アナライザーを使用して、ドキュメントをインデックスに保存できる単語に分解および分割します。 ほとんどの場合、TairSearchの組み込みアナライザーまたはニーズに合ったカスタムアナライザーを使用できます。 このトピックでは、TairSearchアナライザーの使用方法について説明します。
ナビゲーション
内蔵アナライザー | 文字フィルター | Tokenizer | トークンフィルター |
TairSearchアナライザーのワークフロー
TairSearchアナライザーは、文字フィルター、トークナイザー、およびトークンフィルターで構成され、これらは順次適用されます。 文字フィルターとトークンフィルターは空のままにできます。 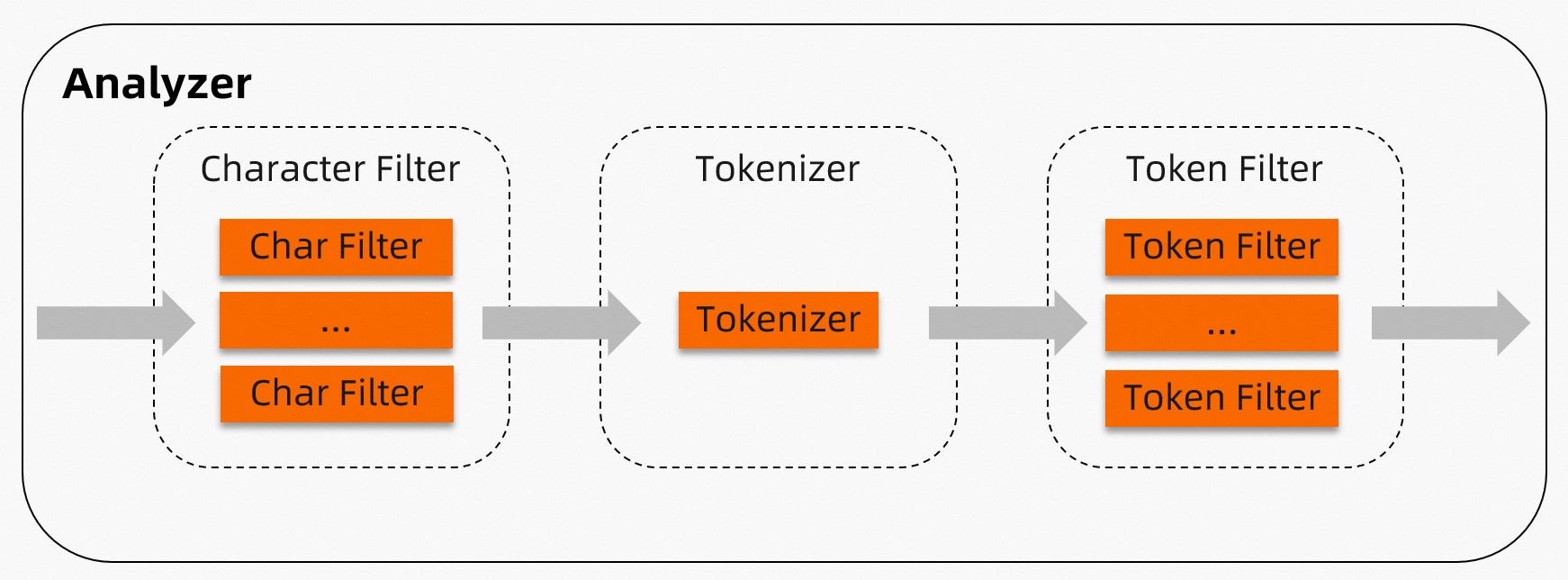 の説明:
の説明:
文字フィルター: ドキュメントを前処理します。 TairSearchアナライザーでは、指定した順序で実行する0個以上の文字フィルターを設定できます。 例えば、文字フィルタは、
"(:"を"happy"に置き換えることができる。Tokenizer: ドキュメントを複数のトークンに分割します。 TairSearchアナライザーごとに指定できるトークナイザーは1つだけです。 たとえば、空白トークナイザーを使用して、
"I am very happy"を["I", "am", "very", "happy"]に分割できます。トークンフィルター: 指定されたトークナイザーによって生成されたトークンを処理します。 TairSearchアナライザーに対して、指定した順序で実行するゼロ以上のトークンフィルターを設定できます。 たとえば、ストップトークンフィルターを使用してストップワードをフィルタリングできます。
内蔵アナライザー
標準
標準アナライザーは、Unicode標準付録 #29で指定されているように、Unicodeテキスト分割アルゴリズムに基づいてドキュメントを分割し、トークンを小文字に変換し、ストップワードを除外します。 アナライザーはほとんどの言語でうまく機能します。
オプションパラメータ:
stopwords: 除外するストップワード。 データ型: ARRAY。 各ストップワードは文字列でなければなりません。 このパラメーターを指定すると、デフォルトのストップワードが上書きされます。 デフォルトの停止ワード:
["a", "an", "and", "are", "as", "at", "be", "but", "by", "for", "if", "in", "into", "is", "it", "no", "not", "of", "on", "or", "such", "that", "the", "their", "then", "there", "these", "they", "this", "to", "was", "will", "with"]max_token_length: トークンに許可される最大文字数。 デフォルト値: 255 最大長を超えるトークンは、指定された最大長に基づいて分割されます。
サンプル設定:
# Default configuration:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"standard"
}
}
}
}
# Use of custom stop words:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"my_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_analyzer":{
"type":"standard",
"max_token_length":10,
"stopwords":[
"memory",
"disk",
"is",
"a"
]
}
}
}
}
}停止
ストップアナライザーは、ドキュメントを任意の文字以外のトークンに分割し、トークンを小文字に変換し、ストップワードを除外します。
オプションパラメータ:
stopwords: 除外するストップワード。 データ型: ARRAY。 各ストップワードは文字列でなければなりません。 このパラメーターを指定すると、デフォルトのストップワードが上書きされます。 デフォルトの停止ワード:
["a", "an", "and", "are", "as", "at", "be", "but", "by", "for", "if", "in", "into", "is", "it", "no", "not", "of", "on", "or", "such", "that", "the", "their", "then", "there", "these", "they", "this", "to", "was", "will", "with"]
サンプル設定:
# Default configuration:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"stop"
}
}
}
}
# Use of custom stop words:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"my_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_analyzer":{
"type":"stop",
"stopwords":[
"memory",
"disk",
"is",
"a"
]
}
}
}
}
}ジーバ
jiebaアナライザーは、中国語のドキュメントに推奨されます。 トレーニング済みまたは指定された辞書に基づいてドキュメントを分割し、英語のトークンを小文字に変換し、ストップワードを除外します。
オプションパラメータ:
userwords: ユーザー定義の単語の辞書。 データ型: ARRAY。 各単語は文字列でなければなりません。 このパラメーターを指定すると、ユーザー定義の単語がデフォルトの辞書に追加されます。 詳しくは、
jiebaのデフォルト辞書。重要jiebaアナライザーには、サイズが20 MBの大きな組み込み辞書があります。 この辞書の単一のコピーのみがjiebaのメモリに保持されます。 この辞書は、jiebaが初めて使用された場合にのみロードされます。 これは、jiebaを使用している間、レイテンシにわずかなジッタを引き起こす可能性があります。
カスタム辞書内の単語には、
\t、\n、、、。
use_hmm: 辞書に含まれていない単語を処理するために隠れマルコフモデル (hmm) を使用するかどうかを指定します。 有効な値: trueおよびfalse。 デフォルト値:true
stopwords: 除外するストップワード。 データ型: ARRAY。 各ストップワードは文字列でなければなりません。 このパラメーターを指定すると、デフォルトのストップワードが上書きされます。 詳しくは、
