永続バッファープール (PBP) は、クラスターが予期せずシャットダウンまたは再起動する前に存在していた共有バッファープールを使用できるようにする機能です。
適用範囲
この機能は、以下のバージョンの PolarDB for PostgreSQL で利用できます。
PostgreSQL 14 (マイナーエンジンバージョン 2.0.14.5.2.0 以降)
PostgreSQL 11 (マイナーエンジンバージョン 2.0.11.2.1.0 以降)
コンソールでマイナーエンジンバージョン番号を表示するか、SHOW polardb_version; 文を実行することで確認できます。ご利用のクラスターがバージョン要件を満たしていない場合は、マイナーエンジンバージョンをアップグレードできます。
背景情報
PolarDB for PostgreSQL または クラスターのメモリは、共有バッファープール、動的共有メモリエリア、プロセスプライベートメモリの 3 つの部分で構成されています。
共有バッファープール:クラスターの起動時に事前に割り当てられる共有メモリの大きなセグメントです。オフセットによって、さまざまな機能モジュールの使用範囲が決定されます。
動的共有メモリエリア:プロセス間の並列計算を実装するために設計された PostgreSQL の共有メモリエリアです。動的に拡張できます。
プロセスグローバルエリアは、プロセスがその操作に使用するメモリエリアです。このエリアは、次の 2 つの部分で構成されています。
メモリコンテキスト
ロジックによって直接制御されるメモリ
次の図は、メモリがどのように分割されるかを示しています。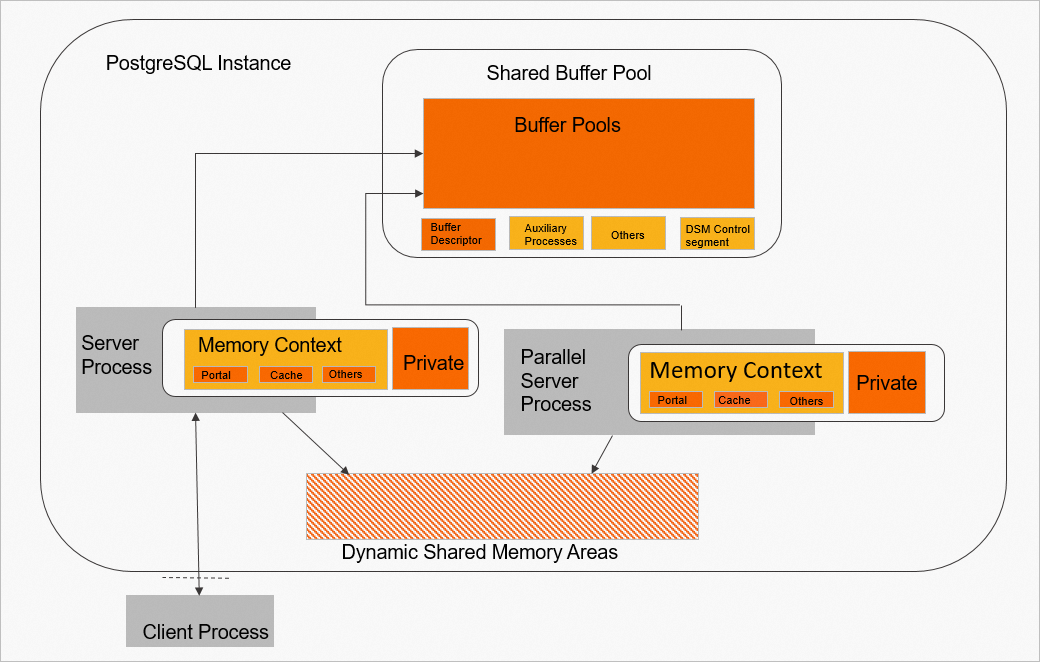
