ビジネスに人体検出が含まれる場合は、ポーズ検出コンポーネントを使用して、推論用のポーズモデルを構築できます。 このトピックでは、ポーズ検出コンポーネントを設定する方法と、コンポーネントの使用方法について説明します。
前提条件
OSSが有効化され、Machine Learning StudioはOSSへのアクセスが許可されています。 詳細については、「OSSの有効化」および「Machine Learning Designerの使用に必要な権限の付与」をご参照ください。
制限事項
ポーズ検出コンポーネントは、Machine Learning Platform for AI (PAI) のMachine Learning Designerでのみ使用できます。
ポーズ検出コンポーネントは、PAIのディープラーニングコンテナ (DLC) のコンピューティングリソースでのみ使用できます。
概要
ポーズ検出は、主流のトップダウンアルゴリズムを提供します。 アルゴリズムは、以下のカテゴリ、すなわち、物体検出および単一姿勢検出に分類することができる。 単一ポーズ検出は、検出アルゴリズムの提案に依存し、HRNetおよびLite-HRNetモデルをサポートする。
ポーズ検出コンポーネントは、コンポーネントライブラリの [オフライントレーニング] サブフォルダーの [ビデオアルゴリズム] フォルダーにあります。
PAIコンソールでのコンポーネント設定
入力ポート
入力ポート (左から右)
データ型
推奨上流コンポーネント
必須
トレーニングのデータ
OSS
不可
トレーニングのデータ注釈パス
OSS
不可
評価のためのデータ
OSS
不可
評価のためのデータ注釈パス
OSS
不可
データキーポイント情報パス
OSS
不可
コンポーネントパラメータ
タブ
パラメーター
必須
説明
デフォルト値
フィールド設定
モデルタイプ
可
モデルトレーニングに使用されるアルゴリズムの種類。 TopDownのみがサポートされています。
TopDown
oss dir to save model
不可
トレーニングモデルが保存されているObject Storage Service (OSS) ディレクトリ。 例: oss:// examplebucket/output_dir/ckpt /
なし
ossデータパスからトレーニング
不可
トレーニング入力ポートのデータを使用してこのコンポーネントのトレーニングデータを指定しなかった場合、このパラメーターを設定する必要があります。
トレーニングデータが保存されているOSSディレクトリ。 例: oss:// examplebucket/data/train_images /
説明入力ポートとこのパラメーターの両方を使用してトレーニングデータを指定する場合、入力ポートを使用して指定された値が優先されます。
なし
oss注釈パスのトレーニングデータ
不可
トレーニング入力ポートのデータ注釈パスを使用してラベル付きトレーニングデータを指定しなかった場合、このパラメーターを設定する必要があります。
ラベル付きトレーニングデータが保存されているOSSディレクトリ。 例: oss:// examplebucket/data/annotations/train.json
説明入力ポートとこのパラメーターの両方を使用してラベル付きトレーニングデータを指定する場合、入力ポートを使用して指定された値が優先されます。
なし
ossデータパスから評価
不可
評価用データ入力ポートで評価データを指定しなかった場合は, このパラメーターを設定する必要があります。
評価データが保存されるOSSディレクトリ。 例: oss:// examplebucket/data/val_images /
説明入力ポートとこのパラメーターの両方で評価データを指定する場合は, 入力ポートで指定した値が優先されます。
なし
oss注釈パス評価データ
不可
評価入力ポートのデータ注釈パスを使用してラベル付き評価データを指定しなかった場合、このパラメーターを設定する必要があります。
ラベル付き評価データが保存されているOSSディレクトリ。 例: oss:// examplebucket/data/annotations/val.json
説明入力ポートとこのパラメーターの両方でラベル付き評価データを指定する場合は、入力ポートで指定した値が優先されます。
なし
データセット情報ファイルへのossパス
不可
データキーポイント情報パス入力ポートを使用してデータセット情報ファイルを指定しなかった場合、このパラメーターを設定する必要があります。
データセット情報ファイルが保存されているOSSディレクトリ。 例: oss:// examplebucke/data/annotations/dataset_info.py
説明入力ポートとこのパラメーターの両方を使用してデータセット情報ファイルを指定する場合、入力ポートを使用して指定された値が優先されます。
なし
データソースタイプ
可
入力データの形式。 DetSourceCOCOのみがサポートされています。
DetSourceCOCO
事前トレーニング済みモデルへのoss path to pretrained model
不可
事前トレーニング済みモデルが保存されているOSSディレクトリ。 事前トレーニング済みモデルがある場合は、このパラメーターを事前トレーニング済みモデルのOSSディレクトリに設定します。 このパラメーターを設定しない場合、PAIが提供する対応するデフォルトの事前トレーニング済みモデルが使用されます。
なし
パラメーター設定
バックボーン
可
使用するバックボーンモデル。 次の主流モデルは支えられます:
hrnet
lite_hrnet
hrnet
numキーポイント
可
データ内のカテゴリの数。
なし
サイズ変更後の画像サイズ
可
サイズ変更後の画像の固定サイズ。 幅と高さをコンマ (,) で区切ります。
192,256
初期学習率
可
初期学習率。
0.01
learning rateポリシー
可
学習率を調整するために使用されるポリシー。 ステップのみサポートされます。 stepの値は、学習レートが指定されたエポックで手動で調整されることを示します。
step
Irステップ
可
学習レートが調整されるエポック。 複数入力する場合は、カンマ (,) で区切ります。 エポックの数がこのパラメーターで指定された値に達すると、学習率は90% 減衰します。
例えば、初期学習率が0.1に設定され、エポックの総数が20に設定され、lrステップパラメータが5,10に設定されたと仮定する。 この場合、トレーニングがエポック1〜5であるとき、学習率は0.1である。 トレーニングがエポック6に入ると、学習率は0.01に減衰し、エポック10が終了するまで継続する。 トレーニングがエポック11に入ると、学習率は0.001に減衰し、すべてのエポックの終わりまで続きます。
170,200
列車のバッチサイズ
可
トレーニングバッチのサイズ。1回の反復でモデルトレーニングに使用されるデータサンプルの数を示します。
32
evalバッチサイズ
可
評価バッチのサイズ。1回の反復でモデル評価に使用されるデータサンプルの数を示します。
32
総列車エポック
可
エポックの総数。 トレーニングのラウンドがすべてのデータサンプルで完了すると、エポックは終了します。 エポックの総数は、データサンプルに対して実施されたトレーニングラウンドの総数を示す。
200
チェックポイントエポックを保存
不可
チェックポイントが保存される頻度。 値1は、エポックが終了するたびにチェックポイントが保存されることを示します。
1
チューニング
オプティマイザ
可
モデルトレーニングの最適化方法。 有効な値:
SGD
アダム
SGD
数プロセスの読み取りデータあたりgpu
不可
各GPUのトレーニングデータの読み取りに使用されるスレッドの数。
2
evtorchモデルfp16
不可
モデルトレーニング中のメモリ使用量を減らすためにFP16を有効にするかどうかを指定します。
なし
シングルワーカーまたは分散DLC
可
コンポーネントの実行に使用される計算エンジン。 ビジネス要件に基づいてコンピューティングエンジンを選択できます。 有効な値:
single_on_dlc
distribute_on_dlc
single_on_dlc
数のワーカー
不可
単一のワーカーまたはDLCで配布パラメーターにdistribute_on_dlcを選択した場合、このパラメーターを設定する必要があります。
計算に使用される同時作業ノードの数。
1
cpuマシンタイプ
不可
単一のワーカーまたはDLCで配布パラメーターにdistribute_on_dlcを選択した場合、このパラメーターを設定する必要があります。
使用するCPU仕様。
16vCPU + 64GB Mem-ecs.g6.4xlarge
gpuマシンタイプ
可
使用するGPU仕様。
8vCPU + 60GB Mem + 1xp100-ecs.gn5-c8g1.2xlarge
出力ポート
出力ポート
データ型
下流コンポーネント
出力モデル
出力モデルが保存されているOSSディレクトリ。 この値は、[フィールド設定] タブで [oss dir to save model] パラメーターに指定した値と同じです。
例
次の図は、ポーズ検出コンポーネントが使用されるサンプルパイプラインを示しています。 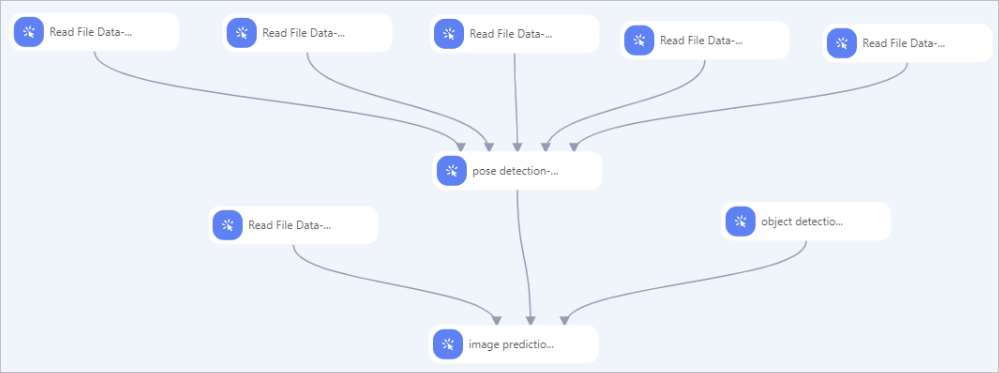 この例では、次の手順を実行して、前の図のようにコンポーネントを構成します。
この例では、次の手順を実行して、前の図のようにコンポーネントを構成します。
データを準備します。 PAIが提供するiTAGを使用して画像にラベルを付ける。 詳細については、次をご参照ください: iTAGを使用します。
Read File Data-1、Read File Data-2、Read File Data-3、Read File Data-4、およびRead File Data-5コンポーネントを使用して、トレーニングデータ、ラベル付きトレーニングデータ、評価データ、ラベル付き評価データ、およびデータセット情報ファイルを読み取ります。 これを行うには、各コンポーネントのOSSデータパスパラメーターを、取得するデータが保存されているOSSディレクトリに設定します。
前の5つのコンポーネントからポーズ検出コンポーネントに線を引き、ポーズ検出コンポーネントのパラメーターを設定します。 詳細については、このトピックの「PAIコンソールでのコンポーネント設定」セクションを参照してください。
画像予測コンポーネントを使用して、オフライン推論を実行します。 これを行うには、画像予測コンポーネントに次のパラメータを設定します。 詳細については、「コンポーネント参照: すべてのコンポーネントの概要」をご参照ください。
model type: pose_predictorを選択します。
oss path for model: pose detectionコンポーネントのモデルパラメータを保存するために、oss dirに設定された値を選択します。
ポーズの検出モデルのパス: ポーズ検出モデルが保存されているossディレクトリを選択します。
説明ポーズが検出される前に、人体が検出されなければならない。 これは、TopDownアルゴリズムタイプのみがサポートされているためです。 オブジェクト検出コンポーネントを使用してpose detectionコンポーネントに接続する場合、オブジェクト検出コンポーネントによってエクスポートされた検出モデルはpose detectionコンポーネントによって使用され、このパラメーターは無視できます。 それ以外の場合は、このパラメーターを設定する必要があります。
ポーズ検出モデルタイプ: 使用されるポーズ検出モデルのタイプ。 This parameter is required. yolox_predictorのみがサポートされています。