PolarDB for MySQL は、データベースカーネルとリモートダイレクトメモリアクセス(RDMA)ネットワークを統合し、強整合性クラスタ(SCC)機能を提供します。 SCC 機能は PolarDB-SCC とも呼ばれます。 これにより、データのグローバル整合性が確保され、データの読み取りと書き込みの高パフォーマンスが実現します。 結果整合性と比較して、クラスタで SCC が有効になっている場合、クラスタのパフォーマンス損失は 10% 以内です。 このトピックでは、SCC の使用上の注意、技術的原則、および有効化方法について説明し、クラスタのパフォーマンス比較結果を示します。
サポートされているバージョン
SCC を有効にするには、PolarDB for MySQL Enterprise Edition クラスタが次のいずれかのバージョン要件を満たしている必要があります。
エンジンバージョンが 8.0.2 で、リビジョンバージョンが 8.0.2.2.19 以降。
エンジンバージョンが 8.0.1 で、リビジョンバージョンが 8.0.1.1.29 以降。
エンジンバージョンが 5.7 で、リビジョンバージョンが 5.7.1.0.26 以降。
クラスタバージョンの確認方法の詳細については、「エンジンバージョン」トピックの「エンジンバージョンのクエリ」セクションをご参照ください。
使用上の注意
デフォルトでは、サーバーレスクラスタのすべての読み取り専用ノードで SCC が有効になっています。
グローバルデータベースネットワーク(GDN)のセカンダリクラスタの読み取り専用ノードでは、SCC を有効にすることはできません。
SCC は、高速クエリキャッシュ機能と互換性があります。 ただし、SCC で変更追跡テーブル(MTT)の最適化が有効になっており、高速クエリキャッシュ機能と SCC の両方を有効にした場合、MTT の最適化は無効になります。
SCC の技術的ソリューション
SCC は PolarTrans に基づいています。 これは、ネイティブ MySQL のアクティブなトランザクション数に基づく従来のトランザクション管理方法を再構築することを目的とした、新しく設計されたタイムスタンプベースのトランザクションシステムです。 このシステムは、分散トランザクションの拡張をサポートするだけでなく、単一クラスタのパフォーマンスも大幅に向上させます。
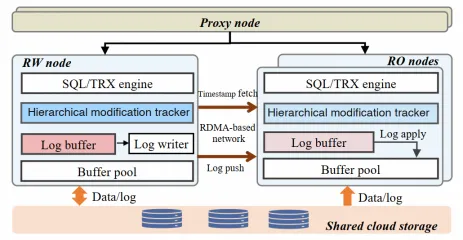
次の図は、SCC の実装方法を示しています。 RDMA ネットワークを使用して、インタラクティブで多次元のプライマリ/セカンダリ情報同期を確立します。 これは、従来のプライマリ/セカンダリログレプリケーションアーキテクチャに取って代わり、線形 Lamport タイムスタンプアルゴリズムを使用して読み取り専用ノードがタイムスタンプを取得する回数を減らし、ログ再生の不要な待ち時間を防ぎます。
線形 Lamport タイムスタンプ:読み取り専用ノードが最新の変更タイムスタンプを取得する効率を最適化するために、線形 Lamport タイムスタンプが使用されます。 従来の方法では、読み取り専用ノードはリクエストを処理するたびにプライマリノードからタイムスタンプを取得する必要があります。 この場合、ネットワーク速度が速くても、高負荷下では大きなオーバーヘッドが発生します。 線形 Lamport タイムスタンプの利点は、読み取り専用ノードがプライマリノードから取得したタイムスタンプをローカルに保存できることです。 ローカルに保存されているタイムスタンプよりも前に読み取り専用ノードに到達するリクエストの場合、読み取り専用ノードはプライマリノードから別のタイムスタンプを取得する必要なく、ローカルタイムスタンプを直接使用できます。 これにより、高負荷下で頻繁にタイムスタンプをリクエストすることによって発生するオーバーヘッドが効果的に削減され、読み取り専用ノードのパフォーマンスが向上します。