PolarDB for PostgreSQL または クラスターでは、共有バッファープールが最も多くのメモリを使用し、パフォーマンスに直接影響します。ネイティブの PostgreSQL では、クラスターが再起動したり、予期せずシャットダウンしたりすると、共有バッファープールはクリアされ、再初期化されます。クラスターが再起動して障害回復状態に入ると、先行書き込みログ (WAL) に基づいてデータページが変更されます。これにはデータの再読み込みや変更が必要となり、クラスターの可用時間に影響します。さらに、共有バッファープールを再初期化すると、ビジネスサービスで必要なデータが再読み込みされ、深刻なパフォーマンスのジッターが発生します。
これらの問題を解決するために、PolarDB for PostgreSQL と は PBP 機能を追加しました。この機能により、クラスターは予期せぬシャットダウンや再起動の前に共有バッファープールを使用できます。この機能には、次の利点があります。
障害回復時間を短縮し、システムの可用性を向上させます。
ノードがクラスターから離脱する前後で、パフォーマンスに大きなジッターは発生しません。
仕組み
PolarDB for PostgreSQL と は、共有バッファープールの一部を Pod レベルのライフサイクルを持つ PBP に変換します。パフォーマンス上の理由から、PolarDB for PostgreSQL と は、主にバッファープールとバッファー記述子を PBP に配置します。他のメモリコンポーネントは、インスタンスレベルのライフサイクルを維持します。
