このトピックでは、TairVector と CLIP を使用して、リアルタイムでパフォーマンスの高い画像テキストマルチモーダル検索を実現するソリューションについて説明します。
背景情報
インターネットには、画像やテキストなど、膨大な量の非構造化データが存在します。DAMO Academy のオープンソースである Contrastive Language-Image Pre-training (CLIP) モデルには、Text Transformer や ResNet などのモデルが組み込まれています。これらのモデルは、画像やテキストなどの非構造化データから特徴を抽出し、構造化データに解析します。
CLIP モデルを使用して、画像やドキュメントなどのデータを前処理し、その結果を Tair に保存できます。その後、TairVector の最近傍探索機能を使用して、効率的な画像-テキストのマルチモーダル検索を実装できます。TairVector の詳細については、「ベクトル」をご参照ください。
ソリューション概要
画像データのダウンロード
この例では、次のテストデータを使用します。
画像:7,000 枚以上のさまざまな種類のペット画像を含むオープンソースのペット画像データセット。
テキスト:「a dog」、「a white dog」、「a running white dog」。
Tair インスタンスに接続します。実装の詳細については、サンプルコード内の
get_tair関数をご参照ください。Tair でイメージとテキストのベクターインデックスを作成します。実装の詳細については、サンプルコードの
create_index関数をご参照ください。画像とテキストデータの書き込み
CLIP モデルを使用してイメージとテキストデータを前処理し、次に TairVector の TVS.HSET コマンドを使用して、それらの名前と特徴を Tair に格納します。実装の詳細については、イメージは
insert_images関数、テキストはupsert_text関数をご参照ください。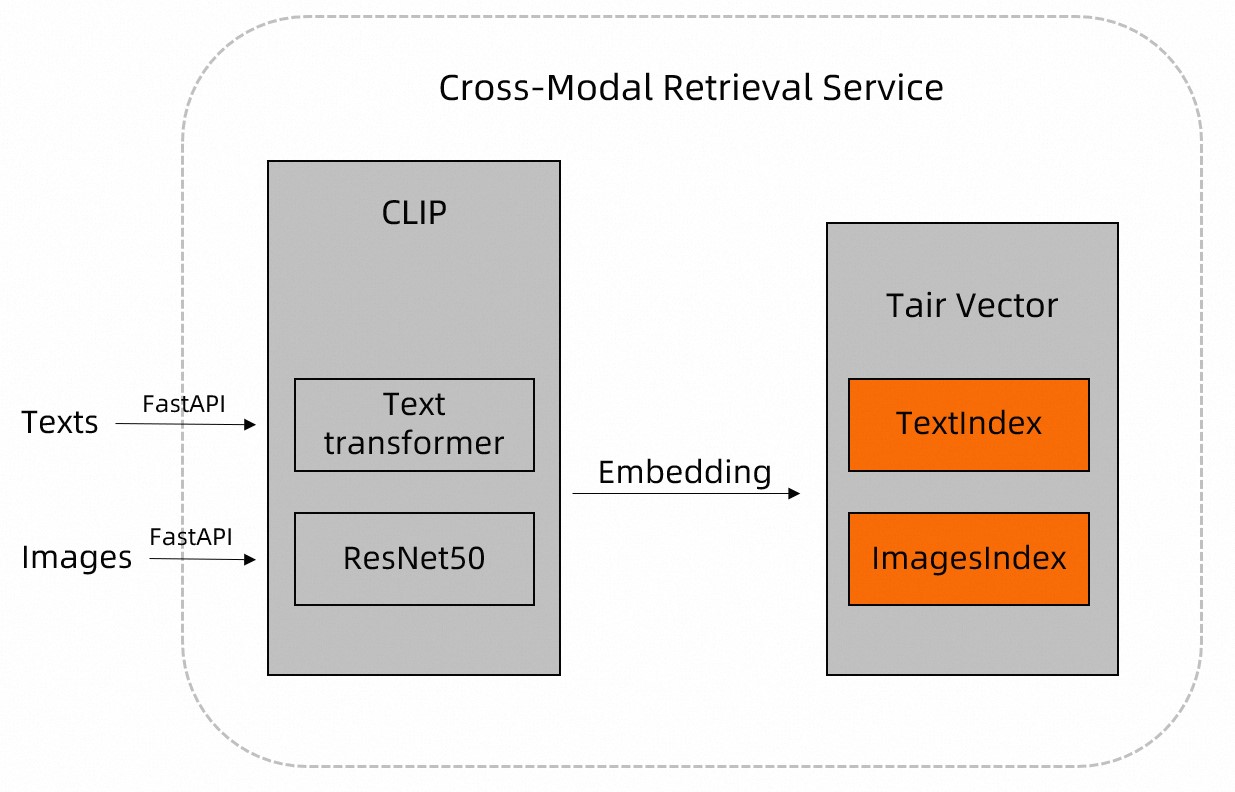
マルチモーダルクエリの実行
テキストによる画像検索
CLIP モデルを使用してクエリテキストを前処理します。次に、TairVector の TVS.KNNSEARCH コマンドを使用して、Tair データベースでテキスト記述に最も類似するイメージを検索します。実装の詳細については、サンプルコードにある
query_images_by_text関数をご参照ください。画像によるテキスト検索
CLIP モデルを使用してクエリイメージを前処理します。 次に、TairVector の TVS.KNNSEARCH コマンドを使用して Tair データベースをクエリし、イメージに最も一致するテキストを検索します。 実装の詳細については、サンプルコードの
query_texts_by_image関数をご参照ください。
説明クエリテキストや画像は TairVector に保存する必要はありません。
TVS.KNNSEARCH コマンドでは、返す結果の数 (
topK) を指定できます。類似度距離 (distance) が小さいほど、類似度が高いことを示します。
サンプルコード
この例では Python 3.8 を使用し、Tair-py、torch、Image、pylab、plt、および CLIP の依存関係が必要です。Tair-py をインストールするには、次のコマンドを実行します: pip3 install tair。
# -*- coding: utf-8 -*-
# !/usr/bin/env python
from tair import Tair
from tair.tairvector import DistanceMetric
from tair import ResponseError
from typing import List
import torch
from PIL import Image
import pylab
from matplotlib import pyplot as plt
import os
import cn_clip.clip as clip
from cn_clip.clip import available_models
def get_tair() -> Tair:
"""
このメソッドは Tair インスタンスに接続します。
* host:Tair インスタンスのエンドポイント。
* port:Tair インスタンスのポート番号。デフォルトは 6379 です。
* password:Tair インスタンスのデフォルトアカウントのパスワード。カスタムアカウントで接続する場合、フォーマットは 'ユーザー名:パスワード' です。
"""
tair: Tair = Tair(
host="r-8vbehg90y9rlk9****pd.redis.rds.aliyuncs.com",
port=6379,
db=0,
password="D******3",
decode_responses=True
)
return tair
def create_index():
"""
画像とテキストの埋め込みを保存するためのベクターインデックスを作成します:
* 画像のキー名は 'index_images'、テキストのキー名は 'index_texts' です。
* ベクターのディメンションは 1024 です。
* ベクターの距離関数は IP です。
* インデックスアルゴリズムは HNSW です。
"""
ret = tair.tvs_get_index("index_images")
if ret is None:
tair.tvs_create_index("index_images", 1024, distance_type="IP",
index_type="HNSW")
ret = tair.tvs_get_index("index_texts")
if ret is None:
tair.tvs_create_index("index_texts", 1024, distance_type="IP",
index_type="HNSW")
def insert_images(image_dir):
"""
画像のパスを入力します。このメソッドは、パス内の画像ファイルを自動的に走査します。
このメソッドは `extract_image_features` メソッドも呼び出し、CLIP モデルを使用して画像ファイルを前処理し、画像の特徴情報を返します。返された特徴情報は Tair Vector に保存されます。
Tair への保存フォーマットは次のとおりです:
* ベクターインデックス名:'index_images' (固定)。
* キー:画像のパスとそのファイル名。例:'test/images/boxer_18.jpg'。
* 特徴情報:1024 ディメンションのベクター。
"""
file_names = [f for f in os.listdir(image_dir) if (f.endswith('.jpg') or f.endswith('.jpeg'))]
for file_name in file_names:
image_feature = extract_image_features(image_dir + "/" + file_name)
tair.tvs_hset("index_images", image_dir + "/" + file_name, image_feature)
def extract_image_features(img_name):
"""
このメソッドは、CLIP モデルを使用して画像ファイルを前処理し、画像の特徴情報 (1024 ディメンションのベクター) を返します。
"""
image_data = Image.open(img_name).convert("RGB")
infer_data = preprocess(image_data)
infer_data = infer_data.unsqueeze(0).to("cuda")
with torch.no_grad():
image_features = model.encode_image(infer_data)
image_features /= image_features.norm(dim=-1, keepdim=True)
return image_features.cpu().numpy()[0] # [1, 1024]
def upsert_text(text):
"""
保存するテキストを入力します。このメソッドは `extract_text_features` メソッドを呼び出し、CLIP モデルを使用してテキストを前処理し、テキストの特徴情報を返します。返された特徴情報は Tair Vector に保存されます。
Tair への保存フォーマットは次のとおりです:
* ベクターインデックス名:'index_texts' (固定)。
* キー:テキストの内容。例:'a running dog'。
* 特徴情報:1024 ディメンションのベクター。
"""
text_features = extract_text_features(text)
tair.tvs_hset("index_texts", text, text_features)
def extract_text_features(text):
"""
このメソッドは、CLIP モデルを使用してテキストを前処理し、テキストの特徴情報 (1024 ディメンションのベクター) を返します。
"""
text_data = clip.tokenize([text]).to("cuda")
with torch.no_grad():
text_features = model.encode_text(text_data)
text_features /= text_features.norm(dim=-1, keepdim=True)
return text_features.cpu().numpy()[0] # [1, 1024]
def query_images_by_text(text, topK):
"""
このメソッドは、テキストによる画像検索を実行します。
検索するテキスト内容 (text) と返す結果の数 (topK) を入力します。
このメソッドは、CLIP モデルを使用してクエリテキストを前処理します。次に、Vector の `TVS.KNNSEARCH` コマンドを使用して Tair データベースにクエリを実行し、テキストの説明に最も類似した画像を探します。
ターゲット画像のキー名と類似度距離 (distance) を返します。distance の値が小さいほど、類似度が高いことを示します。
"""
text_feature = extract_text_features(text)
result = tair.tvs_knnsearch("index_images", topK, text_feature)
for k, s in result:
print(f'key : {k}, distance : {s}')
img = Image.open(k.decode('utf-8'))
plt.imshow(img)
pylab.show()
def query_texts_by_image(image_path, topK=3):
"""
このメソッドは、画像によるテキスト検索を実行します。
クエリ画像のパスと返す結果の数 (topK) を入力します。
このメソッドは、CLIP モデルを使用してクエリ画像を前処理します。次に、Vector の `TVS.KNNSEARCH` コマンドを使用して Tair データベースにクエリを実行し、画像に最も一致するテキストを探します。
ターゲットテキストのキー名と類似度距離 (distance) を返します。distance の値が小さいほど、類似度が高いことを示します。
"""
image_feature = extract_image_features(image_path)
result = tair.tvs_knnsearch("index_texts", topK, image_feature)
for k, s in result:
print(f'text : {k}, distance : {s}')
if __name__ == "__main__":
# Tair データベースに接続し、画像とテキストのベクターインデックスを作成します。
tair = get_tair()
create_index()
# Chinese-CLIP モデルをロードします。
model, preprocess = clip.load_from_name("RN50", device="cuda", download_root="./")
model.eval()
# 例えば、ペット画像データセットのパスが '/home/CLIP_Demo' の場合、画像データを書き込みます。
insert_images("/home/CLIP_Demo")
# サンプルテキストデータ ('a dog', 'a white dog', 'a running white dog') を書き込みます。
upsert_text("a dog")
upsert_text("a white dog")
upsert_text("a running white dog")
# テキストによる画像検索を実行し、テキスト 'a running dog' に最も一致する 3 つの画像を見つけます。
query_images_by_text("a running dog", 3)
# 画像によるテキスト検索を実行します。画像パスを指定して、画像を詳細に説明するテキストを見つけます。
query_texts_by_image("/home/CLIP_Demo/boxer_18.jpg",3)結果
テキストによる画像検索:次の 3 つの画像が、テキスト「a running dog」に最も一致します。

画像によるテキスト検索:指定されたクエリ画像を以下に示します。

クエリ結果は次のとおりです。
{ "results":[ { "text":"a running white dog", "distance": "0.4052203893661499" }, { "text":"a white dog", "distance": "0.44666868448257446" }, { "text":"a dog", "distance": "0.4553511142730713" } ] }
まとめ
Tair は、HNSW などのインデックスアルゴリズムを内蔵したインメモリデータベースであり、検索速度を向上させます。
TairVector と CLIP を組み合わせてマルチモーダル検索を行うことで、商品推薦などのシナリオ向けのテキストによる画像検索と、文章作成支援などのシナリオ向けの画像によるテキスト検索の両方が可能になります。また、CLIP モデルを他のモデルに置き換えることで、テキストによる動画検索やテキストによる音声検索など、より多くのモダリティにわたる検索機能を実装することもできます。