを処理できません。
バックエンドサービスのビジネスロジックを確認します。
503
サーバーは一時的に使用できません。
バックエンドサービスのビジネスロジック、またはバックエンドサーバーが過負荷になっているかどうかを確認します。
ヘルスチェック設定完了後の異常
原因 1:セキュリティサービスの設定が不適切
アップグレードされた ALB インスタンス:デフォルトでは、アップグレードされた ALB インスタンスは、所属 vSwitch の CIDR ブロック内のプライベート IP アドレス (Local IP) を使用して、バックエンドサーバーと通信します。バックエンドサーバーが、iptables ルールまたはサードパーティのセキュリティポリシーソフトウェアなどを使用して、これらの Local IP をブロックしていないことを確認してください。ALB コンソール にログインして Local IP を確認できます。
アップグレードされていない ALB インスタンス:アップグレードされていない ALB インスタンスは、100.64.0.0/10 CIDR ブロック内の IP アドレスを使用して、バックエンドサーバーと通信します。バックエンドサーバーが、iptables ルールまたはサードパーティのセキュリティポリシーソフトウェアなどを使用して、これらの IP アドレスをブロックしていないことを確認してください。
ALB インスタンスのアップグレードについては、「ALB instance upgrade」をご参照ください。
次の例では、100.64.0.0/10 が iptables ルールによってブロックされているかどうかを確認します。
バックエンドサーバー (ECS インスタンス) にログインし、次のコマンドを実行してフィルターテーブル内のすべてのルールをクエリします。
iptables -nL次の結果が返された場合、ALB インスタンスのプライベート CIDR ブロックからのリクエストが ECS インスタンスによってブロックされていることを示しています。
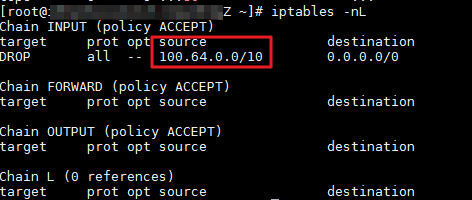
次のコマンドを実行してルールを削除します。
iptables -t filter -D INPUT -s 100.64.0.0/10 -j DROP次のコマンドを実行して、ECS インスタンスが ALB インスタンスのプライベート CIDR ブロックからのリクエストをブロックしていないことを確認します。
iptables -nL
原因 2:ルート設定が不適切
この原因は、アップグレードされていない ALB インスタンスにのみ適用されます。アップグレードされたインスタンスは、所属 vSwitch の CIDR ブロック内のプライベート IP アドレス (Local IP) を使用して、バックエンドサーバーと通信するため、100.64.0.0/10 CIDR ブロックの許可ポリシーは必要ありません。
ALB インスタンスのアップグレードについては、「ALB instance upgrade」をご参照ください。
ECS インスタンスにおいて、100.64.0.0/10 CIDR のルート設定が不適切の場合、ヘルスチェックプローブのパケットが ALB インスタンスに届かず、ヘルスチェック異常になります。
次の例では、Linux の route コマンドを使用してルート設定を確認します。
バックエンドサーバー (ECS インスタンス) にログインし、次のコマンドを実行してルート設定を確認します。
route -nルートの Destination 値が 100.64.0.0、Genmask 値が 255.192.0.0 であり、Gateway 値が対応する ENI のデフォルトゲートウェイに設定されていない場合、ルートが正しく設定されていないことがわかります。デフォルトゲートウェイとは、Destination 値が 0.0.0.0 の場合の Gateway 値を指します。

次のコマンドを実行して、100.64.0.0/10 を指す不適切なルートを削除します。
route del -net 100.64.0.0/10
原因 3:バックエンドサーバーが過負荷
Linux インスタンスのシステム負荷のクエリと分析 を参照し、バックエンドサーバーが過負荷になっているかどうかを確認します。