TairSearchは、全文検索用のTairの社内データ構造で、Elasticsearchと同様の構文を使用します。 このトピックでは、TairSearchでTFT.MSEARCHコマンドを使用してデータシャードでドキュメントを検索する方法について説明します。
背景情報
TairSearchでは、キーは最も基本的なビルディングブロックです。 通常、キーは、マッピングと設定を含むスキーマに対応します。 予想よりも多い数の文書がキーに書き込まれた場合、そのキーは大きなキーになる。 キーのメモリ使用量がデータシャードのメモリ容量を超えると、メモリ不足エラーが発生します。
スタンドアロンインスタンスのメモリ容量をスケールアップする場合は、次の手順を実行します。
スタンドアロンインスタンスをクラスターインスタンスにアップグレードします。
大きなキーを小さなキーに分割し、これらのキーをクラスターインスタンスのデータシャードに配布します。
このコンテキストでは、TairSearchは、大きなキーを検索するための次のソリューションを提供します。大きなキーを小さなキーに分割し、これらのキーにドキュメントを配布してから、TFT.MSEARCHコマンドを使用してこれらのキーのドキュメントを照会します。 これらのキーを作成するときは、これらのキーが同じスキーマ構成であることを確認してください。 TairSearchの詳細については、「Search」をご参照ください。
クエリのパフォーマンスを向上させるために、TairProxyが提供されているプロキシモードの読み書き分離インスタンスまたはクラスターインスタンスでMsearch機能を使用することを推奨します。 直接接続モードのクラスターインスタンスや、TairProxyを持たない標準インスタンスでは、Msearchを使用しないことを推奨します。
Msearchの仕組み
TairSearchは、1つのキーを照会するTFT.SEARCHコマンドと、同じスキーマ構成を持つ複数のキーを照会するTFT.MSEARCHコマンドを提供します。
クライアントがTairProxyに書き込み要求を送信すると、TairProxyはスロットに基づいて対応するデータシャードにキーを書き込みます。
Msearchでは、キーと同じスキーマ設定と、大きなキーを分割するためのカスタムロジックが必要です。 大きなキーを小さなキーに分割し、小さなキーを配布するルールを理解し、指定する必要があります。
図 1. 書き込み要求を処理するTairProxyのワークフロー 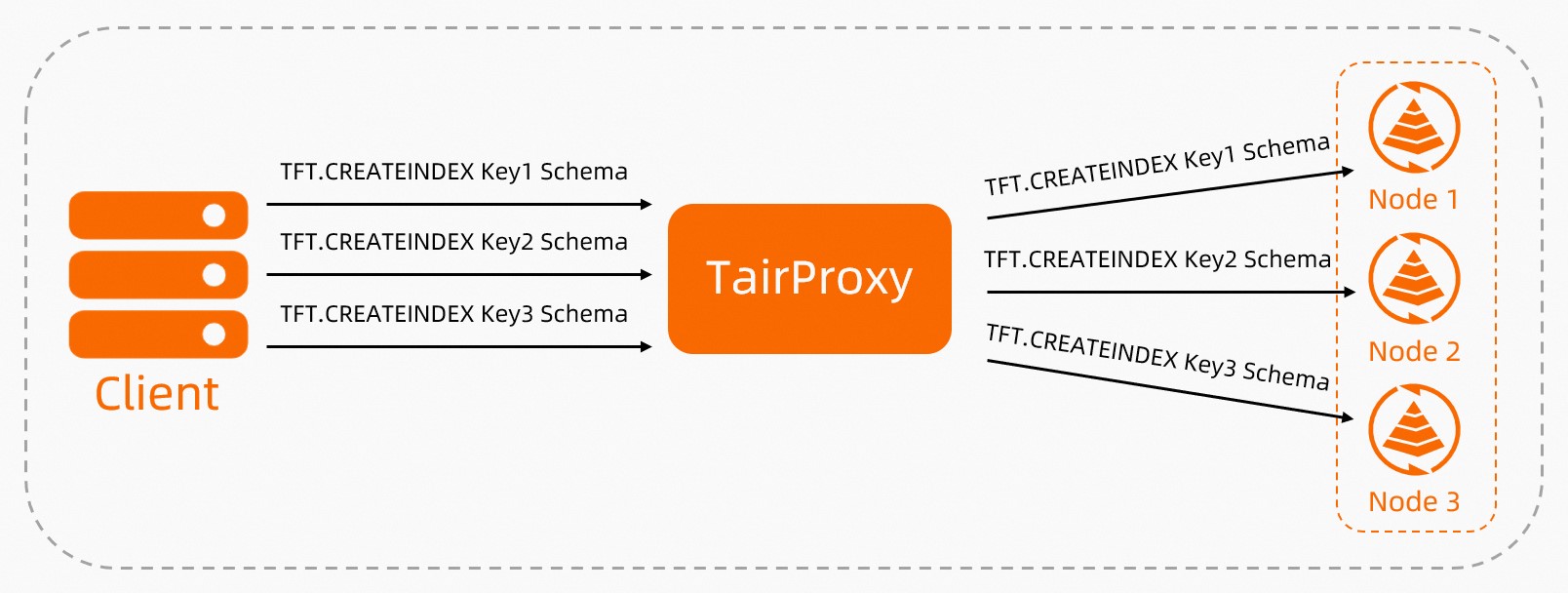
クライアントがTFT.MSEARCHコマンドを使用して読み取り要求をTairProxyに送信すると、TairProxyは要求されたデータを含むデータシャードに要求を転送します。 これらのデータシャードは、キー内の目的のドキュメントをクエリし、結果を収集して、結果をTairProxyに返します。 次に、TairProxyはドキュメントをスコアリング、ソート、および集計し、最終結果セットをクライアントに返します。
図2. 読み取り要求を処理するTairProxyのワークフロー 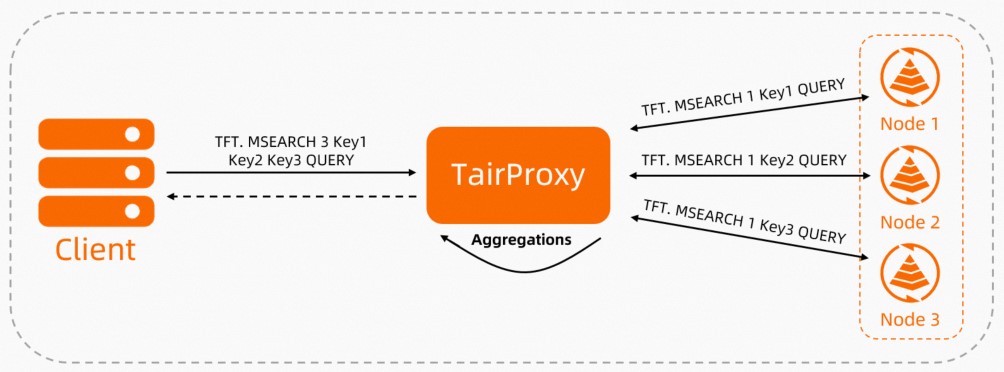
Msearchページング
TairSearchでデータシャードでドキュメントを検索すると、大量のドキュメントが返される場合があります。 この場合、Msearchページングを使用してドキュメントをバッチで取得できます。
