このトピックでは、サービスを呼び出すときに返される状態コードと一般的なエラーについて説明します。
ステータスコードの説明
ステータスコード | 説明 |
200 | サービスはリクエストを正常に処理しました。 |
400 | リクエストボディのフォーマットが正しくありません、またはカスタムプロセッサコードで例外が発生しました。 説明 カスタムプロセッサコードが例外をスローした場合、サーバーは 400 状態コードを返します。これを他のエラーと区別するには、例外に対して特定の状態コードを返すようにカスタムプロセッサを構成します。 |
401 | サービス認証に失敗しました。詳細については、「401 認証失敗」をご参照ください。 |
404 | サービスが見つかりません。詳細については、「404 Not Found」をご参照ください。 |
405 | 許可されていないメソッドです。たとえば、GET リクエストのみをサポートするサーバーに POST リクエストを送信すると、サーバーは 405 エラーを返します。別の HTTP メソッドを使用してみてください。 |
408 | リクエストがタイムアウトしました。サーバーには、各リクエストに対してデフォルトで 5 秒のタイムアウトがあります。これは、サービスを作成する際に JSON ファイルの 説明 単一のリクエストの合計処理時間には、プロセッサの計算時間、ネットワークデータパケットの受信時間、およびキューでの待機時間が含まれます。 |
429 | リクエストがレート制限をトリガーしました。
|
450 | |
499 | クライアントが接続を閉じました。クライアントがアクティブに接続を閉じても、499 状態コードは受信しません。代わりに、サーバーはその接続からの未処理のリクエストを 499 状態コードでログに記録します。たとえば、クライアントの HTTP タイムアウトが 30 ms で、サーバー側の処理遅延が 50 ms の場合、クライアントは 30 ms 後にリクエストを破棄して接続を閉じます。すると、サーバー側のモニタリングに 499 状態コードが表示されます。 |
500 | 内部サーバーエラーです。サーバーがリクエストの実行を妨げる予期しない条件に遭遇しました。 |
501 | 実装されていません。サーバーはリクエストを処理するために必要な機能をサポートしていません。 |
502 | 不正なゲートウェイです。ゲートウェイまたはプロキシとして機能しているサーバーが、アップストリームサーバーから無効な応答を受信しました。 |
