RDS for PostgreSQL は、強力なベクトル類似性検索を可能にする pgvector 拡張機能をサポートしています。この拡張機能は、高次元ベクトルを迅速かつ容易に取得するための新しいデータ型を提供します。
背景情報
RDS for PostgreSQL は pgvector 拡張機能をサポートしており、ベクトルデータの保存、ベクトル類似性検索の実行、AI プロダクトへのデータサポートの提供が可能です。
pgvector 拡張機能には、次の特徴があります:
ベクトルデータを保存し、クエリするための vector データ型をサポートします。
L2 距離 (ユークリッド)、コサイン類似度、内積など、複数の距離尺度を用いた完全および近似最近傍 (ANN) 検索をサポートします。インデックス構築では、HNSW インデックス、並列 IVFFlat インデックス、要素ごとのベクトル乗算、L1 距離関数、合計集約をサポートします。
最大 16,000 ディメンションのベクトルの作成と、最大 2,000 ディメンションのベクトルに対するインデックスの構築をサポートします。
概念と実装の原則
エンベディング
エンベディングとは、高次元データを低次元の表現にマッピングするプロセスです。機械学習や自然言語処理では、エンベディングは離散的なシンボルやオブジェクトを連続ベクトル空間内の点として表現するためによく使用されます。
自然言語処理において、単語埋め込みは一般的な手法です。単語を実数ベクトルにマッピングすることで、コンピューターがテキストをより良く理解し、処理できるようになります。この手法は、ベクトル空間内で単語間の意味的および文法的な関係を表現します。
実装原則
エンベディングは、テキスト、イメージ、音声、動画などのソースからの情報を多次元ベクトルデータに変換します。
pgvector 拡張機能は vector データ型を提供し、RDS for PostgreSQL データベースがベクトルデータを保存できるようにします。
pgvector 拡張機能は、保存されたベクトルデータに対して完全および近似最近傍検索を実行できます。
3つのオブジェクト (リンゴ、バナナ、ネコ) をデータベースに格納し、pgvector を使用してそれらの類似度を計算する必要があるとします。次のステップに従います:
まず、エンベディングを使用して3つのオブジェクトをベクトルに変換します。次の例では、2次元エンベディングを使用します:
Apple: embedding[1,1] Banana: embedding[1.2,0.8] Cat: embedding[6,0.4]ベクトルデータをデータベースに保存します。2次元ベクトルデータをデータベースに保存する方法の詳細については、「使用例」をご参照ください。
2次元平面上では、3つのオブジェクトは次のように分散されます:
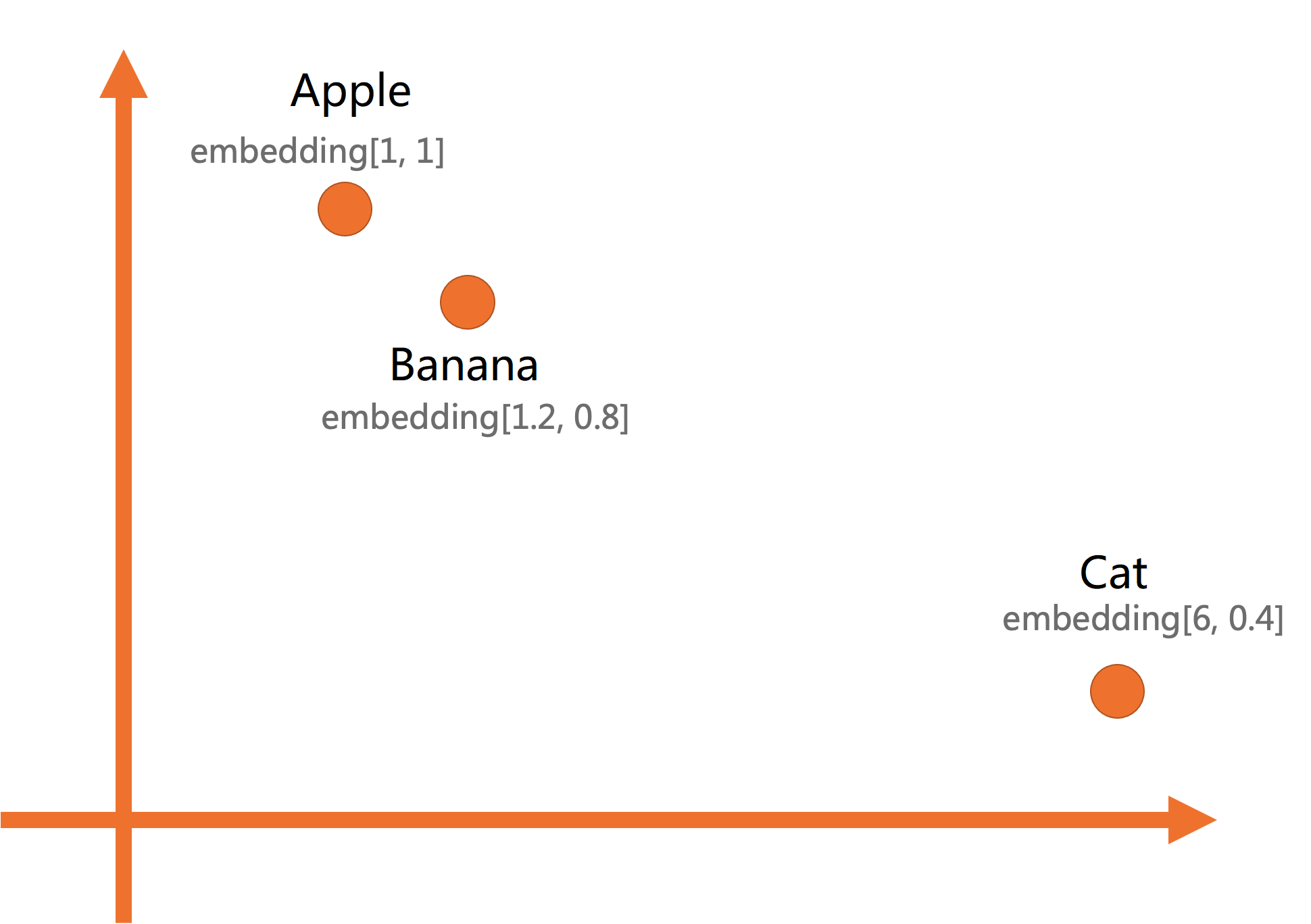
リンゴとバナナはどちらも果物なので、ベクトル空間ではより近くに位置します。ネコは異なる種類のオブジェクトなので、より遠くに位置します。
果物の属性 (色、産地、味など) をさらに詳細に定義できます。各属性は1つのディメンションを表します。より多くのディメンションを使用することで、より細かい分類が可能になり、より正確な検索結果を得ることができます。
シナリオ
ベクトルデータの保存
ベクトル類似性検索の実行
前提条件
RDS for PostgreSQL インスタンスは、次の要件を満たす必要があります:
インスタンスが PostgreSQL 14 以降のメジャーバージョンを実行していること。
インスタンスのマイナーエンジンバージョンが 20230430 以降であること。PostgreSQL 17 を実行しているインスタンスの場合、マイナーエンジンバージョンは 20241030 以降である必要があります。
説明メジャーバージョンのアップグレードまたはマイナーエンジンバージョンの更新方法の詳細については、「メジャーエンジンバージョンのアップグレード」または「マイナーエンジンバージョンの更新」をご参照ください。
RDS for PostgreSQL インスタンスに対して特権アカウントが作成されていること。詳細については、「アカウントの作成」をご参照ください。
拡張機能の管理
コンソールでの拡張機能の管理
拡張機能のインストール
