Tair (Redis OSS-compatible) のメモリが不足すると、頻繁に削除されるキー、応答時間の増加、1秒あたりのクエリ数 (QPS) が不安定になるなどの問題が発生する可能性があります。 これらの問題はワークロードを中断する可能性があります。 インスタンスがメモリ不足の場合、またはインスタンスのメモリアラートを受信した場合は、このトピックを参照して、メモリ使用量が常に高いかどうか、メモリ使用量が突然増加するかどうか、またはメモリ使用量のスキューが発生するかどうかを確認できます。 大きなキーの分割、有効期限ポリシーの設定、仕様のアップグレードなどの戦略を使用して、問題を解決することもできます。
高いメモリ使用量の症状
高メモリ使用率は、次の3つのシナリオで現れます。
メモリ使用量は長期間高いままです。 メモリ使用量が95% を超える場合は、タイムリーに対応する必要があります。
メモリ使用量は一貫して低いですが、突然急上昇して高レベルになり、100% に達します。
インスタンスの全体的なメモリ使用量は少ないですが、特定のデータノードのメモリ使用量はほぼ100% です。
特定のシナリオに基づいて、メモリ使用量を削減するための適切な対策を講じてください。
一貫して高いメモリ使用量へのソリューション
既存のキーがビジネス要件を満たしているかどうかを確認し、不要なキーをタイムリーに削除します。
キャッシュ分析機能を使用して、大きなキーの分布とキーの有効期限 (TTL) を分析します。 詳細については、「オフラインキー分析機能の使用」をご参照ください。
キーに適切なTTL値が設定されているかどうかを確認します。
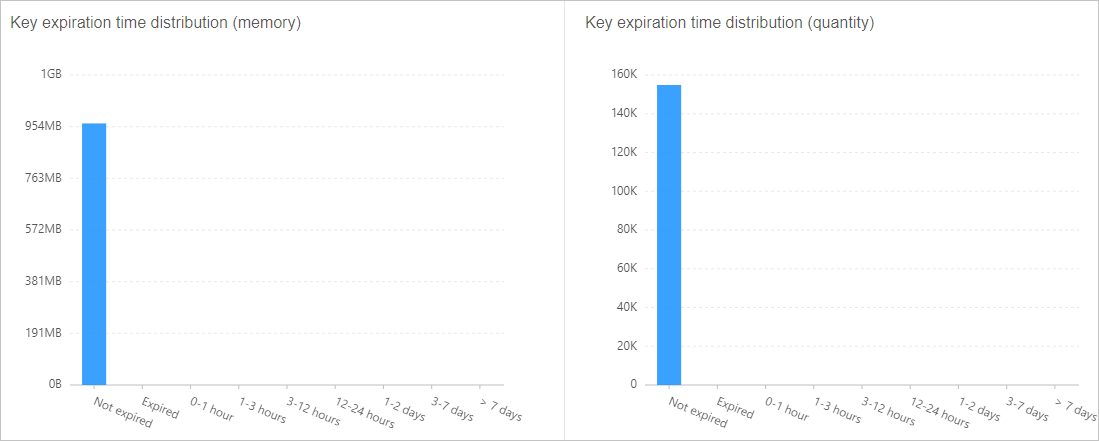
説明次の例では、キーにTTL値が設定されていません。 ビジネス要件に基づいて、クライアントで適切なTTL値を設定することを推奨します。
図4. キーTTLの配布例
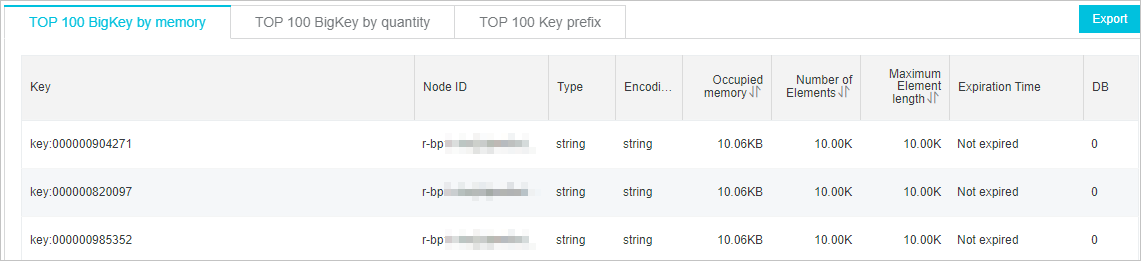
クライアントで大きなキーを評価し、大きなキーを分割します。
図5. 大きなキー分析の例
適切な削除ポリシーを設定するか、ビジネス要件に基づいてmaxmemory-policyパラメーターの値を変更します。 詳細は、「インスタンスパラメーターの設定」をご参照ください。
説明volatile-lruは、Tair (Redis OSS-compatible) のデフォルトの削除ポリシーです。 詳細については、「」をご参照ください。Tair (Redis OSS-compatible) はデフォルトでどのようにデータを追い出しますか?
