このトピックでは、オンライン予測サービスに関するよくある質問 (FAQ) について説明します。
サービスの異常状態
1. サービスが長時間「待機中」状態のままです。どうすれば解決できますか?
デプロイメント後、サービスはリソースのスケジューリングとサービスインスタンスの起動を待つ間、「待機中」状態になります。すべてのサービスインスタンスが正常に起動すると、サービスは「実行中」状態になります。サービスが長期間「待機中」状態のままである場合、通常は [概要] ページの [サービスインスタンス] リストでサービスインスタンスのステータスとログを確認することで、原因を特定できます。考えられる原因は次のとおりです。
この問題は通常、専用リソースグループのアイドルリソースが不足しているためにインスタンスをスケジューリングできない場合に発生します。次の図に例を示します。
この場合、専用リソースグループのマシンノードに CPU、メモリ、GPU を含む十分なアイドルリソースがあるかどうかを確認してください。インスタンスが 3 コアと 4 GB のリソースを必要とする場合、専用リソースグループ内の少なくとも 1 つのマシンノードに 3 コアと 4 GB のアイドルリソースが必要です。
高負荷時のシステム障害を防ぐため、各マシンノードはシステムコンポーネント用に 1 つの CPU コアを予約します。スケジューリング可能なリソースは、総リソースからこの予約済みコアを差し引いたものです。
次の図は、専用リソースグループのノードリストを示しています。リソースグループの詳細を表示する方法については、「EAS リソースグループの使用」をご参照ください。
