PolarDB は、複数の読み取り専用ノード間で負荷を分散するために、接続数に基づく負荷分散 ポリシーと アクティブなリクエストベースのロードバランシング ポリシーをサポートしています。
ロードバランシングポリシー
PolarDB クラスタエンドポイントの 読み取り専用 モードでは、接続数に基づく負荷分散 と アクティブなリクエストベースのロードバランシング の 2 つのロードバランシングポリシーがサポートされています。 読み書き (自動読み書き分離) モードのクラスタエンドポイントは、アクティブなリクエストベースのロードバランシング ポリシーのみをサポートしています。
ロードバランシングポリシー | 違い | 類似点 |
接続ベースのロードバランシング 説明 読み取りリクエストは、ロードバランシングを実装するために、接続数に基づいてクラスタエンドポイント内の複数の読み取り専用ノード間で自動的にスケジュールされます。 |
| 読み取り専用 モードのクラスタエンドポイントの場合、ロードバランシングポリシーに関係なく、プライマリノードにリクエストが転送されることはありません。 |
アクティブリクエストベースのロードバランシング 説明 読み取りリクエストは、ロードバランシングを実装するために、アクティブリクエスト数に基づいてクラスタエンドポイント内の複数の読み取り専用ノード間で自動的にスケジュールされます。 |
|
プライマリノードが読み取りリクエストを受け入れる
[プライマリノードが読み取りリクエストを受け入れる] を [いいえ] に設定すると、一般的な読み取りリクエストはプライマリノードに転送されなくなります。 トランザクションでは、高い整合性が必要な読み取りリクエストは、ビジネス要件を満たすために引き続きプライマリノードに転送されます。 すべての読み取り専用ノードに障害が発生した場合、読み取りリクエストはプライマリノードに転送されます。 ワークロードで高い整合性が必要ない場合は、整合性レベルを結果整合性に設定して、プライマリノードに転送される読み取りリクエストの数を減らすことができます。 また、トランザクション分割機能を使用して、トランザクションが開始される前にプライマリノードに転送される読み取りリクエストの数を減らすこともできます。 ただし、SET リクエストや PREPARE リクエストなどのブロードキャストリクエストは、プライマリノードに転送されます。
プライマリノードによる読み取りリクエストの許可 パラメータは、読み書き パラメータが 読み書き (自動読み書き分離) に設定されている場合にのみ使用できます。 プライマリノードによる読み取りリクエストの許可 設定を変更する方法については、「PolarProxy の構成」をご参照ください。
