エッジクラスタリング係数は、ネットワーク内のエッジがその近傍内の三角形クロージャに参加する程度を測定するために使用されるメトリックです。 これは、エッジによって接続された2つのノードの共通の近傍間で形成される三角形の割合を決定することによって計算される。 この係数は、ネットワーク内のローカルクラスタリングパターンとコミュニティ構造を理解するのに役立ち、ソーシャルネットワーク分析やコミュニティ検出などの分野で広く使用されています。
コンポーネントの設定
方法1: パイプラインページでコンポーネントを設定する
Machine Learning Designerのパイプラインの詳細ページで、エッジクラスタリング係数コンポーネントをパイプラインに追加し、次の表に示すパラメーターを設定します。
タブ | パラメーター | 説明 |
フィールド設定 | Vertexを開始 | エッジテーブルの開始頂点列。 |
エンド頂点 | エッジテーブルの末尾の頂点列。 | |
チューニング | 労働者 | 並列ジョブ実行の頂点の数。 並列性とフレームワーク通信コストの程度は、このパラメータの値とともに増加します。 |
Workerあたりのメモリサイズ (MB) | 1つのジョブで使用できるメモリの最大サイズ。 単位:MB。 デフォルト値: 4096 使用済みメモリのサイズがこのパラメーターの値を超えると、 | |
データ分割サイズ (MB) | データ分割サイズ。 単位:MB。 デフォルト値: 64。 |
方法2: PAIコマンドを使用してコンポーネントを構成する
PAIコマンドを使用してコンポーネントパラメータを設定します。 SQL Scriptコンポーネントを使用してPAIコマンドを呼び出すことができます。 詳細については、「シナリオ4: SQLスクリプトコンポーネント内でPAIコマンドを実行する」をご参照ください。
PAI -name EdgeDensity
-project algo_public
-DinputEdgeTableName=EdgeDensity_func_test_edge
-DfromVertexCol=flow_out_id
-DtoVertexCol=flow_in_id
-DoutputTableName=EdgeDensity_func_test_result;パラメーター | 必須 / 任意 | デフォルト値 | 説明 |
inputEdgeTableName | 対象 | デフォルト値なし | 入力エッジテーブルの名前。 |
inputEdgeTablePartitions | 非対象 | フルテーブル | 入力エッジテーブルのパーティション。 |
fromVertexCol | 対象 | デフォルト値なし | 入力エッジテーブルの開始頂点列。 |
toVertexCol | 対象 | デフォルト値なし | 入力エッジテーブルの末尾の頂点列。 |
outputTableName | 対象 | デフォルト値なし | 出力テーブルの名前。 |
outputTablePartitions | 非対象 | デフォルト値なし | 出力テーブルのパーティション。 |
ライフサイクルの設定 (Set lifecycle) | 非対象 | デフォルト値なし | 出力テーブルのライフサイクル。 |
workerNum | 非対象 | デフォルト値なし | 並列ジョブ実行の頂点の数。 並列性とフレームワーク通信コストの程度は、このパラメータの値とともに増加します。 |
workerMem | 非対象 | 4096 | 1つのジョブで使用できるメモリの最大サイズ。 単位:MB。 デフォルト値: 4096 使用済みメモリのサイズがこのパラメーターの値を超えると、 |
splitSize | 非対象 | 64 | データ分割サイズ。 単位:MB。 |
例:
パイプラインの詳細ページで、SQL Scriptコンポーネントをパイプラインに追加し、そのコンポーネントをクリックします。 [パラメーター設定] タブで、[スクリプトモードの使用] および [テーブル作成ステートメントを追加するかどうか] をオフにし、[SQLスクリプト] エディターに次のSQLステートメントを入力します。
drop table if exists EdgeDensity_func_test_edge; create table EdgeDensity_func_test_edge as select * from ( select '1' as flow_out_id,'2' as flow_in_id union all select '1' as flow_out_id,'3' as flow_in_id union all select '1' as flow_out_id,'5' as flow_in_id union all select '1' as flow_out_id,'7' as flow_in_id union all select '2' as flow_out_id,'5' as flow_in_id union all select '2' as flow_out_id,'4' as flow_in_id union all select '2' as flow_out_id,'3' as flow_in_id union all select '3' as flow_out_id,'5' as flow_in_id union all select '3' as flow_out_id,'4' as flow_in_id union all select '4' as flow_out_id,'5' as flow_in_id union all select '4' as flow_out_id,'8' as flow_in_id union all select '5' as flow_out_id,'6' as flow_in_id union all select '5' as flow_out_id,'7' as flow_in_id union all select '5' as flow_out_id,'8' as flow_in_id union all select '7' as flow_out_id,'6' as flow_in_id union all select '6' as flow_out_id,'8' as flow_in_id )tmp; drop table if exists EdgeDensity_func_test_result; create table EdgeDensity_func_test_result ( node1 string, node2 string, node1_edge_cnt bigint, node2_edge_cnt bigint, triangle_cnt bigint, density double );データ構造
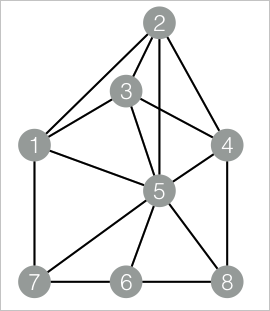
SQL Scriptコンポーネントをパイプラインに追加し、そのコンポーネントをクリックします。 [パラメーター設定] タブで、[スクリプトモードの使用] と [テーブル作成ステートメントを追加するかどうか] をオフにし、[SQLスクリプト] エディターに次のSQLステートメントを入力します。 このコンポーネントをステップ1で追加したコンポーネントと接続します。
drop table if exists ${o1}; PAI -name EdgeDensity -project algo_public -DinputEdgeTableName=EdgeDensity_func_test_edge -DfromVertexCol=flow_out_id -DtoVertexCol=flow_in_id -DoutputTableName=${o1};キャンバスの左上隅で、
 をクリックしてパイプラインを実行します。
をクリックしてパイプラインを実行します。パイプラインの実行後、手順2で追加した [SQLスクリプト] コンポーネントをクリックし、[データの表示]> [SQLスクリプトの出力] を選択してトレーニング結果を表示します。
| node1 | node2 | node1_edge_cnt | node2_edge_cnt | triangle_cnt | density | | ----- | ----- | -------------- | -------------- | ------------ | ------- | | 3 | 1 | 4 | 4 | 2 | 0.5 | | 5 | 1 | 7 | 4 | 3 | 0.75 | | 7 | 1 | 3 | 4 | 1 | 0.33333 | | 1 | 2 | 4 | 4 | 2 | 0.5 | | 4 | 2 | 4 | 4 | 2 | 0.5 | | 2 | 3 | 4 | 4 | 3 | 0.75 | | 5 | 3 | 7 | 4 | 3 | 0.75 | | 3 | 4 | 4 | 4 | 2 | 0.5 | | 8 | 4 | 3 | 4 | 1 | 0.33333 | | 2 | 5 | 4 | 7 | 3 | 0.75 | | 4 | 5 | 4 | 7 | 3 | 0.75 | | 7 | 5 | 3 | 7 | 2 | 0.66667 | | 5 | 6 | 7 | 3 | 2 | 0.66667 | | 8 | 6 | 3 | 3 | 1 | 0.33333 | | 6 | 7 | 3 | 3 | 1 | 0.33333 | | 5 | 8 | 7 | 3 | 2 | 0.66667 |