スラッシュ (/) の前の数字は正常に起動したコンテナーの数を示します。スラッシュ (/) の後の数字はコンテナーの総数を示します。カスタムイメージを使用してサービスをデプロイすると、トラフィックシェーピングやモニタリングなどのタスクのためにサイドカーコンテナーが自動的にインスタンスに挿入されます。このコンテナーを管理する必要はありません。コンソールでは、コンテナーの総数が 2 であることがわかります。これには、カスタムコンテナーとエンジンのサイドカーコンテナーが含まれます。この場合、両方のコンテナーが準備完了状態になった後にのみ、サービスインスタンスは起動したと見なされ、トラフィックの受信を開始します。
問題の説明:Flask (または FastAPI、Sanic、Django などの他の Web フレームワーク) を使用して API 操作を提供する EAS サービスがデプロイされています。ログには Running on http://127.0.0.1:7000 と表示されます。
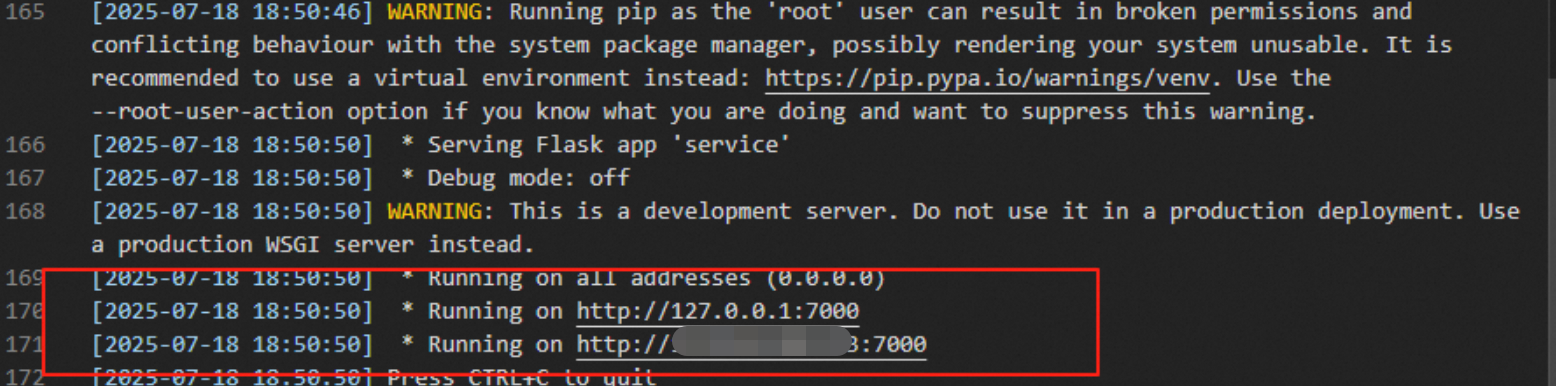
しかし、PAI コンソールでは、EAS サービスがまだ待機中状態であることが示されています。

原因:EAS サービスのワーカーがヘルスチェックに失敗しました。ワーカーによって公開されているポートは 8089 ですが、Flask はポート 7000 でサービスを提供しています。
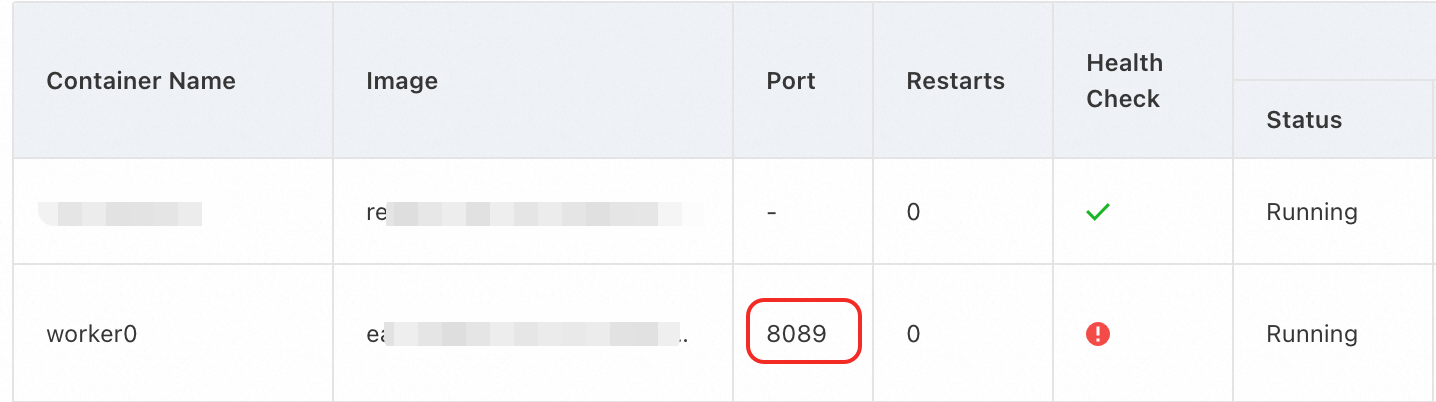
ソリューション:EAS サービスに設定されているポート番号をコード内のポートと一致するように変更し、サービスを再起動します。
2. サービスが「失敗」状態です。どうすれば解決できますか?