PolarProxy が 1.x.x または 2.5.1 以降の場合、新しい プライマリノードによる読み取りリクエストの許可 値はすぐに有効になります。
PolarProxy が 2.x.x で 2.5.1 より前のバージョンであり、持続的接続が使用されている場合は、新しい プライマリノードによる読み取りリクエストの許可 値を検証するために接続を再確立する必要があります。 短期接続が使用されている場合は、新しい値はすぐに有効になります。
トランザクション分割
PolarDB クラスタへの接続に使用されるクラスタエンドポイントが読み取り/書き込みモードの場合、PolarProxy は読み取りリクエストと書き込みリクエストをプライマリノードと読み取り専用ノードに転送します。 セッション内のトランザクション間でデータの整合性を確保するために、PolarProxy はセッションのトランザクション内のすべてのリクエストをプライマリノードに送信します。 たとえば、Java Database Connectivity ( JDBC ) などのデータベースクライアントドライバーは、トランザクション内のリクエストをカプセル化します。 この場合、アプリケーションからのすべてのリクエストがプライマリノードに送信されます。 これにより、プライマリノードに大きな負荷がかかります。 ただし、読み取り専用ノードにはリクエストは送信されません。 次の図は、そのプロセスを示しています。
この問題を解決するために、PolarDB は、Read Committed 分離レベルのセッションでトランザクション分割機能を提供します。 この機能により、セッション内のデータの整合性が確保され、PolarDB は読み取りリクエストを読み取り専用ノードに送信して、プライマリノードの負荷を軽減できます。 アプリケーションのコードや構成を変更することなく、プライマリノードの読み取り負荷を軽減できます。 これにより、プライマリノードの安定性が向上します。 トランザクション分割を有効にする方法の詳細については、「PolarProxy の構成」をご参照ください。
PolarDB for MySQL では、最初の書き込みリクエスト前の読み取りリクエスト分割 (デフォルトで選択され、元のトランザクション分割機能です) と完全なトランザクション分割 (最初の書き込みリクエスト前後の読み取りリクエスト分割) の 2 つのレベルでトランザクションを分割できます。
最初の書き込みリクエスト前の読み取りリクエスト分割