jiebaのデフォルトのストップワード。
サンプル設定:
# Default configuration:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"jieba"
}
}
}
}
# Use of custom stop words:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"my_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_analyzer":{
"type":"jieba",
"stopwords":[
"memory",
"disk",
"is",
"a"
],"userwords":[
"Redis",
"open-source",
"flexible"
],
"use_hmm":true
}
}
}
}
}IK
IKアナライザーは中国語のドキュメントに使用され、Alibaba Cloud ElasticsearchのIKアナライザープラグインと互換性があります。 IKは、ik_max_wordモードとik_smartモードをサポートしています。 ik_max_wordモードでは、IKはすべての可能なトークンを識別する。 ik_smartモードでは、ikはik_max_wordモードの結果をフィルタリングして、最も可能なトークンを識別します。
コンポーネント:
Tokenizer: IK
オプションパラメータ:
stopwords: 除外するストップワード。 データ型: ARRAY。 各ストップワードは文字列でなければなりません。 このパラメーターを指定すると、デフォルトのストップワードが上書きされます。 デフォルトの停止ワード:
["a", "an", "and", "are", "as", "at", "be", "but", "by", "for", "if", "in", "into", "is", "it", "no", "not", "of", "on", "or", "such", "that", "the", "their", "then", "there", "these", "they", "this", "to", "was", "will", "with"]userwords: ユーザー定義の単語の辞書。 データ型: ARRAY。 各単語は文字列でなければなりません。 このパラメーターを指定すると、ユーザー定義の単語がデフォルトの辞書に追加されます。 詳しくは、
IKのデフォルト辞書。quantifiers: ユーザー定義のquantifiersのディクショナリ。 データ型: ARRAY。 このパラメーターを指定すると、ユーザー定義の量子がデフォルトのディクショナリに追加されます。 詳しくは、
IKのデフォルトの数量化ディクショナリ。enable_lowercase: 大文字を小文字に変換するかどうかを指定します。 有効な値: trueおよびfalse。 デフォルト値:true
重要カスタム辞書に大文字が含まれている場合は、ドキュメントを分割する前に変換が実行されるため、このパラメーターをfalseに設定します。
サンプル設定:
# Default configuration:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"ik_smart"
},
"f1":{
"type":"text",
"analyzer":"ik_max_word"
}
}
}
}
# Use of custom stop words:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"my_ik_smart_analyzer"
},
"f1":{
"type":"text",
"analyzer":"my_ik_max_word_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_ik_smart_analyzer":{
"type":"ik_smart",
"stopwords":[
"memory",
"disk",
"is",
"a"
],"userwords":[
"Redis",
"open-source",
"flexible"
],
"quantifiers":[
"ns"
],
"enable_lowercase":false
},
"my_ik_max_word_analyzer":{
"type":"ik_max_word",
"stopwords":[
"memory",
"disk",
"is",
"a"
],"userwords":[
"Redis",
"open-source",
"flexible"
],
"quantifiers":[
"ns"
],
"enable_lowercase":false
}
}
}
}
}Pattern
パターンアナライザーは、指定された正規表現に基づいてドキュメントを分割します。 正規表現と一致する単語は、区切り文字として使用されます。 たとえば、"aaa" 正規表現を使用して "bbbaaaccc" を分割すると、分割結果は "bbb" と "ccc" になります。 同時に、小文字パラメーターを指定してトークンを小文字に変換し、ストップワードを除外することができます。
オプションパラメータ:
pattern: 正規表現。 正規表現と一致する単語は、区切り文字として使用されます。 デフォルト値:
\W +正規表現の構文の詳細については、『GitHub』をご参照ください。stopwords: 除外するストップワード。 ストップワードのディクショナリは配列でなければならず、各ストップワードは文字列でなければなりません。 ストップワードを指定すると、デフォルトのストップワードが上書きされます。 デフォルトの停止ワード:
["a", "an", "and", "are", "as", "at", "be", "but", "by", "for", "if", "in", "into", "is", "it", "no", "not", "of", "on", "or", "such", "that", "the", "their", "then", "there", "these", "they", "this", "to", "was", "will", "with"]lowercase: トークンを小文字に変換するかどうかを指定します。 有効な値: trueおよびfalse。 デフォルト値:true
flags: 正規表現が大文字と小文字を区別するかどうかを指定します。 デフォルトでは、このパラメーターは空のままです。これは、正規表現が大文字と小文字を区別することを示します。 CASE_INSENSITIVEの値は、正規表現が大文字と小文字を区別しないことを示します。