階層型きめ細かい変更追跡:読み取り専用ノードのパフォーマンスを最適化するために、プライマリノードでは 3 つのレベルのタイムスタンプ(グローバルタイムスタンプ、テーブルレベルタイムスタンプ、ページレベルタイムスタンプ)が使用されます。 読み取り専用ノードがリクエストを処理するとき、最初にグローバルタイムスタンプを取得します。 グローバルタイムスタンプが読み取り専用ノードがログを再生したときに生成されたタイムスタンプよりも後の場合、読み取り専用ノードはすぐに待機状態になりません。 代わりに、読み取り専用ノードは、リクエストがアクセスするテーブルとページのタイムスタンプを引き続きチェックします。 読み取り専用ノードは、リクエストのページレベルのタイムスタンプが条件を満たさない場合にのみ、ログの再生が完了するまで待機します。 これにより、ログ再生の不要な待ち時間が効果的に防止され、読み取り専用ノードの応答速度が向上します。
RDMA ベースのログシップメント:SCC は、片側 RDMA インターフェースを使用して、プライマリノードから読み取り専用ノードにログをシップし、ログシップメント速度を大幅に向上させ、ログシップメントによって発生する CPU オーバーヘッドを削減します。
線形 Lamport タイムスタンプ
読み取り専用ノードは、線形 Lamport タイムスタンプを使用して、読み取りリクエストのレイテンシと帯域幅消費を削減できます。 リクエストが読み取り専用ノードに到達したときに、読み取り専用ノードが別のリクエストのためにプライマリノードからタイムスタンプが取得されたことを検出した場合、読み取り専用ノードはタイムスタンプを直接再利用して、プライマリノードへの繰り返しのタイムスタンプリクエストを防ぎます。これにより、強力なデータ整合性が確保され、パフォーマンスが向上します。
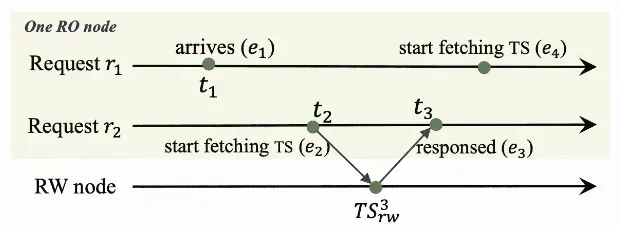
前の図では、2 つの同時読み取りリクエスト r<sub>1</sub> と r<sub>2</sub> が読み取り専用ノードに到達します。 読み取り専用ノードは t<sub>2</sub> でプライマリノードにリクエストを送信して r<sub>2</sub> のタイムスタンプを取得し、t<sub>3</sub> でプライマリノードからタイムスタンプ TS<sup>3</sup><sub>rw</sub> を取得します。 これらのイベントの関係は次のように理解できます:e<sub>2</sub>TS<sup>3 </sup><sub>rw </sub>e<sub>3</sub>。 r<sub>1</sub> は t<sub>1</sub> で読み取り専用ノードに到達します。 読み取り専用ノードの各イベントにタイムスタンプを割り当てることにより、読み取り専用ノードのイベントのシーケンスを決定できます。 t<sub>1</sub> が t<sub>2</sub> より前の場合、次のイベント関係が得られます:e<sub>1</sub>e<sub>2</sub>TS<sup>3 </sup><sub>rw </sub>e<sub>3</sub>。 つまり、r<sub>2</sub> に対して取得されたタイムスタンプは、r<sub>1</sub> が読み取り専用ノードに到達する前のすべての更新をすでにカバーしています。 この場合、r<sub>2</sub> のタイムスタンプは、新しいタイムスタンプを取得する必要なく、r<sub>1</sub> に直接使用できます。 この原則に基づいて、読み取り専用ノードがプライマリノードからタイムスタンプを取得するたびに、読み取り専用ノードはタイムスタンプをローカルに保存し、タイムスタンプが取得された時刻を記録します。 リクエストの到着時刻がローカルにキャッシュされたタイムスタンプが取得された時刻よりも前の場合、タイムスタンプをリクエストに直接使用できます。
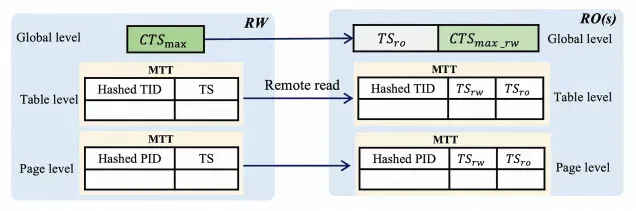
階層型で詳細な変更追跡
データ読み取りの強力な整合性を実装するために、読み取り専用ノードは、最初にプライマリノードの現在のトランザクションによってコミットされた最新のタイムスタンプを取得し、ログをタイムスタンプまで再生してから、読み取りリクエストを処理する必要があります。 ただし、ログの再生中に、リクエストされたデータが最新である可能性があり、読み取り専用ノードはログが再生されるまで待つ必要はありません。 待機に費やされる不要な時間を防ぐために、SCC はよりきめ細かい変更追跡を使用します。 プライマリノードでは、グローバルタイムスタンプ、テーブルレベルタイムスタンプ、ページレベルタイムスタンプの 3 つのレベルの変更情報が保持されます。