PolarProxy は、最初の書き込みリクエストの前にトランザクション内の読み取りリクエストを読み取り専用ノードに送信します。 これにより、プライマリノードの負荷が軽減されます。
完全なトランザクション分割 (最初の書き込みリクエスト前後の読み取りリクエスト分割)
最初の書き込みリクエスト前の読み取りリクエスト分割を使用する場合、最初の書き込みリクエスト後のトランザクション内の読み取りリクエストは引き続きプライマリノードにルーティングされます。 これにより、負荷の不均衡が発生します。 負荷の不均衡を解決するために、PolarDB for MySQL は完全なトランザクション分割機能を提供します。 これにより、トランザクション内のすべての読み取りリクエストを読み取り専用ノードにルーティングし、正しい結果を返すことができます。 この機能は、プライマリノードの負荷をさらに軽減します。
最初の書き込みリクエスト後の分割読み取りリクエストを読み取り専用ノードにルーティングするには、以前のすべての書き込み操作を読み取り専用ノードに同期する必要があります。 セッションの整合性が選択されている場合、システムは、最初の書き込みリクエスト後の分割読み取りリクエストをルーティングする前に、以前のすべての書き込み操作が現在のセッションの読み取り専用ノードに同期されているかどうかを確認します。 同期されている場合、最初の書き込みリクエスト後の分割読み取りリクエストを現在のセッションの読み取り専用ノードにルーティングできます。 そうでない場合、最初の書き込みリクエスト後の分割読み取りリクエストはプライマリノードにルーティングされます。 同様に、グローバル整合性が選択されている場合、システムは、最初の書き込みリクエスト後の分割読み取りリクエストをルーティングする前に、以前のすべての書き込み操作がすべてのセッションの読み取り専用ノードに同期されているかどうかを確認します。 同期されている場合、最初の書き込みリクエスト後の分割読み取りリクエストを読み取り専用ノードにルーティングできます。 そうでない場合、最初の書き込みリクエスト後の分割読み取りリクエストはプライマリノードにルーティングされます。 結果整合性が選択されている場合、完全なトランザクション分割を有効にすることはできません。
サポートされているバージョンと制限
トランザクション分割機能を使用するには、PolarDB for MySQL クラスタが次の要件を満たしている必要があります。
クラスタは、次のいずれかのエンジンバージョンを実行しています。
リビジョンバージョンが 5.6.1.0.29 以降の PolarDB for MySQL 5.6。