503 | サービスを利用できません。ゲートウェイ経由でサービスにアクセスする際に、すべてのバックエンドサービスインスタンスが準備完了状態でない場合、ゲートウェイは 503 状態コードを返します。詳細については、「503 no healthy upstream」をご参照ください。 |
504 | ゲートウェイタイムアウトです。詳細については、「504 timeout」をご参照ください。 |
505 | サポートされていない HTTP バージョンです。サーバーはリクエストで使用された HTTP プロトコルのバージョンをサポートしていません。 |
SDK 呼び出しエラーコード
公式の EAS SDK を使用してサービスを呼び出す場合、SDK はサーバーが返すエラーコードとは異なる独自のエラーコードを生成することがあります。常にゲートウェイとサービスのログにあるエラーコードを信頼できる情報源として参照してください。
状態コード | 説明 |
512 | EAS Golang SDK を使用している場合、クライアントがアクティブに切断すると、SDK は 512 エラーコードを返します。このクライアント側のタイムアウトは、サーバー側の 499 状態コードに対応します。 |
一般的なエラー
404 Not Found
404 エラーは通常、無効なリクエストパス、不正なリクエストボディ、またはサービスがサポートしていない API を示します。受信した特定のエラーメッセージに基づいて、以下のシナリオを使用してトラブルシューティングを行ってください。
エラータイプ 1: {"object":"error","message":"The model `` does not exist.","type":"NotFoundError","param":null,"code":404}
原因: vLLM でデプロイされたサービスの /v1/chat/completions エンドポイントを呼び出す際に、リクエストボディの model パラメーターが空または無効です。
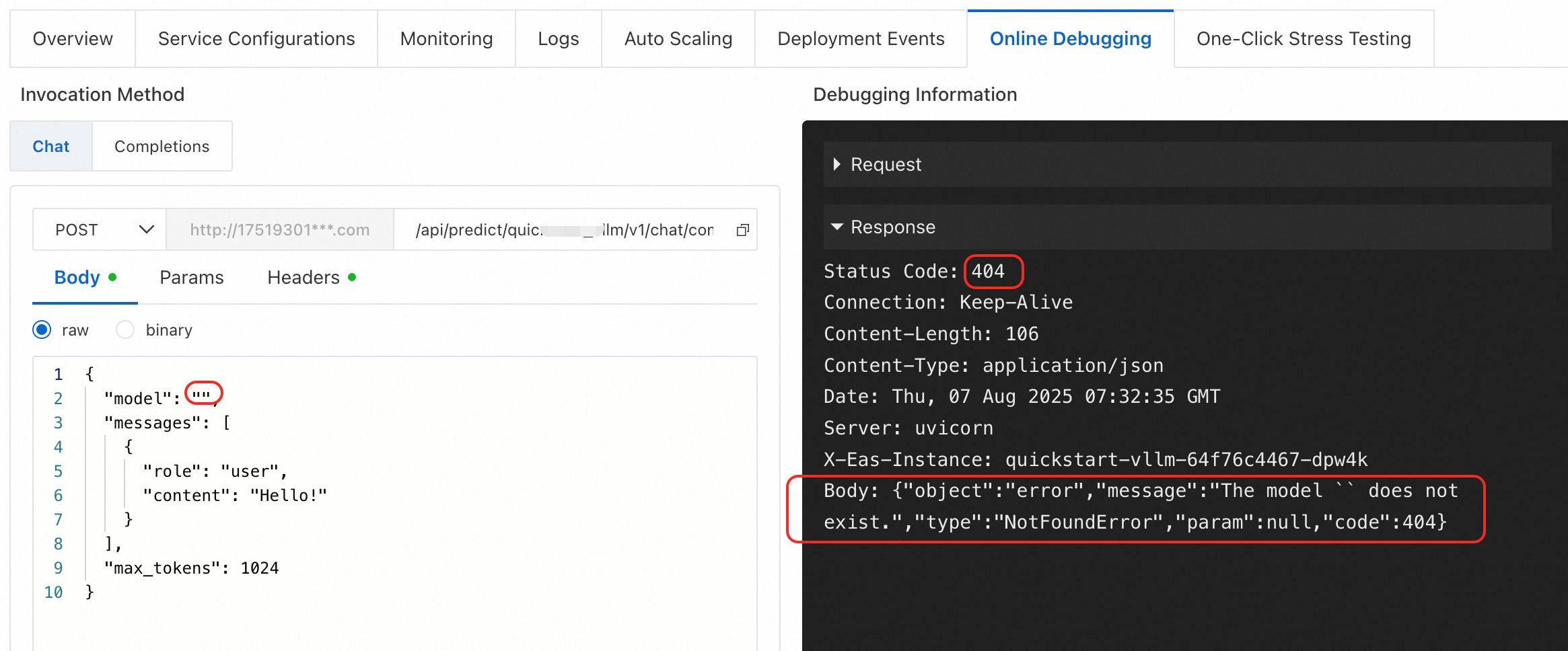
解決策: model パラメーターの値は、有効なモデル名である必要があります。v1/models エンドポイントを使用して、有効なモデル名をクエリします。
エラータイプ 2: {"detail":"Not Found"}
原因: リクエストパスが不完全または正しくありません。たとえば、LLM サービスのチャットエンドポイントを呼び出す際に、ベース URL に v1/chat/completions パスを追加していません。
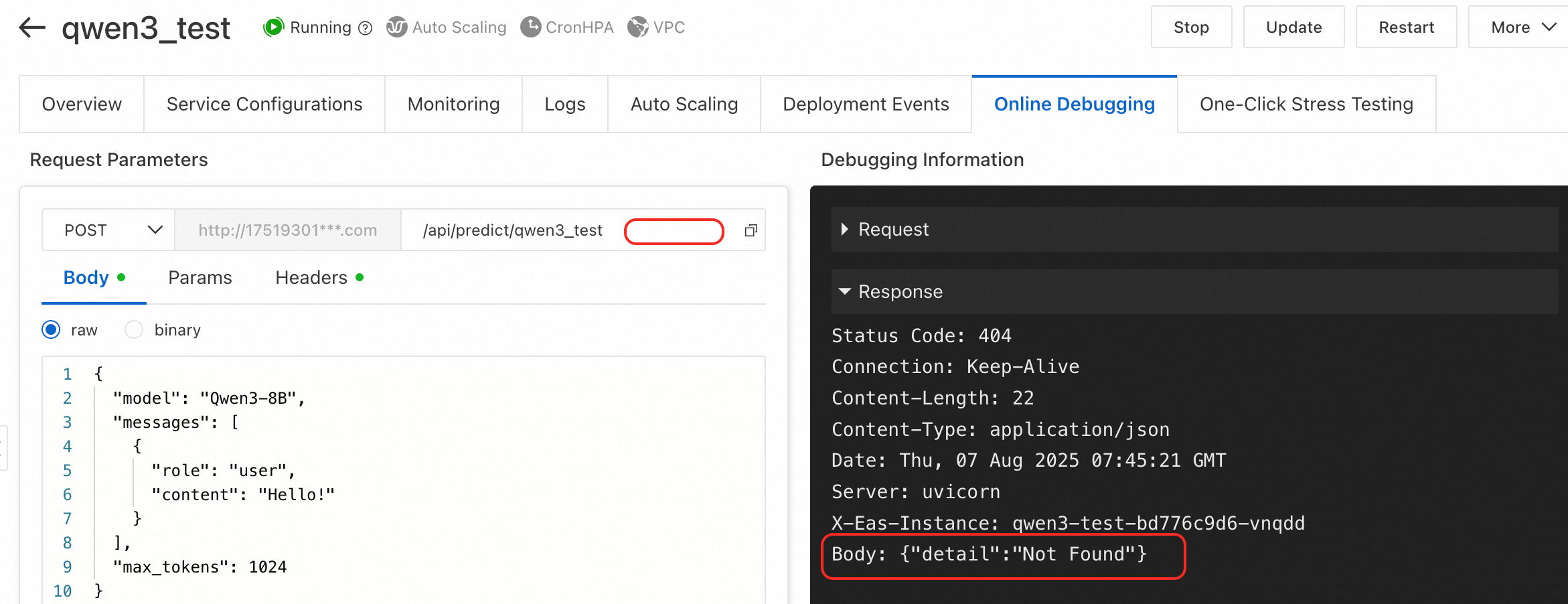
解決策: API リクエストパスが完全かつ正しいことを確認してください。LLM サービスについては、「LLM サービスの呼び出し」をご参照ください。