サンプル設定:
# Default configuration:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"pattern"
}
}
}
}
# Use of custom stop words:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"my_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_analyzer":{
"type":"pattern",
"pattern":"\\'([^\\']+)\\'",
"stopwords":[
"aaa",
"@"
],
"lowercase":false,
"flags":"CASE_INSENSITIVE"
}
}
}
}
}ホワイトスペース
空白アナライザーは、空白文字に遭遇するたびにドキュメントをトークンに分割します。
コンポーネント:
Tokenizer: 空白
オプションパラメータ: なし
サンプル設定:
# Default configuration:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"whitespace"
}
}
}
}シンプル
シンプルアナライザーは、文書を任意の文字以外の文字でトークンに分割し、トークンを小文字に変換します。
コンポーネント:
Tokenizer: 小文字
オプションパラメータ: なし
サンプル設定:
# Default configuration:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"simple"
}
}
}
}キーワード
キーワードアナライザは、文書を分割せずに文書をトークンに変換する。
コンポーネント:
Tokenizer: キーワード
オプションパラメータ: なし
サンプル設定:
# Default configuration:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"keyword"
}
}
}
}言語
言語アナライザーは、中国語、アラビア語、cjk、ブラジル、チェコ語、ドイツ語、ギリシャ語、ペルシャ語、フランス語、オランダ語、ロシア語で利用できます。
オプションパラメータ:
stopwords: 除外するストップワード。 ストップワードのディクショナリは配列でなければならず、各ストップワードは文字列でなければなりません。 ストップワードを指定すると、デフォルトのストップワードが上書きされます。 さまざまな言語のデフォルトのストップワードの詳細については、このトピックの付録4: 組み込み言語アナライザーのデフォルトのストップワードを参照してください。
説明中国語アナライザーのストップワードは変更できません。
stem_exclusion: 語幹が抽出されない単語。 たとえば、
"apples"の茎を抽出すると、結果は"apple"になります。 デフォルトでは、このパラメータは空のままです。 stem_exclusionパラメーターの値は配列で、各単語は文字列である必要があります。説明このパラメータは、ブラジル、ドイツ、フランス、およびオランダのアナライザでのみサポートされています。
サンプル設定:
# Default configuration:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"arabic"
}
}
}
}
# Use of custom stop words:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"my_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_analyzer":{
"type":"german",
"stopwords":[
"ein"
],
"stem_exclusion":[
"speicher"
]
}
}
}
}
}カスタムアナライザー
カスタムTairSearchアナライザーは、文字フィルター、トークナイザー、およびトークンフィルターの組み合わせとして定義されます。 ニーズに応じて、対応するchar_filter、トークナイザー、およびフィルターパラメーターを指定できます。
メソッド: analyzerパラメーターを、propertiesのmy_custom_analyzerなどのカスタムアナライザーに設定します。 設定でmy_custom_analyzerカスタムアナライザーを設定します。
下表に、各パラメーターを説明します。
パラメーター | 説明 |
タイプ | カスタムアナライザー。 このパラメーターは必須で、customに設定されています。 |
char_filter | 文字をフィルターしてドキュメントを前処理します。 デフォルトでは、このパラメーターは空のままです。これは、TairSearchがドキュメントを前処理しないことを示します。 このパラメーターはオプションで、マッピングにのみ設定できます。 フィールド:
|
tokenizer | トークナイザー。 This parameter is required. 単一のトークナイザーのみを指定できます。 有効な値: whitespace、小文字、standard、classic、letter、keyword、jieba、pattern、ik_max_word、ik_smart 詳細については、このトピックの「付録2: サポートされるトークナイザー」を参照してください。 |
フィルター | トークンを小文字に変換し、ストップワードを除外します。 このパラメーターはオプションです。 このパラメーターには複数の値を指定できます。 デフォルトでは、このパラメーターは空のままです。これは、Tairsearchがトークンを処理しないことを示します。 有効な値: classic、elision、小文字、snowball、stop、asciifolding、length、arabic_normalization、persian_normalization。 詳細については、このトピックの「付録3: サポートされるトークンフィルター」を参照してください。 |
サンプル設定:
# Configure the custom analyzer:
# In this example, emoticons and conjunctions are specified as the character filters. In addition, the whitespace tokenizer and the lowercase and stop token filters are specified.