リビジョンバージョンが 5.7.1.0.9 以降の PolarDB for MySQL 5.7。
リビジョンバージョンが 8.0.1.1.18 以降の PolarDB for MySQL 8.0.1。
PolarDB for MySQL 8.0.2。
エンジンパラメータ
loose_query_cache_typeを OFF に設定する必要があります。 このパラメータのデフォルト値は、PolarDB for MySQL 5.6、5.7、および 8.0.1 クラスタでは OFF で、PolarDB for MySQL 8.0.2 クラスタでは ON です。 このパラメータを変更する場合は、PolarDB クラスタを再起動する必要があります。
Read Committed 分離レベルのセッションのトランザクションのみを分割できます。 この機能はデフォルトで有効になっています。
読み取り/書き込みの整合性の制約により、読み取り専用ノードが整合性要件を満たしていない場合、読み取りリクエストはその読み取り専用ノードにルーティングされません。
PolarProxy が 2.4.14 より前のバージョンの場合、完全なトランザクション分割ではなく、書き込み操作前の読み取りリクエスト分割がサポートされます。
PolarProxy が 2.4.14 以降の場合、完全なトランザクション分割が有効になり、持続的接続が使用されている場合は、トランザクション分割機能を使用するために接続を再確立する必要があります。 短期接続が使用されている場合は、トランザクション分割機能をすぐに使用できます。
トランザクション分割を無効にする
トランザクション分割を無効にすると、トランザクション内のすべてのリクエストがプライマリノードにルーティングされます。
重みベースのロードバランシング
デフォルトでは、PolarDB for MySQL PolarProxy は、リクエストをルーティングするために同時リクエスト数が最小のノードを選択します。 このポリシーでは、基本的にトラフィックを異なるバックエンドノードに均等にルーティングできます。 バックエンドノードが異なる仕様を使用している場合でも、ロードバランシングの結果を保証できます。 ただし、お客様のビジネス負荷はさまざまであり、トラフィック分散に対する要件も異なります。
PolarDB for MySQL は、重みベースのロードバランシング機能を導入しています。 ノードに異なる重みを構成できます。 その後、重みと同時リクエスト数が最終的なルーティング決定の参考になります。 重みは、次の 2 つのディメンションでのみ構成できます。
グローバルディメンション
