DeepSeek-R1 671B などの超大規模 MoE モデルは、個々のデバイスの容量を超えています。これに対処するため、Elastic Algorithm Service(EAS)は複数マシン分散推論ソリューションを導入しました。これにより、単一のサービスインスタンスを複数のマシンに分散させ、超大規模モデルの効率的なデプロイと運用を促進できます。このトピックでは、複数マシン分散推論を構成する方法について説明します。
使用上の注意
EAS または ModelGallery によって公式に提供されている SGLang および vLLM イメージの一部は、分散推論をネイティブにサポートしています。カスタムイメージを使用して分散推論をデプロイする場合は、分散推論フレームワークのネットワーク仕様と分散処理の基本パラダイムに従う必要があります。詳細については、「仕組み」をご参照ください。
仕組み
以下の内容は、分散推論の基本的な概念と原則を紹介します。
インスタンスユニット
標準の EAS 推論サービスと比較して、分散推論サービスではインスタンスユニット (以下、ユニットと呼びます) という概念が導入されています。 ユニット内では、インスタンスは TP/PP などのパターンを使用して高性能なネットワーク通信で連携し、リクエスト処理を完了します。 ユニット内のインスタンスはステートフルですが、異なるユニット間は完全に対称かつステートレスです。
インスタンス番号
ユニット内の各インスタンスには、環境変数によってインスタンス番号が割り当てられます(ユニット内の各インスタンスの環境変数と説明については、「付録」をご参照ください)。異なるインスタンスには異なる番号が順番に割り当てられ、異なるインスタンスによる異なるタスクの実行を制御します。
トラフィック処理
デフォルトでは、ユニット全体はインスタンス 0(RANK_ID が 0)のみを介してトラフィックを受信します。システムのサービス検出メカニズムは、ユーザートラフィックを異なるユニットのインスタンス 0 に割り当て、ユニット内で分散方式で処理します。異なるユニットは、干渉することなく、ユーザートラフィックを独立して処理します。