サービスは次の 2 つのシナリオで失敗状態になります。
サービスデプロイ中:デプロイ中にモデルアドレスなどの指定されたリソースが存在しない場合、エラーの原因がサービスの現在のステータス情報に表示されます。通常、このエラーメッセージからデプロイメントの失敗原因を特定できます。
サービス起動中:サービスがデプロイされ、リソースにスケジューリングされた後に起動に失敗します。この場合、ステータスメッセージ
Instance <network-test-5ff76448fd-h9dsn> not healthy: Instance crashed, please inspect instance log.が表示されます。このステータスメッセージは、サービスインスタンスの起動に失敗したことを示します。具体的な原因を特定するには、サービスの [概要] ページの [サービスインスタンス] リストで失敗したステータスを確認する必要があります。インスタンスの失敗の考えられる原因は次のとおりです。
起動中にメモリ不足 (OOM) エラーが発生したため、サービスインスタンスがシステムによって終了されました。この場合、サービスのメモリを増やしてサービスを再デプロイする必要があります。次の図はインスタンスのステータスを示しています。

起動時にコードエラーが原因で、サービスがクラッシュすることがあります。この場合、[最終ステータス]はエラー(エラーコード)になります。インスタンスの[アクション]列の[ログ]ボタンをクリックして、サービスログを確認し、障害の原因を特定します。次の図は、インスタンスのステータスを示しています。

サービスイメージのプルに失敗しました。詳細については、「イメージのプルに失敗した場合 (ImagePullBackOff)、どうすればよいですか?」をご参照ください。
3. EAS サービスが停止後に自動的に再起動します
4. PAI-EAS 起動エラー:IoError(Os { code: 28, kind: StorageFull, message: "No space left on device" })
5. デプロイエラー:fail to start program with error: fork/exec /bin/sh: exec format error
6. エラー: GPU 数 6 は無効です。サポートされているのは [0 1 2 4 8 16] のみです。
イメージに関する問題
1. イメージのプルに失敗した場合 (ImagePullBackOff)、どうすればよいですか?
サービスインスタンスリストの [最後の終了理由] に ImagePullBackOff が表示されている場合、イメージのプルに失敗した可能性があります。[ステータス] 列に次のアイコンが表示されている場合は、そのアイコンをクリックして具体的な原因を表示できます。

イメージのプルに失敗する一般的な原因は次のとおりです。
失敗原因 | 考えられるエラー | ソリューション |
システムディスクの容量不足 |
| システムディスクをスケールアウトします。 |
ACR のアクセスの制御が設定されていない |
| イメージのパブリックエンドポイントを使用する場合は、ACR のパブリックアクセスを有効にする必要があります。 イメージの内部エンドポイントを使用する場合:
|
EAS ネットワーク構成の問題 |
| イメージのパブリックエンドポイントを使用する場合は、EAS のインターネットアクセスを設定する必要があります。 |
認証情報がない、または正しくない |
| ACR Enterprise Edition インスタンスがパブリックな匿名プル用に設定されておらず、インターネット経由で別のリージョンからイメージをプルする場合は、デプロイ時にイメージリポジトリのユーザー名とパスワードを設定する必要があります。認証情報を取得する方法の詳細については、「アクセス認証情報の設定」をご参照ください。 |
イメージサービスと EAS のリージョンに基づいて、次の推奨事項に従ってください。
同じリージョン:内部 URL を使用してイメージをプルします。
異なるリージョン:ACR Personal Edition の場合、パブリックイメージ URL を使用する必要があります。ACR Enterprise Edition の場合、次のいずれかのオプションを選択します。
セキュリティと安定性に対する要件が高い場合は、内部イメージ URL を使用します。Cloud Enterprise Network (CEN) を使用して VPC を接続する必要があります。詳細については、「異なるリージョンまたは IDC から ACR Enterprise Edition インスタンスにアクセスする」をご参照ください。
ビジネスシナリオが単純であるか、内部ネットワークをすぐに接続できない場合は、一時的な解決策としてパブリックイメージ URL を使用します。インターネット経由のダウンロードは遅くなることに注意してください。
ACR Enterprise Edition インスタンスに関する次の点に注意してください。
必要に応じて、VPC とインターネットのアクセスの制御を設定します。
リポジトリが匿名でのイメージプルを許可していない場合、インターネット経由で異なるリージョンからイメージをプルするときに、EAS でイメージリポジトリのユーザー名とパスワードを提供する必要があります。
2. インターネットから EAS 公式イメージをダウンロードできますか?
コンピューティングリソースの使用量
1. 専用リソースグループが常にスケールアウトしています
2. 専用リソースグループからサブスクリプションインスタンスを削除するにはどうすればよいですか?