重み設定はすべてのエンドポイントで有効です。
エンドポイントディメンション
重み設定は現在のエンドポイントに対してのみ有効であり、グローバルディメンションの重み設定を上書きします。 最初にグローバルディメンションで重みを構成し、次に特定のエンドポイントの重みを構成すると、エンドポイントの重みが実際に有効になります。
使用上の注意
この機能を使用するには、PolarProxy が 2.8.3 以降である必要があります。
現在のノード負荷とカスタム重みの両方が考慮されるため、実際の全体的な比率は指定された比率と多少異なる場合があります。 ただし、前者は徐々に後者に近づきます。
サーバーレスクラスタは、エンドポイントディメンションでの重み構成をサポートしていません。
仕組み
各ノードの最終的な重みは、指定した重みと各ノードの同時リクエスト数に基づいて動的に調整されます。 簡略化された式を使用できます。
動的重み = カスタム重み / 同時リクエスト数
動的重みの値が高いほど、ノードがリクエストのルーティングに使用される可能性が高くなります。 重みベースのロードバランシングポリシーは、柔軟なルーティング方法を提供します。 実際には、ビジネストラフィックは指定した重みに基づいて徐々に変化します。 純粋な重みベースのポーリング方法と比較して、より多くの時間がかかります。
手順
すべてのバックエンドノードの初期重みは 1 です。
重みの範囲は 0 ~ 100 です。
ノードの重みが 0 に設定されている場合、他のノードが使用可能な場合は、そのノードにリクエストはルーティングされません。
クラスタに読み取り専用列ストアノードが 1 つしかない場合、その重みは無視できます。 クラスタに複数の読み取り専用列ストアノードが含まれている場合、IMCI リクエストは読み取り専用列ストアノードの重みに基づいて分散されます。
グローバルディメンションで重みを構成する
PolarDB コンソール にログインします。
左上隅で、クラスタがデプロイされているリージョンを選択します。
クラスタを見つけて、その ID をクリックします。
[標準 Enterprise Edition] または [専用 Enterprise Edition] セクションの [基本情報] ページで、[データベースプロキシ設定] をクリックします。
[データベースプロキシ設定] ダイアログボックスで、ビジネス要件に基づいて各ノードの重みを構成します。
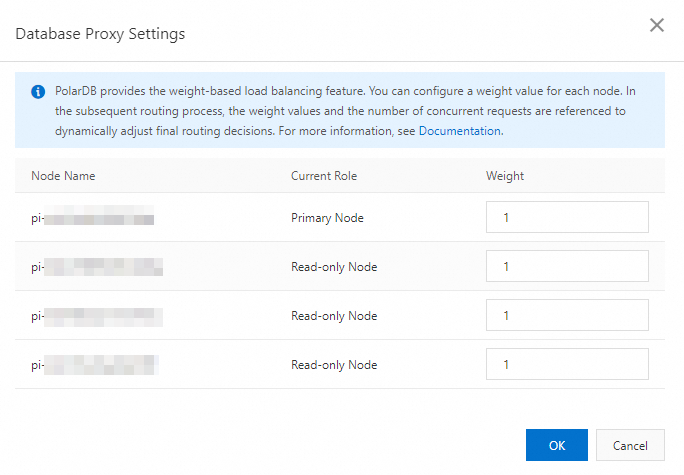
[OK] をクリックします。
エンドポイントディメンションで重みを構成する