Msearchページングのしくみ
fromとsizeの組み合わせを使用してページングを実装するTFT.SEARCHとは異なり、TFT.MSEARCHはsizeとkeys_cursorを使用します。 sizeは、返すことができるドキュメントの総数を指定します。 keys_cursorは、各キーの次のクエリの開始位置を示します。
TFT.MSEARCHを使用してページングを実装する手順:
sizeパラメーターを指定し、TFT.MSEARCHコマンドを実行して、各キーからsizeドキュメントを取得します。
reply_with_keys_cursorパラメーターをtrueに設定して、Tairが収集されたドキュメントをスコアリング、ソート、および集計し、sizeドキュメントとkeys_cursor値を返します。説明key_cursorのデフォルト値は0です。これは、次のクエリがカーソルの後の最初のドキュメントから始まることを示します。
次のクエリで、keys_cursorパラメーターの前の戻り値を指定して、Tairが指定した位置からサイズのドキュメントを取得するようにし、前の手順を繰り返します。
例:
key0、key1、およびkey2キーからドキュメントをクエリするために、sizeパラメーターを10に設定したとします。
Tairは、3つのキーのそれぞれから10個のドキュメントを取得し、これらの30個のドキュメントをスコア、ソート、および集約します。 次に、Tairはトップ10のドキュメントを返します。 key_cursorの {"keys_cursor":{"key0":2,"key1":5,"key2":3}} サンプルの戻り値は、返されるドキュメントがkey0結果の上位2つ、key1結果の上位5つ、およびkey2結果の上位3つで構成されることを示します。 次のクエリでは、keys_cursorパラメーターを {"key0":2,"key1":5,"key2":3} に設定します。 この場合、Tairは、key0の3番目の文書から10個、key1の6番目の文書から10個、key2の4番目の文書から10個を取得する。
サンプルコード
次のサンプルコードは、Msearchを使用してホットデータを検索する方法を示しています。
TairSearchの各キーが1週間以内に生成されたホットデータエントリを格納し、毎日100万個のエントリが生成されると仮定します。 この場合、各キーは700万のドキュメントを保存すると予想されます。
新しいキーは各週の初めに作成され、各キーは2週間保持されます。 期限切れのキーは削除されます。
各データエントリには、datetime、author、uid、およびcontentプロパティが含まれます。
インデックスを作成します。
# Create two keys and specify key names in the "FLOW_START DATE_END DATE" format. Make sure that the keys have the same schema configurations. TFT.CREATEINDEX FLOW_20230109_15 '{ "mappings":{ "properties":{ "datetime":{ "type":"long" }, "author":{ "type":"text" }, "uid":{ "type":"long" }, "content":{ "type":"text", "analyzer": "jieba" } } } }' TFT.CREATEINDEX FLOW_20230116_23 '{ "mappings":{ "properties":{ "datetime":{ "type":"long" }, "author":{ "type":"text" }, "uid":{ "type":"long" }, "content":{ "type":"text", "analyzer": "jieba" } } } }'ドキュメントデータを追加します。
# Write one data entry to each of the two keys. TFT.ADDDOC FLOW_20230109_15 '{ "datetime":20230109001209340, "author":"Hot TV series", "uid":7884455, "content":"The movie will be screened during the Spring Festival" }' TFT.ADDDOC FLOW_20230116_23 '{ "datetime":20230118011304250, "author":"Fashionable commodities", "uid":100093, "content":"Launch a new line of zodiac series products for the Year of the Rabbit" }'これら2つのキーからドキュメントを照会します。
ウサギの年の中国の黄道帯に関連するホットデータを照会し、返されたドキュメントを時間ごとに並べ替えます。
TFT.MSEARCH 2 FLOW_20230109_15 FLOW_20230116_23 '{ "query":{ "match":{ "content":"Chinese zodiac of the Year of the Rabbit" } }, "sort" : [ { "datetime": { "order" : "desc" } } ], "size":10, "reply_with_keys_cursor":true, "keys_cursor":{ "FLOW_2023010916":0, "FLOW_202301623":0 } }'期待される出力:
{ "hits":{ "hits":[ { "_id":"20230118011304250", "_index":"FLOW_20230116_23", "_score":1, "_source":{ "datetime":20230118011304250, "author":"Fashionable commodities", "uid":100093, "content":"Launch a new line of zodiac series products for the Year of the Rabbit" } } ], "max_score":1, "total":{ "relation":"eq", "value":1 } }, "aux_info":{ "index_crc64":14159192555612760957, "keys_cursor":{ "FLOW_20230109_15":0, "FLOW_20230116_23":1 } } }