期限切れのキーを削除する頻度を適切な値に設定するか、ビジネス要件に基づいてhzパラメーターの値を変更します。 詳細については、「バックグラウンドタスクの頻度の調整」をご参照ください。
説明hzパラメーターを100より小さい値に設定することを推奨します。 この値が大きい場合、CPU使用率が影響を受けます。 メジャーバージョンが5.0以降のインスタンスに対して、動的周波数制御を設定することもできます。 詳細については、「バックグラウンドタスクの動的周波数制御の有効化」をご参照ください。
上記の手順を実行してもメモリ使用量が多い場合は、より多くのデータに対応し、全体的なパフォーマンスを向上させるために、インスタンスをより大きなメモリサイズにアップグレードすることを検討してください。 詳細については、「インスタンスの設定の変更」をご参照ください。
説明インスタンスをアップグレードする前に、従量課金インスタンスを購入して、アップグレード先の仕様がワークロードの要件を満たしているかどうかをテストできます。 テストの完了後、従量課金インスタンスをリリースできます。 詳細については、「従量課金インスタンスのリリース」をご参照ください。
メモリ使用量の急増に対する解決策
発生原因
次の理由により、メモリ使用量が突然増加することがあります。
大量の新しいデータが短時間で書き込まれる。
短時間で多数の新しい接続が確立されます。
バーストアクセスでは、ネットワーク帯域幅を超える大量のトラフィックが生成され、その結果、入力バッファと出力バッファにバックログが発生します。
クライアントはTair (Redis OSS-compatible) の処理速度に追いつくことができず、出力バッファにバックログが発生します。
ソリューション
メモリ使用量の突然の増加の原因を特定し、提案されたソリューションを使用して問題を解決します。
大量の新しいデータが書き込まれているかどうかを確認する
トラブルシューティング方法:
[パフォーマンスモニター] ページで、インスタンスのインバウンドトラフィックと1秒あたりの書き込みクエリ (QPS) を確認します。 インバウンドトラフィックと書き込みQPSがメモリ使用量と同じ傾向にある場合、メモリ使用量の急激な増加は、大量の書き込みデータが原因です。
解決策:
キーに適切な有効期間 (TTL) 値を設定して、不要になったキーを自動的に削除したり、不要なキーを手動で削除したりします。
メモリ使用量の急激な増加を緩和するために、メモリ容量を増やしてインスタンス仕様をアップグレードします。 詳細については、「インスタンスの設定の変更」をご参照ください。
インスタンスが標準インスタンスで、メモリ容量を増やした後もメモリ使用量が多い場合は、インスタンスをクラスターインスタンスにアップグレードできます。 これにより、複数のデータシャードにデータを分散して、個々のデータシャードのメモリ負荷を軽減できます。 詳細については、「インスタンスの設定の変更」をご参照ください。
大量の新しい接続が作成されているかどうかの確認
トラブルシューティング方法:
[パフォーマンスモニター] ページで、インスタンスへの接続数。 接続数が突然増加し、メモリ使用量と同じ傾向に従う場合、メモリ使用量の突然の増加は、多数の新しい接続が原因です。
解決策:
接続リークが存在するかどうかを確認します。
アイドル接続を自動的に閉じるように接続タイムアウト期間を設定します。 詳細については、「クライアント接続のタイムアウト期間の指定」をご参照ください。
突然のトラフィックスパイクが入力バッファと出力バッファのバックログにつながるかどうかを確認する
トラブルシューティング方法:
インスタンスのインバウンドトラフィックとアウトバウンドトラフィックの使用量が100% に達しているかどうかを確認します。
MEMORY STATSコマンドを実行して、clients.normalが過剰なメモリを占有しているかどうかを確認します。説明clients.normalは、すべての通常のクライアント接続で入力バッファと出力バッファによって使用されるメモリの総量を反映します。
解決策:
トラフィックバーストの原因を確認します。
インスタンスのネットワーク帯域幅を増やします。 詳細については、「インスタンスの帯域幅を手動で増やす」および「帯域幅自動スケーリングの有効化」をご参照ください。
インスタンス仕様をアップグレードして、入力バッファと出力バッファの最適な使用を確保します。 詳細については、「インスタンスの設定の変更」をご参照ください。
クライアント側のパフォーマンスの問題が出力バッファのバックログにつながるかどうかを確認します
トラブルシューティング方法:
redis-cliで、MEMORY DOCTORコマンドを実行して、big_client_bufの値を表示します。 big_client_bufが1に設定されている場合、少なくとも1つのクライアントに大量のメモリを消費する大きな出力バッファがあります。
解決策:
CLIENT LISTコマンドを実行して、大量のメモリ (omem) を消費する大容量の出力バッファがあるクライアントを確認します。 クライアントアプリケーションにパフォーマンスの問題があるかどうかを確認します。
特定のデータノードの高メモリ使用量に対するソリューション
症状
インスタンスがクラスターインスタンスの場合、次の症状に基づいて、特定のデータシャードのメモリ使用量が多いことがわかります。
CloudMonitorからメモリ使用量アラートを受信します。 アラートメッセージは、特定のデータノードのメモリ使用量がしきい値を超えたことを示します。
インスタンス診断レポートは、メモリ使用量のスキューが発生したことを示します。
[パフォーマンスモニター] ページでは、インスタンスの全体的なメモリ使用量は高くありませんが、特定のデータノードのメモリ使用量は高くなっています。
発生原因