ローリングアップデート
ローリングアップデート中は、ユニットは全体として再構築され、新しいユニット内のすべてのインスタンスが並行して作成されます。新しいユニット内のすべてのインスタンスの準備が整うと、トラフィックは最初に削除されるユニットから転送され、次にそのユニット内のすべてのインスタンスが削除されます。
ライフサイクル
ユニットの再構築
ユニットが完全に再構築されると、古いユニット内のすべてのインスタンスは並行して削除され、新しいユニット内のすべてのインスタンスは並行して作成されます。インスタンス番号に基づいて特別な処理は行われません。
インスタンスの再構築
デフォルトでは、ユニット内の各インスタンスのライフサイクルはインスタンス 0 のライフサイクルと一致します。インスタンス 0 が再構築されると、ユニット内の他のすべてのインスタンスの再構築がトリガーされます。0 以外のインスタンスが再構築されても、ユニット内の他のインスタンスは影響を受けません。
分散フォールトトレランス
インスタンス例外処理メカニズム
分散サービスのインスタンスで例外が検出されると、システムはユニット内のすべてのインスタンスの再起動を自動的にトリガーします。
機能:単一障害点によって引き起こされるクラスタ状態の不整合を効果的に解決し、すべてのインスタンスの実行時環境が完全にリセットされるようにします。
連携リカバリメカニズム
インスタンスが再起動した後、システムはユニット内のすべてのインスタンスが整合性のある準備完了状態になるまで待機し(同期バリアを介して実装)、すべてのインスタンスが準備完了になった後にのみビジネスプロセスを開始します。
機能:
インスタンスの状態の不整合による NCCL 通信ネットワーク中のグループ化例外を防ぎます。
分散推論タスクに参加するすべてのノードの厳密な起動同期を保証します。
分散フォールトトレランス機能はデフォルトで無効になっています。有効にする必要がある場合は、次の例に示すように unit.guard を構成できます。