[RDS インスタンス] ページに移動します。上部のナビゲーションバーで、インスタンスが配置されているリージョンを選択します。次に、インスタンスの ID をクリックします。
左側のナビゲーションウィンドウで、[プラグイン管理] をクリックします。
[プラグインマーケットプレイス] タブで、下にスクロールして vector 拡張機能を見つけ、[インストール] をクリックします。

または、[プラグインの管理] タブで vector 拡張機能を検索し、[操作] 列の [インストール] をクリックします。
表示されるダイアログボックスで、ターゲットデータベースと特権アカウントを選択し、[インストール] をクリックします。
インスタンスのステータスが [メンテナンス中] から [実行中] に変わると、拡張機能はインストールされています。
拡張機能の更新とアンインストール
[プラグインの管理] ページの [インストール済みプラグイン] タブで、ターゲットの拡張機能を見つけ、[操作] 列の [バージョンのアップグレード] をクリックします。
説明[操作] 列に [バージョンのアップグレード] ボタンが表示されていない場合、拡張機能は最新です。
[プラグインの管理] ページの [インストール済みプラグイン] タブで、ターゲットの拡張機能を見つけ、[操作] 列の [アンインストール] をクリックします。
SQL コマンドを使用した拡張機能の管理
特権アカウントのみが次のコマンドを実行できます。特権アカウントを作成するには、「アカウントの作成」をご参照ください。
拡張機能の作成
CREATE EXTENSION IF NOT EXISTS vector;拡張機能の削除
DROP EXTENSION vector;拡張機能の更新
ALTER EXTENSION vector UPDATE [ TO new_version ]説明new_version を pgvector のターゲットバージョンに設定します。pgvector の最新バージョンと機能の詳細については、pgvector 公式ドキュメントをご参照ください。
使用例
以下に、pgvector の簡単な使用例を示します。詳細については、pgvector 公式ドキュメントをご参照ください。
ターゲットデータベースで、テーブル作成権限を持つアカウントを使用して、エンベディングを保存するための `items` という名前のテーブルを作成します。
CREATE TABLE items ( id bigserial PRIMARY KEY, item text, embedding vector(2) );説明この例では2次元ベクトルを使用しています。pgvector 拡張機能は、最大 16,000 ディメンションのベクトルの作成をサポートしています。
テーブルにベクトルデータを挿入します。
INSERT INTO items (item, embedding) VALUES ('Apple', '[1, 1]'), ('Banana', '[1.2, 0.8]'), ('Cat', '[6, 0.4]');コサイン距離演算子
<=>を使用して、バナナとリンゴ、およびバナナとネコの間の距離を計算します。SELECT item, embedding <=> '[1.2, 0.8]' AS cosine_distance FROM items ORDER BY cosine_distance;説明この例では、
<=>演算子はコサイン距離を直接計算します。距離が小さいほど、類似度が高くなります。L2 距離演算子
<->または内積演算子<#>を使用して類似度を計算することもできます。
結果の例:
item | cosine_distance ------+---------------------- Banana | 0 Apple | 0.019419362524530137 Cat | 0.13289443670962842結果の例について:
バナナの結果は 0 です。これは完全一致 (距離が 0) を示します。
リンゴの結果は 0.019 です。これは、リンゴがバナナに非常に近く、類似度が高いことを示します。
ネコの結果は 0.133 です。これは、ネコがバナナから遠く、類似度が低いことを示します。
説明アプリケーションで適切な類似度のしきい値を設定して、類似度の低い結果を除外できます。
類似度クエリのパフォーマンスを向上させるために、pgvector はベクトルデータに対するインデックスの構築をサポートしています。次の文を実行して、embedding フィールドにインデックスを構築します。
