標準化は、特徴データを統一された次元に変換するデータ前処理技術である。 標準化コンポーネントは、平均を0に、標準偏差を1に設定することによって、異なるフィーチャの寸法を統一します。 標準化は、モデル、特に勾配降下最適化アルゴリズムを使用するモデルの収束および性能を強化することができる。
アルゴリズムの説明
テーブル内の1つ以上の列を標準化し、生成されたデータを新しいテーブルに保存できます。
以下の式を標準化のために使用する :( X − 平均)/(標準偏差) 。
平均: サンプルの平均。
標準偏差: サンプルの標準偏差。 標準偏差は、サンプルを使用して総偏差を計算する場合に使用される。 標準化後に得られた値を平均に近づけるには、式
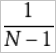 を使用して計算された標準偏差を適度に大きくする必要があります。
を使用して計算された標準偏差を適度に大きくする必要があります。サンプルの標準偏差を計算するために使用される式は
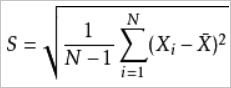 である。
である。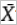 は、サンプルX1、X2、... 、およびXnの平均を表す。
は、サンプルX1、X2、... 、およびXnの平均を表す。
コンポーネントの設定
方法1: パイプラインページでコンポーネントを設定する
Machine Learning Designerのパイプラインページに標準化コンポーネントを追加し、ページの右側にある次の表に示すコンポーネントパラメーターを設定します。
タブ | パラメーター | 説明 |
フィールドの設定 | デフォルトですべて選択 | デフォルトですべて選択します。 余分な列は予測結果に影響しません。 |
元の列を予約する | 処理された列の先頭には「stdized_」があります。 DOUBLEおよびBIGINTタイプをサポートします。 | |
入力スパース行列 | スパース形式の入力データをサポートするかどうかを指定します。 この機能を有効にする場合は、次のパラメーターを設定します。
| |
チューニング | コア | コアの数。 システムは、入力データの量に基づいて、トレーニングに使用されるコアを自動的に割り当てます。 |
コアあたりのメモリサイズ | 各コアのメモリサイズ。 システムは、入力データの量に基づいてメモリを自動的に割り当てます。 単位:MB。 |
方法2: PAIコマンドを使用する
PAIコマンドを使用して標準化コンポーネントパラメーターを設定します。 SQLスクリプトコンポーネントを使用してPAIコマンドを呼び出すことができます。 詳細については、「シナリオ4: SQLスクリプトコンポーネント内でPAIコマンドを実行する」をご参照ください。
高密度データのコマンド
PAI -name Standardize -project algo_public -DkeepOriginal="false" -DoutputTableName="test_5" -DinputTablePartitions="pt=20150501" -DinputTableName="bank_data_partition" -DselectedColNames="euribor3m,pdays"スパースデータのコマンド
PAI -name Standardize -project projectxlib4 -DkeepOriginal="true" -DoutputTableName="kv_standard_output" -DinputTableName=kv_standard_test -DselectedColNames="f0,f1,f2" -DenableSparse=true -DoutputParaTableName=kv_standard_model -DkvIndices=1,2,8,6 -DitemDelimiter=",";
パラメーター | 必須 / 任意 | デフォルト値 | 説明 |
inputTableName | 対象 | なし | 入力テーブルの名前。 |
selectedColNames | 非対象 | すべての列 | トレーニング用に入力テーブルから選択された列。 列名はコンマ (,) で区切る必要があります。 INT型とDOUBLE型の列がサポートされています。 入力データがスパース形式の場合、STRING型の列がサポートされます。 |
inputTablePartitions | 非対象 | すべてのパーティション | トレーニング用に入力テーブルから選択されたパーティション。 次の形式がサポートされています。
説明 複数のパーティションを指定する場合は、コンマ (,) で区切ります。 |
outputTableName | 対象 | なし | 出力テーブルの名前。 |
outputParaTableName | 対象 | なし | 出力パラメーターテーブルの名前。 |
inputParaTableName | ✕ | なし | 入力パラメーターテーブルの名前。 |
keepOriginal | 非対象 | false | 元の列を予約するかどうかを指定します。 有効な値:
|
ライフサイクルの設定 (Set lifecycle) | ✕ | なし | 出力テーブルのライフサイクル。 |
coreNum | 非対象 | システムによって自動的に割り当てられる | コアの数。 |
memSizePerCore | 非対象 | システムによって自動的に割り当てられる | 各コアのメモリサイズ。 |
enableSparse | 非対象 | false | スパース形式の入力データをサポートするかどうかを指定します。 有効な値:
|
itemDelimiter | 非対象 | "," | キーと値のペア間で使用される区切り文字。 |
kvDelimiter | 非対象 | ":" | キーと値の間に使用される区切り文字。 |
kvIndices | ✕ | なし | key-value形式のデータを含むテーブルで標準化が必要な機能インデックス。 |
例
入力データの生成
drop table if exists standardize_test_input; create table standardize_test_input( col_string string, col_bigint bigint, col_double double, col_boolean boolean, col_datetime datetime); insert overwrite table standardize_test_input select * from ( select '01' as col_string, 10 as col_bigint, 10.1 as col_double, True as col_boolean, cast('2016-07-01 10:00:00' as datetime) as col_datetime union all select cast(null as string) as col_string, 11 as col_bigint, 10.2 as col_double, False as col_boolean, cast('2016-07-02 10:00:00' as datetime) as