{
"unit": {
"size": 2,
"guard": true
}
}複数マシン分散推論の構成
EAS カスタムデプロイメント
PAI コンソールにログインします。ページ上部でリージョンを選択します。次に、目的のワークスペースを選択し、[Elastic Algorithm Service (EAS) に入る]をクリックします。
サービスのデプロイ:[推論サービス] タブで、[サービスのデプロイ] をクリックします。[カスタムモデルデプロイメント] セクションで、[カスタムデプロイメント] をクリックします。
サービスの更新: [推論サービス] タブで、サービスリストから操作対象のサービスを探し、[操作] 列の [更新] をクリックします。
以下の主要パラメータを構成します。その他のパラメータについては、「コンソールでのカスタムデプロイメントのパラメータ」をご参照ください。
[環境情報] セクションで、イメージとコマンドを構成します。
[イメージ構成]:[Alibaba Cloud イメージ] を選択し、vllm:0.7.1 または sglang:0.4.1 を選択します。
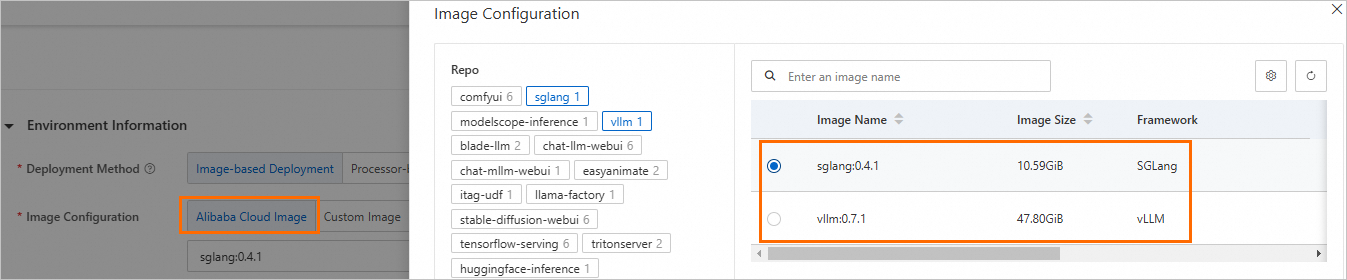
[コマンド]:イメージを選択すると、システムによってコマンドが自動的に設定されます。変更は必要ありません。
[リソース情報] セクションで、[分散推論] オプションをオンにし、以下の主要パラメータを構成します。
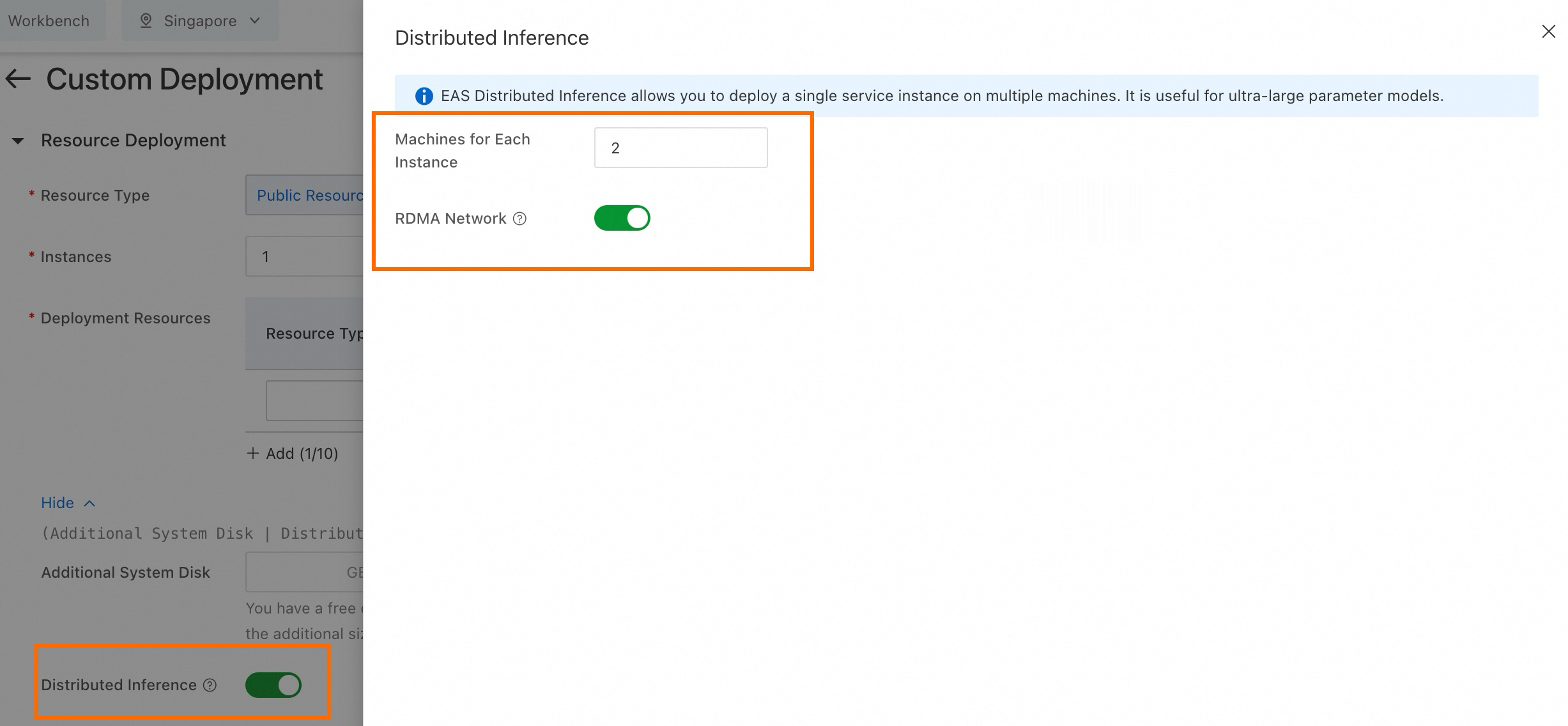
パラメータ
説明
[インスタンスごとのマシン数]
単一モデル推論インスタンスのマシン数。最小値は 2 です。
[RDMA ネットワーク]
マシン間の効率的なネットワーク接続を確保するために RDMA ネットワークを有効にします。
説明現在、凌雲リソースを使用してデプロイされたサービスのみが RDMA ネットワークを使用できます。
[デプロイ] または [更新] をクリックします。
Model Gallery でのワンクリックデプロイ
