PolarDBは、DDL物理レプリケーション最適化をサポートします。 この機能は、プライマリノードでredoログを書き込み、読み取り専用ログでredoログを使用するキーパスを最適化します。 この機能により、プライマリノードでのDDL操作の実行と、読み取り専用ノードでのDDL操作によって生成されるredoログの解析が大幅に高速化されます。 このトピックでは、DDL物理レプリケーション最適化機能の使用方法について説明します。
前提条件
PolarDBクラスターは、次のいずれかのバージョン要件を満たしています。 クラスターエンジンのバージョンを照会する方法の詳細については、「エンジンバージョン」をご参照ください。
リビジョンバージョンが8.0.1.1.10以降のPolarDB for MySQL 8.0.1クラスター。
リビジョンバージョンが5.7.1.0.10以降のPolarDB for MySQL 5.7クラスター。
制限事項
この機能は、プライマリキーまたはセカンダリインデックスの作成に使用されるDDL操作のみをサポートします。 これらのインデックスには、フルテキストインデックスと空間インデックスは含まれません。
この機能は、名前変更操作など、メタデータのみを変更するDDL操作には必要ありません。これらの操作の実行で消費されるリソースはごくわずかなためです。
この機能は、PolarDB for MySQL 8.0.2 5.6ではサポートされていません。
背景
PolarDBは、ストレージリソースからコンピューティングを分離し、プライマリノードと読み取り専用ノードが同じ格納データを共有できるようにします。 これにより、ストレージコストが削減され、クラスターの可用性と信頼性が向上します。 PolarDBは、物理レプリケーション技術を使用して、共有ストレージに基づいてプライマリノードと読み取り専用ノード間でデータの一貫性を実現します。 また、バイナリログに対するfsync操作によって引き起こされるI/Oオーバーヘッドも削減されます。
InnoDB内のデータは、B-treeインデックスによってインデックス付けされます。 ほとんどの場合、低速DDL操作のためにBツリーインデックスを再構築または作成する必要があります。 たとえば、プライマリキーの作成、セカンダリインデックスの作成、またはテーブルの最適化には、Bツリーインデックスが必要です。 これにより、多数のredoログが生成されます。 ただし、redoログに対する操作は、多くの場合、DDL操作のキーパスで実行されます。 これは、DDL動作の実行時間を増加させる。 さらに、物理レプリケーション技術では、新しく生成されたredoログを解析して適用するために読み取り専用ノードが必要です。 DDL操作によって生成された多数のredoログは、読み取り専用ノードのログ同期プロセスに重大な影響を与えたり、読み取り専用ノードが使用できなくなったりする可能性があります。
上記の問題を修正するために、PolarDBはDDL物理レプリケーション最適化機能を提供します。これは、プライマリノードでのredoログの書き込みと読み取り専用ノードでのredoログの使用の主要なパスを最適化します。 このようにして、プライマリノード上でプライマリキーを作成するDDL動作の実行時間を約20.6% に短縮することができる。 読み取り専用ノードでDDL操作によって生成されたredoログを解析するためのレプリケーション待ち時間は、約0.4% に短縮できます。
物理レプリケーションの最適化の有効化
次のパラメーターを指定して、DDL物理レプリケーション最適化機能を有効にできます。