3. EAS リソースグループマシンのサブスクリプションを解除した後、サービスインスタンスのデータは保持されますか?
4. EAS サービスをデプロイするときに、1 コア、2 GB のリソース構成を選択できないのはなぜですか?
5. EAS でデプロイできるサービスの最大数はいくつですか?
6. 4090 グラフィックカードと同等の計算能力を持つ EAS の仕様は何ですか?
7. 特定のリソース構成でデプロイされたモデルの最大同時実行数はどのくらいですか?
サービス管理
1. SSH を使用して EAS インスタンスに接続できますか?
2. EAS のサービスステータスには何がありますか?
3. どの RAM ユーザーがサービスを作成したかを確認する方法
サービスの呼び出し
1. サービスの呼び出しエラーが発生し、404、401、504 などのステータスコードが返されます。
404 エラーは通常、無効なリクエストパス、不正なリクエストボディ、またはサービスがサポートしていない API を示します。受け取った特定のエラーメッセージに基づいて、次のシナリオを使用してトラブルシューティングを行ってください。
エラータイプ 1:{"object":"error","message":"The model `` does not exist.","type":"NotFoundError","param":null,"code":404}
原因:vLLM でデプロイされたサービスの /v1/chat/completions エンドポイントを呼び出す際、リクエストボディの model パラメーターが空または無効です。
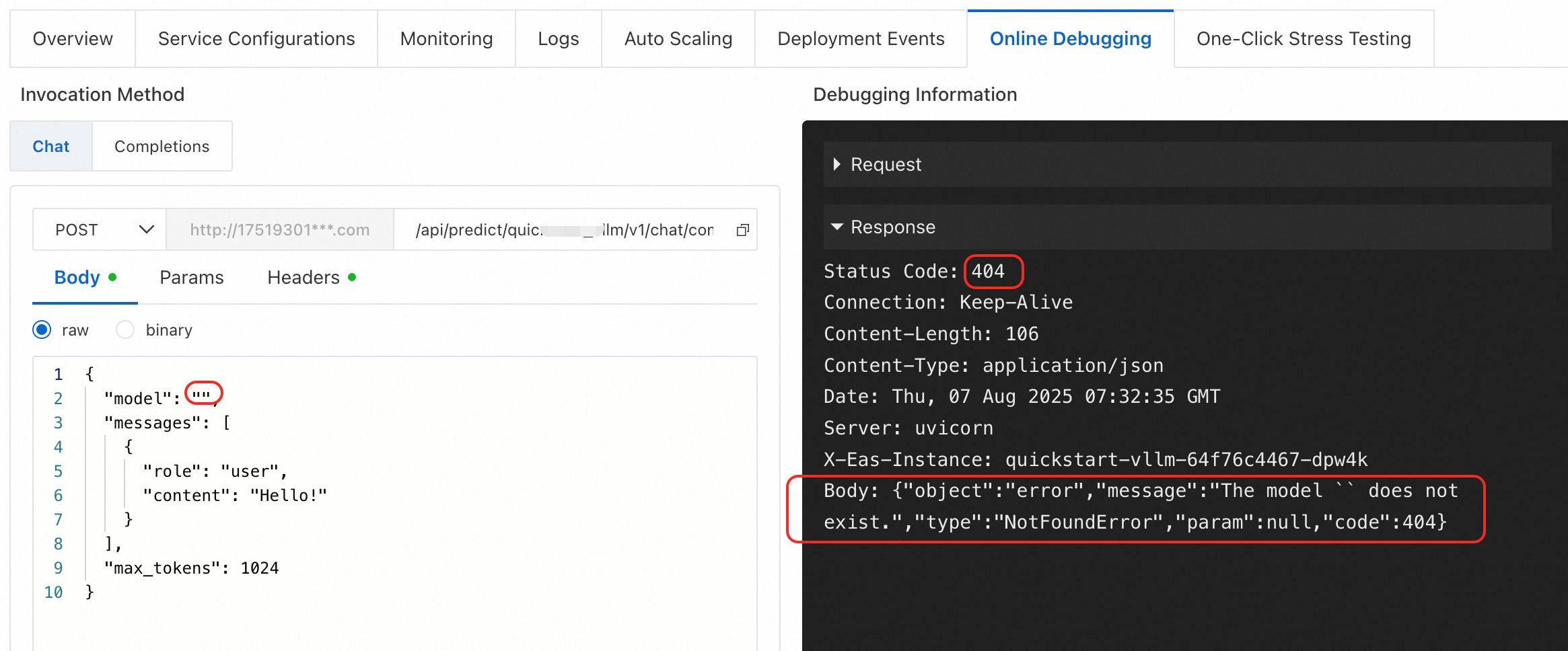
ソリューション:model パラメーターの値は有効なモデル名でなければなりません。v1/models エンドポイントを使用して有効なモデル名をクエリしてください。