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"my_custom_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_custom_analyzer":{
"type":"custom",
"tokenizer":"whitespace",
"filter":[
"lowercase",
"stop"
],
"char_filter": [
"emoticons",
"conjunctions"
]
}
},
"char_filter":{
"emoticons":{
"type":"mapping",
"mappings":[
":) => _happy_",
":( => _sad_"
]
},
"conjunctions":{
"type":"mapping",
"mappings":[
"&=>and"
]
}
}
}
}
}付録1: サポートされている文字フィルター
マッピング文字フィルター
マッピングでキーと値のペアを設定できます。 このように、キーが識別されると、キーは対応する値に置き換えられる。 たとえば、":) =>_ happy_" は、":)" が "_happy_" に置き換えられることを示します。 複数の文字フィルターを指定できます。
パラメーター:
mappings: このパラメーターは必須です。 データ型: ARRAY。 各要素には
=>を含める必要があります。 例:"&=> and"
サンプル設定:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"my_custom_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_custom_analyzer":{
"type":"custom",
"tokenizer":"standard",
"char_filter": [
"emoticons"
]
}
},
"char_filter":{
"emoticons":{
"type":"mapping",
"mappings":[
":) => _happy_",
":( => _sad_"
]
}
}
}
}
}付録2: サポートされるトークナイザー
空白
空白トークナイザーは、空白文字に遭遇するたびにドキュメントをトークンに分割します。
オプションパラメータ:
max_token_length: トークンに許可される最大文字数。 デフォルト値: 255 最大長を超えるトークンは、指定された最大長に基づいて分割されます。
サンプル設定:
# Default configuration:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"my_custom_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_custom_analyzer":{
"type":"custom",
"tokenizer":"whitespace"
}
}
}
}
}
# Custom configuration:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"my_custom_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_custom_analyzer":{
"type":"custom",
"tokenizer":"token1"
}
},
"tokenizer":{
"token1":{
"type":"whitespace",
"max_token_length":2
}
}
}
}
}標準
標準トークナイザは、Unicode standard Annex #29で指定されているように、Unicode Text Segmentationアルゴリズムに基づいてドキュメントを分割します。 トークナイザーはほとんどの言語でうまく機能します。
オプションパラメータ:
max_token_length: トークンに許可される最大文字数。 デフォルト値: 255 最大長を超えるトークンは、指定された最大長に基づいて分割されます。
サンプル設定:
# Default configuration:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"my_custom_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_custom_analyzer":{
"type":"custom",
"tokenizer":"standard"
}
}
}
}
}
# Custom configuration:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"my_custom_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_custom_analyzer":{
"type":"custom",
"tokenizer":"token1"
}
},
"tokenizer":{
"token1":{
"type":"standard",
"max_token_length":2
}
}
}
}
}クラシック
クラシックトークナイザーは、英語の文法に基づいてドキュメントを分割し、次のセクションで説明するように、頭字語、会社名、電子メールアドレス、およびIPアドレスを特別な方法で処理します。
句読点でドキュメントを分割し、句読点を削除します。 空白のない期間 (.) は句読点とは見なされません。 たとえば、
red.appleは分割されず、red.[space] appleはredとappleに分割されます。ハイフンでドキュメントを分割します。 トークンに数字が含まれている場合、トークンは製品番号として解釈され、分割されません。
電子メールアドレスとホスト名をトークンとして識別します。
オプションパラメータ:
max_token_length: トークンに許可される最大文字数。 デフォルト値: 255 最大長を超えるトークンはスキップされます。
サンプル設定:
# Default configuration:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"my_custom_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_custom_analyzer":{
"type":"custom",
"tokenizer":"classic"
}
}
}
}
}
# Custom configuration:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"my_custom_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_custom_analyzer":{
"type":"custom",
"tokenizer":"token1"
}
},
"tokenizer":{
"token1":{
"type":"classic",
"max_token_length":2
}
}
}
}
}手紙
文字トークナイザは、文書を任意の文字以外の文字でトークンに分割し、ヨーロッパ言語でうまく機能します。
サンプル設定:
# Default configuration:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"my_custom_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_custom_analyzer":{
"type":"custom",
"tokenizer":"letter"
}
}
}
}
}小文字
小文字のトークナイザーは、文書を任意の文字以外の文字でトークンに分割し、すべてのトークンを小文字に変換します。 小文字のトークナイザーの分割結果は、文字トークナイザーと小文字のトークンフィルターの組み合わせの分割結果と同じです。 対照的に、小文字のトークナイザーはドキュメントを1回だけトラバースするため、時間がかかりません。
サンプル設定:
# Default configuration:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"my_custom_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_custom_analyzer":{
"type":"custom",
"tokenizer":"lowercase"
}
}
}
}
}キーワード
キーワードトークナイザは、文書を分割せずに文書をトークンに変換する。 通常、キーワードトークナイザは、ドキュメントを小文字に変換するために、小文字のトークンフィルタなどのトークンフィルタと共に使用される。
サンプル設定:
# Default configuration:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"my_custom_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_custom_analyzer":{
"type":"custom",
"tokenizer":"keyword"
}
}
}
}
}ジーバ
中国語にはjieba tokenizerをお勧めします。 トレーニング済みまたは指定された辞書に基づいてドキュメントを分割します。
オプションパラメータ:
userwords: ユーザー定義の単語の辞書。 データ型: ARRAY。 各単語は文字列でなければなりません。 このパラメーターを指定すると、ユーザー定義の単語がデフォルトの辞書に追加されます。 詳しくは、
jiebaのデフォルト辞書。重要カスタム辞書内の単語には、
\t、\n、、、。use_hmm: 辞書に含まれていない単語を処理するために隠れマルコフモデル (hmm) を使用するかどうかを指定します。 有効な値: trueおよびfalse。 デフォルト値:true
サンプル設定:
# Default configuration:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"my_custom_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_custom_analyzer":{
"type":"custom",
"tokenizer":"jieba"
}
}
}
}
}
# Custom configuration:
{
"mappings":{
"properties":{
"f1":{
"type":"text",
"analyzer":"my_custom_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_custom_analyzer":{
"type":"custom",
"tokenizer":"token1"
}
},
"tokenizer":{
"token1":{
"type":"jieba",
"userwords":[
"Redis",
"open-source",
"flexible"
],
"use_hmm":true
}
}
}
}
}パターン
パターントークナイザーは、指定された正規表現に基づいてドキュメントを分割します。 正規表現と一致する単語は、区切り文字として使用されるか、トークンとして識別されます。
オプションパラメータ:
pattern: 正規表現。 デフォルト値:
\W +詳細については、『GitHub』をご参照ください。group: 指定された正規表現を区切り文字またはトークンとして使用します。 デフォルト値: -1。 有効な値:
-1: 指定された正規表現の一致した単語を区切り文字として使用します。 たとえば、
"aaa"正規表現を使用して"bbbaaaccc"を分割した場合、分割結果は"bbb"と"ccc"になります。0または0を超える整数: 正規表現によって一致する単語をトークンとして識別します。 値0は、TairSearchが正規表現全体で単語と一致することを示します。 1または1を超える整数の値は、TairSearchが正規表現内の対応するキャプチャグループによって単語と一致することを示します。 たとえば、正規表現「
a(b +)c」を使用して「abbbcdefabc」を分割するとします。groupが0に設定されている場合、分割結果は"abbbc"と"abc"になります。groupが1に設定されている場合、「a(b +)c」の最初のキャプチャグループb +を使用して単語を照合します。 この場合、分割結果は"bbb"と"b"です。
flags: 指定された正規表現が大文字と小文字を区別するかどうかを指定します。 デフォルトでは、このパラメーターは空のままです。これは、正規表現が大文字と小文字を区別することを示します。 CASE_INSENSITIVEの値は、指定された正規表現が大文字と小文字を区別しないことを示します。
サンプル設定:
# Default configuration:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"my_custom_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_custom_analyzer":{
"type":"custom",
"tokenizer":"pattern"
}
}
}
}
}
# Custom configuration:
{
"mappings":{
"properties":{
"f1":{
"type":"text",
"analyzer":"my_custom_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_custom_analyzer":{
"type":"custom",
"tokenizer":"pattern_tokenizer"
}
},
"tokenizer":{
"pattern_tokenizer":{
"type":"pattern",
"pattern":"AB(A(\\w+)C)",
"flags":"CASE_INSENSITIVE",
"group":2
}
}
}
}
}IK
IKトークナイザーはドキュメントを中国語で分割します。 IKは、ik_max_wordモードとik_smartモードをサポートしています。 ik_max_wordモードでは、IKはすべての可能なトークンを識別する。 ik_smartモードでは、ikはik_max_wordモードの結果をフィルタリングして、最も可能なトークンを識別します。
オプションパラメータ:
stopwords: 除外するストップワード。 データ型: ARRAY。 各ストップワードは文字列でなければなりません。 このパラメーターを指定すると、デフォルトのストップワードが上書きされます。 デフォルトの停止ワード:
["a", "an", "and", "are", "as", "at", "be", "but", "by", "for", "if", "in", "into", "is", "it", "no", "not", "of", "on", "or", "such", "that", "the", "their", "then", "there", "these", "they", "this", "to", "was", "will", "with"]userwords: ユーザー定義の単語の辞書。 データ型: ARRAY。 各単語は文字列でなければなりません。 このパラメーターを指定すると、ユーザー定義の単語がデフォルトの辞書に追加されます。 詳しくは、
IKのデフォルト辞書。quantifiers: ユーザー定義のquantifiersのディクショナリ。 データ型: ARRAY。 このパラメーターを指定すると、ユーザー定義の量子がデフォルトのディクショナリに追加されます。 詳しくは、
IKのデフォルトの数量化ディクショナリ。enable_lowercase: 大文字を小文字に変換するかどうかを指定します。 有効な値: trueおよびfalse。 デフォルト値:true
重要カスタム辞書に大文字が含まれている場合は、ドキュメントを分割する前に変換が実行されるため、このパラメーターをfalseに設定します。
サンプル設定:
# Default configuration:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"my_custom_ik_smart_analyzer"
},
"f1":{
"type":"text",
"analyzer":"my_custom_ik_max_word_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_custom_ik_smart_analyzer":{
"type":"custom",
"tokenizer":"ik_smart"
},
"my_custom_ik_max_word_analyzer":{
"type":"custom",
"tokenizer":"ik_max_word"
}
}
}
}
}
# Custom configuration:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"my_custom_ik_smart_analyzer"
},
"f1":{
"type":"text",
"analyzer":"my_custom_ik_max_word_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_custom_ik_smart_analyzer":{
"type":"custom",
"tokenizer":"my_ik_smart_tokenizer"
},
"my_custom_ik_max_word_analyzer":{
"type":"custom",
"tokenizer":"my_ik_max_word_tokenizer"
}
},
"tokenizer":{
"my_ik_smart_tokenizer":{
"type":"ik_smart",
"userwords":[
"The tokenizer for the Chinese language",
"The custom stop words"
],
"stopwords":[
"about",
"test"
],
"quantifiers":[
"ns"
],
"enable_lowercase":false
},
"my_ik_max_word_tokenizer":{
"type":"ik_max_word",
"userwords":[
"The tokenizer for the Chinese language",
"The custom stop words"
],
"stopwords":[
"about",
"test"
],
"quantifiers":[
"ns"
],
"enable_lowercase":false
}
}
}
}
}付録3: サポートされるトークンフィルター
クラシック
クラシックトークンフィルターは、トークンの末尾と頭字語のピリオド (.) を除外します。 例えば、図は図に変換される。
サンプル設定:
# Default configuration:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"my_custom_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_custom_analyzer":{
"type":"custom",
"tokenizer":"classic",
"filter":["classic"]
}
}
}
}
}elision
削除トークンフィルタは、トークンの先頭から指定された削除を削除します。 このフィルタは主にフランス語に適用されます。
オプションパラメータ:
articles: 指定されたelisions。 このパラメーターは、カスタム設定を指定する場合に必要です。 データ型: ARRAY。 配列内の各要素は文字列でなければなりません。 デフォルト値:
["l", "m", "t", "qu", "n", "s", "j"]このパラメーターを指定すると、デフォルト値が上書きされます。articles_case: 大文字と小文字を区別するかどうかを指定します。 このパラメーターはオプションです。 有効な値: trueおよびfalse。 デフォルト値:false
