因数分解マシン (FM) アルゴリズムは、高次元のスパースデータを処理するのに特に適した一般的な予測モデルである。 FMアルゴリズムは、特徴間の相互作用をモデル化するために潜在ベクトルを導入します。これは、行列因数分解技術の拡張と見なすことができます。 推奨システムや広告クリックスルー率予測などの分野で広く使用されています。
制御ポリシー機能の動作
FMアルゴリズムは、FMトレーニングとFM予測の2つのプロセスを含みます。 これらの2つのプロセスは、それぞれモデル構築および適用フェーズに対応します。
FMトレーニング: このプロセスの中心的な目的は、モデルがターゲット変数を正確に予測できるように、所与のトレーニングデータセットからモデルパラメータを学習することです。 このフェーズでは、アルゴリズムは入力データを分析し、パラメータを最適化してモデルの効率と精度を確保します。
FM予測: このプロセスでは、すでにトレーニングされたモデルを使用して、新しい入力データの予測を行います。 FM予測フェーズの間、モデルパラメータは固定され、モデルがこれらの確立されたパラメータを使用して新しいデータの予測結果を計算し出力することを可能にします。
コンポーネントの構成
方法1: パイプラインページでコンポーネントを設定する
FMトレーニング
パイプラインページで、FM Trainコンポーネントを追加し、次のパラメーターを設定します。
カテゴリ | パラメーター | 説明 | |
フィールドの設定 | フィーチャー列 | 入力テーブルの特性に基づいてフィーチャ列を選択します。 STRING型とDOUBLE型の列がサポートされています。 | |
ラベル列 | 入力テーブルの特性に基づいてラベル列を選択します。 DOUBLEタイプの列のみがサポートされています。 | ||
高度なオプション | このパラメーターはMachine Learning Designerでのみ使用できます。 [詳細オプション] を選択した場合、Flink設定項目が使用可能です。 Flinkの設定方法の詳細については、「Flinkの設定」をご参照ください。 | ||
パラメーター設定 | タスクタイプ | タスクタイプを選択します。 有効な値:
| |
反復回数 | イテレーションの総数を指定します。 デフォルト値は 10 です。 | ||
正則化係数 | コンマ (,) で区切られた3つの浮動小数点数を指定します。 これらの3つの数値は、0次項、1次項、2次項の正則化係数を表している。 | ||
学習率 | 学習率を指定します。 トレーニングが分岐している場合は、このパラメーターを小さい値に設定します。 | ||
パラメータ初期化標準偏差 | パラメーター初期化の標準偏差を指定します。 このパラメーターは、データの正規化に使用されます。 値はDOUBLE型です。 デフォルト値: 0.05 | ||
ディメンション | コンマ (,) で区切られた3つの正の整数を指定します。 これら3つの正の整数は、0次項、1次項、2次項の長さを表す。 | ||
ブロックサイズ | パフォーマンスメトリックの名前を指定します。 | ||
出力テーブルのライフサイクル | このパラメーターはMachine Learning Studioでのみ使用できます。 出力テーブルのライフサイクルを指定します。 | ||
チューニング | 実行モードを選択 | MaxCompute | MaxComputeまたはFlinkコンピューティングリソースを使用します。 ワーカーの数とそのメモリを設定する方法については、「付録: リソース使用量を推定する方法」をご参照ください。 |
Flink | |||
DLC | DLCコンピューティングリソースを使用します。 プロンプトに基づいて仕様を設定します。 | ||
FM予測