HNSW インデックスを作成する
CREATE INDEX ON items USING hnsw (embedding vector_cosine_ops) WITH (m = 16, ef_construction = 64);パラメーターの説明:
パラメーター
説明
m
HNSW インデックスを構築する際に、各レイヤーの各ノードの最大近傍数。
値を大きくするとグラフの密度が高まり、通常は取得率が向上します。ただし、インデックスの構築とクエリに必要な時間も増加します。
ef_construction
HNSW インデックスを構築する際の候補セットのサイズ。これは、最適な接続を選択するために検索プロセス中に保持する候補ノードの数です。
値を大きくすると通常は取得率が向上しますが、インデックスの構築とクエリに必要な時間も増加します。
IVF インデックスを作成する
CREATE INDEX ON items USING ivfflat (embedding vector_cosine_ops) WITH (lists = 100);パラメーターの説明:
パラメータ/値
説明
items
インデックスが追加されるテーブルの名前。
embedding
インデックスが追加される列の名前。
vector_cosine_ops
vector インデックスメソッドで指定されたアクセスメソッド。
コサイン類似度検索には、
vector_cosine_opsを使用します。L2 距離には、
vector_l2_opsを使用します。内積類似度には、
vector_ip_opsを使用します。
lists = 100
lists パラメーターは、データセットを分割するリストの数を指定します。値が大きいほど、データセットはより多く分割され、各サブセットのサイズは比較的小さくなり、インデックスのクエリ速度は速くなります。ただし、lists の値が大きくなるにつれて、クエリの取得率が低下する可能性があります。
説明取得率とは、情報取得または分類タスクにおいて、正しく取得または分類されたサンプルの数を、関連するサンプルの総数で割った比率です。取得率は、システムがすべての関連サンプルを見つける能力を測定するものであり、重要な評価メトリックです。
インデックスの構築には大量のメモリが必要です。lists パラメーターの値が 2000 を超えると、
ERROR: memory required is xxx MB, maintenance_work_mem is xxx MBエラーが発生します。ベクトルデータのインデックスを構築するには、より大きな maintenance_work_mem の値を設定する必要があります。この値が大きすぎると、インスタンスはメモリ不足 (OOM) エラーのリスクが高くなります。パラメーターの設定方法については、「インスタンスパラメーターの設定」をご参照ください。特定のアプリケーションのニーズに合わせて、クエリ速度と取得率のバランスを取るために lists パラメーターの値を調整する必要があります。
次の2つの方法のいずれかを使用して、ivfflat.probes パラメーターを設定できます。このパラメーターは、インデックスで検索するリストの数を指定します。ivfflat.probes の値を大きくすると、より多くのリストを検索することでクエリの取得率が向上します。
セッションレベル
SET ivfflat.probes = 10;トランザクションレベル
BEGIN; SET LOCAL ivfflat.probes = 10; SELECT ... COMMIT;
ivfflat.probes の値が大きいほど、クエリの取得率は向上しますが、クエリ速度は低下します。アプリケーションの要件とデータセットの特性に基づいて、最適なクエリパフォーマンスと取得率を達成するために、lists と ivfflat.probes の値を調整する必要がある場合があります。
説明ivfflat.probes の値がインデックス作成時に指定された lists の値と等しい場合、クエリはベクトルインデックスを無視して全表スキャンを実行するため、クエリのパフォーマンスが低下する可能性があります。
パフォーマンスデータ
ベクトルデータのインデックスを構築する際には、データ量とアプリケーションシナリオに基づいて、クエリ速度と取得率のバランスを取る必要があります。関連するパフォーマンステストの詳細については、以下をご参照ください: