このトピックでは、Machine Learning Designerが提供するChi-square Goodness of Fit Testコンポーネントについて説明します。 カイ二乗適合度テストコンポーネントは、カテゴリ変数が使用されるシナリオで使用されます。 この成分は、単一のマルチクラス分類変数の各分類について、観察された頻度と予想される頻度との間の差を決定するために使用される。 帰無仮説は、観察された周波数と予想される周波数が同じであると仮定する。
コンポーネントの設定
次のいずれかの方法を使用して、テストの適合度のカイ二乗を設定できます。
方法1: Machine Learning Designerでコンポーネントを構成する
Machine Learning Platform for AIコンソールのMachine Learning Designerの [パイプライン設定] タブでコンポーネントを設定します。
パラメーター | 説明 |
入力列 | カイ二乗テストを実行する列。 |
クラス確率 | クラスの確率設定。 このパラメーターを |
方法2: AIコマンド用の機械学習プラットフォームの実行
Machine Learning Platform for AIコマンドを使用してコンポーネントパラメーターを設定します。 SQLスクリプトコンポーネントを使用して、Machine Learning Platform for AIコマンドを実行できます。 詳細については、「SQLスクリプト」をご参照ください。 このコンポーネントの設定に使用するコマンドのパラメーターを次の表に示します。
PAI -name chisq_test
-project algo_public
-DinputTableName=pai_chisq_test_input
-DcolName=f0
-DprobConfig=0:0.3,1:0.7
-DoutputTableName=pai_chisq_test_output0
-DoutputDetailTableName=pai_chisq_test_output0_detailパラメーター | 必須 | 説明 | デフォルト値 |
inputTableName | 可 | 入力テーブルの名前。 | None. |
colName | 可 | 列の名前。 | None. |
outputTableName | 可 | 出力テーブルの名前。 | None. |
outputDetailTableName | 可 | 出力詳細テーブルの名前。 | None. |
inputTablePartitions | 不可 | トレーニング用に入力テーブルから選択されたパーティション。 次の形式がサポートされています。
説明 複数のパーティションを指定する場合は、コンマ (,) で区切ります。 | デフォルトでは、このパラメータは空のままです。 |
probConfig | 不可 | クラスの確率設定。 このパラメーターを | デフォルトでは、このパラメーターは指定されておらず、すべての確率値は同じです。 |
例:
テストデータ
create table pai_chisq_test_input as select * from ( select '1' as f0,'2' as f1 union all select '1' as f0,'3' as f1 union all select '1' as f0,'4' as f1 union all select '0' as f0,'3' as f1 union all select '0' as f0,'4' as f1 )tmp;PAIコマンド
PAI -name chisq_test -project algo_public -DinputTableName=pai_chisq_test_input -DcolName=f0 -DprobConfig=0:0.3,1:0.7 -DoutputTableName=pai_chisq_test_output0 -DoutputDetailTableName=pai_chisq_test_output0_detailアウトプットの説明
outputTableNameパラメーターで指定された出力テーブルはJSON形式です。 テーブルには、1つの行と1つの列のみが含まれます。
{ "Chi-Square": { "comment": "Pearson's chi-square test", "df": 1, "p-value": 0.75, "value": 0.2380952380952381 } }次の表に、outputDetailTableNameパラメーターで指定する出力詳細テーブルの列を示します。
列名
コメント
colName
データソースクラス。
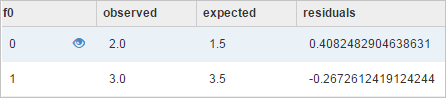
observed
観察された頻度。
expected
予想される周波数。
residuals
標準残差。次の式を使用して計算されます。
(標準残差= (Observed frequency - Expected frequency))/sqrt(Expected frequency)。生成されたデータ