サンプル設定:
# Default configuration:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"my_custom_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_custom_analyzer":{
"type":"custom",
"tokenizer":"whitespace",
"filter":["elision"]
}
}
}
}
}
# Custom configuration:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"my_custom_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_custom_analyzer":{
"type":"custom",
"tokenizer":"whitespace",
"filter":["elision_filter"]
}
},
"filter":{
"elision_filter":{
"type":"elision",
"articles":["l", "m", "t", "qu", "n", "s", "j"],
"articles_case":true
}
}
}
}
}小文字
小文字のトークンフィルターは、トークンを小文字に変換します。
オプションパラメータ:
language: トークンフィルターが使用する言語。 有効な値: greekとrussian。 このパラメーターを指定しない場合、トークンフィルターは英語を使用します。
サンプル設定:
# Default configuration:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"my_custom_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_custom_analyzer":{
"type":"custom",
"tokenizer":"whitespace",
"filter":["lowercase"]
}
}
}
}
}
# Custom configuration:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"my_custom_greek_analyzer"
},
"f1":{
"type":"text",
"analyzer":"my_custom_russian_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_custom_greek_analyzer":{
"type":"custom",
"tokenizer":"whitespace",
"filter":["greek_lowercase"]
},
"my_custom_russian_analyzer":{
"type":"custom",
"tokenizer":"whitespace",
"filter":["russian_lowercase"]
}
},
"filter":{
"greek_lowercase":{
"type":"lowercase",
"language":"greek"
},
"russian_lowercase":{
"type":"lowercase",
"language":"russian"
}
}
}
}
}雪玉
スノーボールトークンフィルタは、すべてのトークンから抽出します。 例えば、トークンフィルタは、catからcatを抽出する。
オプションパラメータ:
language: トークンフィルターが使用する言語。 有効な値: english、german、french、dutch。 デフォルト値: english。
サンプル設定:
# Default configuration:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"my_custom_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_custom_analyzer":{
"type":"custom",
"tokenizer":"whitespace",
"filter":["snowball"]
}
}
}
}
}
# Custom configuration:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"my_custom_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_custom_analyzer":{
"type":"custom",
"tokenizer":"standard",
"filter":["my_filter"]
}
},
"filter":{
"my_filter":{
"type":"snowball",
"language":"english"
}
}
}
}
}停止
ストップトークンフィルターは、指定されたストップワードの配列に基づいて、トークンからストップワードを削除します。
オプションパラメータ:
stopwords: ストップワードの配列。 各ストップワードは文字列でなければなりません。 このパラメーターを指定すると、デフォルトのストップワードが上書きされます。 デフォルトの停止ワード:
["a", "an", "and", "are", "as", "at", "be", "but", "by", "for", "if", "in", "into", "is", "it", "no", "not", "of", "on", "or", "such", "that", "the", "their", "then", "there", "these", "they", "this", "to", "was", "will", "with"]ignoreCase: ストップワードが大文字と小文字を区別するかどうかを指定します。 有効な値: trueおよびfalse。 デフォルト値:false
サンプル設定:
# Default configuration:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"my_custom_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_custom_analyzer":{
"type":"custom",
"tokenizer":"whitespace",
"filter":["stop"]
}
}
}
}
}
# Custom configuration:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"my_custom_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_custom_analyzer":{
"type":"custom",
"tokenizer":"standard",
"filter":["stop_filter"]
}
},
"filter":{
"stop_filter":{
"type":"stop",
"stopwords":[
"the"
],
"ignore_case":true
}
}
}
}
}asciifolding
拡張トークンフィルタは、Basic Latin Unicodeブロックに含まれていないアルファベット文字、数字文字、および記号文字をASCII相当物に変換します。 たとえば、このトークンフィルターは é をeに変換します。
サンプル設定:
# Default configuration:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"my_custom_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_custom_analyzer":{
"type":"custom",
"tokenizer":"standard",
"filter":["asciifolding"]
}
}
}
}
}長さ
長さトークンフィルタは、指定された文字長よりも短いまたは長いトークンを除去する。
オプションパラメータ:
min: トークンに許可される最小文字数。 データ型: INTEGER。 デフォルト値:0
max: トークンに許可される最大文字数。 データ型: INTEGER。 デフォルト値: 2 ^ 31 - 1。
サンプル設定:
# Default configuration:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"my_custom_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_custom_analyzer":{
"type":"custom",
"tokenizer":"whitespace",
"filter":["length"]
}
}
}
}
}
# Custom configuration:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"my_custom_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_custom_analyzer":{
"type":"custom",
"tokenizer":"whitespace",
"filter":["length_filter"]
}
},
"filter":{
"length_filter":{
"type":"length",
"max":5,
"min":2
}
}
}
}
}正規化
正規化トークンフィルタは、特定の言語の特定の文字を正規化する。 有効な値: arabic_normalizationおよびpersian_normalization。 このトークンフィルターは、標準のトークナイザーと一緒に使用することを推奨します。
サンプル設定:
# Default configuration:
{
"mappings":{
"properties":{
"f0":{