エラータイプ 3: BladeLLM の /v1/models エンドポイントを呼び出すと 404: Not Found が返されます。
原因: BladeLLM でデプロイされたサービスは v1/models エンドポイントをサポートしていません。
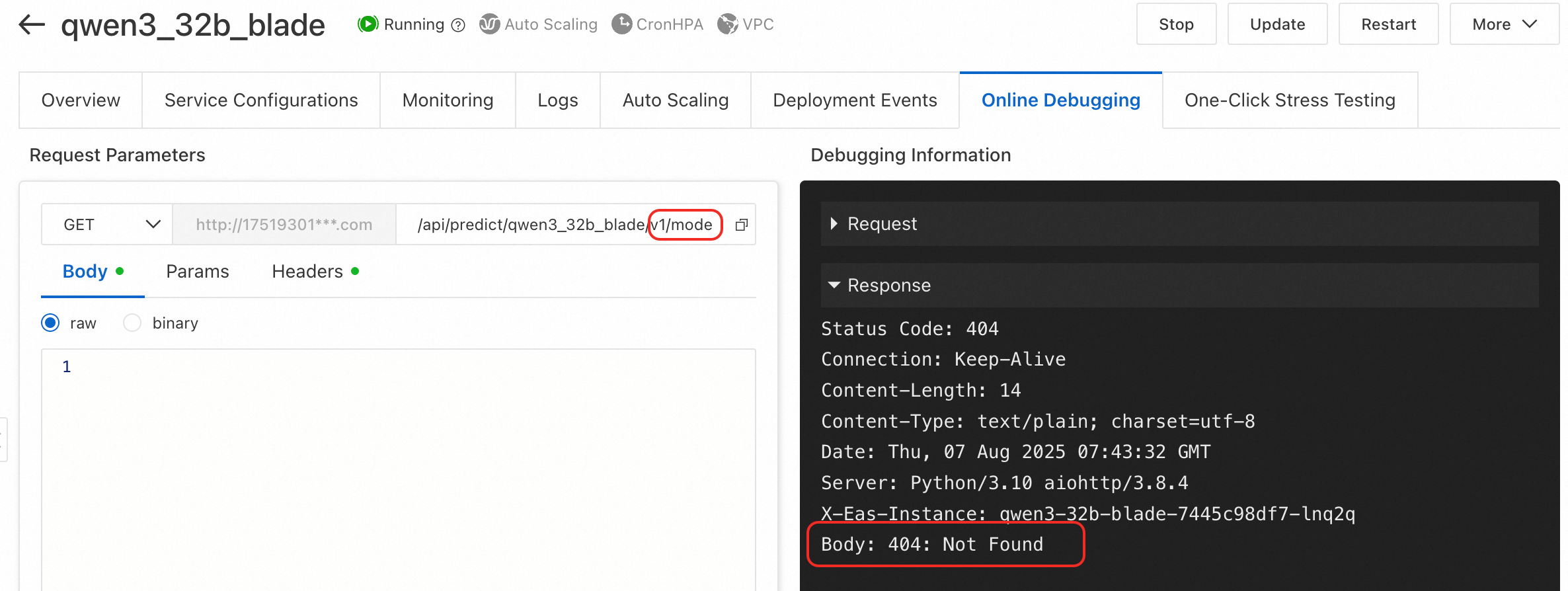
解決策: サポートされている API のリストについては、「BladeLLM サービス呼び出しのパラメーター構成」をご参照ください。
エラータイプ 4: オンラインデバッグページで、他の情報なしで 404 エラーが返されます。
原因: リクエストパスが正しくありません。オンラインデバッグを使用する場合、ベース URL は通常 http://123***.cn-hangzhou.pai-eas.aliyuncs.com/predict/service_name です。URL のサービス名部分を誤って変更または削除すると、404 エラーが発生します。
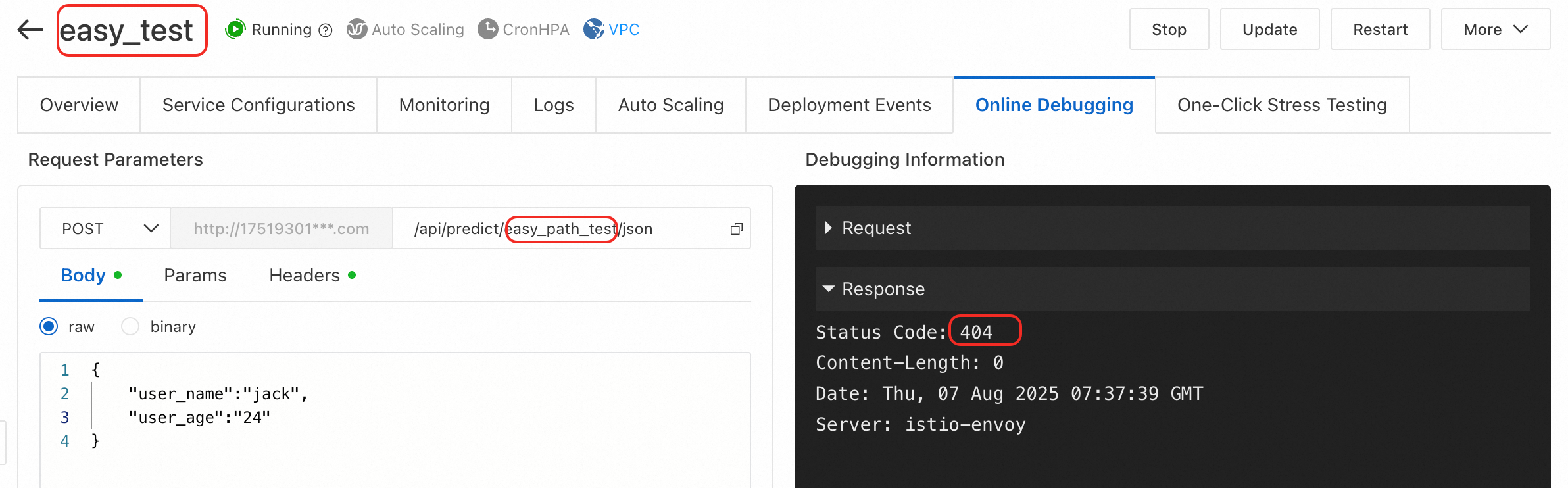
解決策: オンラインデバッグを使用する場合、通常はデフォルトの URL を変更または削除する必要はありません。呼び出す必要がある特定の API パスを追加してください。
エラータイプ 5: ComfyUI への API 呼び出しで "404 not found page" が返されます。
400 Bad Request
リクエストボディのフォーマットが正しくありません。JSON 構造、フィールド名、データの型など、リクエストボディのフォーマットを注意深く確認してください。
401 認証失敗
認証トークンが見つからない、正しくない、または不適切に使用されています。以下を確認してください:
トークンが正しいか確認します。サービスの [概要] ページで、[基本情報] セクションの [呼び出し情報を表示] をクリックします。
説明デフォルトでは、サービスは認証トークンを自動的に生成します。カスタムトークンを指定し、サービスの更新時に更新することもできます。
トークンが正しく設定されているか確認します。
curlコマンドを使用する場合は、HTTP ヘッダーのAuthorizationフィールドにトークンを追加します。例:curl -H 'Authorization: NWMyN2UzNjBiZmI2YT***' http:// xxx.cn-shanghai.aliyuncs.com/api/predict/echo。SDK を使用してサービスにアクセスする場合は、対応する