パラメーター | レベル | 説明 |
innodb_bulk_load_page_grained_redo_enable | グローバル | DDL物理レプリケーション最適化機能を有効にするかどうかを指定します。 デフォルト値: OFF。 有効な値:
|
パフォーマンステスト
準備
テスト環境
16 CPUコアと128 GBのメモリを備えたPolarDB for MySQL 8.0クラスター (1つのプライマリノードと1つの読み取り専用ノードを含む) 。
クラスターのストレージ容量は50テラバイトです。
Schema
t0という名前のテーブルを作成します。CREATE TABLE t0 (INTプライマリーキー、b INT) ENGINE=InnoDB;Data
テーブルにデータをランダムに挿入します。
DELIMITER // CREATE PROCEDURE populate_t0() 開始 DECLARE i int DEFAULT 1; WHILE (i <= $table_size) t0値 (i、1000000 * RAND()) に挿入します。 セットi = i + 1; END WHILE; END // DELIMITER; CALL populate_t0();説明テストでは、
$table_sizeを1000000などのテーブル内のレコード数に置き換えます。このテストでは、100万行、100万行、10億行のデータを含むテーブルを使用します。
テストで使用されたDDL操作。
プライマリキーの追加セカンダリインデックスの追加最適化テーブル
テスト方法
テスト1: 物理レプリケーション最適化機能が有効または無効になっているときに、行数の異なるテーブルに対して異なるDDL操作を実行するのに必要な時間を比較します。
テスト2: Parallel DDLの有無にかかわらず、物理レプリケーション最適化機能を使用する場合に、10億行のテーブルで
セカンダリインデックスの追加を実行するのに必要な時間を比較します。テスト3: 物理レプリケーション最適化機能が有効または無効になっている場合の読み取り専用ノードのパフォーマンスをテストします。 パフォーマンスのメトリックには、ノードのステータス、ピークCPU使用率、レプリケーション遅延が含まれます。 このテストでは、クラスター内のプライマリノードでの同時DDL操作の数は1、2、4、6、および8であり、クラスターには10億行のテーブルが含まれています。
Results:
テスト1
innodb_bulk_load_page_grained_redo_enableがONまたはOFFに設定されている場合、行数の異なるテーブルに対して
主キー (a) の追加操作を実行するのに必要な時間 (秒) をテストします。 このテストでは、100万行、100万行、10億行のデータを含むテーブルを使用します。 以下の図にテスト結果を示します。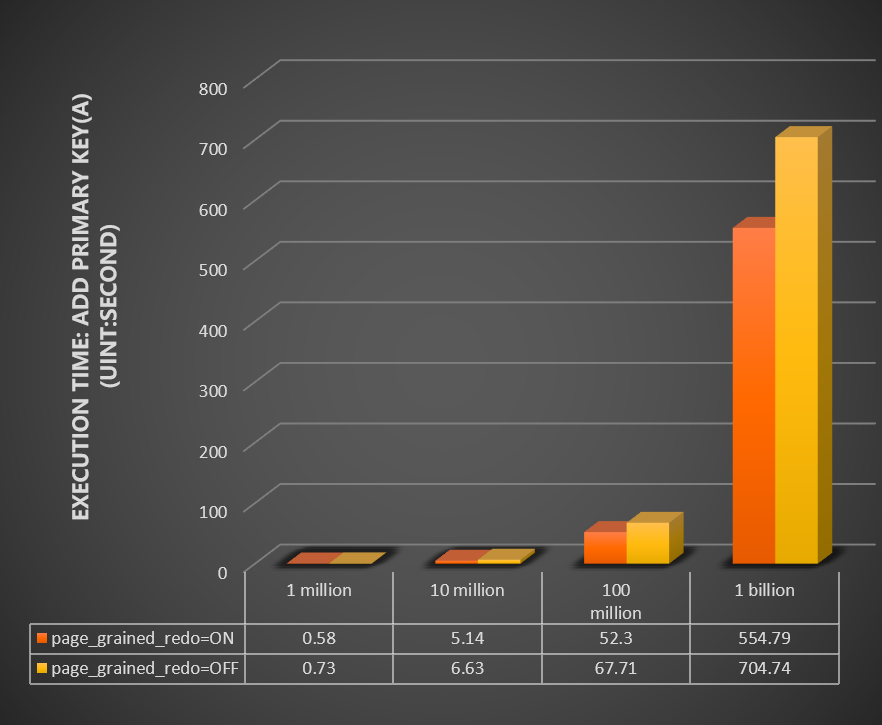
innodb_bulk_load_page_grained_redo_enableがONまたはOFFに設定されている場合、行数の異なるテーブルに対して
テーブルの最適化操作を実行するのに必要な時間 (秒) をテストします。 このテストでは、100万行、100万行、10億行のデータを含むテーブルを使用します。 以下の図にテスト結果を示します。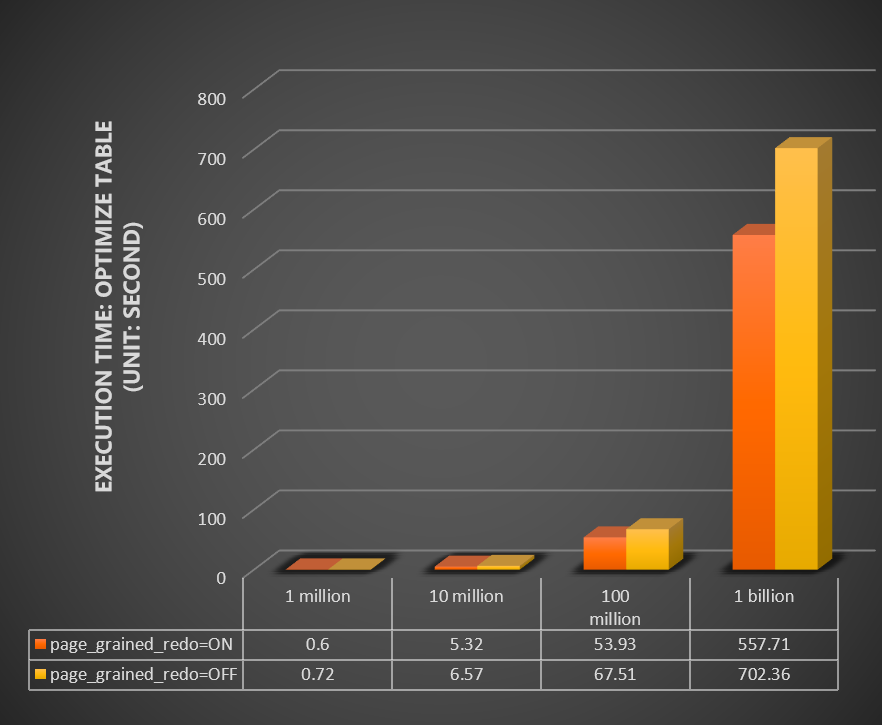
テスト2