エラータイプ 2:{"detail":"Not Found"}
原因:リクエストパスが不完全または正しくありません。たとえば、LLM サービスのチャットエンドポイントを呼び出す際に、ベース URL に v1/chat/completions パスを追加していません。
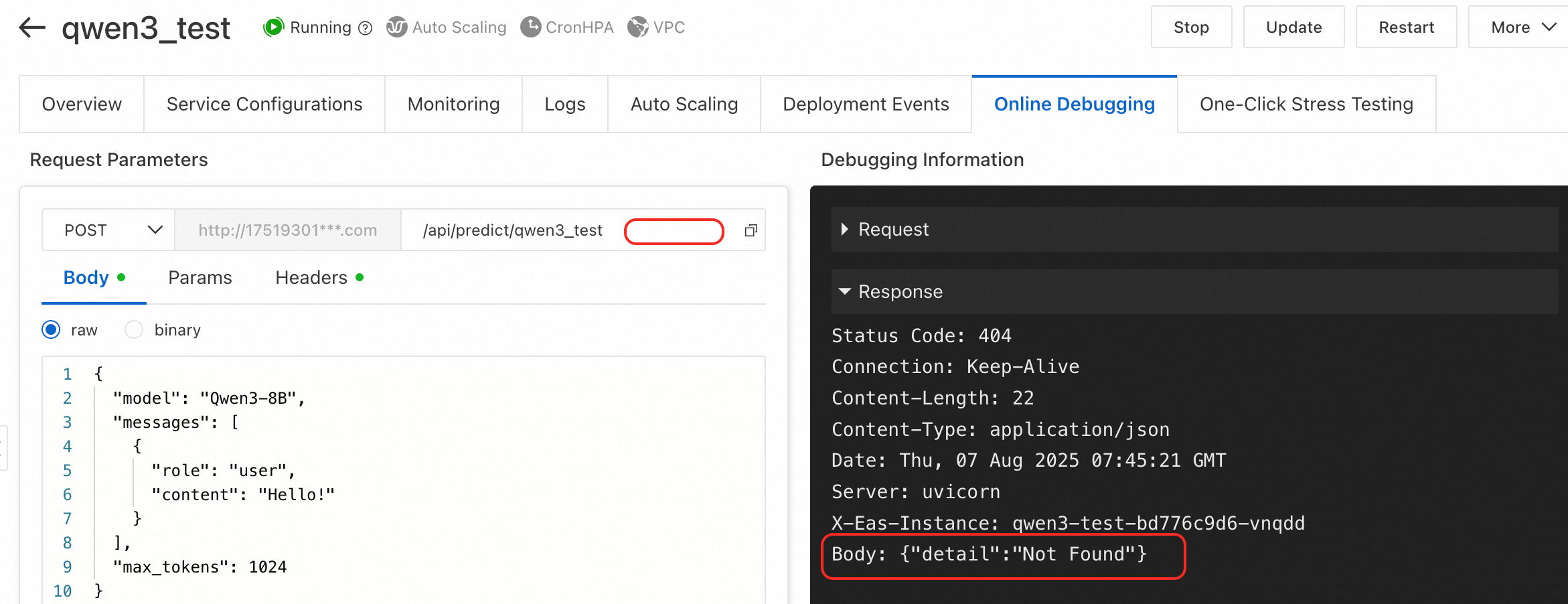
ソリューション:API リクエストパスが完全で正しいことを確認してください。LLM サービスについては、「LLM サービスの呼び出し」をご参照ください。
エラータイプ 3:BladeLLM の /v1/models エンドポイントを呼び出すと 404: Not Found が返されます。
原因:BladeLLM でデプロイされたサービスは v1/models エンドポイントをサポートしていません。
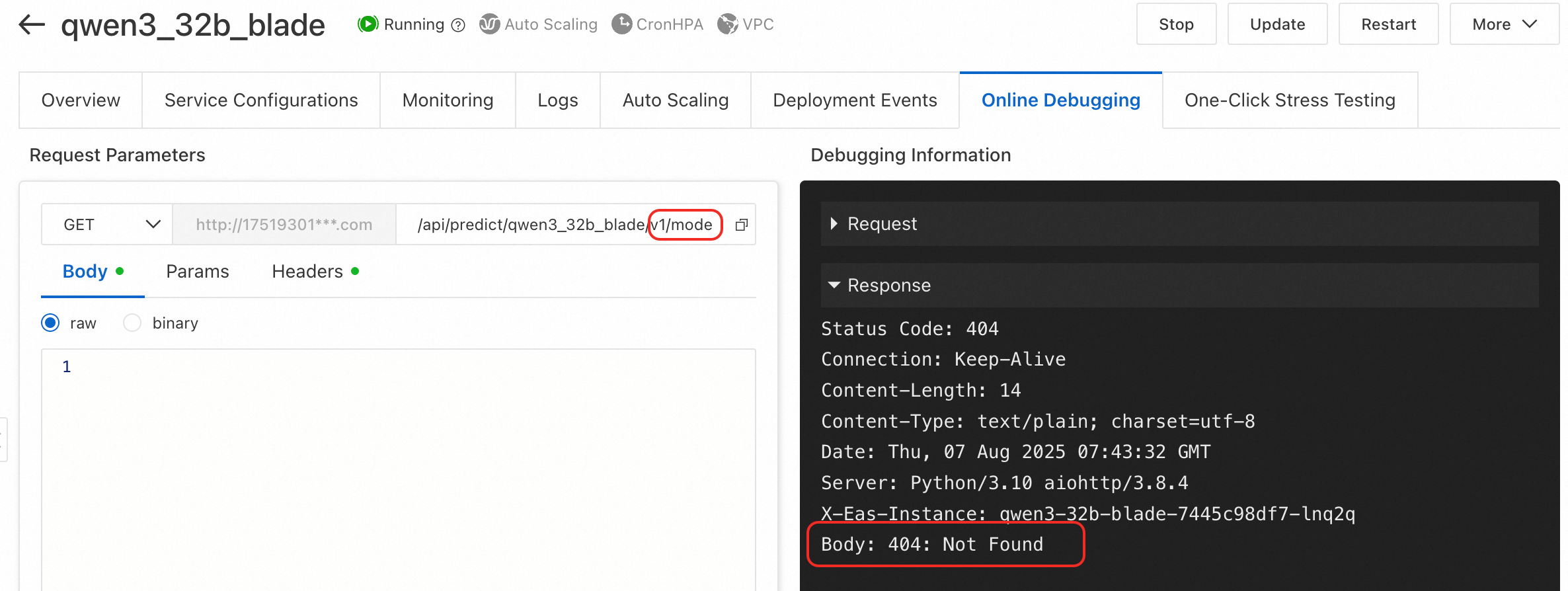