SetToken()関数を呼び出します。詳細については、「Java SDK の使用手順」をご参照ください。
504 timeout
ゲートウェイまたはプロキシとして機能しているサーバーが、アップストリームサーバーから時間内に応答を受信しませんでした。これは通常、モデルの推論に時間がかかりすぎていることを意味します。この問題を解決するには:
クライアントコードで、HTTP リクエストのタイムアウトを増やします。
長時間実行されるタスクには、バッチまたは長時間実行される推論タスクを処理するように設計されている EAS キューサービス (非同期呼び出し) モードを使用します。
450: キューがいっぱいのためリクエストが破棄されました
サーバーサイドのコンピューティングインスタンスがリクエストを受信すると、まずそのリクエストをキューに配置します。インスタンス内のワーカーが利用可能になると、処理のためにキューからデータを取得します。デフォルトのワーカー数は 5 で、サービスの作成 JSON ファイルの metadata.rpc.worker_threads フィールドを使用して調整できます。ワーカーの処理時間が長すぎると、リクエストがキューに蓄積される可能性があります。キューがいっぱいになると、インスタンスは、過剰なキューイングによってレイテンシーが増加し、サービスが利用できなくなるのを防ぐために、450 ステータスコードで新しいリクエストをすぐに拒否します。デフォルトのキューの長さは 64 で、サービスの作成 JSON ファイルの metadata.rpc.max_queue_size フィールドを使用して調整できます。
キューの長さを制限することは、トラフィックスパイクによるサービスのカスケード障害を防ぐためのレート制限の一形態としても機能します。
解決策:
少数の 450 状態コードを受信した場合は、リクエストをリトライできます。サーバー側のインスタンスは独立しているため、リトライは混雑していないインスタンスにルーティングされる可能性があり、クライアントには問題が透過的になります。ただし、レート制限保護の目的を損なうため、無期限にリトライしないでください。
すべてのリクエストが 450 状態コードを返す場合、プロセッサ内のコードがスタックしている可能性があります。すべてのワーカーがリクエストの処理中にデッドロックし、キューからデータを取得しなくなった場合は、プロセッサのコードをデバッグしてバグを見つける必要があります。
503 no healthy upstream
オンラインデバッグ中に「no healthy upstream」というメッセージとともに 503 エラーが表示されます:

次のように問題をトラブルシューティングします:
インスタンスの状態を確認します。インスタンスが停止している場合は、[サービスの再起動] を行います。
サービスの状態が [実行中] の場合、インスタンスに CPU、メモリ、GPU メモリなどのリソースが不足している可能性があり、バッファースペースが不足します。
パブリックリソースを使用している場合は、オフピーク時間帯に再度呼び出しを試みるか、別のリソース仕様またはリージョンに切り替えてください。
専用リソース (EAS リソースグループ) を使用している場合は、リソースグループがインスタンスに十分な CPU、メモリ、および GPU メモリを予約していることを確認してください。バッファーとして少なくとも 20% のリソースを空けておくことをお勧めします。
もう 1 つの一般的なシナリオは、デプロイ後にサービスの状態が [実行中] で、すべてのインスタンスが [準備完了] になっている場合です。ただし、リクエストがコード内のバグをトリガーし、バックエンドサービスインスタンスがクラッシュして応答しなくなります。この状況では、ゲートウェイはクライアントに 503 状態コードを返します。バグを特定して修正するには、ログを使用します。
エラー: 予期しないトークン 12606 (期待値: 開始トークン 200006)
vllm を使用して gpt-oss をデプロイすると、サービス呼び出しで次のエラーが返されることがあります:

解決策: SGLang アクセラレーションを使用してデプロイしてみてください。
curl 呼び出しエラー: no URL specified
次のコマンドでリクエストを送信すると、no URL specified エラーが表示されます:
curl -X http://17****.cn-hangzhou.pai-eas.aliyuncs.com/api/predict/service_name/**path** \
-H "Content-Type: application/json" \
-H "Authorization: **********==" \
-d '{"***":"****"}'原因: curl コマンドは -X フラグを使用していますが、POST などのメソッドがありません。
呼び出しが ASCII エンコーディングを返す
次のようにコードを変更します:
from flask import Flask, Response
@app.route('/hello', methods=['POST'])
def get_advice():
result = "result"
