PageRankアルゴリズムは、webページの重要性を測定するために使用されます。 PageRankアルゴリズムは、ハイパーリンクを分析して、ウェブページへのリンクの数および品質に基づいてウェブページの重要性を判定する。 ウェブページへのリンクの数が多いほど、ウェブページのランキングが高いことを示す。 リンクソースの重みは、webページの最終的なPageRankスコアにも影響します。 ページランクコンポーネントは、各ノードの重みを計算するために使用されます。
説明
PageRankアルゴリズムは、ウェブページへのリンクを分析して、ウェブページの相対的な重要性を評価する。 PageRankアルゴリズムは、次の基本原則に基づいて機能します。
他のウェブページからウェブページへのリンクの数が多いほど、ウェブページの重要性または品質が高いことを示します。
PageRankアルゴリズムは、他のウェブページからウェブページへのリンクの数を収集し、他のウェブページの重みを考慮に入れる。 ウェブページの重みは、ウェブページのPageRankスコアと、ウェブページから他のウェブページへのリンクの数とに基づいて計算されます。
PageRankアルゴリズムは、ソーシャルネットワークにも適用できます。 ソーシャルネットワークでは、ユーザーの影響は、その個人的な属性とその社会的なつながりの質によって決まります。 たとえば、Sina Weiboユーザーがフォロワーに与える影響は、フォロワーとの関係の近さによって影響を受けます。 ほとんどの場合、Sina Weiboユーザーは家族、クラスメート、同僚に影響を与える可能性が高くなります。 ソーシャルネットワークでは、エッジ重みは、ユーザ間の関係の近さを反映し、関係強度インデックスであると考えられます。
リンク重み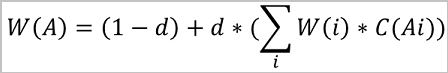 を含むPageRank式
を含むPageRank式
W(i): ノードiの重み。
C(Ai): リンク重み。
d: ダンピング係数。
W(A): 各ユーザの影響指数とアルゴリズム反復後のノード重みが安定します。
コンポーネントの設定
方法1: パイプラインページでコンポーネントを設定する
Platform for AI (PAI) コンソールのMachine Learning Designerのパイプラインページで、ページランクコンポーネントのパラメーターを設定します。 下表に、各パラメーターを説明します。
タブ | パラメーター | 説明 |
フィールド設定 | ソース頂点列 | エッジテーブルの開始頂点列。 |
ターゲット頂点列 | エッジテーブルの末尾の頂点列。 | |
エッジ重量コラム | エッジテーブルのエッジ重み列。 | |
パラメーター設定 | 最大イテレーション | アルゴリズムが自動的に収束するまでの反復回数。 デフォルト値:30。 |
ダンピング係数 | ユーザーがブラウジングを続ける確率。 | |
チューニング | 労働者 | 並列ジョブ実行のノード数。 並列性とフレームワーク通信コストの程度は、このパラメータの値とともに増加します。 |
Workerあたりのメモリサイズ (MB) | ジョブで使用できるメモリの最大サイズ。 単位:MB。 デフォルト値: 4096 使用されているメモリのサイズがこのパラメーターの値を超えると、 |
方法2: PAIコマンドを使用する
PAIコマンドを使用して、ページランクコンポーネントのパラメーターを設定します。 SQLスクリプトコンポーネントを使用してPAIコマンドを呼び出すことができます。 詳細については、「シナリオ4: SQLスクリプトコンポーネント内でPAIコマンドを実行する」をご参照ください。
PAI -name PageRankWithWeight
-project algo_public
-DinputEdgeTableName=PageRankWithWeight_func_test_edge
-DfromVertexCol=flow_out_id
-DtoVertexCol=flow_in_id
-DoutputTableName=PageRankWithWeight_func_test_result
-DhasEdgeWeight=true
-DedgeWeightCol=weight
-DmaxIter 100;パラメーター | 必須 / 任意 | デフォルト値 | 説明 |
inputEdgeTableName | 可 | デフォルト値なし | 入力エッジテーブルの名前。 |
inputEdgeTablePartitions | 不可 | フルテーブル | 入力エッジテーブルのパーティション。 |
fromVertexCol | 可 | デフォルト値なし | 入力エッジテーブルの開始頂点列。 |
toVertexCol | 可 | デフォルト値なし | 入力エッジテーブルの末尾の頂点列。 |
outputTableName | 可 | デフォルト値なし | 出力テーブルの名前。 |
outputTablePartitions | 不可 | デフォルト値なし | 出力テーブルのパーティション。 |
ライフサイクルの設定 (Set lifecycle) | 不可 | デフォルト値なし | 出力テーブルのライフサイクル。 |
workerNum | 不可 | デフォルト値なし | 並列ジョブ実行のノード数。 並列性とフレームワーク通信コストの程度は、このパラメータの値とともに増加します。 |
workerMem | 不可 | 4096 | ジョブで使用できるメモリの最大サイズ。 単位:MB。 デフォルト値: 4096 使用されているメモリのサイズがこのパラメーターの値を超えると、 |
splitSize | 不可 | 64 | データ分割サイズ。 単位:MB。 |
hasEdgeWeight | 不可 | false | 入力エッジテーブルのエッジに重みがあるかどうかを指定します。 |
edgeWeightCol | 不可 | デフォルト値なし | 入力エッジテーブルのエッジ重み列。 |
maxIter | 不可 | 30 | 反復の最大数。 |
例:
SQLスクリプトコンポーネントをノードとしてキャンバスに追加します。 [スクリプトモードの使用] および [テーブル作成文を追加するかどうか] の選択を解除します。 次のSQL文を実行してトレーニングデータを生成します。
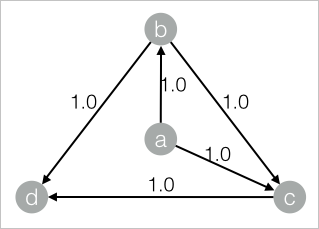
drop table if exists PageRankWithWeight_func_test_edge; create table PageRankWithWeight_func_test_edge as select * from ( select 'a' as flow_out_id,'b' as flow_in_id,1.0 as weight union all select 'a' as flow_out_id,'c' as flow_in_id,1.0 as weight union all select 'b' as flow_out_id,'c' as flow_in_id,1.0 as weight union all select 'b' as flow_out_id,'d' as flow_in_id,1.0 as weight union all select 'c' as flow_out_id,'d' as flow_in_id,1.0 as weight )tmp;データ構造
SQLスクリプトコンポーネントをノードとしてキャンバスに追加します。 [スクリプトモードの使用] および [テーブル作成文を追加するかどうか] の選択を解除します。 ステップ1と2でノードを接続します。
drop table if exists ${o1}; PAI -name PageRankWithWeight -project algo_public -DinputEdgeTableName=PageRankWithWeight_func_test_edge -DfromVertexCol=flow_out_id -DtoVertexCol=flow_in_id -DoutputTableName=${o1} -DhasEdgeWeight=true -DedgeWeightCol=weight -DmaxIter 100; をクリックしてパイプラインを実行します。
をクリックしてパイプラインを実行します。実行が終了したら、手順2でコンポーネントを右クリックし、[データの表示]> [SQLスクリプトの出力] を選択してトレーニング結果を表示します。
| node | weight | | ---- | ---------- | | a | 0.12841452 | | b | 0.18299069 | | c | 0.26076174 | | d | 0.42783305 |