分散推論は、デプロイ方法が SGLang 高速デプロイメント または vLLM 高速デプロイメント の場合にのみサポートされます。
パラメーター量の多いモデルの場合、モデルギャラリーでワンクリックでモデルサービスをデプロイする際に、分散デプロイメントメソッドとして[SGLang 高速化デプロイメント]または[vLLM 高速化デプロイメント]を選択すると、EAS によって自動的に[分散推論]が有効になります。[設定の変更]をクリックして、単一インスタンスで使用されるマシンの数を調整できます。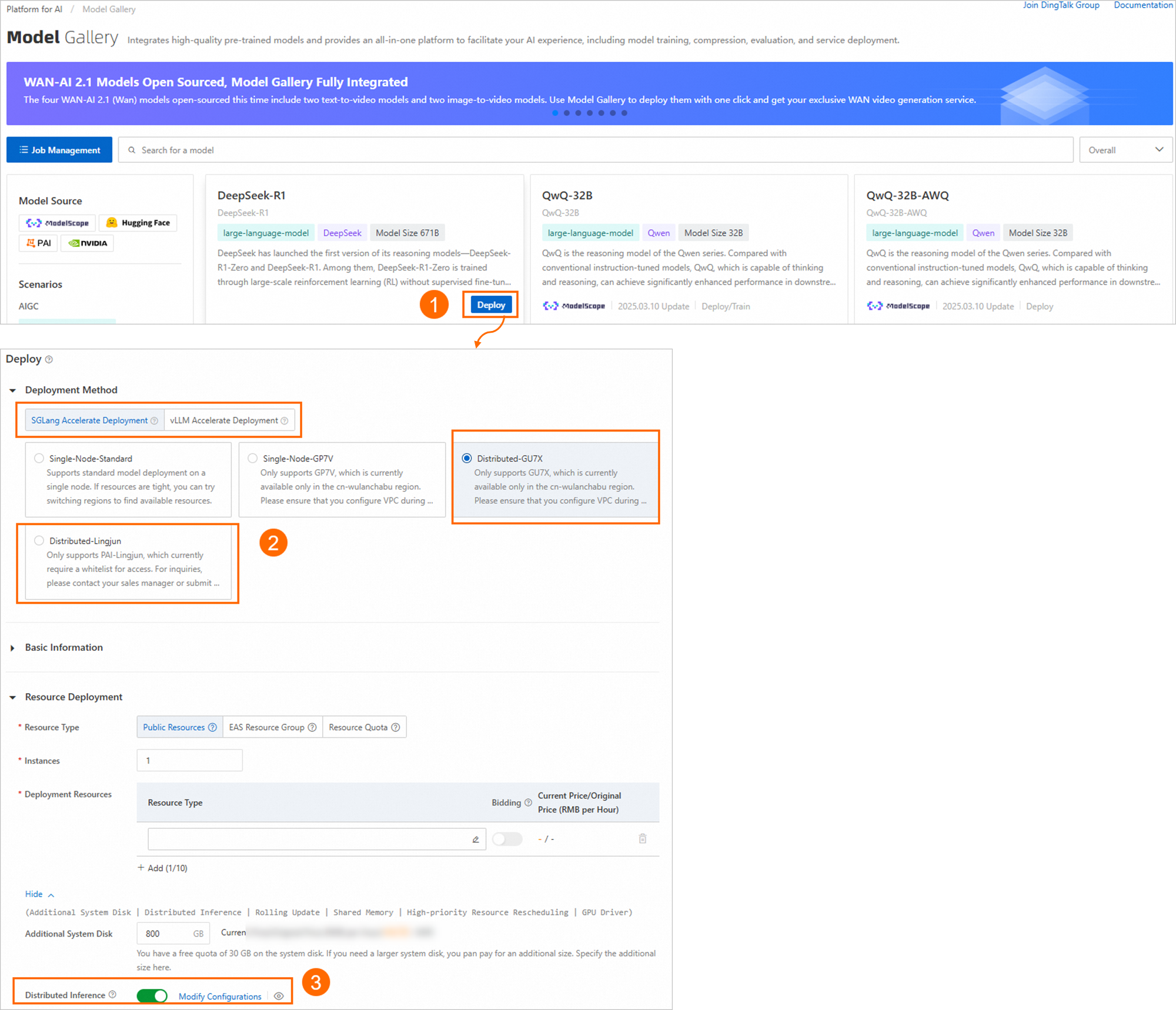
付録
分散推論サービスをデプロイする場合は、通常、ネットワーク操作が必要です(Torch 分散フレームワークまたは Ray フレームワークの使用など)。VPC または RDMA が構成されている場合、各インスタンスには複数のネットワークカードがあるため、ネットワーク通信に使用するネットワークカードを指定する必要があります。
RDMA が構成されている場合、デフォルトで RDMA ネットワークカード(net0)が使用されます。
RDMA が構成されていない場合、ユーザーが構成した VPC(eth1)に対応するネットワークカードが使用されます。
関連する構成は、起動コマンドで使用できる環境変数を介して渡されます。次に例を示します。
環境変数 | 説明 | 値の例 |
RANK_ID | インスタンス番号。0 から始まり、増加します。 | 0 |
COMM_IFNAME | ネットワークに使用するデフォルトのネットワークカード。
| net0 |
RANK_IP | ネットワークに使用する IP アドレス。COMM_IFNAME ネットワークカードの IP アドレスです。 | 11.*.*.* |
MASTER_ADDRESS | RANK_ID が 0 のインスタンスの IP アドレス。インスタンス 0 の COMM_IFNAME ネットワークカードの IP アドレスです。 | 11.*.*.* |