Parallel DDL機能のinnodb_polar_use_sample_sortおよびinnodb_polar_use_parallel_bulk_loadを有効にします。 innodb_bulk_load_page_grained_redo_enableがONまたはOFFに設定されている場合、10億行のテーブルに対して
セカンダリインデックスの追加操作を実行するのに必要な時間 (秒) をテストします。 このテストでは、並列スレッドの数を指定するinnodb_polar_parallel_ddl_threadsパラメーターは、1、2、4、8、16、および32に設定されます。 以下の図にテスト結果を示します。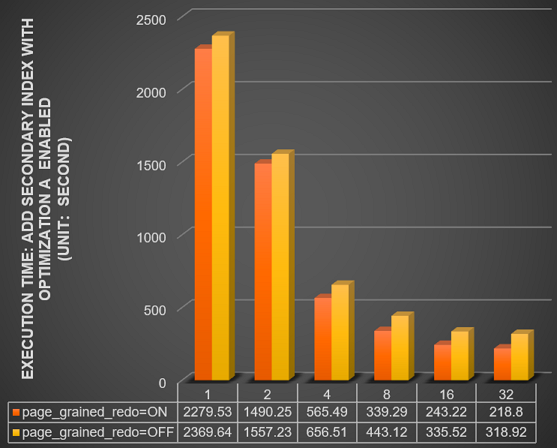
パラレルDDL機能のinnodb_polar_use_sample_sortおよびinnodb_polar_use_parallel_bulk_loadを無効にします。 innodb_bulk_load_page_grained_redo_enableがONまたはOFFに設定されている場合、10億行のテーブルに対して
セカンダリインデックスの追加操作を実行するのに必要な時間 (秒) をテストします。 このテストでは、並列スレッドの数を指定するinnodb_polar_parallel_ddl_threadsパラメーターは、1、2、4、8、16、および32に設定されます。 以下の図にテスト結果を示します。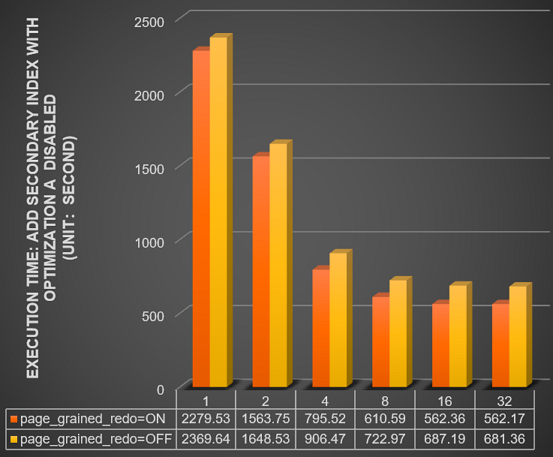
テスト3
innodb_bulk_load_page_grained_redo_enableがONに設定されている場合、読み取り専用ノードのパフォーマンスをテストします。 このテストでは、クラスター内のプライマリノードでの同時DDL操作の数は1、2、4、6、および8であり、クラスターには10億行のテーブルが含まれています。 次の表にテスト結果を示します。
同時DDL操作の数
1
2
4
6
8
読み取り専用ノードのステータス
正常
正常
正常
正常
正常
ピークCPU使用率 (%)
1.86
1.71
1.76
2.25
2.36
ピークメモリ使用率 (%)
10.37
10.80
10.88
11
11.1
IOPSの読み取り (1秒あたりの読み取り)
10965
10762
10305
10611
10751
ピークレプリケーション待ち時間
0
0.73
0.87
0.93
0.03
innodb_bulk_load_page_grained_redo_enableがOFFに設定されている場合、読み取り専用ノードのパフォーマンスをテストします。 このテストでは、クラスター内のプライマリノードでの同時DDL操作の数は1、2、4、6、および8であり、クラスターには10億行のテーブルが含まれています。 次の表にテスト結果を示します。
説明同時DDL操作の数が4の場合、テスト結果には読み取り専用ノードが使用できなくなる前のデータが表示されます。
表の
ハイフン (-)は、特定の数の同時DDL操作のシナリオでDDL操作が実行されないことを示します。 したがって、テスト結果は返されません。
同時DDL操作の数
1
2
4
6
8
読み取り専用ノードのステータス
正常
正常
使用できません
使用できません
使用できません
ピークCPU使用率 (%)
4.2
9.5
10.3
-
-
ピークメモリ使用率 (%)
22.15
23.55
68.61
-
-
IOPSの読み取り (1秒あたりの読み取り)
9243
7578
7669
-
-
ピークレプリケーション待ち時間
0.8
14.67
211
-
-