PolarDB コンソール にログインします。
左上隅で、クラスタがデプロイされているリージョンを選択します。
クラスタを見つけて、その ID をクリックします。
[標準 Enterprise Edition] または [専用 Enterprise Edition] セクションの [基本情報] ページで、クラスタエンドポイントまたはカスタムエンドポイントの右上隅にある [構成] をクリックします。
[エンドポイント設定の変更] ダイアログボックスの [ノード設定] セクションで、[ノードの重みを構成する] を選択し、ノードの重みを設定します。

[OK] をクリックします。
テストデータ
次の図は、ノードの重みが構成された後の実際のテストデータを示しています。
3 つのノードの重み比率が 1:2:3 (プライマリノードの場合は 1) の場合、予期されるテスト結果が得られます。 sysbench oltp_read_only テストセットが使用されていることに注意してください。
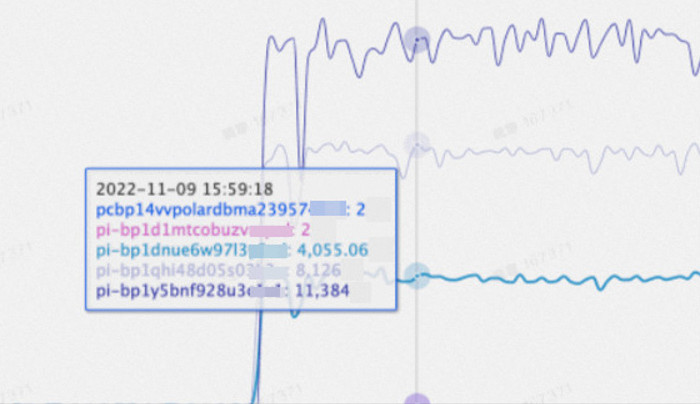
内部ノード pi-bp1d1mtcobuzv**** と pcbp14vvpolardbma23957**** はリクエストのルーティングには関与しません。 これらのメトリックはスキップできます。
オンデマンド接続
背景情報
[アクティブリクエストベースのロードバランシング] で使用されるエンドポイントの場合、デフォルトでは完全接続方式が使用されます。 クライアントが PolarProxy にセッションを開始した後、PolarProxy はエンドポイント内のすべてのノードにセッション (接続) を設定します。 1:N の対応が形成されます。 このクライアントセッションからの読み取りリクエストは、現在のノードのアクティブな負荷に応じて他のノードにルーティングされます。 SET 文などのブロードキャストリクエストは、すべてのノードにルーティングされます。 多数のノードが作成されると、接続の確立とブロードキャストによって全体的な効率が低下します。
仕組み
オンデマンド接続方式を使用する場合、PolarProxy は必要に応じてバックエンドノードへの接続を確立します。 データの整合性が確保され、プライマリノードが負荷を処理できる限り、ノードへの接続数を減らして、接続の確立とブロードキャストに関連するオーバーヘッドを削減します。 ほとんどの場合、セッションは 1 つのプライマリノードと 1 つの読み取り専用ノードに接続されます (結果整合性のみが提供されます)。 短期接続またはブロードキャスト文が多いシナリオでは、この方法によりパフォーマンスが大幅に向上します。
