PolarDBは、クラウドネイティブアーキテクチャに基づいています。 PolarDBは、商用データベースとオープンソースのクラウドデータベースの利点を提供します。 商用データベースは、安定性、信頼性、高性能、およびスケーラビリティの利点を提供する。 オープンソースのクラウドデータベースには、シンプルさ、オープン性、迅速なイテレーションの利点があります。 このトピックでは、PolarDBのアーキテクチャと機能について説明します。
図1. Product architecture 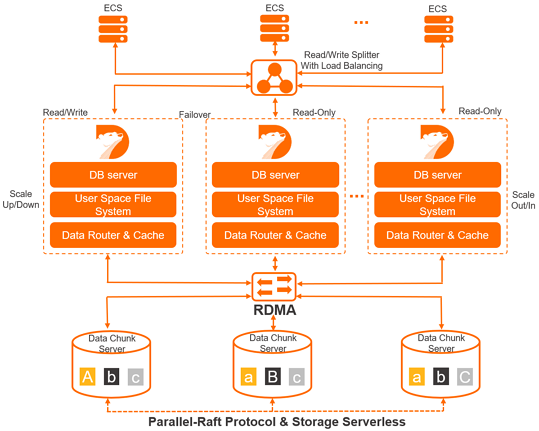
1つのプライマリノードと複数の読み取り専用ノード
PolarDBは、分散クラスターベースのアーキテクチャを使用します。 Cluster Editionクラスターは、プライマリノードと最大15の読み取り専用ノードで構成されます。 高可用性を確保するために、少なくとも1つの読み取り専用ノードが使用されます。 プライマリノードは読み取り要求と書き込み要求を処理し、読み取り専用ノードは読み取り要求のみを処理します。 PolarDBは、プライマリノードと読み取り専用ノード間でアクティブ-アクティブフェールオーバー方式を使用します。 この方法は、データベースの高可用性サービスを提供します。
コンピューティングとストレージの分離
PolarDBは、コンピューティングをストレージから分離します。 これにより、ビジネス要件に基づいてAlibaba Cloudにデプロイされているクラスターをスケーリングできます。 データベース計算ノード (データベースエンジンサーバ) は、メタデータのみを格納する。 リモートストレージノード (データベースストレージサーバー) は、データファイルやredoログなどのデータを保存します。 コンピューティングノード間でredoログに関連するメタデータを同期するだけで済みます。 これにより、プライマリノードと読み取り専用ノード間のレプリケーション遅延が削減されます。 プライマリノードに障害が発生した場合、読み取り専用ノードは短時間で引き継ぐことができます。
読み書き分離
デフォルトでは、読み書き分離は、PolarDB Cluster Editionに提供される透過的で高可用性の適応型負荷分散機能です。 読み書き分離機能は、クラスターエンドポイントに基づいて、構造化クエリ言語 (SQL) リクエストをPolarDB Cluster Editionの各ノードに自動的に転送します。 これにより、集計および高スループットのシナリオで同時SQL文を処理できます。 詳細については、「読み書き分離」をご参照ください。
高速ネットワーク接続
高速ネットワーク接続は、データベースの計算ノードとストレージノードの間で使用されます。 リモートダイレクトメモリアクセス (RDMA) プロトコルは、計算ノードとストレージノードとの間でデータを送信するために使用される。 これら2つの機能により、I/Oパフォーマンスのボトルネックが解消されます。
共有分散ストレージ
複数の計算ノードが1組のデータを共有する。 各計算ノードは、同じデータセットを格納する必要はない。 これにより、ストレージコストが大幅に削減されます。 新しく開発された分散ストレージおよび分散ファイルシステムを使用することで、ストレージ容量をスムーズにオンラインでスケーリングできます。 この機能は、単一のデータベースサーバの記憶容量によって制限されず、数百テラバイトのデータに対処することができる。
複数のデータレプリカとParallel-Raftプロトコル
データベースのストレージノード上のデータには、複数のレプリカがあります。 これにより、データの信頼性が確保されます。 さらに、Parallel-Raftプロトコルを使用して、これらのレプリカ間でデータの一貫性を確保します。