col_datetime union all select '02' as col_string, cast(null as bigint) as col_bigint, 10.3 as col_double, True as col_boolean, cast('2016-07-03 10:00:00' as datetime) as col_datetime union all select '03' as col_string, 12 as col_bigint, cast(null as double) as col_double, False as col_boolean, cast('2016-07-04 10:00:00' as datetime) as col_datetime union all select '04' as col_string, 13 as col_bigint, 10.4 as col_double, cast(null as boolean) as col_boolean, cast('2016-07-05 10:00:00' as datetime) as col_datetime union all select '05' as col_string, 14 as col_bigint, 10.5 as col_double, True as col_boolean, cast(null as datetime) as col_datetime ) tmp;
PAIコマンドの実行
drop table if exists standardize_test_input_output; drop table if exists standardize_test_input_model_output; PAI -name Standardize -project algo_public -DoutputParaTableName="standardize_test_input_model_output" -Dlifecycle="28" -DoutputTableName="standardize_test_input_output" -DinputTableName="standardize_test_input" -DselectedColNames="col_double,col_bigint" -DkeepOriginal="true"; drop table if exists standardize_test_input_output_using_model; drop table if exists standardize_test_input_output_using_model_model_output; PAI -name Standardize -project algo_public -DoutputParaTableName="standardize_test_input_output_using_model_model_output" -DinputParaTableName="standardize_test_input_model_output" -Dlifecycle="28" -DoutputTableName="standardize_test_input_output_using_model" -DinputTableName="standardize_test_input";入力
standardize_test_input
col_文字列
col_bigint
col_double
col_boolean
col_datetime
01
10
10.1
true
2016-07-01 10:00:00
NULL
11
10.2
false
2016-07-02 10:00:00
02
NULL
10.3
true
2016-07-03 10:00:00
03
12
NULL
false
2016-07-04 10:00:00
04
13
10.4
NULL
2016-07-05 10:00:00
05
14
10.5
true
NULL
Output
standardize_test_input_output
col_文字列
col_bigint
col_double
col_boolean
col_datetime
stdized_col_bigint
stdized_col_double
01
10
10.1
true
2016-07-01 10:00:00
-1.2649110640673518
-1.2649110640683832
NULL
11
10.2
false
2016-07-02 10:00:00
-0.6324555320336759
-0.6324555320341972
02
NULL
10.3
true
2016-07-03 10:00:00
NULL
0.0
03
12
NULL
false
2016-07-04 10:00:00
0.0
NULL
04
13
10.4
NULL
2016-07-05 10:00:00
0.6324555320336759
0.6324555320341859
05
14
10.5
true
NULL
1.2649110640673518
1.2649110640683718
standardize_test_input_model_output
特徴
json
col_bigint
{“name”: “standize”, “type”: “bigint”, “paras”:{“mean”:12, “std”: 1.58113883008419}}
col_double
{“name”: “standize”, “type”: “double”, “paras”:{“mean”:10.3, “std”: 0.1581138830082909}}
standardize_test_input_output_using_model
col_文字列
col_bigint
col_double
col_boolean
col_datetime
01
-1.2649110640673515
-1.264911064068383
true
2016-07-01 10:00:00
NULL
-0.6324555320336758
-0.6324555320341971
false
2016-07-02 10:00:00
02
NULL
0.0
true
2016-07-03 10:00:00
03
0.0
NULL
false
2016-07-04 10:00:00
04
0.6324555320336758
0.6324555320341858
NULL
2016-07-05 10:00:00
05
1.2649110640673515
1.2649110640683716
true
NULL
standardize_test_input_output_using_model_model_output
特徴
json
col_bigint
{“name”: “standize”, “type”: “bigint”, “paras”:{“mean”:12, “std”: 1.58113883008419}}
col_double
{“name”: “standize”, “type”: “double”, “paras”:{“mean”:10.3, “std”: 0.1581138830082909}}