大量のデータから上位K個の結果を得ることは、古典的な問題である。 そこから導出されるディープページング問題は特に困難であり、分析データベースに大きな課題をもたらす。 このトピックでは、PolarDB for MySQLが提供するメモリ内列インデックス (IMCI) 機能がどのようにこの課題に直面するかについて説明します。
背景情報
ビジネスシステムでは、ユーザーがレコードをフィルタリングして特定のレコードのセットを見つけ、条件に基づいて結果を並べ替え、ページごとに結果を表示するという一般的なシナリオが存在します。 例えば、ユーザは、販売されている製品をフィルタリングして、特定の販売業者によって販売されている製品を見つけ、販売量に基づいて結果をソートし、次いで、ページごとに結果を表示したい場合がある。 上記のシナリオは通常、ORDER by列LIMIT n, mなどのクエリ文を使用してデータベースに実装されます。
業務システムのページごとに100のレコードを表示する場合は、次の文を実行して、特定のページにレコードを表示できます。
ORDER BY列LIMIT 0, 100文を実行して、ページ1にレコードを表示します。ORDER BY列LIMIT 1000000, 100文を実行して、ページ10,001にレコードを表示します。
インデックスが存在しない場合、このようなクエリは、次のロジックに基づいて、データベースで従来のヒープベースのTopKアルゴリズムを使用して実装されます。 ヒープ内の一番上の要素は最小の要素です。 システムは、トラバースされた要素をトップ要素と比較する。 要素が最上位の要素よりも大きい場合、最上位の要素は新しい要素に置き換えられ、ヒープが再構築されます。 すべての要素がトラバースされた後、ヒープ内の要素は最初のK個の最大要素になります。 上記の例の1ページのように、結果を表示するページのページ番号が小さい場合、Kは比較的小さくなります。 この場合、クエリでヒープベースのTopKアルゴリズムを使用するのが効率的です。
ただし、ディープページングクエリは、ページ10,001など、ページ番号が非常に大きいページにレコードを表示するビジネスシナリオにも存在します。 この場合、Kは非常に大きく、メモリはサイズKのヒープをキャッシュするには不十分な場合があります。したがって、ヒープベースのTopKアルゴリズムを使用してクエリ結果を取得することはできません。 メモリが十分であっても、ヒープメンテナンス中のランダムメモリアクセスのためにヒープのサイズが非常に大きく、最終的なパフォーマンスが満足のいくものではない場合、ヒープベースのTopKアルゴリズムの効率は低下します。
最初に、PolarDB for MySQLのIMCI機能は、前述の方法を使用して、ページ化されたクエリを実装します。 サイズKのヒープをキャッシュするにはメモリが不足している場合、テーブル内のすべてのレコードがソートされ、指定された範囲のレコードがキャッシュされます。 その結果、ディープページングクエリにおけるIMCIのパフォーマンスは、期待されるほど良好ではない。 この問題に対処するために、PolarDB for MySQLは、ディープページングシナリオの特性の分析と従来のソリューションの問題に基づいて、IMCIのSort/TopK演算子を再設計します。 テストシナリオでは、再設計されたSort/TopK演算子は、ディープページングシナリオでのIMCIのパフォーマンスを大幅に向上させます。