ソリューション:サポートされている API のリストについては、「BladeLLM サービス呼び出しパラメーターの構成」をご参照ください。
エラータイプ 4:オンラインデバッグページで、他の情報なしで 404 エラーが返されます。
原因:リクエストパスが正しくありません。オンラインデバッグを使用する場合、ベース URL は通常 http://123***.cn-hangzhou.pai-eas.aliyuncs.com/predict/service_name です。URL のサービス名部分を誤って変更または削除すると、404 エラーが発生します。
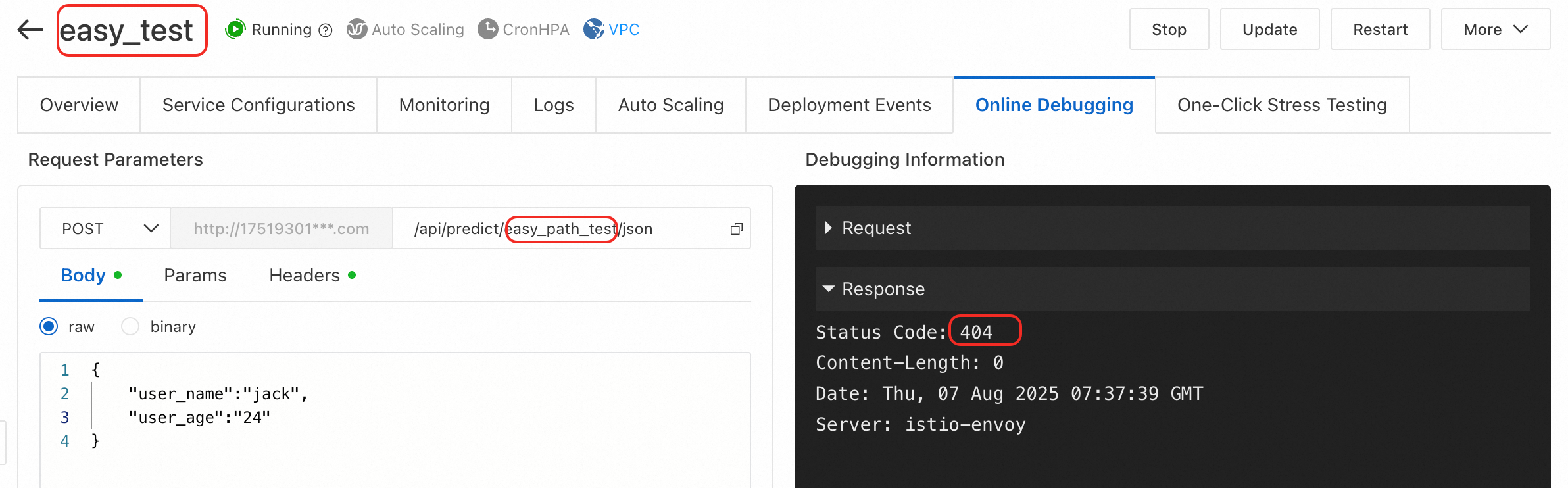
ソリューション:オンラインデバッグを使用する場合、通常はデフォルトの URL を変更または削除する必要はありません。呼び出す必要がある特定の API パスを追加してください。