"type":"text",
"analyzer":"my_arabic_analyzer"
},
"f1":{
"type":"text",
"analyzer":"my_persian_analyzer"
}
}
},
"settings":{
"analysis":{
"analyzer":{
"my_arabic_analyzer":{
"type":"custom",
"tokenizer":"arabic",
"filter":["arabic_normalization"]
},
"my_persian_analyzer":{
"type":"custom",
"tokenizer":"arabic",
"filter":["persian_normalization"]
}
}
}
}
}付録4: 異なる言語の組み込み言語アナライザーのデフォルトの停止語
アラビア语
["من","ومن","منها","منه","في","وفي","فيها","فيه","و","ف","ثم","او","أو","ب","بها","به","ا","أ","اى","اي","أي","أى","لا","ولا","الا","ألا","إلا","لكن","ما","وما","كما","فما","عن","مع","اذا","إذا","ان","أن","إن","انها","أنها","إنها","انه","أنه","إنه","بان","بأن","فان","فأن","وان","وأن","وإن","التى","التي","الذى","الذي","الذين","الى","الي","إلى","إلي","على","عليها","عليه","اما","أما","إما","ايضا","أيضا","كل","وكل","لم","ولم","لن","ولن","هى","هي","هو","وهى","وهي","وهو","فهى","فهي","فهو","انت","أنت","لك","لها","له","هذه","هذا","تلك","ذلك","هناك","كانت","كان","يكون","تكون","وكانت","وكان","غير","بعض","قد","نحو","بين","بينما","منذ","ضمن","حيث","الان","الآن","خلال","بعد","قبل","حتى","عند","عندما","لدى","جميع"]cjk
["with","will","to","this","there","then","the","t","that","such","s","on","not","no","it","www","was","is","","into","their","or","in","if","for","by","but","they","be","these","at","are","as","and","of","a"]ブラジル
["uns","umas","uma","teu","tambem","tal","suas","sobre","sob","seu","sendo","seja","sem","se","quem","tua","que","qualquer","porque","por","perante","pelos","pelo","outros","outro","outras","outra","os","o","nesse","nas","na","mesmos","mesmas","mesma","um","neste","menos","quais","mediante","proprio","logo","isto","isso","ha","estes","este","propios","estas","esta","todas","esses","essas","toda","entre","nos","entao","em","eles","qual","elas","tuas","ela","tudo","do","mesmo","diversas","todos","diversa","seus","dispoem","ou","dispoe","teus","deste","quer","desta","diversos","desde","quanto","depois","demais","quando","essa","deles","todo","pois","dele","dela","dos","de","da","nem","cujos","das","cujo","durante","cujas","portanto","cuja","contudo","ele","contra","como","com","pelas","assim","as","aqueles","mais","esse","aquele","mas","apos","aos","aonde","sua","e","ao","antes","nao","ambos","ambas","alem","ainda","a"]チェコ
["a","s","k","o","i","u","v","z","dnes","cz","tímto","budeš","budem","byli","jseš","muj","svým","ta","tomto","tohle","tuto","tyto","jej","zda","proc","máte","tato","kam","tohoto","kdo","kterí","mi","nám","tom","tomuto","mít","nic","proto","kterou","byla","toho","protože","asi","ho","naši","napište","re","což","tím","takže","svých","její","svými","jste","aj","tu","tedy","teto","bylo","kde","ke","pravé","ji","nad","nejsou","ci","pod","téma","mezi","pres","ty","pak","vám","ani","když","však","neg","jsem","tento","clánku","clánky","aby","jsme","pred","pta","jejich","byl","ješte","až","bez","také","pouze","první","vaše","která","nás","nový","tipy","pokud","muže","strana","jeho","své","jiné","zprávy","nové","není","vás","jen","podle","zde","už","být","více","bude","již","než","který","by","které","co","nebo","ten","tak","má","pri","od","po","jsou","jak","další","ale","si","se","ve","to","jako","za","zpet","ze","do","pro","je","na","atd","atp","jakmile","pricemž","já","on","ona","ono","oni","ony","my","vy","jí","ji","me","mne","jemu","tomu","tem","temu","nemu","nemuž","jehož","jíž","jelikož","jež","jakož","nacež"]ドイツ人
["wegen","mir","mich","dich","dir","ihre","wird","sein","auf","durch","ihres","ist","aus","von","im","war","mit","ohne","oder","kein","wie","was","es","sie","mein","er","du","daß","dass","die","als","ihr","wir","der","für","das","einen","wer","einem","am","und","eines","eine","in","einer"]greek
["ο","η","το","οι","τα","του","τησ","των","τον","την","και","κι","κ","ειμαι","εισαι","ειναι","ειμαστε","ειστε","στο","στον","στη","στην","μα","αλλα","απο","για","προσ","με","σε","ωσ","παρα","αντι","κατα","μετα","θα","να","δε","δεν","μη","μην","επι","ενω","εαν","αν","τοτε","που","πωσ","ποιοσ","ποια","ποιο","ποιοι","ποιεσ","ποιων","ποιουσ","αυτοσ","αυτη","αυτο","αυτοι","αυτων","αυτουσ","αυτεσ","αυτα","εκεινοσ","εκεινη","εκεινο","εκεινοι","εκεινεσ","εκεινα","εκεινων","εκεινουσ","οπωσ","ομωσ","ισωσ","οσο","οτι"]ペルシャ語