TopKクエリに対する既存のソリューション
TopKクエリの実装方法は、業界では一般的な問題です。 TopKクエリを効率的に実装するための多くのソリューションがあります。 これらのソリューションの中核は、非結果セットデータに対する演算を減らすことです。 実際には、次の3つの解決策が主なものです。
優先キューに基づくTopKアルゴリズム
詳細については、このトピックの「背景情報」セクションをご参照ください。
マージソート中のオフセットと制限に基づく切り捨て
サイズKの優先キューをキャッシュするにはメモリが不足している場合、PolarDB、ClickHouse、SQL Server、DuckDBなどの一部のデータベースは、マージソートを使用してこの問題を処理します。 TopKアルゴリズムの目的は、[offset, offset + limit) の範囲のレコードを見つけることだけです。 したがって、システムは、各マージソート中にすべてのデータをソートする必要はない。 システムは、オフセット + リミットの長さを有する新しいソートされたランを生成するだけでよい。 マージ中の切り捨ては、結果の精度を保証し、非結果セットデータに対する演算を減らすことができる。

自己シャープ入力フィルター
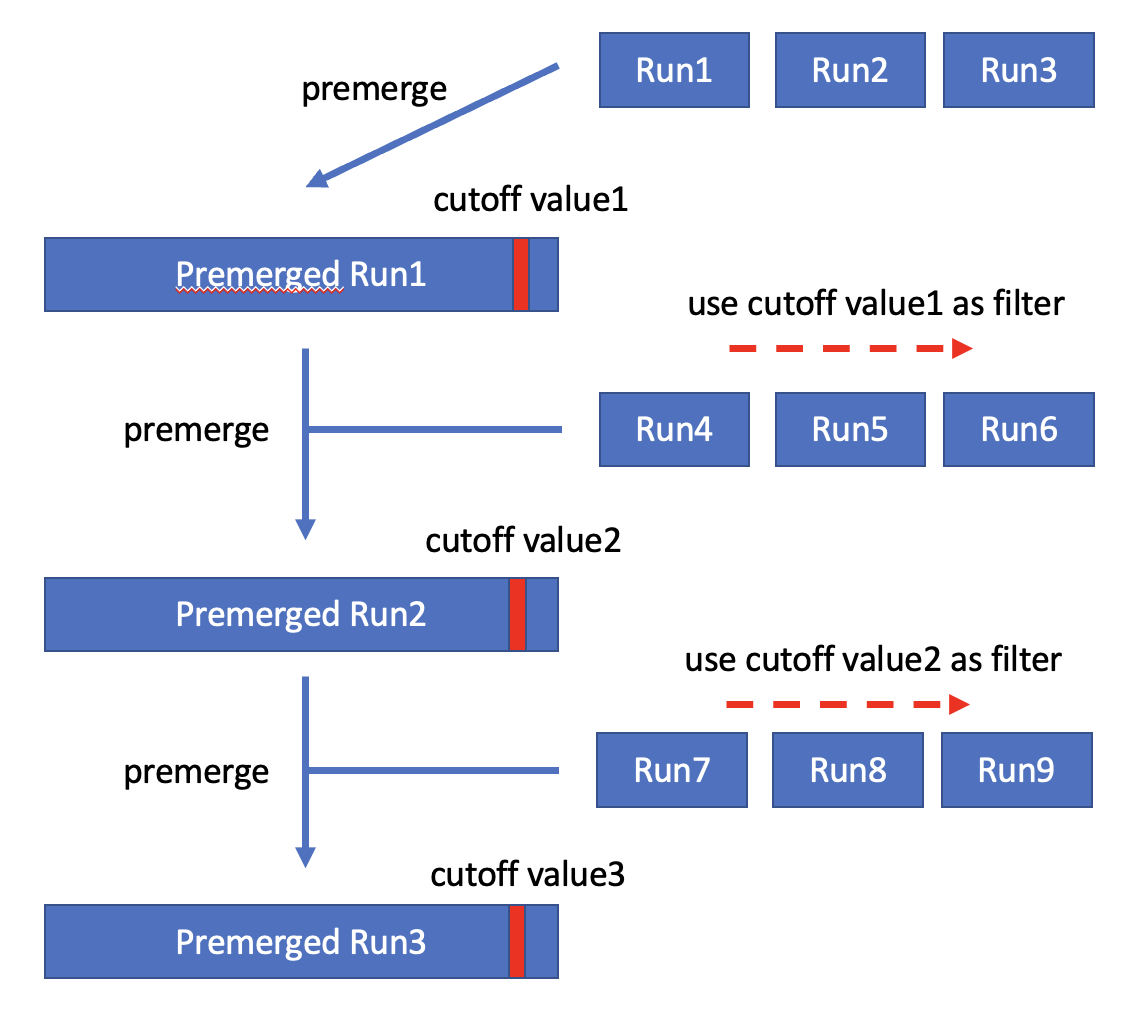
この解決策は、Goetz Graefeの論文で最初に提案されました。 ApsaraDB for ClickHouseはこのソリューションを採用しています。 このソリューションに基づくTopKクエリ中、システムはカットオフ値を維持し、カットオフ値よりも大きいレコードをTopKクエリの結果セットから除外します。 新しいソートされた実行を生成するために、システムは現在のカットオフ値を使用してデータをフィルタリングします。 新しいソートされたランが生成された後、Kが新しいソートされたランの長さよりも短い場合、現在のカットオフ値は、新しいソートされたラン内のK番目のレコードに置き換えられる。 新しいソートされた実行のデータは、古いカットオフ値を使用してフィルタリングされます。 したがって、新しいカットオフ値は常に古いカットオフ値以下である。 このようにして、カットオフ値は連続的に自己鮮鋭化される。 最後に、システムは、結果セットを取得するために、フィルタリングされたソート済みランをマージするだけでよい。
