PolarDB-Xには、ルールベースのオプティマイザとコストベースのオプティマイザがあり、SQLクエリの論理実行プランを最適化して物理実行プランを生成するのに役立ちます。 ルールベースのオプティマイザは、SQL書き換えと呼ばれます。 コストベースのオプティマイザは、Plan Enumeratorと呼ばれます。 このトピックでは、クエリオプティマイザの仕組みと、SQLクエリで使用されるリレーショナル代数演算子について説明します。
- The syntax parser parses the SQL text to an abstract syntax tree (AST).
- The syntax tree is converted to a logical execution plan based on relational algebra operators.
- The optimizers optimize the logical execution plan to generate a physical execution plan.
- The executor executes the physical execution plan to retrieve the query result and returns the query result to the client.
関係代数演算子
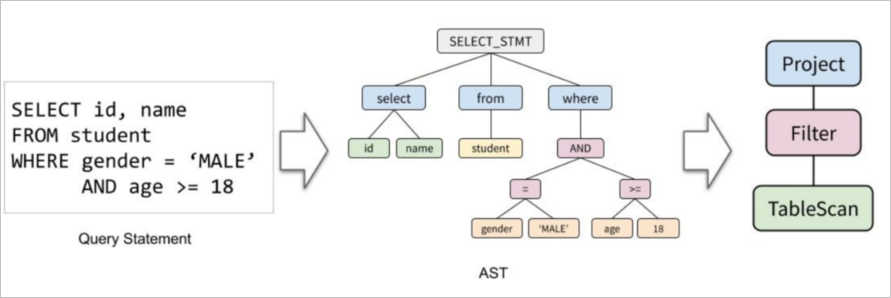
データベースシステムでは、SQLクエリは、通常、関係代数演算子からなるツリーとして表される。 SQLクエリでは、次のタイプの演算子を使用できます。
- プロジェクト演算子は、SELECT操作の実行に使用される関数を含め、SELECT操作を記述するために使用されます。
- フィルタ演算子は、WHERE条件を記述するために使用される。
- 結合演算子は、Join条件を記述するために使用される。 join演算子に対応する物理演算子には、HashJoin、BKAJoin、Nested-Loop Join、およびSortMergeJoinが含まれます。
- 集計演算子は、GROUP BY条件と集計関数を記述するために使用されます。 集計演算子に対応する物理演算子には、HashAggとSortAggが含まれます。
- ソート演算子は、ORDER BYおよびLIMIT条件を記述するために使用されます。 ソート演算子に対応する物理演算子には、TopNとMemSortがあります。
たとえば、次のコードは、SQLクエリを実行するために実行されるSQL文を提供します。
SELECT l_orderkey, sum(l_extendedprice *(1 - l_discount)) AS収益
顧客、注文、LINEITEMから
c_mktsegment = 'AUTOMOBILE'
とc_custkey = o_custkey
とl_orderkey = o_orderkey
およびo_orderdate <''1995-03-13'
およびl_shipdate > '1995-03-13'
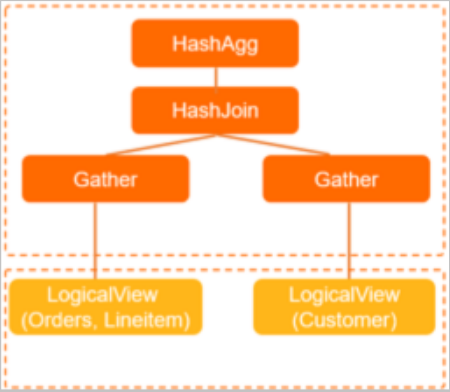
グループBY l_orderkey; EXPLAINステートメントを実行してPolarDB-Xで実行プランを照会すると、次の情報が返されます。
HashAgg(group="l_orderkey", revenue="SUM(*)")
HashJoin(condition="o_custkey = c_custkey", type="inner")
収集 (concurrent=true)
LogicalView(tables="ORDERS_[0-7],LINEITEM_[0-7]", shardCount=8, sql="SELECT 'ORDERS'.'o_custkey', 'LINEITEM'.'l_orderkey', ('LINEITEM'.'l_extendedprice' *? -'LINEITEM'.'l_discount') AS 'x' FROM 'ORDERS' AS 'ORDERS' INNER JOIN 'LINEITEM' AS 'LINEITEM' ON ((('ORDERS'.'o_orderkey' = 'LINEITEM'.'_) 'LINEIDE.'?'__(')' ('ORRRSDEIRDEIDEIDEIDEIDERS') ')'? '?'_(''__) ''
収集 (concurrent=true)
LogicalView(tables="CUSTOMER_[0-7]" 、shardCount=8、sql="SELECT 'c_custkey' FROM 'CUSTOMER' AS 'CUSTOMER' WHERE ('c_mktsegment' = ?)") ASTを使用した実行計画を次の図に示します。
