モジュール性は、ネットワークのコミュニティへの分割の強さを測定するメトリックです。 このメトリックは、コミュニティ間のリンクと比較したコミュニティ内のリンクの密度を定量化します。 0.3より大きいモジュール値は、ネットワークが強いコミュニティ構造を有することを示す。 Machine Learning Designerは、グラフのModularity値を計算できるModularityコンポーネントを提供します。
コンポーネントの設定
方法1: Platform for AI (PAI) コンソールの使用
PAIコンソールでコンポーネントを構成するには、PAIコンソールにログインし、[Visualized Modeling (Designer)] ページに移動してパイプラインを開きます。 パイプラインページで、Modularityコンポーネントをキャンバスにドラッグし、右側のペインでパラメーターを設定します。 下表に、各パラメーターを説明します。
カテゴリ | パラメーター | 説明 |
フィールド設定 | ソース頂点列 | エッジリストの開始頂点を含む列。 |
初期頂点ラベル列 | エッジリストの開始頂点が属するグループ。 | |
ターゲット頂点列 | エッジリストの終了頂点を含む列。 | |
ターゲット頂点ラベル列 | エッジリストの終了頂点が属するグループ。 | |
チューニング | 数の労働者 | 同時に実行されるワーカーの数。 より高い値は、より高い通信オーバーヘッドをもたらす。 |
ワーカーメモリ (MB) | ワーカーが使用できるメモリの最大量。 単位:MB。 デフォルト値: 4096 実際のメモリ使用量がこの値を超えると、 |
方法2: PAIコマンドを使用する
PAIコマンドを使用してModularityコンポーネントを構成するには、SQLスクリプトコンポーネントでコマンドを実行します。 詳細については、「シナリオ4: SQLスクリプトコンポーネント内でPAIコマンドを実行する」をご参照ください。
PAI -name Modularity
-project algo_public
-DinputEdgeTableName=Modularity_func_test_edge
-DfromVertexCol=flow_out_id
-DfromGroupCol=group_out_id
-DtoVertexCol=flow_in_id
-DtoGroupCol=group_in_id
-DoutputTableName=Modularity_func_test_result;パラメーター | 必須 | デフォルト値 | 説明 |
inputEdgeTableName | 可 | N/A | 入力エッジリストの名前。 |
inputEdgeTablePartitions | 不可 | Full list | 入力エッジリストのパーティション。The partition in the input edge list. |
fromVertexCol | 可 | N/A | エッジリストの開始頂点を含む列。 |
fromGroupCol | 可 | N/A | エッジリストの開始頂点が属するグループ。 |
toVertexCol | 可 | N/A | エッジリストの終了頂点を含む列。 |
toGroupCol | 可 | N/A | エッジリストの終了頂点が属するグループ。 |
outputTableName | 可 | N/A | 出力テーブルの名前。 |
outputTablePartitions | 不可 | N/A | 出力テーブルのパーティション。 |
ライフサイクルの設定 (Set lifecycle) | 不可 | N/A | 出力テーブルのライフサイクル。 |
workerNum | ✕ | None | 同時に実行されるワーカーの数。 より高い値は、より高い通信オーバーヘッドをもたらす。 |
workerMem | 不可 | 4096 | ワーカーが使用できるメモリの最大量。 単位:MB。 デフォルト値: 4096 実際のメモリ使用量がこの値を超えると、 |
splitSize | 不可 | 64 | 分割された入力データのサイズ。 単位:MB。 |
例:
次の手順を実行すると、右側のウィンドウの [スクリプトモードを使用] および [テーブルの作成文を追加するかどうか] チェックボックスをオフにします。
SQLスクリプトコンポーネントを追加し、次のSQL文を右側のウィンドウのエディターに貼り付けて、トレーニングデータを生成します。
drop table if exists Modularity_func_test_edge; create table Modularity_func_test_edge as select * from ( select '1' as flow_out_id,'3' as group_out_id,'2' as flow_in_id,'3' as group_in_id union all select '1' as flow_out_id,'3' as group_out_id,'3' as flow_in_id,'3' as group_in_id union all select '1' as flow_out_id,'3' as group_out_id,'4' as flow_in_id,'3' as group_in_id union all select '2' as flow_out_id,'3' as group_out_id,'3' as flow_in_id,'3' as group_in_id union all select '2' as flow_out_id,'3' as group_out_id,'4' as flow_in_id,'3' as group_in_id union all select '3' as flow_out_id,'3' as group_out_id,'4' as flow_in_id,'3' as group_in_id union all select '4' as flow_out_id,'3' as group_out_id,'6' as flow_in_id,'7' as group_in_id union all select '5' as flow_out_id,'7' as group_out_id,'6' as flow_in_id,'7' as group_in_id union all select '5' as flow_out_id,'7' as group_out_id,'7' as flow_in_id,'7' as group_in_id union all select '5' as flow_out_id,'7' as group_out_id,'8' as flow_in_id,'7' as group_in_id union all select '6' as flow_out_id,'7' as group_out_id,'7' as flow_in_id,'7' as group_in_id union all select '6' as flow_out_id,'7' as group_out_id,'8' as flow_in_id,'7' as group_in_id union all select '7' as flow_out_id,'7' as group_out_id,'8' as flow_in_id,'7' as group_in_id )tmp ;対応するグラフデータ構造:
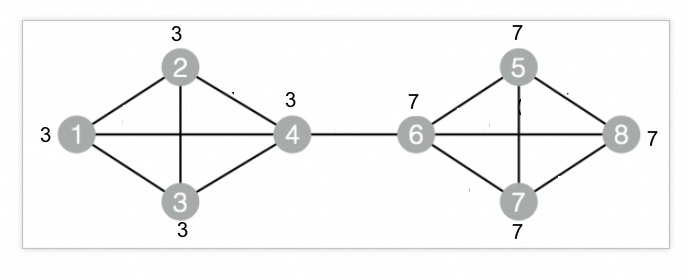
別のSQLスクリプトコンポーネントを追加し、次のコマンドを右側のウィンドウのエディターに貼り付けてトレーニングを開始します。 次に、追加した2つのコンポーネントを接続します。
drop table if exists ${o1}; PAI -name Modularity -project algo_public -DinputEdgeTableName=Modularity_func_test_edge -DfromVertexCol=flow_out_id -DfromGroupCol=group_out_id -DtoVertexCol=flow_in_id -DtoGroupCol=group_in_id -DoutputTableName=${o1};パイプラインを実行します。 パイプラインの実行が完了したら、前の手順で追加したSQLスクリプトコンポーネントを右クリックし、ショートカットメニューで [データの表示]> [SQLスクリプトの出力] を選択してトレーニング結果を表示します。
| val | | ------------------- | | 0.42307692766189575 |