次の例は、前述のアルゴリズムを示しています。現在のTopKクエリでは、Kの値は3です。 データの最初のバッチが読み取られた後、最初のソートされた実行は (1、2、10、15、21) であり、カットオフ値は10に更新される。 次に、カットオフ値10を使用して、データの第2のバッチをフィルタリングする。 第2のソートされたランは (2,3, 5,6, 8) であり、カットオフ値は5に更新される。 次に、カットオフ値5を使用して、データの第3のバッチをフィルタリングする。 3番目のソートされた実行は (1、2、3、3) であり、カットオフ値は3に更新される。 後続のソートされたランおよびカットオフ値は、同じ方法で得られる。 連続的にシャープ化されたカットオフ値は、より多くのデータをフィルタリングする。
Kがソートされたランの長さよりも大きい場合、システムは、Kレコードを超える十分なソートされたランを蓄積し、蓄積されたソートされたランを事前にマージしてカットオフ値を取得します。 次に、システムはカットオフ値を使用してデータをフィルタリングし、十分にソートされた実行を蓄積します。 次に、システムは、これらのソートされたランを事前にマージして、より小さなカットオフ値を取得します。 プロセス全体は、Kがソートされたランの長さよりも短い場合と同様である。 違いは、十分なソートされた実行がカットオフ値を得るために事前にマージされることにあります。
課題分析
ディープページングクエリは特別なTopKクエリです。 ディープページングクエリでは、Kは非常に大きいが、実際の結果セットは小さい。 たとえば、ORDER BY列LIMIT 1000000, 100文では、Kは1,000,100ですが、実際の結果セットには100レコードしか含まれていません。 これは、前のセクションで説明したソリューションに次の課題をもたらします。
メモリが十分であり、システムが優先キューベースのTopKアルゴリズムを使用する場合、非常に大きなサイズの優先キューが維持される必要がある。 キュー動作のランダムメモリアクセスは、メモリアクセス効率を低下させ、アルゴリズムの実際の性能を低下させる。
メモリが不十分で、システムがマージソートのオフセットとリミットに基づいて切り捨てを実行する場合、ソートされたランの長さがオフセット + リミット未満である可能性があるため、マージソートの初期段階で切り捨てを実行できない可能性があります。 その結果、すべてのデータがソートされ、切り捨ての効果が影響を受けます。
このトピックでは、十分なメモリとは、アルゴリズムで少なくともK個のレコードを管理するために使用されるデータ構造をメモリにキャッシュできることを示し、TopKクエリの入力データをメモリにキャッシュできないことを示します。 実際、このトピックで説明するシナリオでは、TopKクエリの入力データのサイズは、クエリの実行に使用されるメモリのサイズよりもはるかに大きくなります。
さらに、システム設計の観点から、ディープページングのソリューションを設計する際には、次の項目を考慮する必要があります。
ディープページングとシャローページングのシナリオでクエリを実装するには、さまざまなソリューションが必要ですか? 2つのシナリオで異なるソリューションが使用される場合、システムはどのようにディープページングとシャローページングの境界を決定しますか?
システムは、メモリのサイズに基づいてメモリまたはディスクアルゴリズムをどのように適応的に選択しますか?
ソリューションデザイン
全体的なデザイン
前のセクションで説明した調査と分析を組み合わせると、PolarDB for MySQL IMCIのSort/TopK演算子を再設計して、既存のソリューションに基づいてディープページングの問題を解決します。
メモリが十分な場合は、次のメモリアルゴリズムが使用されます。
自己鮮鋭化入力フィルタソリューションは、低いメモリアクセス効率の問題を防止するために採用される。
これに基づいて、単一命令複数データ (SIMD) 命令が、フィルタリング効率を改善するために使用される。
このアルゴリズムは、深いページングと浅いページングとの間の境界を決定する必要なく、深いページングと浅いページングの両方のシナリオで使用される。
メモリが不足している場合は、次のディスクアルゴリズムが使用されます。
切り捨ては、マージソート時のオフセットとリミットに基づいて行われる。
これに基づいて、ZoneMapは、プルーニングのためのマージソートの初期段階で使用されます。 これにより、非結果セットデータに対する演算が可能な限り低減される。
メモリまたはディスクのアルゴリズムが動的に選択されます。 固定しきい値に依存する代わりに、アルゴリズムは、利用可能なメモリの量に基づいて実行中に動的に選択される。
マージソート中のオフセットおよびリミットに基づく自己鮮鋭化入力フィルタおよび切り捨ての解決策については、前のセクションで説明した。 以下のセクションでは、2つのソリューションが選択される理由について説明します。 また、以下のセクションでは、SIMD命令を使用してデータフィルタリング効率を改善する方法、ZoneMapをプルーニングに使用する方法、およびメモリまたはディスクアルゴリズムを動的に選択する方法について説明します。
SIMD-accelerated self-sharpening input filter
メモリが十分である場合、2つの主な理由で自己鮮鋭化入力フィルタソリューションが直接使用されます。
自己鮮鋭化入力フィルタソリューションでは、システムがカットオフ値を使用してデータをフィルタリングするか、ソートされたランを事前マージするかに関係なく、メモリアクセスはシーケンシャルです。 これは、優先キューの低いメモリアクセス効率を防止する。
このソリューションは、ディープページングとシャローページングの両方のシナリオで優れたクエリパフォーマンスを提供します。 ディープページングとシャローページングの境界を考慮する必要はありません。
実際、自己鮮鋭化入力フィルタソリューションは、ある程度、優先待ち行列ベースのアルゴリズムに類似している。 カットオフ値は、ヒープの先頭の要素に似ており、どちらも読み取りデータのフィルタリングに使用されます。 違いは、優先キューベースのアルゴリズムがヒープ内の最上位要素をリアルタイムで更新するのに対し、自己鮮鋭化入力フィルタソリューションは、ソートされた実行でデータを蓄積し、データのバッチを使用してカットオフ値を更新することです。
カットオフ値を使用してデータをフィルタリングすることは、自己鮮鋭化入力フィルタソリューションにおける重要なプロセスである。 このプロセスにはデータ比較が含まれ、操作は単純で反復的ですが、頻繁に実行されます。 したがって、SIMD命令は、このプロセスを加速するために使用される。 カットオフ値フィルタは、テーブルスキャンで使用される述語フィルタに似ています。 したがって、述語を処理する式を直接再利用して、フィルタリング効率を向上させ、TopKの計算時間を短縮することができます。
ZoneMapベースの剪定
メモリが不足している場合は、次の理由により、マージソートが使用され、オフセットと制限に基づいて切り捨てが実行されます。