前の図では、PolarDB クラスタに 1 つのプライマリノードと 3 つの読み取り専用ノードのみが含まれており、データの整合性が考慮されていない場合、3 つのシナリオでのリクエストルーティングとデータ読み取りに関する次の効率結果が得られます。
オンデマンド接続以外
セッションにより、PolarProxy は 4 つのノードへの接続を確立し、ブロードキャスト文は 4 つのノードにルーティングされます。
読み取り専用セッションのオンデマンド接続
セッションにより、PolarProxy は 1 つの読み取り専用ノードへの接続を確立します。 読み取り専用リクエスト (ブロードキャストリクエストを含む) は、この読み取り専用ノードのみにルーティングされます。 これにより、データ読み取り効率が大幅に向上します。
読み取り/書き込みセッションのオンデマンド接続
セッションにより、PolarProxy は 1 つの読み取り専用ノードへの接続と 1 つのプライマリノードへの接続を確立します。 ブロードキャストリクエストは、2 つのノードのみにルーティングされます。 これにより、データ読み取り効率も大幅に向上します。
シナリオ
多数の読み取り専用ノード
短期接続
多数のブロードキャスト文 (たとえば、PHP 短期接続シナリオでは、セッションの最初の文は一般に
SET NAMES utf8mb4文です)短い PREPARE 文を使用するほとんどのクエリ
制限
PolarProxy は 2.8.34 以降である必要があります。 クラスタの PolarProxy バージョンを表示する方法の詳細については、「PolarProxy バージョンのクエリ」をご参照ください。
SHOW PROCESSLISTS文を実行して接続されているノードの数を表示する場合、すべての接続が表示されない場合があります。KILL 文を実行して指定された接続を終了する場合、すべてのノードへの指定された接続が終了されない場合があります。
パフォーマンステスト
テスト環境
ノード: 1 つのプライマリノードと 7 つの読み取り専用ノード
使用される SQL 文:
SET NAMES utf8mb4およびSELECT 1テストツール: Sysbench。 毎回同じ数の同時リクエストが送信されます。
テストシナリオ: 接続プール機能が無効になっている、接続プール機能がセッションレベルで有効になっている、および接続プール機能がトランザクションレベルで有効になっている。 各シナリオは 2 つの部分に分かれています。最初の部分ではオンデマンド接続機能が無効になっており、2 番目の部分ではオンデマンド接続機能が有効になっています。