Pod レベルのライフサイクル:PolarDB for PostgreSQL と は Kubernetes 上にデプロイされます。Pod レベルのライフサイクルを持つ共有メモリは、クラスターがシャットダウンしても破棄されません。
インスタンスレベルのライフサイクル:クラスターレベルの共有メモリで、クラスターがシャットダウンしたり、異常シャットダウン後に再起動したりするとクリアされます。
次の図は、メモリがどのように分割されるかを示しています。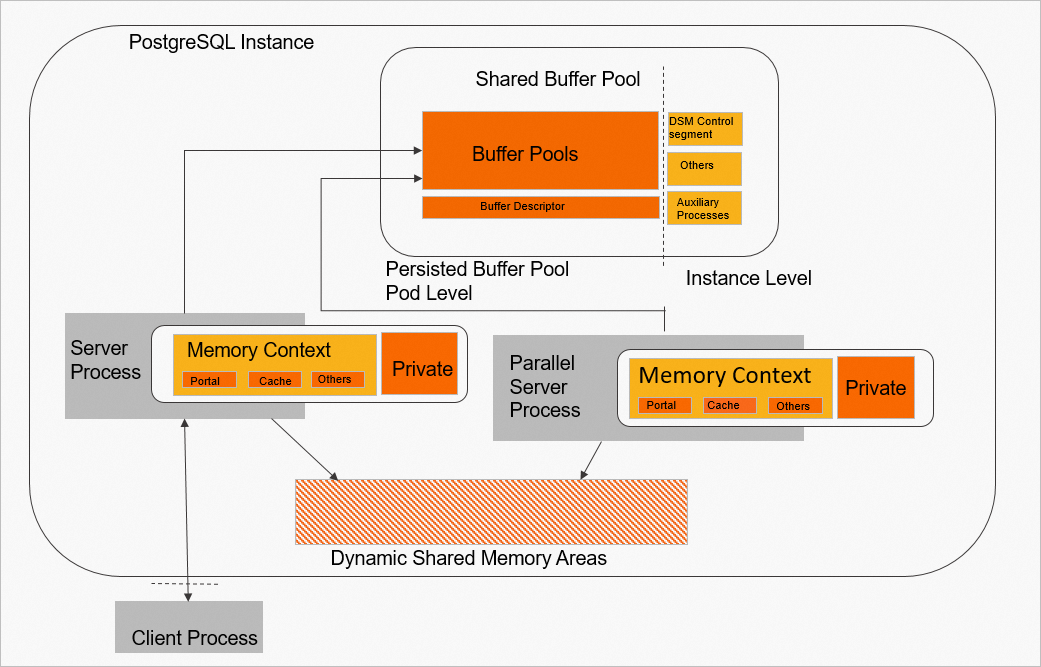
PBP の可用性に影響するメトリック
クラスターがシャットダウンする前の PBP は、すべてのシナリオで使用できるわけではありません。クラスターの起動時に、次のような状況では PBP を使用できません。
クラスターの仕様が変更され、異なるサイズのバッファープールが必要になった場合。
現在の PBP は、このクラスターで作成されたものではありません。
現在の PBP 内のコントロール情報は無効です。
PBP 全体の可用性を確認することに加えて、PBP 内の各ページも可用性を確認する必要があります。次のような状況では、ページを使用できません。
ページに未コミットのトランザクションが含まれている場合。
ページの記述子情報が無効な場合。
ページには無効なログシーケンス番号 (LSN) が含まれています。
ページのプロパティが正しくないか、無効な場合。
次の図は、PBP の可用性に影響するメトリックを示しています。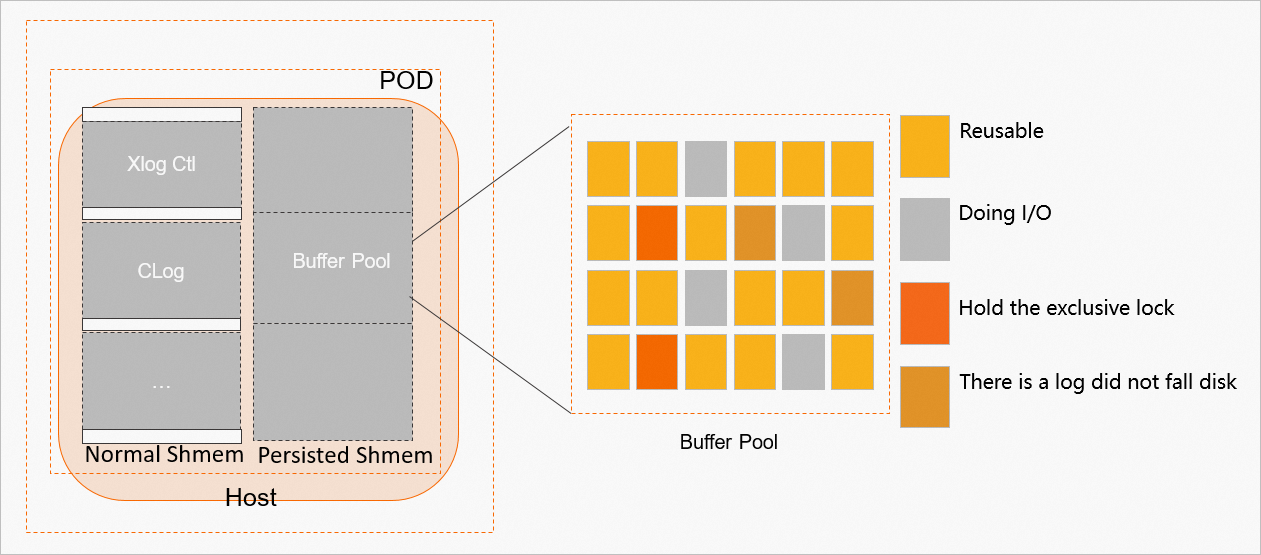
PBP のパフォーマンス上の利点