メモリが不足しているときにシステムが自己鮮鋭化入力フィルタソリューションを使用し続ける場合、システムは蓄積されたソート済み実行をディスクに保存する必要があり、プリマージ中に外部ソートアルゴリズムを使用するため、ディスクの読み取りおよび書き込み操作が多数発生します。 メモリが十分であるシナリオで使用される自己鮮鋭化入力フィルタソリューションと比較すると、これは追加のオーバーヘッドを引き起こす。 Kが非常に大きい場合、プリマージ中に使用される外部ソートには、大量の非結果セットデータが含まれる可能性があります。 これは、TopKクエリが [offset, offset + limit) の範囲のレコードのみを取得する必要があり、[0, offset) の範囲のレコードは無関係だからです。
この場合、マージソートを使用できます。 ソートされた実行が生成されると、システムはソートされた実行のみをディスクに保存し、統計を使用して実行します。 これにより、不必要なディスクの読み取りおよび書き込み操作を防ぎ、非結果セットデータに対する操作を可能な限り削減します。
下図は、プラニングのための統計の使用方法を示しています。 図において、矢印は数軸を示し、長方形はソートされたランを示す。 軸の長方形の左右の位置は、ソートされたランの最小値と最大値を示します。 バリアは剪定のしきい値を示します。 ARRIER
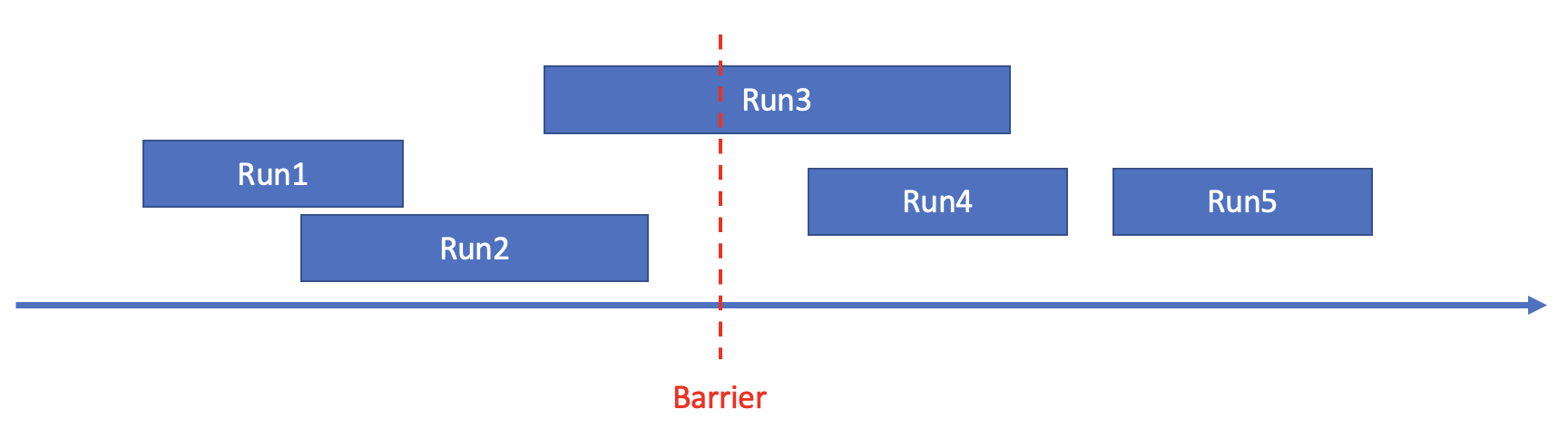
バリアは、すべてのソートされた実行を3つのタイプに分割できます。
タイプA: 最小値と最大値の両方がバリア未満であるソートされたラン。 例: Run1とRun2。
タイプB: 最小値がバリアより小さいが最大値がバリアより大きいソートされたラン。 例: 実行3。
Type C: 最小値と最大値の両方がバリアより大きいソートされた実行。 例: Run4とRun5。
バリアの場合、タイプaとタイプBのすべてのソート済みランのレコードの総数がTopKクエリのオフセット値未満の場合、タイプAのソート済みランのレコードは [0, offset) の範囲内にある必要があります。 この場合、タイプAのソートされたランは、後続のマージから除外することができる。
バリアの場合、タイプaのすべてのソート済みランのレコードの総数がTopKクエリのoffset + limitの合計よりも大きい場合、タイプCのソート済みランのレコードは [offset + limit, N) の範囲内になければなりません。 この場合、タイプCのソートされた実行は、後続のマージから除外できます。
上記のルールに基づいて、統計は次のプロセスで剪定に使用されます。
ソートされた実行の最小値と最大値を含むZoneMapを作成します。
ZoneMapで、できるだけ大きく、次の条件を満たすBarrier 1を見つけます。タイプAとタイプBのソートされた実行のレコード数がTopKクエリのオフセット未満です。
ZoneMapで、できるだけ小さく、次の条件を満たすBarrier 2を見つけます。タイプAのソートされた実行のレコード数が、TopKクエリのoffset + limitの合計よりも大きい。
Barrier1とBarrier2を使用して、関連するソート済みランを剪定します。
動的メモリまたはディスクアルゴリズムの選択
メモリアルゴリズムはディスクアルゴリズムとは異なります。 メモリまたはディスクアルゴリズムを選択するための基準として、特定のしきい値を使用することができます。 たとえば、Kがしきい値未満の場合はメモリアルゴリズムを選択し、それ以外の場合はディスクアルゴリズムを選択できます。 この場合、メモリのサイズが変更された場合は、別のしきい値を指定する必要があります。 これは、手動介入のオーバーヘッドを引き起こす。
この問題に対処するために、PolarDB for MySQLは単純なフォールバックメカニズムを使用して、実行中に使用可能なメモリのサイズに基づいて使用するアルゴリズムを動的に選択します。 アルゴリズムは、次のプロセスに基づいて選択されます。
使用可能なメモリ量に関係なく、最初にTopKの計算にメモリアルゴリズムを使用してみてください。
メモリアルゴリズムの実行中に、メモリが常に十分である場合は、メモリアルゴリズムを使用して計算全体を完了します。