return Response(result, mimetype='text/plain', charset='utf-8')サービスログの "[WARN] connection is closed: End of file" または "Write a Invalid stream: End of file" を解決する方法
この警告ログは、クライアントまたはサーバーが接続を閉じたこと、およびサーバーがその閉じた接続に応答を書き込もうとしていたことを示します。接続は 2 つの方法で閉じることができます:
サーバー側のタイムアウト: プロセッサモードでは、デフォルトのサーバー側タイムアウトは 5 秒です。これは、サービスの
metadata.rpc.keepaliveパラメーターを使用して変更できます。タイムアウトに達すると、サーバーは接続を閉じ、モニタリングに 408 状態コードを記録します。クライアント側のタイムアウト: 呼び出し元のコードの設定によってクライアント側のタイムアウトが決まります。クライアントが設定されたタイムアウト期間内に HTTP 応答を受信しない場合、クライアントはアクティブに接続を閉じます。その後、サーバーはモニタリングに 499 状態コードを記録します。
upstream connect error or disconnect/reset before headers. reset reason: connection termination
持続的接続のタイムアウトやインスタンスの負荷の不均衡などの問題が、通常このエラーの原因となります。サーバー側の処理時間がクライアントで構成された HTTP タイムアウトを超えると、クライアントはリクエストを破棄し、アクティブに接続を閉じます。その後、サーバー側のモニタリングに 499 状態コードが表示されます。詳細な確認のためにモニタリングメトリックを確認できます。時間のかかる推論タスクの場合は、非同期推論サービスをデプロイします。
Tensorflow/Pytorch プロセッサでデプロイされたサービスのオンラインデバッグの失敗を解決する方法
パフォーマンス上の理由から、TensorFlow/PyTorch プロセッサはリクエストボディに非プレーンテキストの protobuf フォーマットを使用します。オンラインデバッグは現在、プレーンテキストのテキスト入力のみをサポートしています。したがって、これらのプロセッサでデプロイされたサービスをコンソールで直接デバッグすることはできません。提供されている EAS SDK を使用してサービスを呼び出してください。さまざまな言語の SDK の情報については、「サービス呼び出し SDK」をご参照ください。