TairVectorは、Tair (Enterprise Edition) の社内データ構造で、ベクターの高性能なリアルタイム保存と検索を提供します。 このトピックでは、TairVectorのパフォーマンスをテストする方法について説明し、Alibaba Cloudが取得したテスト結果を提供します。
TairVectorは、近似最近傍 (ANN) 探索アルゴリズムをサポートする。 TairVectorは、非構造化データとパーソナライズされたレコメンデーションのセマンティック検索に使用できます。 詳細については、「ベクター」をご参照ください。
テストの説明
データベーステスト環境
項目 | 説明 |
リージョンとゾーン | 中国 (張家口) リージョンのゾーンA |
ストレージタイプ | Redis 6.0を実行するDRAMベースのインスタンス |
エンジンバージョン | 6.2.8.2 |
インスタンスアーキテクチャ | クラスターモードが無効になっている標準のマスターレプリカアーキテクチャ。 詳細については、「標準アーキテクチャ」をご参照ください。 |
インスタンスタイプ | tair.rdb.16g. インスタンスタイプは、テスト結果に些細な影響を与えます。 |
クライアントテスト環境
Tair (Redis OSS-compatible) インスタンスと同じ仮想プライベートクラウド (VPC) にデプロイされたElastic Compute Service (ECS) インスタンスが作成され、VPCを介して Tair (Redis OSS-compatible) インスタンスに接続されます。
Linuxオペレーティングシステムが使用されます。
Python 3.7以降がインストールされます。
テストデータ
Sift-128-euclidean、Gist-960-euclidean、グローブ200角度、およびディープ画像96角度のデータセットを使用して、階層的ナビゲート可能スモールワールド (HNSW) インデックス付けアルゴリズムをテストします。 Random-s-100-ユークリッドデータセットとMnist-784-euclideanデータセットを使用して、Flat Searchインデックス付けアルゴリズムをテストします。
データセット | 説明 | ベクトル次元 | ベクトルの数 | クエリ数 | データ量 | 距離式 |
Texmexデータセットとスケール不変特徴変換 (SIFT) アルゴリズムを使用して生成される画像特徴ベクトル。 | 128 | 1,000,000 | 10,000 | 488 MB | L2 | |
Texmexデータセットと胃腸間質腫瘍 (GIST) アルゴリズムを使用して生成される画像特徴ベクトル。 | 960 | 1,000,000 | 1,000 | 3.57 GB | L2 | |
GloVeアルゴリズムをインターネットからのテキストデータに適用することによって生成される単語ベクトル。 | 200 | 1,183,514 | 10,000 | 902 MB | コイン | |
ImageNetトレーニングデータセットを使用してGoogLeNetニューラルネットワークの出力レイヤーから抽出されるベクトル。 | 96 | 9,990,000 | 10,000 | 3.57 GB | コイン | |
Random-s-100-euclidean | ImageNetトレーニングデータセットを使用してGoogLeNetニューラルネットワークの出力レイヤーから抽出されるベクトル。 | 100 | 90,000 | 10,000 | 34 MB | L2 |
手書きの数字のModified National Institute of Standards and Technology (MNIST) データベースからのデータセット。 | 784 | 60,000 | 10,000 | 179 MB | L2 |
テストツールとメソッド
テストサーバーに
tair-pyとhiredisをインストールします。次のコマンドを実行してhiredisをインストールします。
pip install tair hiredisダウンロードと解凍 Ann-benchmarks.