PBP を使用すると、データベースは再起動前のバッファープールを使用できます。これにより、キャッシュされたデータを迅速に使用して、回復シナリオとビジネスシナリオの両方でパフォーマンスを向上させることができます。次の図に例を示します。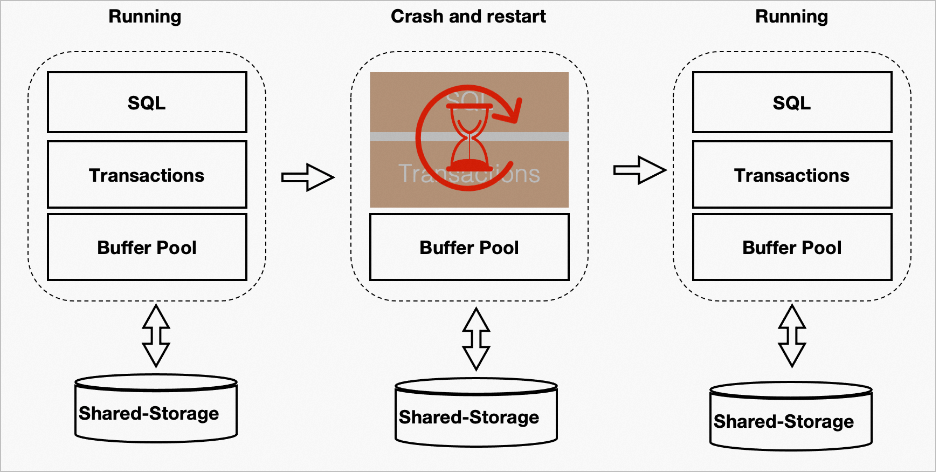
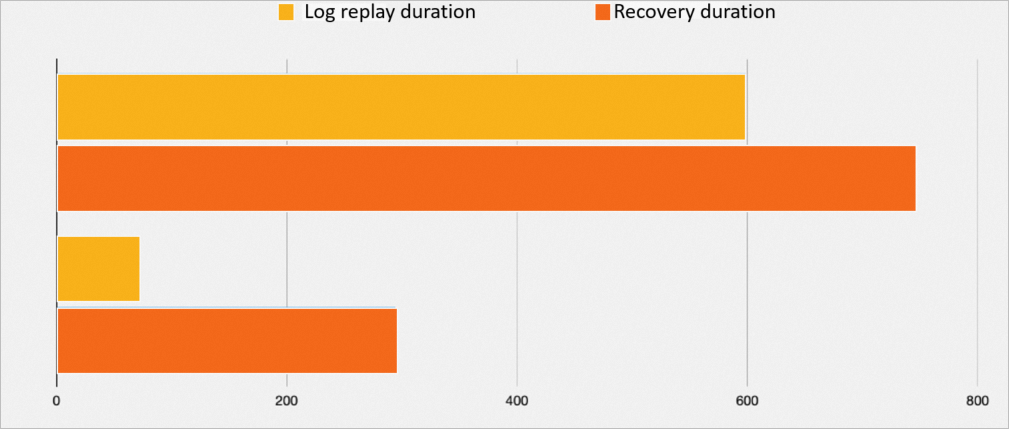
回復パフォーマンスの比較
異常シャットダウンのシミュレーションシナリオでは、合計 2093 MB のログが再生されます。
パラメーター
ログ再生時間
障害回復時間
PBP 無効
598 秒
746 秒
PBP 使用
68 秒
294 秒
次の図は、所要時間の比較を示しています。
再起動前後のパフォーマンス比較
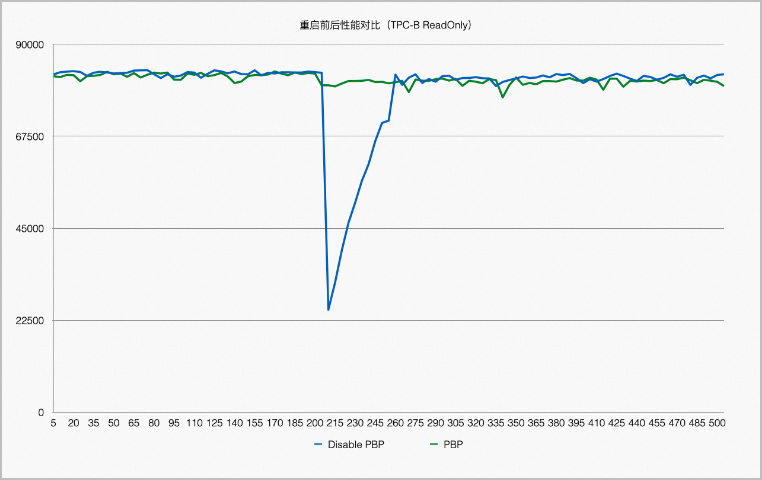
バッファープール内のすべてのページを再利用できるわけではありません。たとえば、システムがダウンする前にプロセスがページに X ロックをかける場合があります。障害後、ロックを解除できるプロセスはありません。したがって、障害と再起動の後、バッファープール内のすべてのページを走査して、再利用できないページを削除する必要があります。バッファープールの再利用は Kubernetes にも依存します。この最適化は、再起動前後のパフォーマンスを安定させるのに役立ちます。次の図は、再起動前後のパフォーマンスの比較を示しています。
使用方法
この機能を使用するには、次のパラメーターを有効にしてください。
polar_enable_persisted_buffer_pool = ONこのパラメーターの変更を有効にするには、クラスターの再起動が必要です。