インスタンスのメモリ使用量が少ないが、データノードのメモリ使用量が多い場合、メモリ使用量のスキューが発生します。
ソリューション
大きいキーが存在し、大きいキーを分割するチェック
大きなキーの識別
オフラインキー分析機能を使用して、大きなキーを識別できます。 詳細については、「オフラインキー分析機能の使用」をご参照ください。
大きなキーを識別する方法については、「大きなキーとホットキーの識別と処理」をご参照ください。
分割大きなキー
たとえば、数万のメンバーを含むHASHキーを、適切な数のメンバーを持つ複数のHASHキーに分割できます。 クラスターインスタンスの場合、大きなキーを分割して、複数のデータシャード間でメモリ使用量のバランスを取ることができます。
ハッシュタグが使用されているかどうかの確認
ハッシュタグを使用する場合は、ビジネス要件に基づいてハッシュタグを複数のハッシュタグに分割することを検討してください。 このようにして、データは異なるデータノードにわたって均等に分散される。
インスタンス仕様のアップグレード
各シャードに割り当てられるメモリを増やしてインスタンス仕様をアップグレードすることは、メモリスキューを防ぐための一時的な解決策として役立ちます。 詳細については、「インスタンスの設定の変更」をご参照ください。
インスタンス仕様の変更中にデータスキューの事前チェックが開始されます。 選択したインスタンスタイプがデータスキューの問題を処理できない場合、システムはエラーを報告します。 仕様の高いインスタンスタイプを選択して、もう一度お試しください。
インスタンス仕様をアップグレードすると、メモリ使用量のスキューが緩和される可能性があります。 しかしながら、スキューは、帯域幅およびCPUリソース上でも発生し得る。
付録1: Tairのメモリ使用量 (Redis OSS互換)
Tair (Redis OSS-compatible) のメモリ使用量は3つの部分に分かれています。 メモリ使用量を次の表に示します。
メモリ使用量 | 説明 |
リンク関連の操作によって消費されるメモリ | 入力バッファによって消費されるメモリ、出力バッファによって消費されるメモリ、JITオーバーヘッドによって消費されるメモリ、Fake Lua Linkによって消費されるメモリ、および実行されたLuaスクリプトをキャッシュするために消費されるメモリが含まれます。 メモリ消費量は動的に変化する。 INFOコマンドを実行すると、出力の [クライアント] 列からクライアントキャッシュ情報を取得できます。 説明 入力バッファおよび出力バッファによって消費されるメモリは小さく、各クライアントからの接続数に基づいて変化する。 クライアントがレンジベースの操作を開始するとき、またはクライアントが大きなキーを低速で送受信するとき、入力バッファおよび出力バッファによって消費されるメモリが増加する。 その結果、データを格納するために使用できるメモリが減少し、メモリ不足 (OOM) の問題が発生する可能性があります。 |
データによって消費されるメモリ | フィールド値の格納に消費されるメモリが含まれます。 メモリ消費のこの部分は、分析する必要がある重要なオブジェクトです。 |
管理操作によって消費されるメモリ | ハッシュセットによって消費されるメモリ、レプリケーションバッファーによって消費されるメモリ、および追加専用ファイル (AOF) バッファーによって消費されるメモリが含まれます。 メモリ消費量は32 MBから64 MBの範囲で安定しており、これは小さいです。 説明 数億などの多数のキーは、大量のメモリを消費する。 |
ほとんどのOOMの問題は、動的に取得およびリリースされたメモリの管理が不十分なために発生します。 例えば、スロットリングにより多数のリクエストが積み重なると、動的に獲得するメモリ量が急激に増加する。 OOMの問題は、複雑または不適切なLuaスクリプトによっても発生する可能性があります。 動的に取得および解放されたメモリの管理は、Tair (Enterprise Edition) で強化されています。 Tair (Enterprise Edition) の使用を推奨します。 詳細については、「概要」をご参照ください。
付録2: メモリ使用量を確認するその他の方法
MEMORY STATSコマンドを使用してメモリ使用量を表示する
MEMORY DOCTORコマンドを使用してメモリ診断の提案を表示する
redis-cliでMEMORY DOCTORコマンドを実行し、メモリ診断の提案を取得します。
図3. 診断結果の例 
MEMORY DOCTORコマンドを実行すると、インスタンスの診断提案が次のディメンションから提供されます。 診断の提案に基づいて最適化の決定を行うことができます。
int empty = 0; /* Instance is empty or almost empty. */
int big_peak = 0; /* Memory peak is much larger than used mem. */
int high_frag = 0; /* High fragmentation. */
int high_alloc_frag = 0;/* High allocator fragmentation. */
int high_proc_rss = 0; /* High process rss overhead. */
int high_alloc_rss = 0; /* High rss overhead. */
int big_slave_buf = 0; /* Slave buffers are too big. */
int big_client_buf = 0; /* Client buffers are too big. */
int many_scripts = 0; /* Script cache has too many scripts. */