テスト結果
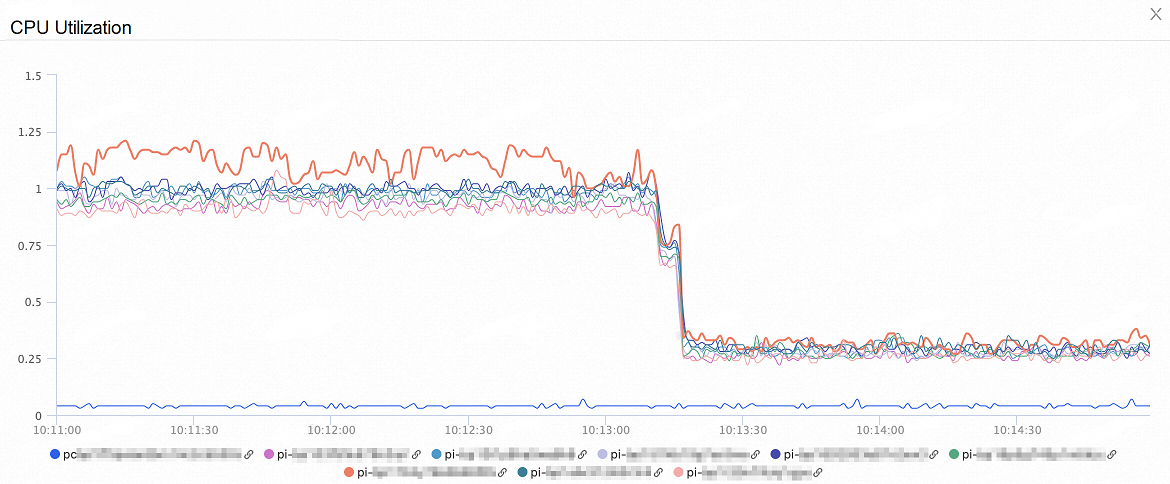
接続プール機能が無効になっている場合のパフォーマンステストの結果:
次の図は、ノードの CPU 使用率の変化を示しています。 オンデマンド接続機能を有効にすると、ノードの CPU 使用率は 60% 以上減少します。
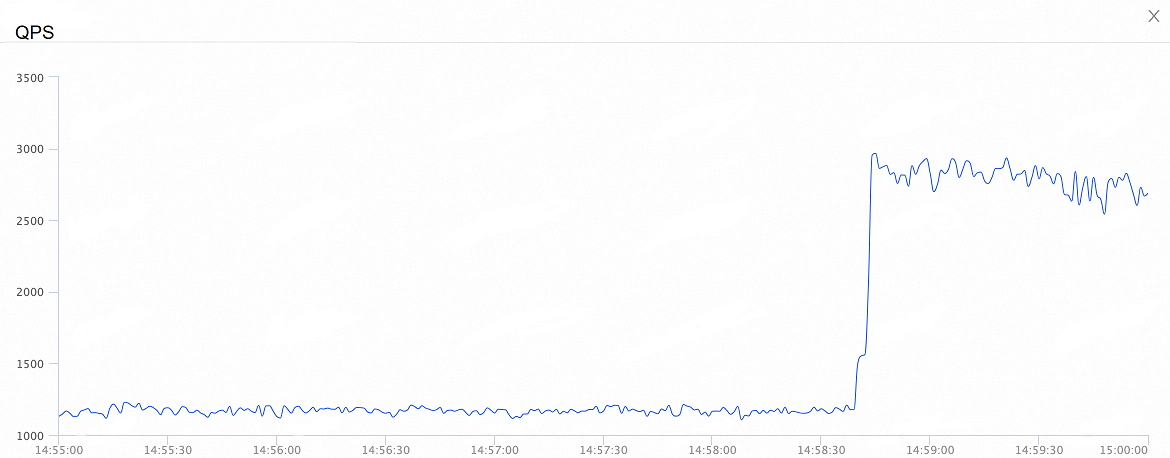
次の図は、ノードへの合計接続数の変化を示しています。 オンデマンド接続機能を有効にすると、ノードへの合計接続数は 80% 以上減少します。
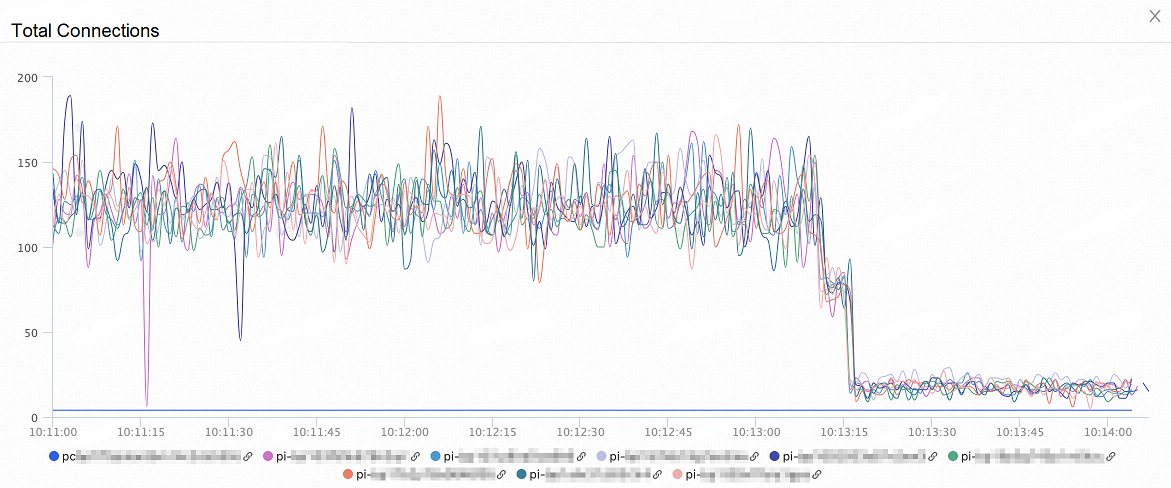
次の図は、全体的な QPS の変化を示しています。 オンデマンド接続機能を有効にすると、全体的な QPS は 35% 増加します。
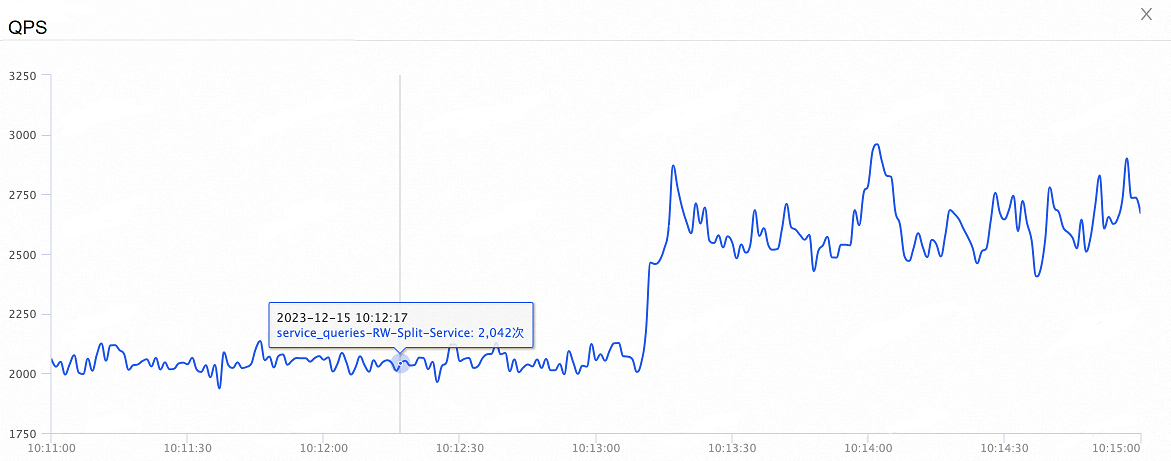
接続プールがセッションレベルで有効になっているシナリオでのパフォーマンステストの結果:
次の図は、ノードの CPU 使用率の変化を示しています。 オンデマンド接続機能を有効にすると、ノードの CPU 使用率は 50% ~ 60% 減少します。
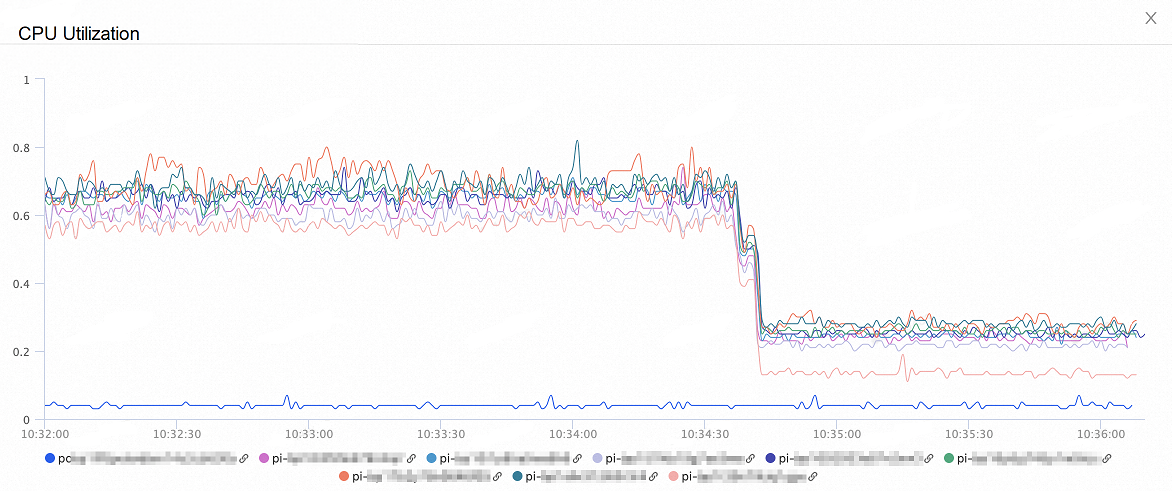
次の図は、ノードへの合計接続数の変化を示しています。 オンデマンド接続機能を有効にすると、ノードへの合計接続数は 60% 減少します。
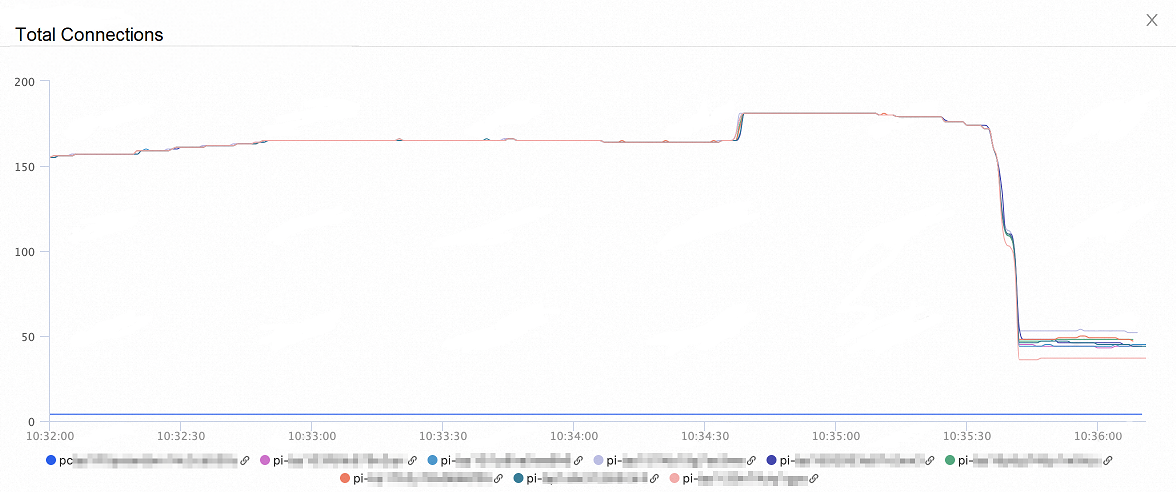
次の図は、全体的な QPS の変化を示しています。 オンデマンド接続機能を有効にすると、全体的な QPS は 30% 増加します。
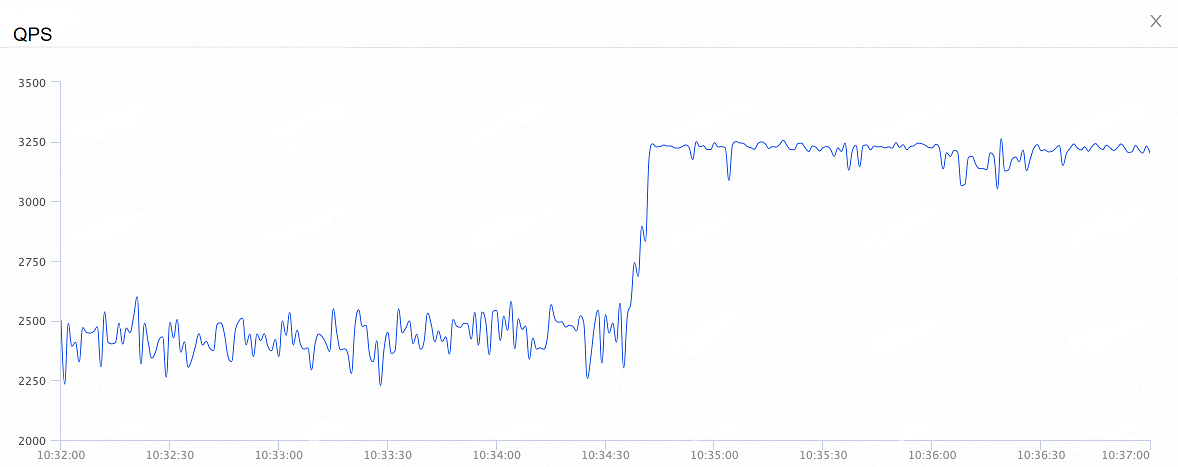
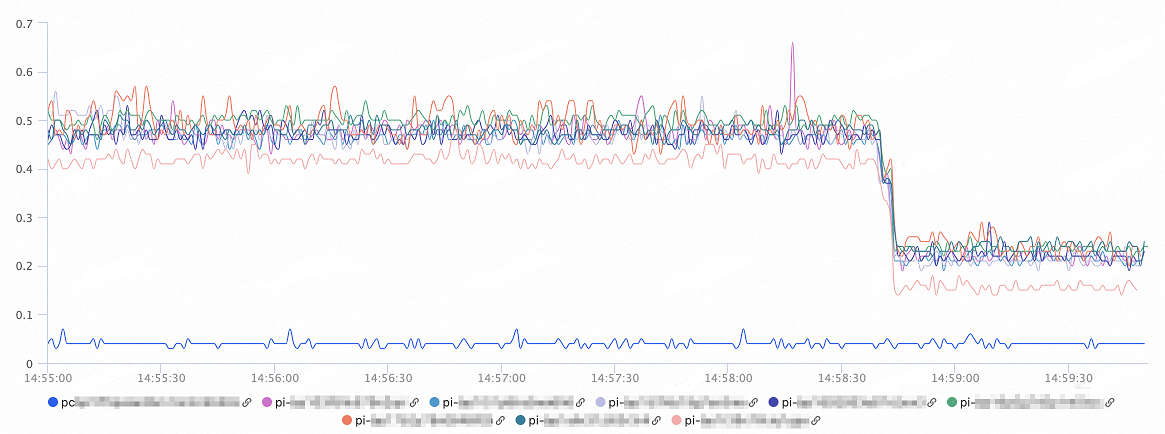
接続プール機能がトランザクションレベルで有効になっている場合のパフォーマンステストの結果:
次の図は、ノードの CPU 使用率の変化を示しています。 オンデマンド接続機能を有効にすると、ノードの CPU 使用率は 60% 減少します。
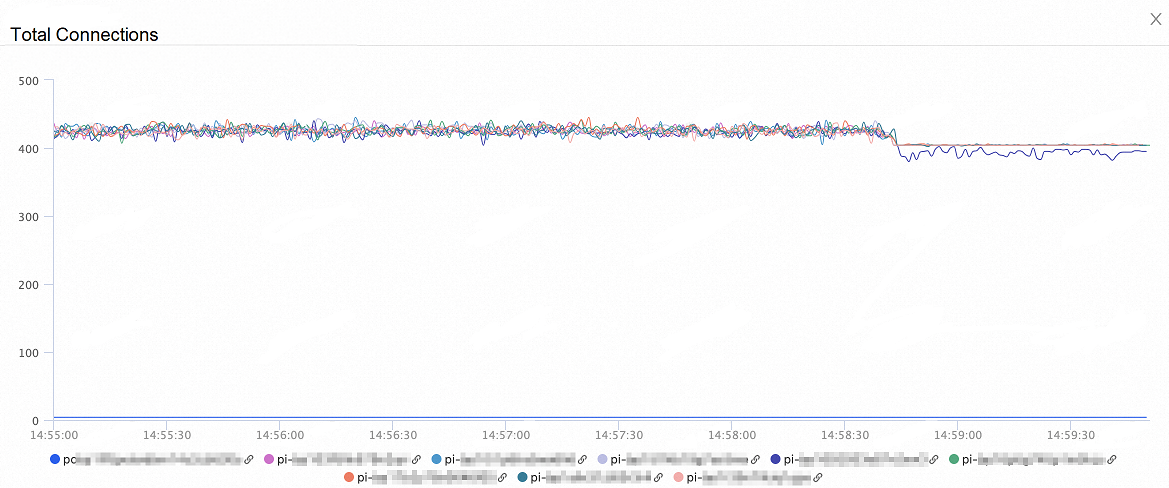
次の図は、ノードへの合計接続数の変化を示しています。 オンデマンド接続機能を有効にすると、ノードの合計接続数は 50% 減少します。
次の図は、全体的な QPS の変化を示しています。 オンデマンド接続機能を有効にすると、全体的な QPS は 260% 増加します。