エラータイプ 5:ComfyUI への API 呼び出しで "404 not found page" が返されます。
ステータスコードの詳細については、「付録:サービスステータスコードと一般的なエラー」をご参照ください。
2. PAI-EAS サービスは HTTPS 呼び出しをサポートしていますか?
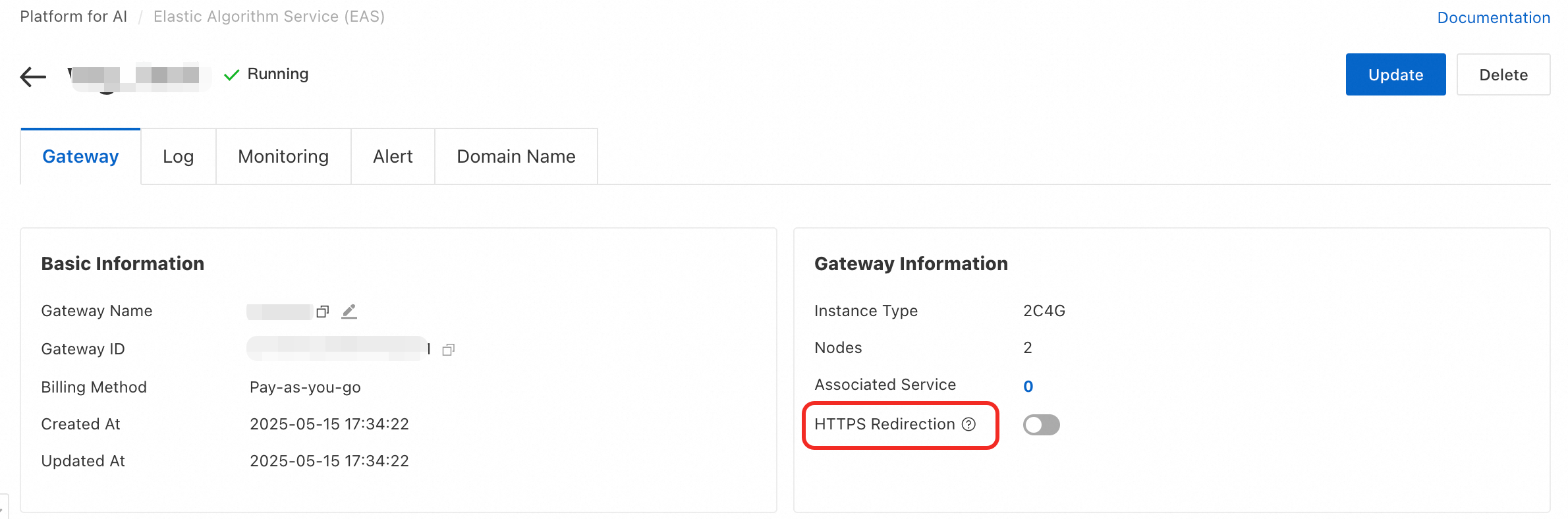
3. HTTP アクセスをブロックし、HTTPS アクセスのみを許可するにはどうすればよいですか?
共有ゲートウェイでは HTTP アクセスをブロックできません。専用ゲートウェイの場合は、[HTTPS リダイレクト] を有効にできます。これにより、すべての HTTP リクエストが HTTPS プロトコルにリダイレクトされます。
4. 独自のドメイン名で呼び出すことはできますか?
5. トークンは有効期限が切れたり、変更されたりしますか?
6. 1 つのサービスに対して複数のトークンを作成できますか?
7. デプロイされた LLM サービスのストリーミング応答を有効にするにはどうすればよいですか?
8. VPC エンドポイント呼び出しと VPC 直接接続呼び出しの違いは何ですか?
9. curl コマンドを使用して EAS オンラインサービスを呼び出すにはどうすればよいですか?
その他
システムディスク
システムディスクを拡張する方法
システムディスクは、 で構成するか、サービスの JSON 構成ファイルを次のように直接変更できます。

"metadata": {"disk": "40Gi"}専用リソースを使用する場合、必要なシステムディスクサイズが利用可能なシステムディスク容量よりも大きい場合は、現在のリソースを削除し、必要なサイズの新しいリソースを購入する必要があります。
ネットワークに関する問題
EAS サービスはサービス内からどのようにインターネットにアクセスしますか?
サービスストレージマウント
EAS サービスをデプロイするときに OSS バケットを選択できないのはなぜですか?
権限
RAM ユーザーが EAS サービスリンクロールを自動的に作成または削除できないのはなぜですか?
TensorFlow に関する問題
詳細については、「TensorFlow よくある質問」をご参照ください。