PolarDBクラスターは、システム障害が発生すると、プライマリノードから読み取り専用ノードにサービスを自動的にフェールオーバーできます。 読み取り専用ノードを新しいプライマリノードとして指定して、手動フェールオーバーを実行することもできます。
注意事項
自動または手動フェールオーバー中、読み取り専用ノードのホットスタンバイが無効になっている場合、データベースサービスが約20〜30秒間中断されることがあります。 この場合、データベースへの接続が中断される可能性があります。 アプリケーションがクラスターに自動で再接続されることをご確認ください。 読み取り専用ノードでホットスタンバイが有効になっている場合、フェールオーバーは5〜10秒以内に完了できます。 読み取り専用ノードのホットスタンバイを有効にする方法については、「ホットレプリカノードの設定」をご参照ください。
特定の極端なケースでは、フェールオーバー中のデータベースの中断時間が増加する可能性がありますが、3分を超えません。
自動フェイルオーバー
cluster EditionのPolarDBクラスターは、アクティブ-アクティブ高可用性アーキテクチャを使用します。 プライマリノードに障害が発生すると、システムは自動的に読み取り専用ノードから新しいプライマリノードを選択し、元のプライマリノードから新しいプライマリノードへのサービスをフェールオーバーします。
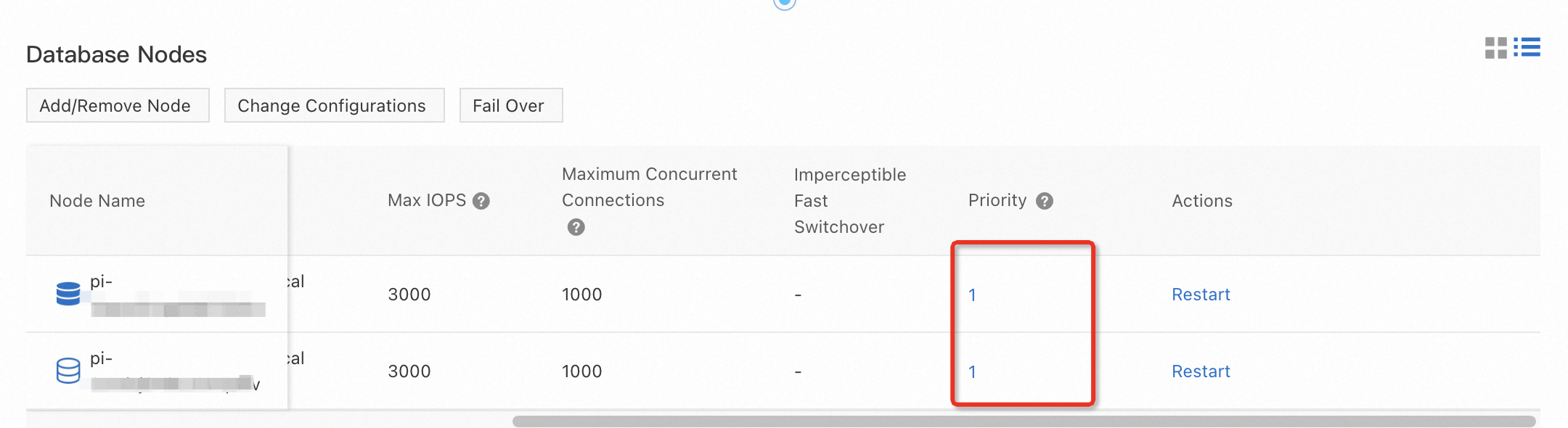
クラスタ内の各ノードにフェイルオーバー優先度が割り当てられます。 優先順位は、フェイルオーバー中にどのノードをプライマリノードとして選択できるかを決定する。 複数のノードが同じ優先度を有する場合、それらは、プライマリノードとして選択される同じ確率を有する。
システムは次の手順を実行して、プライマリノードを選択します。
プライマリノードとして選択できるすべての使用可能な読み取り専用ノードを見つけます。
フェールオーバーの優先度が最も高い読み取り専用ノードを選択します。
ネットワークの問題、異常なレプリケーション状態、またはその他の理由により、最初の読み取り専用ノードへのフェールオーバーが失敗した場合、フェールオーバーが成功するまで、システムは次の読み取り専用ノードへのサービスのフェールオーバーを試みます。
クラスターの データベースノード ページの 概要 セクションで、クラスター内の各ノードのフェールオーバー優先度を表示および設定できます。
新しいプライマリノードとして選択された読み取り専用ノードのホットスタンバイが無効になっている場合、フェールオーバー中にデータベースサービスが約20〜30秒間中断されることがあります。 この場合、データベースへの接続が中断される可能性があります。 アプリケーションがクラスターに自動で再接続されることをご確認ください。
新しいプライマリノードとして選択された読み取り専用ノードでホットスタンバイが有効になっている場合、フェールオーバーは5〜10秒以内に完了できます。
特定の極端なケースでは、フェールオーバー中のデータベースの中断時間が増加する可能性がありますが、3分を超えません。
手動フェールオーバー