SQLの書き換え
SQL文がSQL書き換えによって処理されると、そのSQL文の論理実行プランが別の論理実行プランに書き換えられる。 SQL書き換えでは、最適化のために複数のヒューリスティックルールがSQL文に適用されます。 このように、SQL書き換えはルールベースのオプティマイザとして使用されます。
SQL文がSQL書き換えで処理されると、次の操作が実行されます。
- サブクエリのネスト解除。 ネストされたサブクエリは、セミジョイン演算子または同様の演算子を使用する演算に変換され、その後の最適化を容易にします。たとえば、演算子をApsaraDB RDS for MySQLにプッシュダウンしたり、PolarDB-Xで実行するアルゴリズムを選択したりします。 次の例では、Inサブクエリは半結合演算子を使用する操作に変換され、次にPolarDB-Xで実行するために物理ハッシュ半結合演算子を使用する操作に変換されます。
> select id from t1 where id IN (select id from t2 wher e t2.name = 'hello'); SemiHashJoin(condition="id = id", type="semi") 収集 (concurrent=true) LogicalView(tables="t1", shardCount=2, sql="SELECT 'id' FROM 't1' AS 't1'") 収集 (concurrent=true) LogicalView(tables="t2_[0-3]", shardCount=4, sql="SELECT 'id' FROM 't2' AS 't2' WHERE ('name' = ?)") - オペレータpushdownオペレーターは押し下げられます。 オペレーターのプッシュダウンは重要です。 PolarDB-Xは、オペレータプッシュダウンのための以下の組み込み最適化ルールを提供します。
最適化ルール 説明 予測プッシュダウンまたは列の剪定 フィルターおよびプロジェクト演算子をApsaraDB RDS for MySQLにプッシュして実行し、不要な行および列を除外します。 クラスタリングに参加 結合操作のその後のプッシュダウンを容易にするために、シャーディングメソッドとシャードキーの等価条件に基づいて結合操作を再ソートおよびクラスタ化します。 プッシュダウンに参加する 特定の条件を満たす結合操作をApsaraDB RDS for MySQLにプッシュダウンして実行します。 集約プッシュダウン 各集計操作をFinalAgg演算子とLocalAgg演算子を使用する操作に分割し、LocalAgg演算子をApsaraDB RDS for MySQLにプッシュダウンします。 プッシュダウンの並べ替え 各ソート操作をMergeSortおよびLocalSort演算子を使用する操作に分割し、LocalSort演算子をApsaraDB RDS for MySQLにプッシュダウンします。 クエリのプッシュダウンの詳細については、「プッシュダウンと書き換えクエリ」をご参照ください。
計画列挙子
Plan Enumeratorは、SQL書き換えによって生成された受け取った論理実行プランに基づいて、最終的な物理実行プランを提供します。 Plan Enumeratorは、事前定義されたコストモデルを使用して、複数の実行可能なプランからコストが最小のクエリプランを選択します。 SQL書き換えによって生成された実行プランは、SQLステートメントの元の実行プランよりも良い場合も悪い場合もあります。 Plan Enumeratorは、演算子を使用して2つの実行計画のコストを比較し、コストの少ない実行計画を選択します。 このように、Plan Enumeratorはコストベースのオプティマイザとして使用されます。
以下の項目は、Plan Enumeratorのコアコンポーネントです。
- 統計値
- カーディナリティの推定
- 変換ルール
- コストモデル
- スペース検索エンジンを計画する
SQL文がPlan Enumeratorによって処理されると、次の操作が実行されます。
- 検索エンジンは、変換ルールを使用して論理実行プランを変換し、物理実行プランの検索空間を構築します。
- Plan Enumeratorは、コストモデルを使用して、検索空間内の各実行プランのコストを推定します。 次に、Plan Enumeratorは、コストが最も低い物理実行プランを選択します。
- コスト推定の間、濃度推定コンポーネントは、各テーブルおよび各列についての統計情報に基づいて、入力行の数、選択率、および各オペレータについての他の情報を推定する。 そして、推定された情報をオペレータのコストモデルに提供して、各実行計画のコストを推定する。