次のコマンドを実行してAnn-benchmarksを解凍します。
tar -zxvf ann-benchmarks.tar.gzのエンドポイント、ポート番号、ユーザー名、およびパスワードを設定します。テアインスタンスの
algos.yamlファイルを作成します。algos.yamlファイルを開き、tairvectorを検索して関連する設定項目を見つけ、base-argsの次のパラメーターを設定します。url: Tairインスタンスのエンドポイント、ユーザー名、パスワード。 形式:
redis:// user:password @ host:port
parallelism: 同時スレッドの数。 デフォルト値: 4。 デフォルト値を使用することを推奨します。
例:
{"url": "redis://testaccount:Rp829dlwa@r-bp18uownec8it5****.redis.rds.aliyuncs.com:6379", "parallelism": 4}を実行します。Run the
run.pyテストを開始するためのスクリプト。重要run.pyスクリプトを実行すると、テスト全体が開始され、インデックスが作成され、インデックスにデータが書き込まれ、結果がクエリされて記録されます。 単一のデータセットでスクリプトを繰り返し実行しないでください。例:
# Run a multi-threaded test by using the Sift-128-euclidean dataset and HNSW indexing algorithm. python run.py --local --runs 3 --algorithm tairvector-hnsw --dataset sift-128-euclidean --batch # Run a multi-threaded test by using the Mnist-784-euclidean dataset and Flat Search indexing algorithm. python run.py --local --runs 3 --algorithm tairvector-flat --dataset mnist-784-euclidean --batch組み込みのwebフロントエンドを使用してテストを実行することもできます。 例:
# Install the Streamlit dependency in advance. pip3 install streamlit # Start the web frontend. Then, you can enter http://localhost:8501 in your browser. streamlit run webrunner.pyを実行します。Run the
data_export.pyスクリプトを作成し、結果をエクスポートします。例:
# Multiple threads. python data_export.py --output out.csv --batch
テスト結果
書き込みパフォーマンス、k-nearest neighbor (kNN) クエリのパフォーマンス、およびメモリ効率のテスト結果に注意を払うことを推奨します。
書き込みパフォーマンス: TairVectorの書き込みパフォーマンスは、書き込みスループットに比例して向上します。
kNNクエリパフォーマンス: 1秒あたりのクエリ数 (QPS) はシステムパフォーマンスを反映し、リコール率は結果の精度を反映します。 典型的には、リコール率が高いほど、QPSは低くなる。 QPS比較は、再現率が同じである場合にのみ有意である。 これに関連して、試験結果は「QPS対s」で示される。 "カーブを思い出してください。 FLATインデックスの場合、リコール率は常に1であるため、QPSのみが表示されます。
メモリ効率: ベクターインデックスのメモリ使用量が少ないほど、TairVectorのパフォーマンスが向上します。
writeとkNNクエリテストの両方に、4つの同時スレッドが含まれます。
この例では、TairVectorのパフォーマンスはfloat32とfloat16のデータ型でテストされます。 デフォルトのデータ型はfloat32です。 HNSWインデックスアルゴリズムのパフォーマンスは、AUTO_GC機能を有効にしてテストされます。
HNSWインデックス
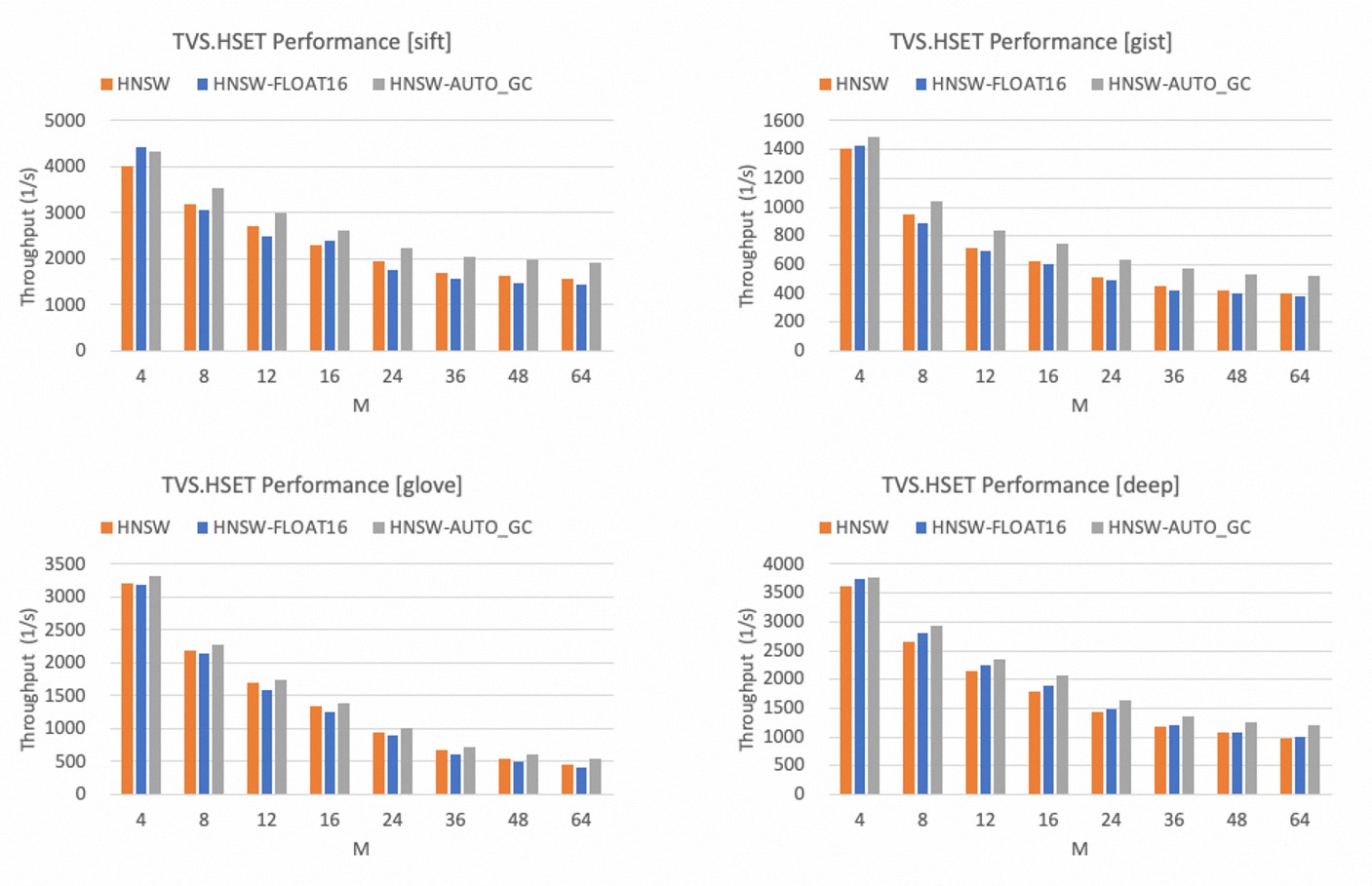
書き込みパフォーマンス
次の図は、ef_constructが500に設定されている場合の、Mパラメータの異なる値でのHNSWインデックス付けアルゴリズムの書き込みパフォーマンスを示しています。 Mパラメータは、グラフインデックス構造内の各レイヤ上の出力ネイバーの最大数を指定する。
HNSWインデクシングアルゴリズムの書き込み性能は、Mパラメータの値に反比例して低下する。
float32データ型と比較して、float16データ型を使用すると、ほとんどの場合、HNSWインデックスアルゴリズムの書き込みパフォーマンスがわずかに低下します。
AUTO_GC機能を有効にすると、HNSWインデックスアルゴリズムの書き込みパフォーマンスが最大30% 向上します。
kNNクエリのパフォーマンス
リコール率とQPSが高いほど、kNNクエリのパフォーマンスは向上します。 したがって、曲線が右上隅に近いほど、HNSWインデックス付けアルゴリズムの性能が向上する。
以下の図は、「QPS対s」を示す。 HNSWインデックスが異なるデータセットで使用されるときの「曲線」を思い出してください。
4つのデータセットすべてで、HNSWインデックスは99% を超える再現率を達成できます。
float32データ型と比較して、float16データ型を使用すると、HNSWインデックスアルゴリズムのパフォーマンスがわずかに低下します。 これら2つのデータ型のパフォーマンスは非常に近いです。
AUTO_GC機能を有効にすると、kNNクエリのパフォーマンスが大幅に低下します。 したがって、大量のデータを削除する場合にのみ、AUTO_GC機能を有効にすることをお勧めします。

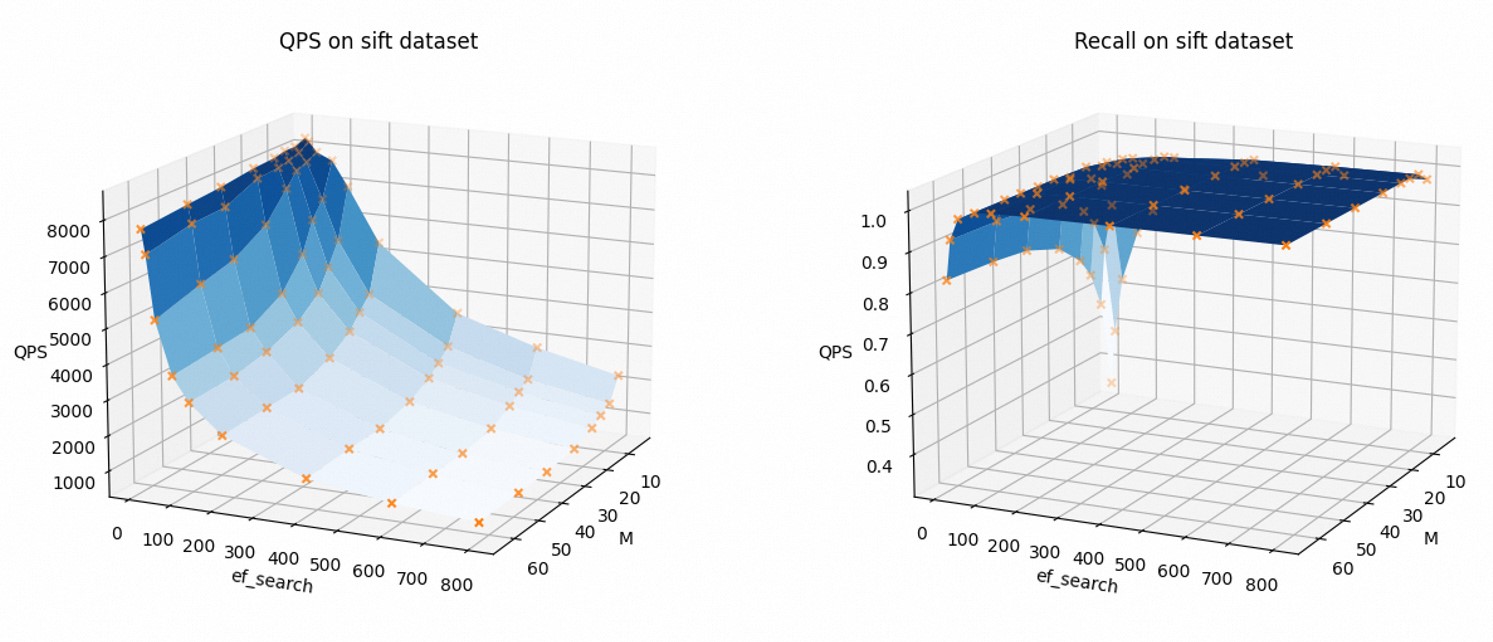
パラメーター設定がkNNクエリのパフォーマンスにどのように影響するかを視覚的に示すために、次の図は、QPSと再現率がMとef_searchの値でどのように変化するかを示しています。 この例では、Sift-128-euclideanデータセットとfloat32データ型が使用され、AUTO_GC機能は無効になっています。
Mおよびef_searchの値が増加するにつれて、QPSは減少し、再現率は増加する。
ビジネス要件に基づいて関連するパラメーターを変更して、kNNクエリのパフォーマンスとリコール率のバランスを取ることができます。
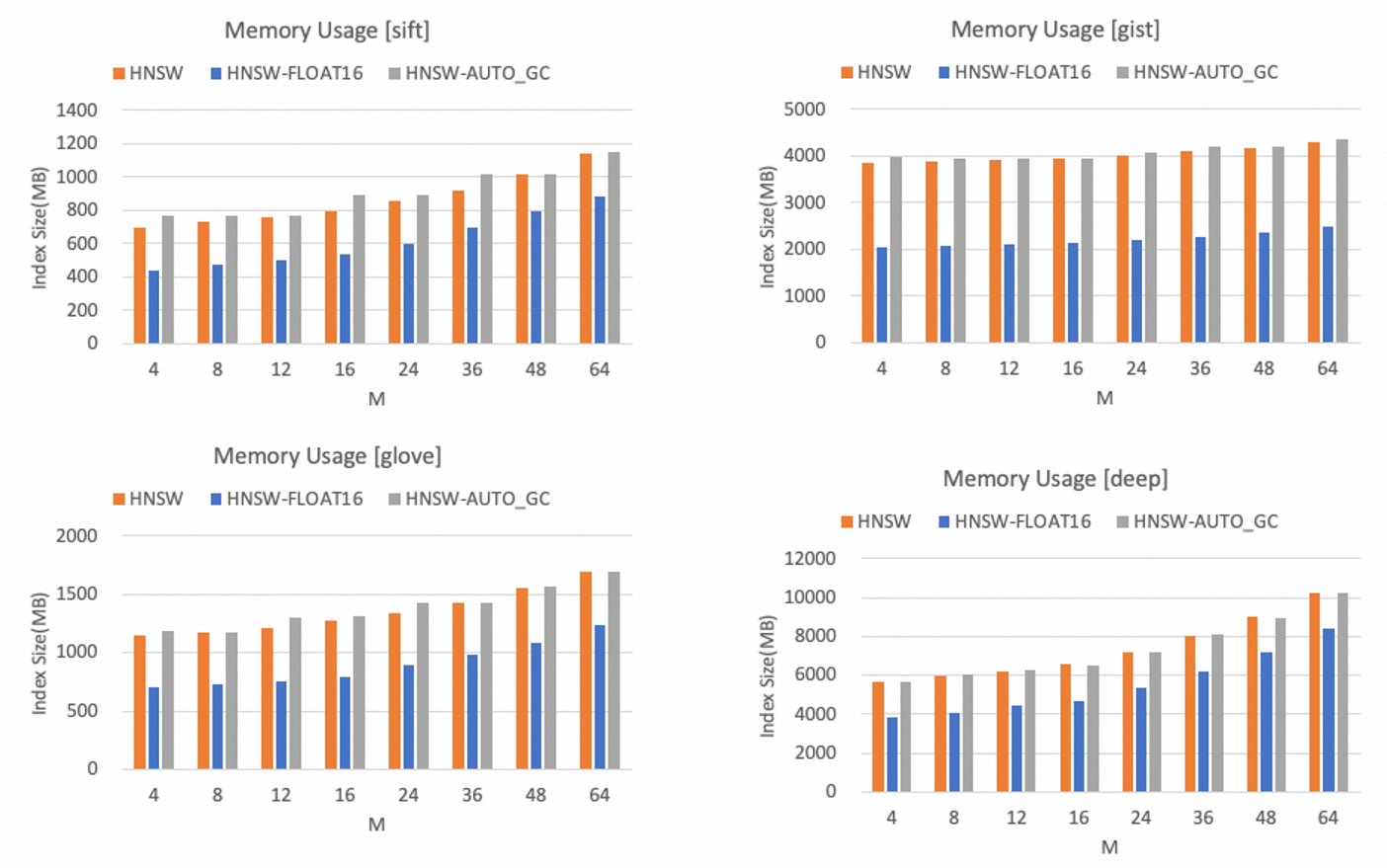
メモリ効率
HNSWインデックスのメモリ使用量は、Mパラメーターの値に比例してのみ増加します。
次の図は、異なるデータセット間のHNSWインデックスのメモリ使用量を示しています。
float32データ型と比較して、float16データ型はメモリ使用量を40% 以上大幅に削減できます。
AUTO_GC機能を有効にすると、メモリ使用量がわずかに増加します。
説明ベクトルの次元とメモリ容量の予算に基づいて、Mパラメーターの適切な値を決定できます。 特定の精度の低下を受け入れることができる場合は、float16データ型を使用してメモリ容量を節約することをお勧めします。
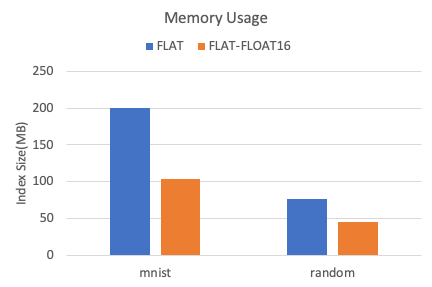
FLATインデックス
書き込みパフォーマンス
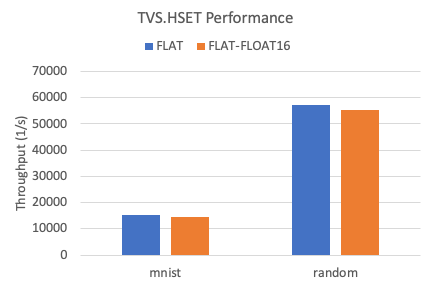
次の図は、2つのデータセット間のFLATインデックスの書き込みスループットを示しています。
float32データ型と比較して、float16データ型を使用すると、FLATインデックスの書き込みパフォーマンスが約5% 低下します。
kNNクエリのパフォーマンス
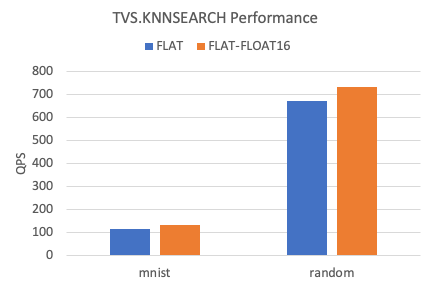
次の図は、2つのデータセット間のFLATインデックスのkNN QPSを示しています。
float32データ型と比較して、float16データ型を使用すると、FLATインデックスのkNNクエリのパフォーマンスが約10% 向上します。
メモリ効率
次の図は、2つのデータセット間のFLATインデックスのメモリ使用量を示しています。
float32データ型と比較して、float16データ型はメモリ使用量を40% 以上削減できます。