["انان","نداشته","سراسر","خياه","ايشان","وي","تاكنون","بيشتري","دوم","پس","ناشي","وگو","يا","داشتند","سپس","هنگام","هرگز","پنج","نشان","امسال","ديگر","گروهي","شدند","چطور","ده","و","دو","نخستين","ولي","چرا","چه","وسط","ه","كدام","قابل","يك","رفت","هفت","همچنين","در","هزار","بله","بلي","شايد","اما","شناسي","گرفته","دهد","داشته","دانست","داشتن","خواهيم","ميليارد","وقتيكه","امد","خواهد","جز","اورده","شده","بلكه","خدمات","شدن","برخي","نبود","بسياري","جلوگيري","حق","كردند","نوعي","بعري","نكرده","نظير","نبايد","بوده","بودن","داد","اورد","هست","جايي","شود","دنبال","داده","بايد","سابق","هيچ","همان","انجا","كمتر","كجاست","گردد","كسي","تر","مردم","تان","دادن","بودند","سري","جدا","ندارند","مگر","يكديگر","دارد","دهند","بنابراين","هنگامي","سمت","جا","انچه","خود","دادند","زياد","دارند","اثر","بدون","بهترين","بيشتر","البته","به","براساس","بيرون","كرد","بعضي","گرفت","توي","اي","ميليون","او","جريان","تول","بر","مانند","برابر","باشيم","مدتي","گويند","اكنون","تا","تنها","جديد","چند","بي","نشده","كردن","كردم","گويد","كرده","كنيم","نمي","نزد","روي","قصد","فقط","بالاي","ديگران","اين","ديروز","توسط","سوم","ايم","دانند","سوي","استفاده","شما","كنار","داريم","ساخته","طور","امده","رفته","نخست","بيست","نزديك","طي","كنيد","از","انها","تمامي","داشت","يكي","طريق","اش","چيست","روب","نمايد","گفت","چندين","چيزي","تواند","ام","ايا","با","ان","ايد","ترين","اينكه","ديگري","راه","هايي","بروز","همچنان","پاعين","كس","حدود","مختلف","مقابل","چيز","گيرد","ندارد","ضد","همچون","سازي","شان","مورد","باره","مرسي","خويش","برخوردار","چون","خارج","شش","هنوز","تحت","ضمن","هستيم","گفته","فكر","بسيار","پيش","براي","روزهاي","انكه","نخواهد","بالا","كل","وقتي","كي","چنين","كه","گيري","نيست","است","كجا","كند","نيز","يابد","بندي","حتي","توانند","عقب","خواست","كنند","بين","تمام","همه","ما","باشند","مثل","شد","اري","باشد","اره","طبق","بعد","اگر","صورت","غير","جاي","بيش","ريزي","اند","زيرا","چگونه","بار","لطفا","مي","درباره","من","ديده","همين","گذاري","برداري","علت","گذاشته","هم","فوق","نه","ها","شوند","اباد","همواره","هر","اول","خواهند","چهار","نام","امروز","مان","هاي","قبل","كنم","سعي","تازه","را","هستند","زير","جلوي","عنوان","بود"]フランス语
["ô","être","vu","vous","votre","un","tu","toute","tout","tous","toi","tiens","tes","suivant","soit","soi","sinon","siennes","si","se","sauf","s","quoi","vers","qui","quels","ton","quelle","quoique","quand","près","pourquoi","plus","à","pendant","partant","outre","on","nous","notre","nos","tienne","ses","non","qu","ni","ne","mêmes","même","moyennant","mon","moins","va","sur","moi","miens","proche","miennes","mienne","tien","mien","n","malgré","quelles","plein","mais","là","revoilà","lui","leurs","","toutes","le","où","la","l","jusque","jusqu","ils","hélas","ou","hormis","laquelle","il","eu","nôtre","etc","est","environ","une","entre","en","son","elles","elle","dès","durant","duquel","été","du","voici","par","dont","donc","voilà","hors","doit","plusieurs","diverses","diverse","divers","devra","devers","tiennes","dessus","etre","dessous","desquels","desquelles","ès","et","désormais","des","te","pas","derrière","depuis","delà","hui","dehors","sans","dedans","debout","vôtre","de","dans","nôtres","mes","d","y","vos","je","concernant","comme","comment","combien","lorsque","ci","ta","nບnmoins","lequel","chez","contre","ceux","cette","j","cet","seront","que","ces","leur","certains","certaines","puisque","certaine","certain","passé","cependant","celui","lesquelles","celles","quel","celle","devant","cela","revoici","eux","ceci","sienne","merci","ce","c","siens","les","avoir","sous","avec","pour","parmi","avant","car","avait","sont","me","auxquels","sien","sa","excepté","auxquelles","aux","ma","autres","autre","aussi","auquel","aujourd","au","attendu","selon","après","ont","ainsi","ai","afin","vôtres","lesquels","a"]オランダ語
["andere","uw","niets","wil","na","tegen","ons","wordt","werd","hier","eens","onder","alles","zelf","hun","dus","kan","ben","meer","iets","me","veel","omdat","zal","nog","altijd","ja","want","u","zonder","deze","hebben","wie","zij","heeft","hoe","nu","heb","naar","worden","haar","daar","der","je","doch","moet","tot","uit","bij","geweest","kon","ge","zich","wezen","ze","al","zo","dit","waren","men","mijn","kunnen","wat","zou","dan","hem","om","maar","ook","er","had","voor","of","als","reeds","door","met","over","aan","mij","was","is","geen","zijn","niet","iemand","het","hij","een","toen","in","toch","die","dat","te","doen","ik","van","op","en","de"]ロシア
["а","без","более","бы","был","была","были","было","быть","в","вам","вас","весь","во","вот","все","всего","всех","вы","где","да","даже","для","до","его","ее","ей","ею","если","есть","еще","же","за","здесь","и","из","или","им","их","к","как","ко","когда","кто","ли","либо","мне","может","мы","на","надо","наш","не","него","нее","нет","ни","них","но","ну","о","об","однако","он","она","они","оно","от","очень","по","под","при","с","со","так","также","такой","там","те","тем","то","того","тоже","той","только","том","ты","у","уже","хотя","чего","чей","чем","что","чтобы","чье","чья","эта","эти","это","я"]