読み取り専用ノードが読み取りリクエストを処理するとき、最初にグローバルタイムスタンプを取得してデータの整合性をチェックします。 グローバルタイムスタンプが条件を満たさない場合、読み取り専用ノードは宛先テーブルのローカルタイムスタンプを取得して、よりきめ細かい検証を行います。 テーブルレベルのタイムスタンプがまだ条件を満たさない場合、読み取り専用ノードは宛先ページのタイムスタンプを取得してさらに検証を行います。 現在のページのタイムスタンプが読み取り専用ノードがログを再生したタイムスタンプよりも後の場合にのみ、読み取り専用ノードは最新のデータが読み取られるようにログの再生が完了するまで待つ必要があります。
メモリ使用量を削減するために、3 つのレベルのタイムスタンプはメモリ内のハッシュテーブルに格納されます。 メモリ使用量をさらに最適化するために、複数のテーブルまたはページのタイムスタンプが同じハッシュテーブルにマッピングされる場合があります。 整合性を確保するために、後のタイムスタンプのみが以前のタイムスタンプを置き換えることができます。 この設計により、読み取り専用ノードが後のタイムスタンプを取得した場合でも、整合性が損なわれないことが保証されます。 次の図は、その原理を示しています。 この図では、TID はテーブル ID を示し、PID はページ ID を示します。 読み取り専用ノードによって取得されたタイムスタンプは、他の適格なリクエストのために線形 Lamport タイムスタンプの設計に基づいてローカルにキャッシュされます。
RDMA ベースのログシップメント
SCC では、プライマリノードは片側 RDMA を介してログを読み取り専用ノードのキャッシュにリモートで書き込みます。 このプロセスは読み取り専用ノードの CPU リソースを消費せず、低レイテンシを保証します。 次の図に示すように、読み取り専用ノードとプライマリノードの両方が同じサイズのログバッファを保持します。 プライマリノードのバックグラウンドスレッドは、RDMA を介してプライマリノードのログバッファを読み取り専用ノードのログバッファに書き込みます。 読み取り専用ノードは、レプリケーション同期を高速化するためにファイルを読み取る代わりに、ローカルログバッファを読み取ります。
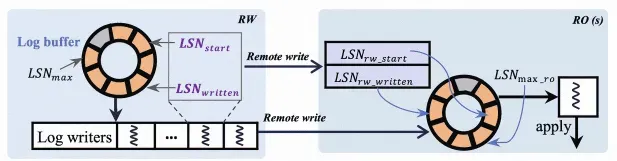
RDMA ベースのログシップメントの詳細については、「RDMA ベースのログシップメント」をご参照ください。
SCC を有効にする
PolarDB コンソールにログオンします。 [クラスタ] ページで、管理するクラスタを見つけ、その ID をクリックしてクラスタの詳細ページに移動します。 [基本情報] ページの [データベース接続] セクションで、SCC を有効にするエンドポイントにポインタを移動し、[構成] をクリックします。 詳細については、「PolarProxy の構成」をご参照ください。
グローバル整合性(高パフォーマンスモード)は、有効にすると、クラスタのすべてのエンドポイントに適用されます。 クラスタの 1 つのエンドポイントでこのモードを有効にすると、クラスタの他のすべてのエンドポイントでこのモードが有効になります。
パフォーマンス比較
テスト環境
8 CPU コアと 32 GB のメモリを搭載した クラスターエディション の PolarDB for MySQL 8.0 クラスタ。
テストツール
Sysbench
テストデータのサイズ
各テーブルに 250,000 行の 25 テーブル
テスト結果
読み取りと書き込みのパフォーマンス
チャートの概要
qps:sysbench テスト結果の 1 秒あたりのクエリ数(QPS)。
threads:テストで使用された同時 sysbench スレッドの数。
RW:プライマリノードの QPS。 読み取り専用ノードがグローバルに一貫性のある読み取り操作を提供できない場合、すべての読み取りおよび書き込み操作はプライマリノードに送信されます。
グローバル整合性:グローバル整合性が有効になっている QPS。
SCC:結果整合性と SCC が有効になっている QPS。
結果整合性:読み取り操作で結果整合性が有効になっており、SCC が無効になっている QPS。
2 つのクラスタ間で読み取りと書き込みのパフォーマンスをテストするシナリオでは、結果整合性が有効になっているクラスタと比較して、SCC が有効になっているクラスタの全体的なパフォーマンス損失は 10% 以内です。