メモリアルゴリズムの実行中に、メモリが不十分な場合はフォールバックメカニズムを実行します。 たとえば、使用可能なメモリが、K個を超えるレコードを含む十分にソートされた実行をキャッシュするには不十分な場合や、使用可能なメモリがプリマージを完了するには不十分な場合があります。
フォールバックメカニズム: メモリに蓄積されたソート済みランの最小値と最大値を収集し、ZoneMapを使用してソート済みランをプルーニングし、これらのソート済みランをディスクに保存できます。 これらのソートされたランは、ディスクアルゴリズムの実行に使用される。
フォールバックメカニズムが実行されたら、ディスクアルゴリズムを使用して計算全体を完了します。
同じデータ構造がメモリ及びディスクアルゴリズムで使用される。 したがって、フォールバックメカニズムはデータを再編成する必要はありません。 オーバーヘッドは小さいです。 さらに、メモリアルゴリズムは、非結果セットデータのみをフィルタリングして除去する。 メモリアルゴリズムに蓄積されたソートされたランがディスクアルゴリズムの実行に直接使用される場合、精度の問題は存在しない。
その他
後期の具体化
後期具体化は、エンジニアリング実装における最適化です。 ソートされた実行が生成されると、ORDER BYに関連する行IDと式または列のみが具体化されます。 TopKクエリの結果セットが計算された後、結果セット内の行IDに基づいてストレージから出力列が取得されます。 ソートされた実行が生成されるときの出力列のマテリアライゼーションと比較して、レイトマテリアライゼーションには次の2つの利点があります。
マテリアライズド行IDの占有スペースが少なくなります。 使用可能なメモリが同じであれば、メモリアルゴリズムを使用してより多くのデータを処理できます。
TopKの計算中にデータの順序を調整する必要があります。これには、データのコピーとスワップ操作が含まれます。 ソートされた実行が生成されたときにすべての出力列が具体化される場合、各レコードのコピーまたはスワップ操作を各列で実行する必要があり、オーバーヘッドが大きくなります。 しかし、行IDのみを実体化すれば、CopyおよびSwapのコストを削減することができる。
後期具体化の欠点は、いくつかのランダムI/O動作が、行IDに基づいてストレージから出力列を取得するために必要とされ得ることである。 ただし、分析によると、ディープページングシナリオでは、Kは非常に大きいが、実際の結果セットは小さい。 したがって、後期実体化によるランダムI/O動作のオーバーヘッドは小さい。
Computing pushdown
自己鮮鋭化入力フィルタアルゴリズムの実行中に、システムは、連続的に更新されるカットオフ値をテーブル走査演算子に押し下げる。 カットオフ値は、SQL文の新しい述語として機能します。 テーブルスキャン演算子がデータを取得すると、演算子はプルーナを再利用して、新しい述語に基づいてパックまたは行グループ内のデータをフィルタリングできます。
コンピューティングプッシュダウンは、次の2つの方法でTopKクエリのパフォーマンスを向上させます。
I/O操作の削減: テーブルスキャン中、システムは非結果セットデータのみを含むパックまたは行グループを読み取りません。
Reduce computing: フィルタ処理されたパックまたは行グループのデータは、その後の上位層演算子の計算には使用されなくなりました。
テスト結果
ソリューションの簡単な検証は、サイズが100 GBのTPC-Hデータセットに対して実行されます。
select
l_orderkey,
sum(l_quantity)
から
lineitem
グループによって
l_orderkey
による注文
sum(l_quantity) desc
制限
1000000、100; 次の表にテスト結果を示します。
PolarDB IMCI | ClickHouse | MySQL |
11.63秒 | 23.07秒 | 353.15秒 |