パイプラインページで、FM予測コンポーネントを追加し、次のパラメーターを設定します。
カテゴリ | パラメーター | 説明 | |
パラメーター設定 | 予測結果列 | 予測結果列の名前を指定します。 | |
出力詳細列 | 予測詳細列の名前を指定します。 | ||
予約済み列 | 出力テーブルで予約する列を指定します。 | ||
高度な構成 | このパラメーターはMachine Learning Designerでのみ使用できます。 [詳細設定] を選択した場合、各ワーカーが使用するスレッド数とModelSizeのタイプが使用できます。 | ||
チューニング | 実行モードを選択 | MaxCompute | MaxComputeまたはFlinkコンピューティングリソースを使用します。 ワーカーの数とそのメモリを設定する方法については、「付録: リソース使用量を推定する方法」をご参照ください。 |
Flink | |||
DLC | DLCコンピューティングリソースを使用します。 プロンプトに基づいて仕様を設定します。 | ||
方法2: PAIコマンドを使用する
PAIコマンドを使用して、FM TrainおよびFM Predictionコンポーネントのパラメーターを設定します。
FMトレイン
パラメーター | 必須 / 任意 | デフォルト値 | 説明 |
tensorColName | 可 | なし | フィーチャー列の名前。 列のデータはkey-value形式でなければなりません。 複数の名前はコンマ (,) で区切ります。 例: 1:1.0,3:1.0 |
labelColName | 可 | なし | label列の名前。 数値データ型の列のみがサポートされています。 taskパラメーターがbinary_classificationに設定されている場合、labelの値は0または1である必要があります。 |
task | 可 | 回帰 | タスクの ID を設定します。 有効な値: regression and binary_classification。 |
numEpochs | 不可 | 10 | 反復回数。 |
dim | 不可 | 1,1,10 | コンマ (,) で区切られた3つの正の整数。 これら3つの正の整数は、0次項、1次項、2次項の長さを表す。 |
learnRate | 不可 | 0.01 | 学習率。 トレーニングが分岐している場合は、learnRateパラメーターを小さい値に設定します。 |
lambda | 不可 | 0.01,0.01,0.01 | コンマ (,) で区切られた3つの浮動小数点数。 これらの3つの数値は、0次項、1次項、2次項の正則化係数を表している。 |
initStdev | 不可 | 0.05 | パラメータ初期化の標準偏差。 |
FM予測
パラメーター | 必須 / 任意 | デフォルト値 | 説明 |
predResultColName | 不可 | prediction_result | 予測結果列の名前。 |
predScoreColName | 不可 | prediction_score | 予測スコア列の名前。 |
predDetailColName | 不可 | prediction_detail | 予測の詳細列の名前。 |
keepColNames | 不可 | すべての列 | 出力テーブルで予約する列。 |
例:
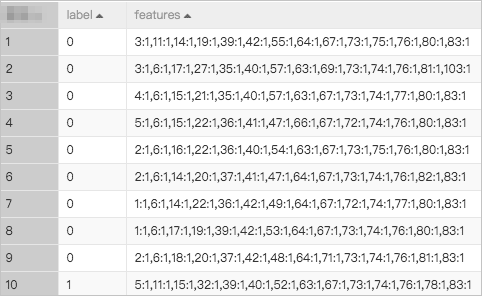
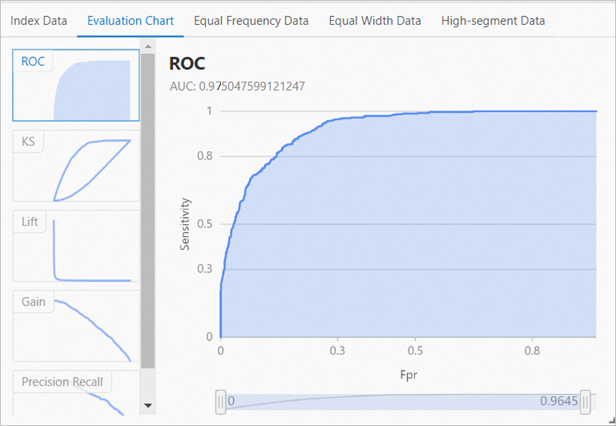
次のデータをFM推奨モデルに基づくAlinkフレームワークテンプレートの入力として使用すると、トレーニング操作によって生成されるモデル曲線下面積 (AUC) は約0.97になります。