読み取り専用ノードを新しいプライマリノードとして指定して、手動フェールオーバーを実行することもできます。 手動フェイルオーバーは、クラスターの高可用性をテストするか、特定の読み取り専用ノードをクラスターのプライマリノードとして指定する必要があるシナリオに適しています。
PolarDBコンソールにログインします。
左上隅で、接続するクラスターがデプロイされているリージョンを選択します。
クラスターを見つけて、そのIDをクリックします。
では、データベースノードのセクション概要ページをクリックし、
 ビューを切り替えるには、セクションの右上隅にあるアイコン。
ビューを切り替えるには、セクションの右上隅にあるアイコン。 フェイルオーバーをクリックします。
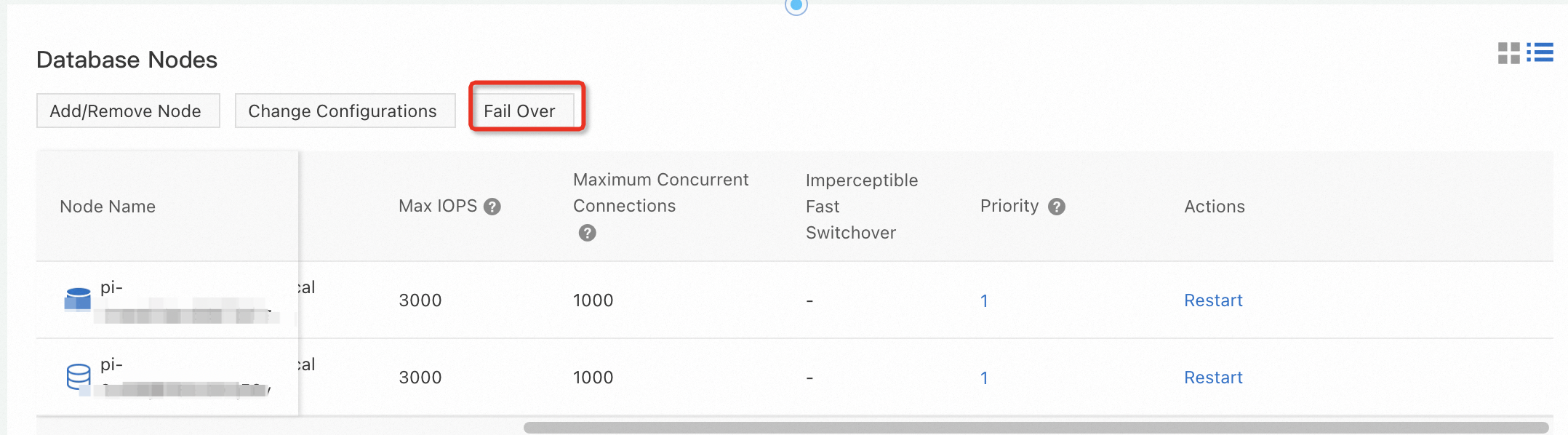
表示されるダイアログボックスで、新しいプライマリノードパラメーターを設定し、OKをクリックします。
説明新しいプライマリノードとして指定されている読み取り専用ノードのホットスタンバイが無効になっている場合、フェールオーバー中にデータベースサービスが約20〜30秒間中断されることがあります。 この場合、データベースへの接続が中断される可能性があります。 アプリケーションがクラスターに自動で再接続されることをご確認ください。
新しいプライマリノードとして指定された読み取り専用ノードに対してホットスタンバイが有効になっている場合、フェールオーバーは5〜10秒以内に完了できます。
特定の極端なケースでは、フェールオーバー中のデータベースの中断時間が増加する可能性がありますが、3分を超えません。
よくある質問
フェールオーバーが完了してから10分後に、クラスターのステータスが [実行中] に戻りません。 考えられる原因は何ですか? 問題を処理するにはどうすればよいですか?
アプリケーションとクラスターの間に永続的な接続が確立されている場合、異常がフェールオーバーをトリガーしたときに、アプリケーションが変更された接続ステータスを検出できない場合があります。 ソケットのタイムアウト期間が指定されていない場合、アプリケーションはデータベースが結果を返すのを待ちます。 ほとんどの場合、アプリケーションは数百秒後に切断されます。 この間に, データベースへの接続に異常が発生し, 多数のSQL文の実行に失敗します。
無効な接続を回避するには、connectTimeoutパラメーターとsocketTimeoutパラメーターを指定して、ネットワークエラーによる長時間の待機を防ぐことを推奨します。 これにより、故障からの回復に要する時間が短縮される。
これらのパラメーターは、ワークロードと使用モードに基づいて指定する必要があります。 オンライン取引シナリオの推奨値:
connectTimeout: このパラメーターを1〜2秒に設定することを推奨します。
socketTimeout: 内部ネットワーク環境の場合、このパラメーターを10〜15秒に設定することを推奨します。 パブリックネットワーク環境の場合、このパラメーターを60〜90秒に設定することを推奨します。
説明上記の値は参照用です。
関連する API 操作
API 操作 | 説明 |
読み取り専用ノードを新しいプライマリノードとして指定することで、PolarDBクラスターで手動フェールオーバーを実行します。 |